MetaKP: On-Demand Keyphrase Generation
MetaKP:按需生成关键词
paper: https://arxiv.org/abs/2407.00191
GitHub: https://github.com/uclanlp/MetaKP
本文提出了一种的关键词生成范式,即按需生成,其实就是将关键词的生成划分为两个阶段,第一个阶段是生成一个目标文本中关键词的类别,可以理解为去找关键词集合中的子集,然后根据目标类别与文本去生成符合类别标准的关键词,防止无关关键词的干扰。
然后本文测试了两种方法:1.微调序列模型,例如bart,flan-t5… 2.提示LLM
文章目录~
1.背景动机
介绍关键词抽取面临的问题:
现有的关键词预测方法一般都遵循一个次优假设:
对于每篇文档,模型都会预测一组与应用无关的关键词,然后根据一组参考进行评估。
这种方法既无法满足下游应用对关键词预判定的主题和具体程度的不同要求,也无法满足具有不同背景的人类用户的不同期望。为了妥善处理这些不同的反馈,目前的方法只能依赖于抽样重排策略,这在很大程度上是低效的。此外,单一参考设置也会使关键词预测模型的内在评估出现偏差,因为关键词标签中的高频主题可能会大大超过长尾关键词。
引出本文提出的解决范式,即需生成关键词:
为了应对这挑战,提出了 "按需生成关键词"这一新颖的范式,该范式以 "目标短语"为条件预测关键词,"目标短语 "指定了关键词的高级类别或意图。如图1

本文提出的解决该范式的方法:
MetaKP,这是一个大规模按需关键词生成基准,涵盖新闻和生物医学文本领域的四个数据集、7500 个文档和 3760 个独特目标。
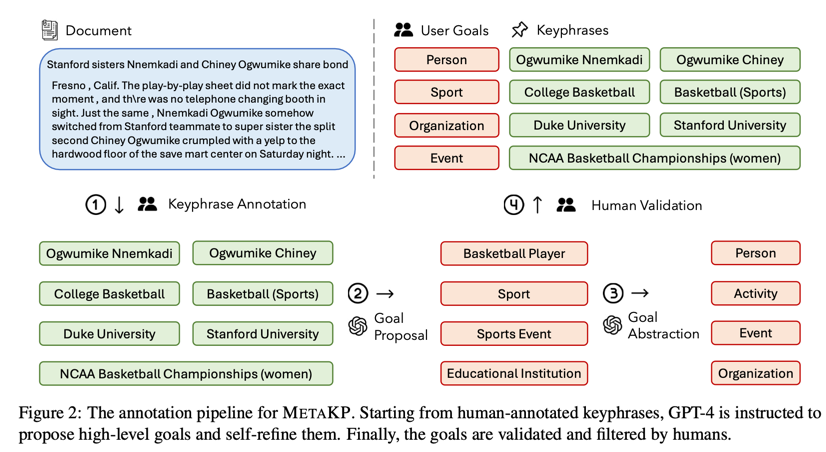
- 建立了一个可扩展的标注管道,该管道结合了 GPT-4和人类标注者,可从关键词中构建高质量的目标(图 2)。
- 为了进行评估,设计了两项任务:(1)判断目标的相关性和(2)生成符合目标的关键词。
通过使用 MetaKP,开发出了按需生成关键词的有监督和无监督方法。
- 在监督方法中,设计了一种多任务微调方法,使序列预训练语言模型能够自我确定目标的相关性,并有选择地生成关键词。
- 然后,介绍了一种无监督自一致性提示方法,该方法利用了大型语言模型(LLM)。
2.Model
1.介绍提出的关键词生成新范式:
1.1.传统的关键词预测任务范式:
传统的关键词预测任务定义为一个元组:(文档 X \mathcal{X} X,参考集 Y \mathcal{Y} Y)。给定 X \mathcal{X} X,模型直接生成所有关键词假设,目标是逼近 Y \mathcal{Y} Y。
1.2.本文提出的按需生成关键词任务范式:
为了按需生成关键词,引入了一个开放词汇目标短语 g g g,它描述了用户指定的关键词类别。因此,该模型的目标是根据 ( X , g ) (\mathcal{X},g) (X,g)生成一组关键词,以近似符合目标的关键词集合 Y g ⊆ Y \mathcal{Y}_{g}\subseteq\mathcal{Y} Yg⊆Y 。
2.基准数据集的构造方法和流程:
为了收集高质量的目标,设计了一个环中模型注释流水线,将 GPT-4 与人类注释者相结合,从关键词注释中反向推断目标,具体分为以下四个步骤:
2.1.Keyphrase Annotation by Human(人工关键词注释):
给定文档 X \mathcal{X} X,人工注释者指定所有可能的关键词集合 Y \mathcal{Y} Y。
2.2.Goal Proposal(目标建议):
指示 GPT-4 为每个关键词提出一个高级目标,多个关键词可以共享同一个目标。具体来说,给定 X , Y \mathcal{X},\mathcal{Y} X,Y,GPT-4 会返回一个从目标到关键词的映射。
2.3.Goal Abstraction(目标抽象):
在上一步之后,虽然提出的目标是相关的,但发现它们有时过于具体。因此,指示 GPT-4 进行一轮自我提炼,即尝试为上一轮中的每个目标提出一个更抽象的版本,或者保留原来的目标(如果它们已经足够高级)。
2.4.Human Validation(人工验证):
定性地发现,两次 GPT-4 注释迭代的输出结果足够抽象和多样化。为了进一步提高目标的质量并减少重复,两位作者进行了一轮筛选,以获得最终的目标注释。
3.Irrelevant Goal Sampling(负相关目标样本构造算法):
为了测试关键词生成模型在不相关的目标下避免生成关键词的能力,为每篇文档额外构建了一组不相关的目标。具体来说,对标注数据中的目标进行聚类,并以每个文档的现有目标为锚,对可能与该文档无关的目标进行抽样,因此该文档不太可能存在与抽样目标相对应的关键词。
具体来说,将同一数据集中的所有现有目标汇集为统一目标集,并利用短语嵌入模型嵌入所有短语。然后,对于文档中的每个目标,将其作为锚来检索 d% 的最不相似目标。在所有数据集中使用 d = 50。
- 根据这些目标在最终数据集中作为相关目标出现的频率分布,从这些目标中抽取一个与文档无关的目标作为无关目标。
- 此外,还设计了一个频率匹配约束,强制要求目标 g 作为无关目标出现的频率不能超过其作为相关目标出现的频率。
在实际操作中,首先应用频率匹配约束。如果没有符合条件的目标,就根据频率从相差最大的 d% 目标中抽取一个目标。
4.微调多任务的序列模型:
采用了一种新颖的方法来训练序列到序列模型,以自动回归(1)评估目标的相关性和(2)联合考虑文档以及预期目标来预测关键词。
具体来说,将按需生成关键字词作为两个标记预测任务的分层组合。在编码器中输入文档后,编码器首先建立 P(gi|X)模型,即 gi 成为真实用户提出的高质量相关目标的可能性。该模型用 P (<n/a>|X , gi ) 来表示这种概率,这是一种用于拒绝非相关目标的特殊标记。如果目标被确定为相关,模型就会根据所学到的分布 P (Ygi |X , gi ) 继续生成关键词。
推理:使用前缀控制解码来进行推理。gi 之后是一个特殊的端到目标标记 ,它被固定为解码器的生成起点。然后,我们使用自回归解码,让模型自我评估目标的相关性,并自动决定要生成的关键词。
训练:我们设计了一种多任务学习方法,在 P (<n/a>|X , gi) 和 P (Ygi |X , gi) 上直接监督模型,并混合使用相关和不相关的目标。由于用户提供的目标可能是任意的,因此我们不直接监督 P (gi |X ) 上的模型。
5.LLM提示生成关键词:
由于按需提取关键词可以很容易地表述为一项遵循指令的任务,因此研究了 LLMs 作为一种无监督方法的潜力。从一个判断目标相关性的简单指令开始:
根据文档的标题和摘要,决定是否应该拒绝高级分类。可以使用高级分类来编写文档中的关键词。
Decide if you should reject the high-level category given the title and abstract of a document. One could use the high-level category to write keyphrases from the document.
以及根据目标生成关键词的另一条指令:
从给定文本中生成属于高级类别的现有和不存在的关键词。
Generate present and absent keyphrases belonging to the high-level category from the given text.
LLMs可能存在的问题:
初步实验表明,第一条指令在决定目标相关性方面已经取得了很好的效果,甚至接近有监督模型。然而,在生成关键词时,LLMs 会将这项任务误解为命名实体提取:它们通常会生成一个几乎详尽无遗的目标相关实体列表。
为了纠正这种行为,假设 LLMs 倾向于在预测序列的较早位置更频繁地生成突出实体。设计了一种新颖的自一致性解码过程,利用 LLMs 样本中的等级和频率信息,筛选出编码最重要信息的短语。
具体来说,使用相同的指令和输入,从 LLM 中独立采样 K K K 预测序列 ( s 1 , . . . , s K ) (s_{1},...,s_{K}) (s1,...,sK),其中每个序列包含不同数量的关键词。然后,对于每个关键词 p p p,将其显著性得分定义为
s c o r e ( p ) = f r e q ( p ) K × f r e q ( p ) ∑ i = 1 , . . . , K r a n k ( s i , p ) , score(p)=\frac{freq(p)}{K}\times\frac{freq(p)}{\sum_{i=1,...,K}rank(s_{i},p)}, score(p)=Kfreq(p)×∑i=1,...,Krank(si,p)freq(p),
3.原文阅读
Abstract
传统的关键词预测方法只能为每篇文档提供一组关键词,无法满足用户和下游应用的不同需求。为了弥补这一差距,我们引入了按需生成关键词的方法,这是一种新颖的范式,它要求关键词符合特定的高层次目标或意图。为了完成这项任务,我们提出了 METAKP,这是一个大型基准,包括四个数据集、7500 个文档和 3760 个目标,涉及新闻和生物医学领域,并带有人类标注的关键词。利用 METAKP,我们设计了监督和非监督方法,包括多任务微调方法和使用大型语言模型的自一致性提示方法。结果凸显了有监督微调方法面临的挑战,因为这种方法的性能对分布变化并不稳定。相比之下,我们提出的自一致性提示方法大大提高了大型语言模型的性能,使 GPT-4o 的 SemF1 达到 0.548,超过了完全微调的 BART 基础模型的性能。最后,我们展示了我们的方法作为通用 NLP 基础架构的潜力,例如它在社交媒体流行病事件检测中的应用。
1 Introduction
关键词预测是一项吸引了长期研究兴趣的 NLP 任务(Witten 等人,1999 年;Hulth,2003 年;Meng 等人,2017 年)。给定来自学术写作、新闻、社交媒体或会议等不同领域的文档,关键词提取和关键词生成模型会输出短语,旨在概括文档中提到的关键实体和概念。除了一些信息检索应用(Kim等人,2013年;Tang等人,2017年;Boudin等人,2020年)之外,关键词预测方法还被广泛纳入其他NLP任务的管道中,如自然语言生成(Yao等人,2019年;Li等人,2020年)、文本摘要(Dou等人,2021年)和文本分类(Berend,2011年)。
介绍关键词抽取面临的问题:
现有的关键词预测方法尽管广泛应用于不同的场景,对关键词的类型也有不同的要求,但一般都遵循一个次优假设:对于每篇文档,模型都应预测一组与应用无关的关键词,然后根据一组单一的参考文献进行评估(Wu 等,2023b)。这种 "一刀切 "的方法既无法满足下游应用对关键词预判定的主题和具体程度的不同要求,也无法满足具有不同背景的人类用户的不同期望。为了妥善处理这些不同的反馈,目前的方法只能依赖于抽样重排策略(Zhao 等,2022;Wu 等,2023a),这在很大程度上是低效的。此外,单一参考设置也会使关键词预测模型的内在评估出现偏差,因为关键词标签中的高频主题可能会大大超过长尾关键词。
引出本文提出的解决范式,即需生成关键词:
为了应对这些挑战,我们提出了 “按需生成关键词”(on-demand keyphrase generation)这一新颖的范式,该范式以 “目标短语”(goal phrase)为条件预测关键词,"目标短语 "指定了关键词的高级类别或意图(图 1)。对于现有的关键词预测模型来说,这项任务极具挑战性,因为它要求预测不仅要捕捉关键信息,还要符合目标。此外,这些模型还需要接受开放词汇目标,这比使用预定义类别或本体预测关键词要高出一大步[14]。

本文提出的解决该范式的方法:
为了测试这项新任务,我们精心策划并发布了 MetaKP,这是一个大规模按需关键词生成基准,涵盖新闻和生物医学文本领域的四个数据集、7500 个文档和 3760 个独特目标。我们建立了一个可扩展的标注管道,该管道结合了 GPT-4 [1] 和人类标注者,可从关键词中构建高质量的目标(图 2)。为了进行评估,我们设计了两项任务:判断目标的相关性和生成符合目标的关键词。对于后者,我们采用最先进的评估方法 [23] 进行基于语义的评估。
通过使用 MetaKP,我们开发出了按需生成关键词的有监督和无监督方法。在监督方法中,我们设计了一种多任务微调方法,使序列到序列的预训练语言模型能够自我确定目标的相关性,并有选择地生成关键词(第 4.1 节)。然后,在第 4.2 节中,我们介绍了一种无监督自一致性提示方法,该方法利用了大型语言模型(LLM)提出与目标相关的候选关键词的强大能力,以及它们预测具有更高频率和等级的高质量关键词的倾向。综合实验揭示了以下观点:
- MetaKP 是一个具有挑战性的关键词生成基准。最强的微调模型 Flan-T5-XL 在所有数据集上的平均满意率仅为 0.609,而强 LLM 的零点提示 GPT-4o 的满意率仅为 0.492。
- 所提出的微调方法可以联合学习目标相关性判断和关键词生成,而不会影响每个任务的性能(第 5.3 节)。
- 所提出的自一致性提示方法大大提高了 LLM 的性能,使 GPT-4o 达到了 0.548 SemF1,超过了完全微调的 BART 基础模型的性能。
- 有监督的微调可能无法泛化分布外测试数据。相比之下,基于 LLM 的无监督方法在所有领域都取得了一致的性能,尤其是在新闻领域,GPT-4o 在分布外测试中比监督 Flan-T5-XL 高出 19%。
最后,我们展示了按需生成关键词作为通用 NLP 基础设施的潜力。具体来说,我们使用流行病预测的事件检测作为测试平台。通过从事件本体中构建简单的目标,并尝试从社交媒体文本中提取相关的关键词,我们证明了按需关键词生成模型在提取流行病相关趋势方面的潜力,类似于在特定任务数据上训练的事件检测模型。基准和实验代码将发布在 https://github.com/uclanlp/MetaKP,以促进进一步的研究。
2 Related Work
keyphrase prediction with types:
这项工作与之前关于用预定义类型或类别对关键词建模的工作密切相关。早期的数据集通常来自命名实体识别,其中关键词的跨度与实体类型标签相关(QasemiZadeh 和 Schumann,2016;Augenstein 等人,2017;Luan 等人,2018)。著名的建模方法包括使用中间任务训练强大且可转移的编码器表征(Park 和 Caragea,2020 年)以及多任务微调(Park 和 Caragea,2023 年)。此外,现有文献还探索了诱导高级类型变量以实现更准确的关键词预测,如主题引导的关键词生成(Wang 等人,2019;Zhang 等人,2022a)、分层关键词生成(Wang 等人,2016;Chen 等人,2020;Zhang 等人,2022b)以及关键词补全(Zhao 等人,2021)。与这些先前的工作相比,我们的基准具有大量的开放词汇目标,覆盖领域广泛。我们设计了新颖的监督和非监督建模方法,其中考虑到了大型语言模型等最新技术。
On-demand information extraction:
我们的工作与最近为信息提取设计灵活公式的趋势不谋而合。例如,Zhong 等人(2021 年)为摘要任务提出了一种以查询为中心的公式,Zhang 等人(2023 年)进一步扩展了该任务,使其包括五个约束条件:长度、提取度、特定性、主题和发言人。最近,Jiao 等人(2023 年)提出了按需信息提取,要求模型通过从相关文本中提取信息并以表格格式组织信息来回答查询。相比之下,本研究开创性地定义了关键词预测模型的目标跟踪能力,并对其进行了基准测试。我们的资源和方法为用户可控的关键词系统和灵活的概念提取基础设施奠定了基础。
3 MetaKP Benchmark
本节将阐述按需生成关键词的任务,并介绍 MetaKP 评估基准。
3.1.Problem Formulation
传统的关键词预测任务范式:
传统的关键词预测任务定义为一个元组:(文档 X \mathcal{X} X,参考集 Y \mathcal{Y} Y)。给定 X \mathcal{X} X,模型直接生成所有关键词假设,目标是逼近 Y \mathcal{Y} Y。
本文提出的按需生成关键词任务范式:
为了按需生成关键词,我们引入了一个开放词汇目标短语 g g g,它描述了用户指定的关键词类别。因此,该模型的目标是根据 ( X , g ) (\mathcal{X},g) (X,g)生成一组关键词,以近似符合目标的关键词集合 Y g ⊆ Y \mathcal{Y}_{g}\subseteq\mathcal{Y} Yg⊆Y 。
对新范式的图解:
图 1 提供了一个直观的任务示例。我们注意到,对于不相关的目标, Y g = ϕ \mathcal{Y}_{g}=\phi Yg=ϕ,这意味着理想的模型在给定此类目标时不应该生成任何关键词。此外,尽管 m a t h c a l Y g mathcal{Y}_{g} mathcalYg 会根据目标的不同而变化,但假设关键字的通用集合 m a t h c a l Y mathcal{Y} mathcalY 一般是固定的。换句话说, g g g 可以被视为一个查询,它指定了 Y \mathcal{Y} Y 中的一个目标子集,这就为建模设计提供了广泛的选择。
3.2.Benchmark Creation Pipeline
基准数据的构造:
为了评估按需关键词生成,我们策划了一个大规模多领域评估基准–MetaKP。关键的挑战在于构建通用、有意义和多样化的目标,以反映文档索引和搜索引擎等真实世界场景中的高级关键词类型。为了收集高质量的目标,我们设计了一个环中模型注释流水线,将 GPT-4 (OpenAI,2023 年)与人类注释者相结合,从关键词注释中反向推断目标(图 2),具体分为以下四个步骤。
Keyphrase Annotation by Human(人工关键词注释):
给定文档 X \mathcal{X} X,人工注释者指定所有可能的关键词集合 Y \mathcal{Y} Y。对于 MetaKP,我们直接利用专家从各自的关键词预测数据集中整理出的关键词。
Goal Proposal(目标建议):
我们指示 GPT-4 为每个关键词提出一个高级目标,多个关键词可以共享同一个目标。具体来说,给定 X , Y \mathcal{X},\mathcal{Y} X,Y,GPT-4 会返回一个从目标到关键词的映射。我们在附录 A 中介绍了这一步骤的提示。
Goal Abstraction(目标抽象):
在上一步之后,每个关键词都有一个相关的目标草案。虽然提出的目标是相关的,但我们发现它们有时过于具体。因此,我们指示 GPT-4 进行一轮自我提炼,即尝试为上一轮中的每个目标提出一个更抽象的版本,或者保留原来的目标(如果它们已经足够高级)。这一步骤的完整提示见附录 A。
Human Validation(人工验证):
我们定性地发现,两次 GPT-4 注释迭代的输出结果足够抽象和多样化。为了进一步提高目标的质量并减少重复,两位作者进行了一轮筛选,以获得最终的目标注释。由于这一步不需要添加新的目标,因此注释者之间按照注释指南达成了很高的一致(详见下一节),我们在附录 A 中介绍了该指南。最后,我们为每个过滤后的目标创建一个实例,形式为 ( X , g i , Y g i ) (\mathcal{X},g_{i},\mathcal{Y}_{g_{i}}) (X,gi,Ygi)。
3.3.Dataset Statistics
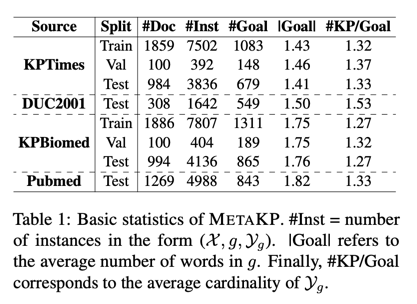
我们在四个关键词预测数据集上执行了上述目标构建管道,这四个数据集涵盖两个领域:新闻和生物医学文本。对于每个领域,我们都创建了一个分布内和分布外测试集。
KPTimes Gallina 等人(2019)是新闻领域的大规模关键词生成数据集。文件来源于《纽约时报》,关键词由专业编辑策划。
DUC2001 Wan 和 Xiao(2008 年)是一个广泛使用的关键词提取数据集,其中的新闻文章来自 TREC-9,并配以人工标注的关键词。
KPBiomed Houbre 等人(2022 年)是一个大型数据集,包含 PubMed 摘要与论文作者自己注释的关键词配对。
Pubmed Schutz (2008) 是生物医学领域的传统关键词提取数据集,其中包含从 PubMed 中心提取的文档和关键词。
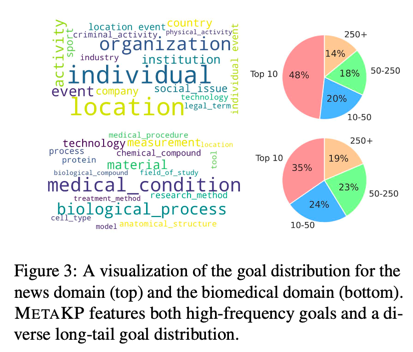
我们利用这些数据集分别策划了一个测试集,并从 KPTimes 和 KPBiomed 的训练集中抽样构建了两个特定领域的训练/验证集。表 1 和图 3 列出了最终数据集的基本统计数据。METAKP 的优势之一是覆盖领域广泛:数据集共涵盖 3760 个独特的目标,包括不同的主题和科目。虽然 40% 的实例对应于每个领域中最流行的 10 个目标,但也有相当数量的目标属于长尾分布,这对理解目标语义提出了新的重大挑战。
为了构建 MetaKP,两阶段 GPT-4 注释花费了大约 500 美元,人类注释者总共花费了大约 80 个小时进行最终数据筛选。我们从 KPTimes 和 KPBiomed 中各随机抽取 50 篇文档,注释者之间的一致性达到 0.699 Cohen’s Kappa。然后,注释者分别处理其余文档。如果发现有歧义的情况,则进行讨论以达成一致。
Irrelevant Goal Sampling(负相关目标样本构造算法):
为了测试关键词生成模型在不相关的目标下避免生成关键词的能力,为每篇文档额外构建了一组不相关的目标。具体来说,我们对标注数据中的目标进行聚类,并以每个文档的现有目标为锚,对可能与该文档无关的目标进行抽样,因此该文档不太可能存在与抽样目标相对应的关键词。
3.4 Evaluation Metric
通过 METAKP,我们设计了两个任务来综合评估模型按需生成关键词的能力。
Goal Relevance Assessment(目标相关性评估):
这项任务旨在测试模型能否正确区分无法生成任何关键词的非相关目标和相关目标。正如我们将在第 6 节中介绍的那样,这项技能对于按需关键词生成模型的广泛应用也至关重要。借鉴最近关于弃权的文献(Feng 等人,2024 年),我们使用Abstain F1 作为评价指标,它被定义为拒绝为无关目标生成关键词的模型的预搜索率和召回率的调和平均值。
Goal-Oriented Keyphrase Generation(面向目标的关键词生成):
给定文档 X、目标列表 g1、g2、…、gn 和参考文献 Yg1、Yg2、…、Ygn,我们用两个指标来评估模型的预测结果 P1、P2、…、Pn:
- 参考协议,评估模型生成与目标 gi 相对应的关键词的能力。具体来说,我们按照 Wu 等人(2023b)的方法计算并报告 SemF1(Ygi , Pi )。
- 满意率(SR):评估模型生成高质量关键词的频率。具体来说,我们计算并报告 SR((Yg1,P1),…,(Ygn,Pn)),即 SemF1(Ygi , Pi) 大于阈值的目标百分比。
4.Modeling Approach
在本节中,我们将介绍两种用于按需生成关键词的建模方法:一种是用于微调序列到序列预训练语言模型的多任务学习方法,另一种是用于提示大型语言模型(LLM)的自一致性解码方法。
4.1.Multi-Task Supervised Fine-tuning
微调多任务的序列模型:
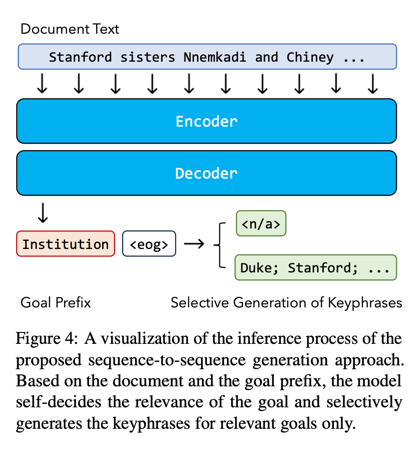
之前的文献已经证明了微调序列到序列预训练语言模型用于关键词生成的有效性(Kulkarni 等人,2022;Wu 等人,2022,2023a)。然而,目前还不清楚如何将这些序列预测方法用于按需关键词生成。为了弥补这一差距,我们采用了一种新颖的方法来训练序列到序列模型,以自动回归(1)评估目标的相关性和(2)联合考虑文档以及预期目标来预测关键词。
具体来说,我们将按需生成关键字词作为两个标记预测任务的分层组合。如图 4 所示,在编码器中输入文档后,编码器首先建立 P(gi|X)模型,即 gi 成为真实用户提出的高质量相关目标的可能性。该模型用 P (<n/a>|X , gi ) 来表示这种概率,这是一种用于拒绝非相关目标的特殊标记。如果目标被确定为相关,模型就会根据所学到的分布 P (Ygi |X , gi ) 继续生成关键词。
推理:我们使用前缀控制解码来进行推理。gi 之后是一个特殊的端到目标标记 ,它被固定为解码器的生成起点。然后,我们使用自回归解码,让模型自我评估目标的相关性,并自动决定要生成的关键词。
训练:我们设计了一种多任务学习方法,在 P (<n/a>|X , gi) 和 P (Ygi |X , gi) 上直接监督模型,并混合使用相关和不相关的目标。由于用户提供的目标可能是任意的,因此我们不直接监督 P (gi |X ) 上的模型。
备注:我们注意到所提出的方法有几个优点。首先,目标相关性评估和关键词预测过程都简化为一个序列预测过程,无需单独的架构或推理过程。其次,由于 gi 不被输入到编码器中,我们的模型避免了目标被冗长的输入上下文冲淡,并通过重复使用编码的输入表示来预测具有不同目标的关键词,从而实现了高效推理。
4.2.Prompting Large Language Models
根据人类指令进行调整的大型语言模型(LLMs)已被证明能够很好地适应通过人类查询定义的大量任务(欧阳等人,2022;OpenAI,2023)。它们还被证明能实现令人满意的关键词提取或关键词生成性能,尤其是在基于语义的评估方面(Song 等人,2023 年;Wu 等人,2023 年)。由于按需提取关键词可以很容易地表述为一项遵循指令的任务,因此我们研究了 LLMs 作为一种无监督方法的潜力。我们从一个判断目标相关性的简单指令开始:
根据文档的标题和摘要,决定是否应该拒绝高级分类。可以使用高级分类来编写文档中的关键词。
Decide if you should reject the high-level category given the title and abstract of a document. One could use the high-level category to write keyphrases from the document.
以及根据目标生成关键词的另一条指令:
从给定文本中生成属于高级类别的现有和不存在的关键词。
Generate present and absent keyphrases belonging to the high-level category from the given text.
LLMs可能存在的问题:
我们的初步实验表明,第一条指令在决定目标相关性方面已经取得了很好的效果,甚至接近有监督模型(第 5.2 节)。然而,在生成关键词时,LLMs 会将这项任务误解为命名实体提取:它们通常会生成一个几乎详尽无遗的目标相关实体列表。为了纠正这种行为,我们假设 LLMs 倾向于在预测序列的较早位置更频繁地生成突出实体。受 Wang 等人(2023 年)的启发,我们设计了一种新颖的自一致性解码过程,利用 LLMs 样本中的等级和频率信息,筛选出编码最重要信息的短语。
具体来说,使用相同的指令和输入,我们从 LLM 中独立采样 K K K 预测序列 ( s 1 , . . . , s K ) (s_{1},...,s_{K}) (s1,...,sK),其中每个序列包含不同数量的关键词。然后,对于每个关键词 p p p,我们将其显著性得分定义为
s
c
o
r
e
(
p
)
=
f
r
e
q
(
p
)
K
×
f
r
e
q
(
p
)
∑
i
=
1
,
.
.
.
,
K
r
a
n
k
(
s
i
,
p
)
,
score(p)=\frac{freq(p)}{K}\times\frac{freq(p)}{\sum_{i=1,...,K}rank(s_{i},p)},
score(p)=Kfreq(p)×∑i=1,...,Krank(si,p)freq(p),
其中,
f
r
e
q
(
p
)
freq(p)
freq(p) 返回
p
p
p 在所有样本中出现的频率,
r
a
n
k
(
s
i
,
p
)
rank(s_{i},p)
rank(si,p) 返回
p
p
p 在
s
i
s_{i}
si 中的排名(从 1 开始),如果
p
∉
s
i
p\notin s_{i}
p∈/si,则返回 0。第一项奖励在样本中经常出现的关键词,第二项奖励等级较高的关键词。无论样本数量多少,也无论模型在每个样本中生成的关键词数量多少,得分范围都是 0 到 1。最后,我们采用阈值过滤法,只保留分数(p)大于或等于阈值
τ
\tau
τ的高质量关键词。
5 Experiments
5.1.Experimental Setup
监督微调(Supervised Fine-tuning):利用提出的目标,我们对四个序列到序列模型进行了微调:BART-base/large(Lewis 等人,2020 年)和 Flan-T5-large/XL (Longpre 等人,2023 年),规模从 1.4 亿到 3B 不等。我们使用批量大小 64、学习率 3e-5、亚当优化器和 50 warmup steps的线性衰减对模型进行 20 个历时训练。根据验证集上的关键词生成性能选择最佳模型检查点。
提示我们通过 OpenAI API 使用 gpt-3.5-turbo-0125 和 gpt-4o-2024-05-13 模型。我们将这两个模型分别命名为 GPT-3.5-Turbo 和 GPT-4o。我们使用单独的提示来进行目标相关性判断和按需生成关键词。第一个任务使用贪婪搜索。在第二项任务中,我们生成了 10 个 p = 0.95 和 temperature = 0.7 的样本。输出长度限制为 30 个 token,可容纳约 10 个关键词。最后,在过滤方面,我们对所有数据集都使用了 τ = 0.3 \tau=0.3 τ=0.3。
5.2 Main Results
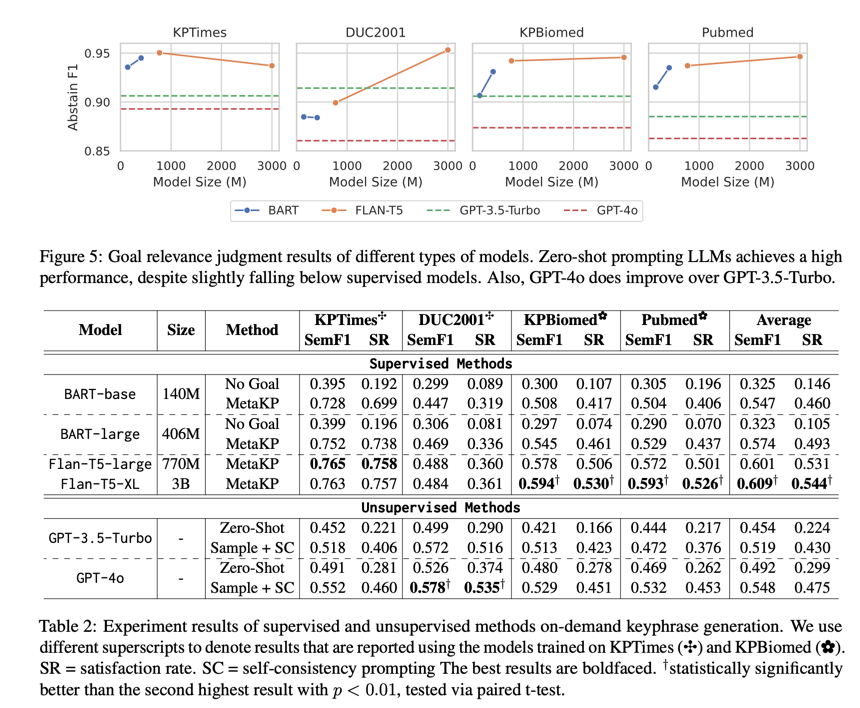
我们在图 5 和表 2 中列出了这两项任务的主要结果。
目标相关性评估:根据图 5,我们发现有监督微调和无监督提示在评估是否有目标方面都达到了很高的性能,所有数据集的弃权F1 分数都超过了 0.85。随着模型规模的扩大,分布外性能更容易扩展,而分布内性能在 Flan-T5-large 时趋于平稳。在大型语言模型中,我们观察到了强大的性能,尤其是在 DUC2001 上,超过了在 KPTimes 上训练的 Flan-T5-large 的性能。
关键词生成:关键词生成的主要结果见表 2。对于有监督的方法,我们还加入了 "无目标 "基线,即对模型进行微调,以一次性生成同一文档的所有关键词。对于 BART-base 和 BART-large,该基线的性能都很低,这表明直接利用关键词生成模型来完成既定任务具有挑战性。相比之下,所提出的目标导向微调方法大大提高了性能,最佳的 Flan-T5-XL 模型达到了 0.609 SemF1 和 0.544 满意率。另一方面,与无目标训练的自一致性模型相比,直接进行零点提示的大型语言模型已经取得了更优越的性能。所提出的自一致性进一步大幅提高了性能,使 GPT-4o 实现了 0.548 SemF1 和 0.475 满意率。值得注意的是,结果表明基于 LLM 的方法具有更强的通用性。在 DUC2001 上,所有基于 KPTi- mes 训练的监督模型都表现不佳。相比之下,GPT-3.5-Turbo 和 GPT-4o 能够超越所有监督模型的性能。
5.3.Analyses
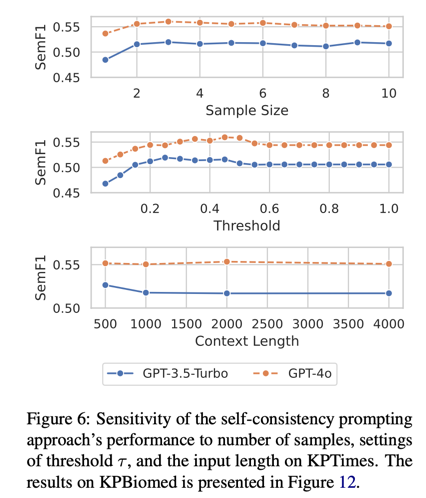
哪个参数对 LLM 的影响最大?
在图 6 中,我们使用 KPTimes 的验证集来研究基于 LLM 的方法对三个超参数的敏感性:样本数量( K K K)、阈值 τ \tau τ 和输入的上下文长度。虽然多个样本对高性能至关重要,但两个样本之后的更多样本只能起到微不足道的作用。此外,我们的方法对阈值设置并不敏感–0.25 到 0.45 之间的多重设置可以获得最佳性能。最后,GPT-3.5-Turbo 在上下文较长的情况下性能略有下降,而 GPT-4o 对上下文长度的变化却很稳健。
多任务学习是否会损害单个任务的性能?
在表 3 中,我们基于有监督的训练损失,对 BART 进行了消减研究。在计算损失时,我们会屏蔽掉每个被消减部分的相应标记。总的来说,与只学习单个任务相比,将两个学习目标结合在一起并不会对性能造成明显损害,同时产生的计算开销也要小得多。事实上,在 KPTimes 上,这两个任务是建设性的–学习目标相关性有助于生成更好的符合目标的关键词,反之亦然。
6 MetaKP in the Wild: Event Detection
最后,我们以事件检测(ED)为案例,展示了按需生成关键词作为通用 NLP 基础设施的潜力。
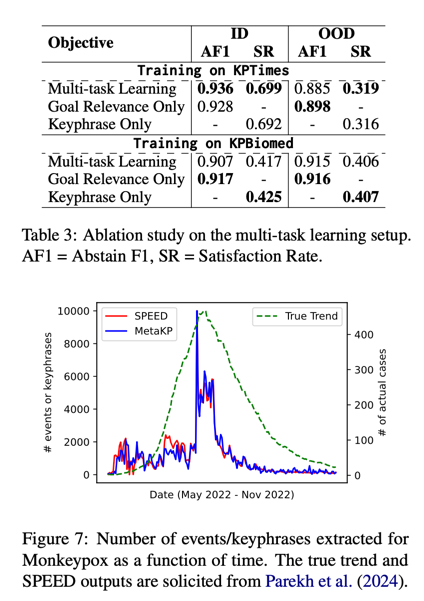
我们利用了 SPEED(Parekh 等人,2024 年)中使用的测试数据集,该数据集包含与 Monkeybox3 相关的有时间戳的社交媒体帖子。我们从 SPEED 本体论中整理出七个与流行病相关的目标:疾病感染、流行病传播、流行病预防、流行病控制、症状、疾病康复、流行病致死。然后,我们运行在 MetaKP 所有训练数据上训练的 FLAN-T5-large 模型,评估每个目标与每个社交媒体帖子的相关性。如果<n/a>跟随的概率大于 0.001,则判定该目标与帖子相关,因此相关事件很可能发生。
如图 7 所示,我们发现这种基于关键词的范式能够提取出与 SPEED(Parekh 等人,2024 年)训练的 ED 模型相似的趋势。直观地说,在给定一个包含 "接种疫苗 "的句子时,按需生成的关键词并不关注触发点 “接种”,而是更关注 “接种疫苗”,因为目标是 “流行病控制”。这样,按需关键词生成模型既可以自然地重新用于教育,也有望提取与该事件相关的辅助主题。
7.Conclusion
我们引入了按需关键词生成功能,以满足针对不同应用和用户需求的动态、以目标为导向的关键词预测需求。我们策划并推出了一个大规模、多领域、人工验证的基准 MetaKP。我们在 MetaKP 上设计并评估了有监督和无监督方法,突出了使用大型语言模型进行自一致性提示的优势。在领域转移的情况下,这种方法的性能明显优于传统的微调方法,从而展示了我们方法的鲁棒性和更广泛的适用性。最后,我们强调了按需关键词生成在流行病事件提取等实际应用中的多功能性,为作为通用 NLP 基础设施的关键词生成指明了新方向。
Limitations
在这项工作中,我们提出了新颖的按需关键词生成范式。未来,该范式和 MetaKP 基准的扩展将有几个令人兴奋的方向:
1.多语言关键词生成。MetaKP 仅涵盖英语数据。未来的一个重要方向是进一步确定基准并增强多语言和跨语言按需关键词生成能力。
2.更广泛的领域覆盖。我们主要关注新闻和生物医学文本领域,因为这两个领域已被证明是关键词生成的重要应用领域。
3.灵活的指令。在这项工作中,用户的 "需求 "一般被定义为关键词的主题或类别。不过,未来的工作可以将这一定义扩展到包括指定文体限制的需求,如关键词的数量、长度和格式。
Goal Proposal:
在图 8 中,我们展示了用于指示 GPT-4 从文件和人类注释的关键词中提出目标的提示。我们将文档正文截断为四句话,因为它的作用只是提供必要的上下文。LLM 收到的指令是为所有关键词提出所有目标,这有助于模型将具有相同目标的关键词组合在一起。
为每个关键词生成一个抽象类别。例如流程、任务、材料、工具、测量、模型、技术和度量等。不要局限于这些例子。确保这些类别在科学领域中信息丰富,并且看起来自然,就像由熟读的用户指定的一样。返回字典列表,每个字典有两个键–"关键词 "和 “类别”。如果两个关键词具有相同的类别,请确保它们被标注为相同的短语。不要改变关键词的显示方式,包括它们的大小写。只返回 json,不提供其他信息。
Negative sampling Algorithm:
为了构建用于评估模型剔除无关目标能力的训练和评估数据,我们设计了一种简单的算法来抽取无关目标。具体来说,我们将同一数据集中的所有现有目标汇集为统一目标集,并利用(Wu 等人,2023b)发布的短语嵌入模型嵌入所有短语。然后,对于文档中的每个目标,我们将其作为锚来检索 d% 的最不相似目标。我们在所有数据集中使用 d = 50。根据这些目标在最终数据集中作为相关目标出现的频率分布,我们从这些目标中抽取一个与文档无关的目标作为无关目标。此外,我们还设计了一个频率匹配约束,强制要求目标 g 作为无关目标出现的频率不能超过其作为相关目标出现的频率。在实际操作中,首先应用频率匹配约束。如果没有符合条件的目标,我们就根据频率从相差最大的 d% 目标中抽取一个目标。