LLM-TAKE: Theme-Aware Keyword Extraction Using Large Language Models
LLM-TAKE:使用大型语言模型提取主题关键词
paper:https://arxiv.org/abs/2312.00909
github:
就是通过prompt构造提示,然后使用LLM生成关键词结果,然后通过一系列后处理方式,减少模型幻觉的影响。可以参考他的后处理方式,然后结合自己的方法去使用。
文章目录~
1.背景动机
介绍抽取式和生成式关键词的区别:
提取型关键词主要是利用文本中存在的单词来概括输入文本,而抽象型关键词可以从文本中推断出来,但并不完全包含在文本中。
关键词抽取的传统方法,并指明缺陷:
一些模型以监督方式提取关键词,而另一些则以无监督方式提取。此外,这些模型一般分一个阶段或两个阶段完成任务。单阶段模型同时执行关键字召回集生成和关键字排名任务,而两阶段模型首先生成召回集,然后在重要性提取阶段选择最重要的关键字。然而,它们具有很强的领域针对性,而且由于缺乏足够的背景知识,通常只能在与其训练数据类似的文本上正常工作。
介绍基于PLM的关键词抽取以及PLM的缺陷:
预训练语言模型(PLM)通过在更大的文本库中进行训练,并将文本标记和片段映射到嵌入空间中,从而缓解了这一问题。然而,
- 由于训练数据的限制,一些 PLM 很难从输入文本中进行推理,并输出能够理解整个输入文本主题的结果。
- 传统的语言模型以及一些 PLM注意力持续时间短,这使得它们很难对文本中相互独立的单词得出相关结论
通过上述的缺陷,引出使用LLM:
大型语言模型具有推理能力,并能从大量训练数据中获取更广泛的知识背景,因此比以前的 PLM 更胜一筹。它们的架构更大,因此注意力更集中,能更好地理解输入文本的上下文
介绍本文提出的LLM架构:
在本文中,提出了一个多阶段框架,利用大型语言模型的强大功能,为电子商务环境中的商品提取主题感知关键词。把这个基于 LLM 的框架称为 “主题感知关键词提取模型”(LLM-TAKE)。
下面将讨论该框架的每个阶段如何帮助提高输出关键词的质量并减少幻觉。
2.Model
介绍该框架的不同阶段,以减少基于 LLM 方法的典型幻觉
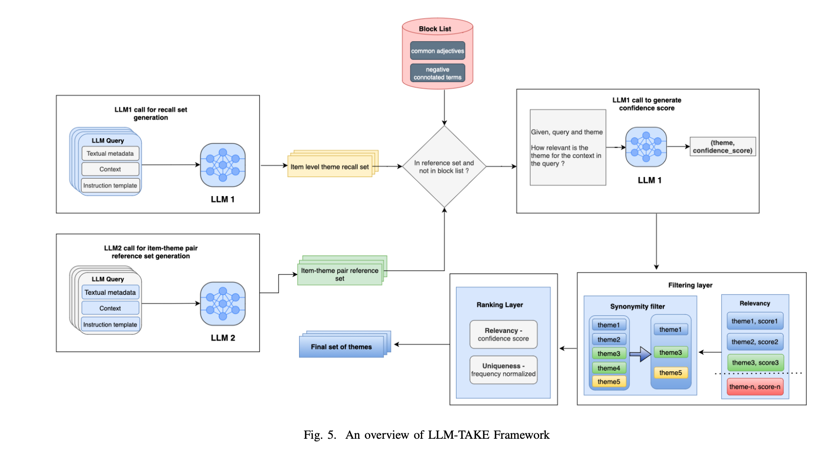
第一阶段(Theme Recall Set Generation)—候选关键词召回集的生成:
首先使用ChatGPT 的复杂 LLM 来生成候选关键词召回集。目标是生成两组关键词:(i) 抽象关键词和 (ii) 提取关键词。使用不同的提示策略来生成每组关键词。
Note: 生成抽象关键词可能会涉及更多推理,因为 LLM 可能会推断出产品的主题,而这是无法从输入的文本中获得的。然而,这反过来可能会导致更多的幻觉,生成的关键词可能无法从文本中推断出来。
在本文的提示策略中,使用相同的基本提示来生成提取型和抽象型关键词,但是,在提示生成提取型关键词时,我们明确添加了文本中存在的限制条件。
但是,即使明确指示 LLM 从文本中生成输出,它有时也会生成输入文本中未出现的关键词。
第二阶段(Hallucination Reduction and Theme Quality Improvement Steps)—减少幻觉和主题质量改进步骤:
2.1.构建主题参考集:
1.构建主题参考集: 为了减少幻觉,首先使用计算成本更低的模型为更大的产品集生成一组关键词。这个计算成本更低的模型可以是另一个参数数量更少的 LLM。
在使用主 LLM 为目标条目集中的任何给定条目生成主题感知关键词集时,本文会交叉检查生成的主题在条目-主题配对词典中的出现频率。如果给定主题在参考字典中出现的次数少于阈值,就会剔除该生成主题。通过这种方法,可以避免出现对特定兴趣项目过于独特的主题,从而避免出现过于新颖的结果,因为这些结果更有可能是幻觉的结果。
2.2.消除非信息性和一般性主题:
2.消除非信息性和一般性主题: 该框架的目标是生成具有足够信息量并能在用户决策过程中提供帮助的主题。因此,非常笼统的主题可能不具备区分能力,无法帮助用户做出决策。因此,剔除了 "完美 "或 "伟大 "等非常笼统的词语,因为这些词语在比较和对比产品时不会增加任何信息价值。
2.3.消除敏感词:
3.消除敏感词: 虽然在训练 LLM 时采取了许多预防措施来避免敏感回应,但仍然观察到输出了一些在某些情况下可能被解释为敏感的词语。为了剔除大部分敏感词,本文使用谷歌亵渎词 Github 存储库生成了一组敏感词。这就为我们提供了第二组词块列表,用于消除 LLM 生成的一些主题/关键词。
第三阶段(Theme Importance Extraction)—重要性主题抽取:
在与参考项目-主题对进行交叉检查并剔除非信息性和敏感关键词后,本文获得了生成的主题与相关项目的相关性。为此,会进行另一轮提示,要求 LLM 输出一个置信度分数,以衡量生成的关键词对输入产品的描述程度。
第四阶段(Theme Ranking)—主题排序
使用上一步生成的分数作为排序的主要标准。在这种情况下,可能会遇到两个主题得分相同的情况。我们会将在参考项目主题集中出现频率较高的主题排在较高的位置,从而打破平局。如果频率计数也相等,则对关键词进行随机排序。剔除所有得分低于预设阈值的项目-主题对。
第五阶段(Keyword Diversification)—关键词多样化:
最后,为了进一步改进最终为项目生成的关键词主题集,进行了同义词检查,以避免提取语义相似的关键词。例如,“fun”(有趣)和 “funny”(滑稽)这两个词可能会作为某个产品的主题出现。通过这一步骤,可以剔除与较高级别的主题在语义上相似的较低级别的主题。为了获得词对的相似性得分,使用 SpaCy Python 库中的 en core web md 嵌入模型来生成词嵌入。
3.原文阅读
Abstract
关键词提取是自然语言处理的核心任务之一。传统的提取模型由于注意力集中时间短,很难总结出相距甚远的单词和句子之间的关系。这反过来又使它们无法用于生成从整个文本的上下文推断出的关键词。在本文中,我们将探索使用大型语言模型(LLM)来生成根据项目文本元数据推断出的项目关键词。我们的建模框架包括几个阶段,通过避免输出无信息或敏感的关键词,减少 LLM 中常见的幻觉,从而对结果进行细粒度处理。我们将基于 LLM 的框架称为主题感知关键词提取(LLM-TAKE)。我们提出了两种不同的框架,用于在电子商务环境中生成提取型和抽象型产品主题。我们在三个真实数据集上进行了大量实验,结果表明,与基准模型相比,我们的建模框架可以提高基于准确性和多样性的指标。
I Introduction
介绍抽取式和生成式关键词的区别:
关键词提取被定义为生成一组相关关键词来概括和描述输入文本的任务[1]。生成的关键词可以是提取型的,也可以是抽象型的。提取型关键词主要是利用文本中存在的单词来概括输入文本,而抽象型关键词可以从文本中推断出来,但并不完全包含在文本中[2]。提取关键词的目的是通过提供有限的关键词来提高人类理解纹理信息的效率。在电子商务环境中,这项任务可以帮助客户从提取的关键词中快速了解产品的特征,并有可能提高客户的购物效率和体验。
关键词抽取算法的分类:
关键词提取任务的经典算法在提取关键词的策略范式上各不相同。一些模型以监督方式提取关键词,而另一些则以无监督方式提取[3]。此外,这些模型一般分一个阶段或两个阶段完成任务。单阶段模型同时执行关键字召回集生成和关键字排名任务,而两阶段模型首先生成召回集,然后在重要性提取阶段选择最重要的关键字[4]。
介绍传统方法的缺陷,引出使用PLM,并介绍PLM的缺陷:
然而,这些模型大多是 “狭隘的专家”,因为它们具有很强的领域针对性,而且由于缺乏足够的背景知识,通常只能在与其训练数据类似的文本上正常工作 [5,6]。预训练语言模型(PLM)通过在更大的文本库中进行训练,并将文本标记和片段映射到嵌入空间中,从而缓解了这一问题。然而,由于训练数据的限制,一些 PLM 很难从输入文本中进行推理,并输出能够理解整个输入文本主题的结果。
除此之外,传统的语言模型以及一些 PLM 因注意力持续时间短而臭名昭著,这使得它们很难对文本中相互独立的单词得出相关结论,从而使它们在提取从整个文本中获取的关键词时显得力不从心[7]。换句话说,当语言任务依赖于上下文时,它们的使用会受到限制[8]。
通过上述的缺陷,引出使用LLM:
大型语言模型最近在语言任务中显示出了巨大的潜力。大型语言模型具有推理能力,并能从大量训练数据中获取更广泛的知识背景,因此比以前的 PLM 更胜一筹。它们的架构更大,因此注意力更集中,能更好地理解输入文本的上下文[9]。特别是,它们在总结和情感分析等其他语言任务中击败了最先进的模型[10, 11, 12]。
介绍本文提出的LLM架构:
在本文中,我们提出了一个多阶段框架,利用大型语言模型的强大功能,为电子商务环境中的商品提取主题感知关键词,从而进一步帮助顾客完成购物之旅。我们把这个基于 LLM 的框架称为 “主题感知关键词提取模型”(LLM-TAKE)。我们在专有数据集和公共数据集上进行的实验表明,与最先进的模型相比,我们提出的方法能有效地改善相关指标。我们将讨论该框架的每个阶段如何帮助提高输出关键词的质量并减少幻觉。
本文接下来的内容安排如下。第二节,我们回顾了文献中的相关工作。第三节,介绍并讨论 LLM-TAKE 框架。第四部分,我们介绍并分析实验结果。最后,我们在第五部分结束本文。
II Literature Review
基于统计的方法(KE):
传统的关键词提取模型是基于统计或基于图的方法来解决这个问题的。统计模型依赖于各种统计特征,如词频、N-grams、位置和文档语法[3]。然而,这些特征可能无法充分捕捉文档中单词之间错综复杂的关系。统计方法的基本原理是利用单篇文档或多篇文档中的各种统计数据来确定给定术语的得分。计算得分后,该方法会根据得分对术语进行排序,并将前 n 个术语突出显示为基本关键词,不同的方法采用不同的 N-gram 分数计算方法(见 [13, 14, 15])。
基于图的方法(KE):
与基于统计的方法并行,基于图的关键词提取已成为最有效和最广泛采用的无监督关键词提取模型之一。基于图的模型将人类语言表示为错综复杂的网络,并利用图来概括文档中单词或短语之间存在的多方面关系[16]。例如,[17] 从 PageRank [18]汲取灵感,创建了 TextRank,将文档建模为一个图,其中节点表示单词或短语,边表示它们之间的联系。[19]提出的 PositionRank 模型将单词出现的位置信息整合到有偏差的 TextRank 中,大大提高了其在较长文档中的性能。随后,又提出了几种策略来丰富文档图中包含的信息。例如,[20] 提出了 TopicRank 模型,旨在通过候选关键词聚类为主题分配重要性分数。该模型应用 TextRank 排名算法来评估主题,并通过从排名最高的主题中选择最具指示性的候选关键词来提取关键词。
基于预训练模型,深度学习方法(KE):
在传统的关键词提取模型中利用从外部文本语料库中获取的背景信息一直是一个长期存在的挑战[21],因为根据[22]的研究,纳入外部知识或附加特征会进一步增强关键词提取任务。预训练的嵌入模型拥有大量信息,使其能够准确地表示词或短语之间的关系。因此,根据文献[3],基于预训练语言模型(PLM)的关键词提取近年来取得了重大进展。
[23]引入了 Key2Vec,这是一种训练嵌入的方法,在创建科学文章的主题表征和为潜在关键词分配主题权重方面被证明是有效的。此外,他们还将主题加权 PageRank [18] 纳入了自己的框架,对这些关键词进行排名。不过,Key2Vec 仅适用于科学文章领域。[24] 提出了 EmbedRank,它利用了候选关键词嵌入和文档句子嵌入之间的余弦相似度。有鉴于此,[25] 提出了一种基于嵌入的模型,称为 SIFRank,它将[26] 的句子嵌入模型 SIF 与自回归预训练语言模型 ELMo [27]融合在一起,从而在关键词提取方面取得了显著的性能,尤其是对于简洁的文档。[25] 通过采用文档分割和上下文词嵌入对齐进一步增强了 SIFRank,确保了速度和准确性。此外,他们还针对长文档引入了 SIFRank+,结合位置偏置权重,显著提高了其在扩展文本上的性能。
为了使关键词抽取模型更具上下文感知能力,[28] 的 AttentionRank 采用预训练语言模型来确定候选词在句子上下文中的自关注度以及候选词与文档中句子的交叉关注度,从而评估候选词的局部和全局意义。KeyBERT 是一种使用 BERT 提取关键词的工具包,它首先提取文档嵌入以获得文档级表示。随后,它提取 N-gram 词或短语的词嵌入。然后,KeyBERT 应用余弦相似性来识别与文档最相似的单词或短语,这些单词或短语被认为是整个文档的最佳关键词。作为 KeyBERT 的升级版,[30] 引入了 AdaptKeyBERT,这是一种利用 LLM 基础训练关键词提取器的管道,它将正则化注意力集成到预训练阶段,以便进行下游领域适应。
III Modeling Framework
在本节中,我们将讨论 LLM-TAKE 生成主题感知关键词的框架。我们将介绍该框架的不同阶段,以减少基于 LLM 方法的典型幻觉
A.Theme Recall Set Generation
第一阶段—候选关键词召回集的生成:
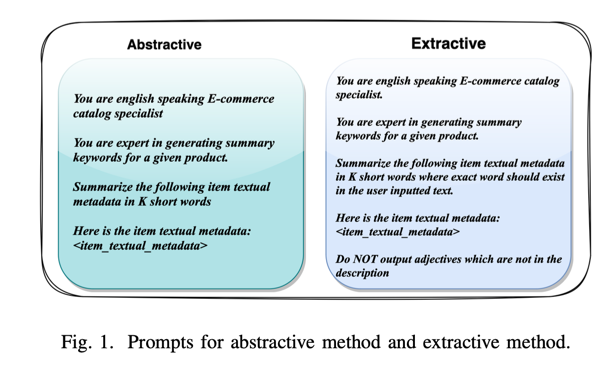
我们首先要生成一个候选关键词召回集。我们使用类似于 [31] 中 ChatGPT 的复杂 LLM 来生成召回集。正如导言中所述,我们的目标是生成两组关键词:(i) 抽象关键词和 (ii) 提取关键词。我们使用不同的提示策略来生成每组关键词。下图 1 展示了我们在每种方法中使用的提示。
需要注意的是,生成抽象关键词可能会涉及更多推理,因为 LLM 可能会推断出产品的主题,而这是无法从输入的文本中获得的。然而,这反过来可能会导致更多的幻觉,生成的关键词可能无法从文本中推断出来。在这种情况下,对于工业应用中的某些用例来说,提取关键词可能更为安全。
在我们的提示策略中,我们使用相同的基本提示来生成提取型和抽象型关键词,但是,在提示生成提取型关键词时,我们明确添加了文本中存在的限制条件。有趣的是,我们发现即使明确指示 LLM 从文本中生成输出,它有时也会生成输入文本中未出现的关键词。因此,即使在提示获取提取关键词时,我们也可能会检查并删除输入文本中不存在的所有关键词。
B.Hallucination Reduction and Theme Quality Improvement Steps
LLM-TAKE 还包括一系列步骤,以减少幻觉并提高最终生成关键词的质量,这将在下面的小节中讨论。
第二阶段—减少幻觉和主题质量改进步骤:
2.1.构建主题参考集:
1.构建主题参考集: 为了减少幻觉,我们首先使用计算成本更低的模型为更大的产品集生成一组关键词。这个计算成本更低的模型可以是另一个参数数量更少的 LLM。为了便于参考,我们称这种计算成本更低的模型为 “LLM2”。在预言数据集的实验中,我们对从类似产品类别中获得的约 1,000 万个项目进行了这一实验。这组项目-主题对可作为最终相关项目集的参考。
在使用主 LLM 为目标条目集中的任何给定条目生成主题感知关键词集时,我们会交叉检查生成的主题在条目-主题配对词典中的出现频率。如果给定主题在参考字典中出现的次数少于阈值,我们就会剔除该生成主题。通过这种方法,我们可以避免出现对特定兴趣项目过于独特的主题,从而避免出现过于新颖的结果,因为这些结果更有可能是幻觉的结果。我们推测**,一些因幻觉而产生的独特主题在参考项目主题集中多次重复出现的几率较低**。因此,如果一个主题在许多项目中出现过,这可能是由于主题的普遍性,因而不是由于幻觉产生的。
2.2.消除非信息性和一般性主题:
2.消除非信息性和一般性主题: 该框架的目标是生成具有足够信息量并能在用户决策过程中提供帮助的主题。因此,非常笼统的主题可能不具备区分能力,无法帮助用户做出决策。因此,我们剔除了 "完美 "或 "伟大 "等非常笼统的词语,因为这些词语在比较和对比产品时不会增加任何信息价值。
最初的通用主题集来自牛津大学使用的前 500 个形容词。通过人工调查样本关键词集,我们将更多关键词添加到这组通用词中。这就是我们用来剔除由 LLM 生成的部分关键词的第一份模块列表。
2.3.消除敏感词:
3.消除敏感词: 虽然我们在训练 LLM 时采取了许多预防措施来避免敏感回应,但我们仍然观察到输出了一些在某些情况下可能被解释为敏感的词语。为了剔除大部分敏感词,我们使用谷歌亵渎词 Github 存储库生成了一组敏感词。这就为我们提供了第二组词块列表,用于消除 LLM 生成的一些主题/关键词。
C. Theme Importance Extraction
第三阶段—重要性主题抽取:
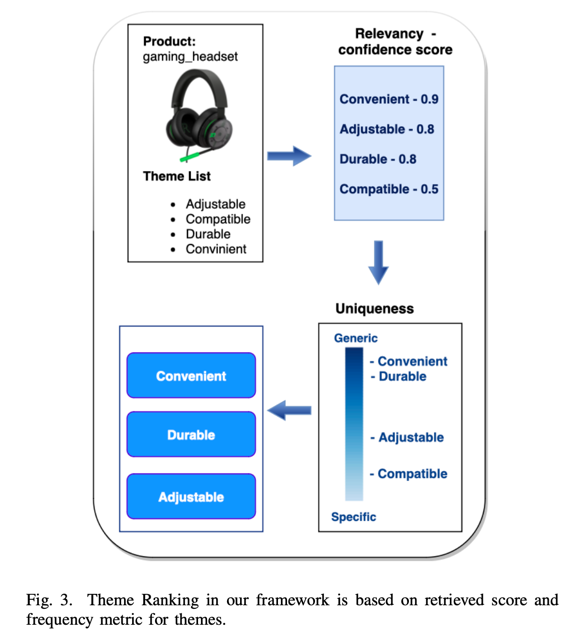
为了重新验证生成的主题集的相关性,在与参考项目-主题对进行交叉检查并剔除非信息性和敏感关键词后,我们获得了生成的主题与相关项目的相关性。为此,我们会进行另一轮提示,要求 LLM 输出一个置信度分数,以衡量生成的关键词对输入产品的描述程度。下图 2 展示了我们框架的这一步骤:
有趣的是,在进行这一步时,我们观察到一组生成的分数对相关产品的置信度分数非常低。在我们的专有数据集中执行此步骤后,约有 10% 的项目-主题对在分数阈值为 0.2 时丢失。

D.Theme Ranking
第四阶段—主题排序
我们使用上一步生成的分数作为排序的主要标准。在这种情况下,我们可能会遇到两个主题得分相同的情况。我们会将在参考项目主题集(见第 III-B1 小节)中出现频率较高的主题排在较高的位置,从而打破平局。在这种情况下,我们要确保取消较独特项目的优先排序,因为它们可能有更高的机会成为幻觉的结果。如果频率计数也相等,则对关键词进行随机排序(根据我们的实验,这种情况非常罕见,因为项目-主题对的参考集是根据大量项目构建的)。
请注意,在我们的框架中,无论主题的等级如何,我们都会剔除所有得分低于预设阈值的项目-主题对。
E. Keyword Diversification
第五阶段—关键词多样化:
最后,为了进一步改进最终为项目生成的关键词主题集,我们进行了同义词检查,以避免提取语义相似的关键词。例如,“fun”(有趣)和 “funny”(滑稽)这两个词可能会作为某个产品的主题出现。通过这一步骤,我们可以剔除与较高级别的主题在语义上相似的较低级别的主题。为了获得词对的相似性得分,我们使用 SpaCy Python 库中的 en core web md 嵌入模型来生成词嵌入[34]。
图 5 总结了我们提出的框架工作流程。
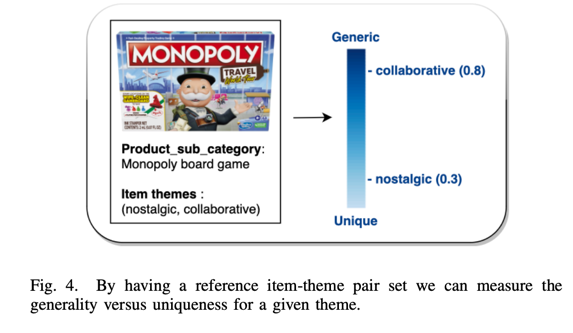
F.Approximating Theme Generality vs Uniqueness
通常,在电子商务环境中,商品空间被划分为电子产品、玩具和游戏、家居和花园等产品大类。这些产品大类又分为若干小类。例如,电子产品可分为笔记本电脑、耳机等。
在本小节中,我们要强调参考项目-主题配对集为我们提供的另一项功能。对于给定产品子类别中的所有项目,我们可以计算该子类别中每个项目生成主题的频率。这样,我们就可以衡量出该生成主题在该产品子类别中的通用性和唯一性。例如,考虑 "棋盘游戏 "子类别中的项目。我们发现,"协作 "主题比 "怀旧 "主题出现的频率更高。这意味着,合作类的棋盘游戏数量较多,而怀旧类的棋盘游戏数量较少(可能在其设计中包含了怀旧主题,或者让玩家回忆起童年时光)。在这个例子中,我们可以得出这样的结论:"协作 "是一个比 "怀旧 "更普遍的主题。这样,我们就可以在需要强调物品更独特或更一般的主题时,选择不同的主题。见图 4。
IV Empirical Results
在本节中,我们将评估所提出的 LLM-TAKE 方法在实际数据上的性能,这两个数据集分别来自一个电子商务平台的专有数据和 DUC2001 的公共数据。其中一个专有数据集包括电子产品类项目(用 P-Electronics 表示),另一个包括玩具和游戏类项目(用 P-Toys 表示)。我们将 LLM-TAKE 的性能与各种最先进的关键词提取模型进行了比较。表 I 显示了这三个数据集的文档数量,以及 LLM-TAKE 和所有基准模型生成的唯一关键词数量。
A.Datasets
专有数据集由一个电子商务平台上的 188 个高流量项目组成,其各自的文本元数据可作为关键字外延的文档。该数据集包括 94 个玩具类项目和 94 个电子产品类项目。
DUC2001 [35] 公共数据集也用于评估不同模型的性能。该数据集在 ExpandRank 论文[35]中进行了人工标注。DUC2001 数据集最初设计用于文档摘要,由 308 篇新闻文章组成,涵盖 30 个不同的新闻主题。平均每篇文章包含 740 个单词。
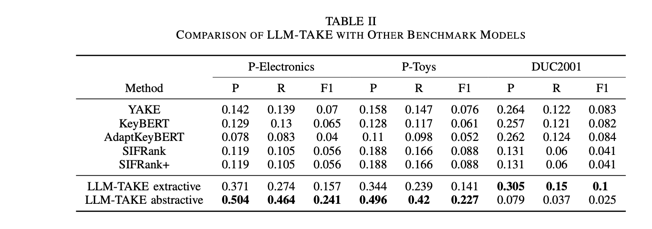
B.Benchmark Models
我们将我们的模型与传统关键词提取模型和基于嵌入的关键词提取模型进行了比较。我们评估了 YAKE [14]、SIFRank、SIFRank+ [25]、KeyBERT [29] 和 AdaptKeyBERT [30]。对于 YAKE,我们将窗口大小设为 1,重复数据删除阈值设为 0.9,n-gram 长度设为 1。对于 SIFRank 和 SIFRank+,我们使用了作者建议的代码库和相同的参数。对于 KeyBERT,我们使用了 [29] 开发的工具包。我们使用开源 python 库 AdaptKeyBERT 来实现 AdaptKeyBERT,该库由 [30] 在 KeyBERT 工具包 [29] 的基础上构建而成。我们使用 OpenAI [31] 提供的 GPT-3.5 API 实现了 LLM-TAKE 方法。我们还使用计算成本更低的 LLM 生成项目主题对的参考集。我们测试了抽象型和提取型 LLM-TAKE 方法。在本研究中,我们使用宏观精度(P)、召回率(R)和 F1 分数(F1)(3)来评估模型[36]。
C.Performance Comparison
产品专家团队为专有数据集的每个项目手动评估和选择最重要的关键词。该团队为所有 188 个项目选择了 322 个不同的关键词,平均每个文档有 3.14 个关键词。在 94 个玩具项目中,产品专家选择了 186 个不同的关键词,平均每个文档有 3.24 个关键词。此外,94 个电子产品项目有 179 个不同的关键词被选中,平均每个文档有 3.05 个关键词。
表 II 列出了本文讨论的所有提取方法的前三名精确度、召回率和 F1 分数。该表分为两部分:第一部分显示了基准结果,第二部分展示了 LLM-TAKE 在抽取和抽象两种形式下的性能。在这些基准模型中,我们发现 YAKE 模型尽管易于实现,却能获得与其他基准模型相当的分数。SIFRank 和 SIFRank+ 显示了相同的结果,因为我们只截取了前 3 个关键词,而这 3 个关键词在两个模型中的排名都很高。
在 DUC2001 数据集中,AdaptKeyBERT 比其他基准模型略胜一筹。我们的 LLM-TAKE 模型的抽象版本在 P-Electronics 和 P-Toys 数据集中取得了一流的成绩。与此同时,LLM-TAKE 的提取版本在由长新闻文档组成的 DUC2001 数据集中取得了最佳性能。抽象型和提取型 LLM-TAKE 方法的不同表现可归因于数据集注释过程的差异。在 DUC2001 数据集中,两名研究生[35]采用了抽取式方法(而非抽象式)对数据进行注释。
另一方面,对于 P-电子产品和 P-玩具,分析过程涉及将所有基线模型的输出结果以及 LLM-TAKE 的抽象和提取输出结果进行合并。然后,这份合并输出清单被洗牌并转发给一个产品专家小组,但没有告知他们每个关键词的来源方法。产品专家团队随后选出前三名结果并进行排名,作为标签。
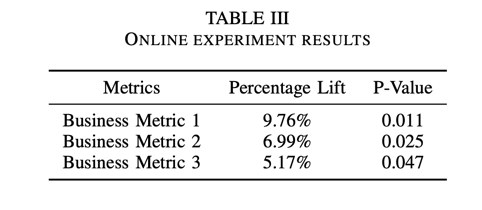
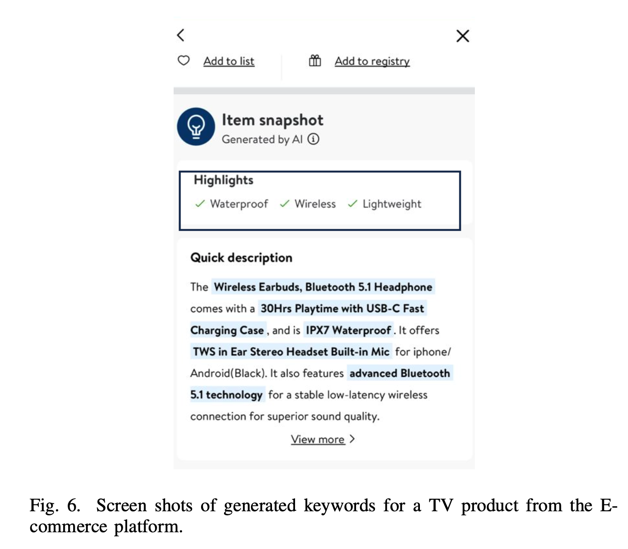
D.Online Experiment
离线实验展示了最先进的性能,之后我们决定进行在线实验。在这些在线测试中,我们将从产品描述中提取的前三个关键词显示为特定商品的亮点,见图 6。我们在电子商务平台上的 200 多个产品类别中引入了这一功能。
表 III 显示了在线实验的结果,其中揭示了包括不同业务指标在内的各方面统计意义上的显著提升。出于专有原因,我们隐去了商业指标的名称。这些发现有力地表明,LLM-TAKE 方法确实非常有效。这进一步强调了 LLM-TAKE 在电子商务应用领域的重要性和潜在影响。
V Conclusion
传统的关键词提取模型存在训练数据有限和关注时间短的问题。因此,当需要从任何文本文档中生成上下文感知和主题感知的关键词时,这些模型的使用就变得非常有限。在本文中,我们提出了一个基于 LLM 的框架,用于生成电子商务环境中基于上下文和主题的产品关键词。我们将这一建模框架称为主题感知关键词提取(LLM-TAKE)方法。我们提出了从产品文本元数据中生成抽取式关键词和抽取式关键词的两种方法。我们讨论了该框架的不同实施阶段,以减少生成敏感或无信息关键词的机会。我们还讨论了通过交叉检查任何给定 LLM 生成的主题和由计算成本更低的模型生成的项目主题对参考集来减少幻觉的方法。此外,我们还说明了如何将参考项目-主题对用作衡量任何生成主题的通用性和唯一性的标准。
我们在三个有注释的真实世界数据集上进行的实验表明,我们的框架能带来更高的准确度指标,从而证明了大型语言模型在为某些数据集生成主题感知关键词方面的能力。
VI. LIMITATIONS
与 LLM 相关的常见风险是可能出现幻觉,即生成的文本可能与事实不符或本质上是错误的。虽然我们已经在方法论中加入了多个步骤来应对幻觉,包括维护参考集、剔除非信息词、去优先级更独特的词等,这些在前面的章节中都有详细解释,但幻觉的概率仍然不会为零,因为 LLM 可能会因为输入中的噪声而受到上下文理解能力有限的挑战。