Seq2Seq模型是由谷歌在2014年提出的一种模型,它由一系列的LSTM构成的模型,而LSTM是RNN的一种变种,RNN前面我们已经介绍了,下面我们先介绍LSTM,再介绍Seq2Seq模型。
1.1 LSTM模型
(1)LSTM模型网络结构
LSTM是RNN的一种改进网络,单层LSTM网络结构如下:
设用Xt表示LSTM输入向量,ht表示LSTM的输出值,Ct表示LSTM的状态向量。LSTM模型可以看作是由两个主要函数构成的网络,第一个是用于计算记忆向量Ct的函数,另一个是用于计算输出向量ht的函数。
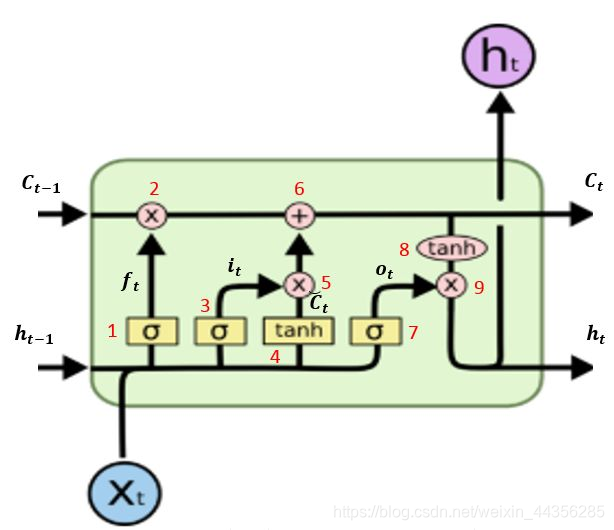
用于计算状态向量Ct的函数定义为,它依赖的向量有3个,分别为前一个输入得到的状态向量Ct-1及输出向量ht-1,和当前输入向量Xt。那么,
用于计算输出向量ht的函数定义为,它同样依赖Ct-1、ht-1、Xt。那么,
(2)LSTM内部逻辑
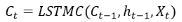
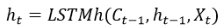
如上图,我们队LSTM内部的计算做了红色标记,总共有9次计算,每次计算的公式如下:
第1次计算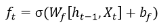
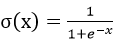
第2次计算: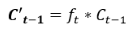
第3次计算: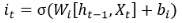
第4次计算: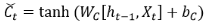
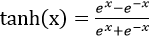
第5次计算: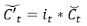
第6次计算: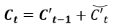
第7次计算: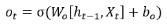
第8次计算: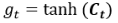
第9次计算: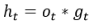
(3)LSTM的使用
LSTM模型使用,首先把所有事件按照顺序排列成一个序列,逐个输入到LSTM模型,通过状态向量Ct-1使模型记忆和理解上下文,例如:用户输入一串字符ABC,预测用户下一个输入,把A、B、C进行one-hot向量化,得到X1,X2,X3,依次带入计算(其中C0,h0为初始化向量):
1.2 Seq2Seq
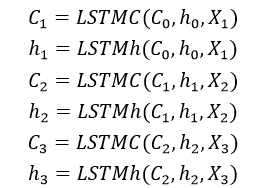
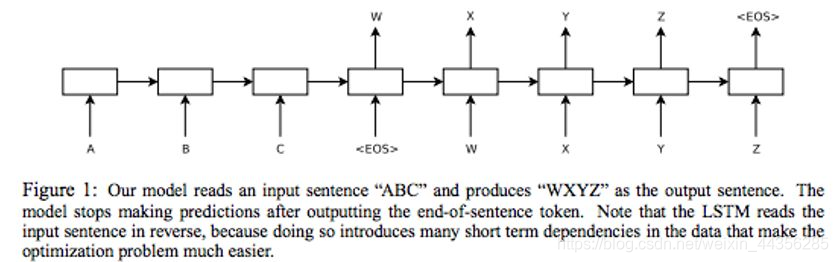
模型结构图如下:
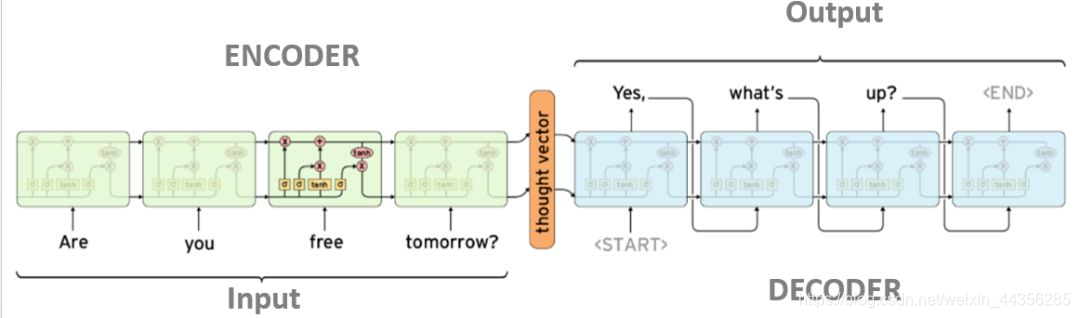
上图中左边为输入ABC,后边为输出WXYZ,整个模型分为左右两个LSTM网络,左边为encoder的LSTM网络,右边为decoder的LSTM网络。在谷歌发表的论文中,他们采用的是4层的LSTM网络。
为了便于说明,我们以单层LSTM的Seq2Seq模型为例,模型展开如下:
其中Input每个输入的LSTM网络参数都是一样,同理output的每个输出的LSTM网络参数是一样的。ENCODER的输入是one-hot编码的词,DECODER输出的是one-hot编码的词。
1.3 如何将Seq2Seq运用到推荐算法
Seq2Seq模型的优点,序列化预测,一个输入序列输出一个序列。在推荐场景中可以将用户历史浏览的物品按照时间顺序排列形成输入序列,将用户在输入节点后的物品浏览记录按照时间顺序形成输出序列,然后运用Seq2Seq算法进行预测
1.4 实例代码
https://github.com/rdevooght/sequence-based-recommendations
参考来源
[1] https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf
[2] https://florianwilhelm.info/2018/08/multiplicative_LSTM_for_sequence_based_recos/