Absformer: Transformer-based Model for Unsupervised Multi-Document Abstractive Summarization
Absformer: 基于transformer的无监督多文档抽象总结模型
paper: https://arxiv.org/abs/2306.04787
github:
本文提出了一种无监督的多文档抽象摘要总结模型,主要分为两个阶段:
阶段1:使用DistilBERT作为编码器来训练一个文档embedding模型,即对DistilBERT进行预训练,训练后的embedding被输入到kmeans中去完成聚类,或者使用监督方式训练一个分类器,已完成文档聚类。聚类后的文档将获取一个文档embedding和一个聚类中心emebdding。
阶段2:使用DistilBERT作为解码器,DistilBERT编码器的输出文档embedding并送入到DistilBERT解码器中,在训练阶段冻结编码器,其目标是根据输入的文档embedding去重建文档内容,即下一个词预测。
摘要生成:将阶段1聚类后的聚类中心embedidng作为解码器的输入,从而生成文本摘要
文章目录~
1.背景动机
文本摘要技术有助于高效地分析文本数据。重要信息可以从多个文档中总结出来,这就是多文档总结(MDS)。多种MDS 方法都依赖于大量的文档摘要对注释数据来进行监督训练。然而,在许多领域,这种有监督的数据并没有,且制作成本高。
介绍现有的MDS方法:
现有的 MDS 方法将 LSTM 和 GRU 等循环架构纳入基于自动编码器的架构中。BERT和 RoBERTa,通过利用 Transformer架构来解决多种任务,该架构已被证明能比递归架构更好地捕捉长程依赖关系。在无监督 MDS 设置中,基于 Transformer 的模型尚未被探索,因为真实摘要无法获取以用于训练端到端模型。
介绍本文提出的方法:
本文提出的_Absformer_是一种基于transformer的新型模型,用于无监督多文档_抽象_摘要。目标是为每组语义相似的文档预测由一组句子组成的摘要。
Absformer 是一种用于无监督 MDS 的两阶段方法:
- 在第一阶段,当没有给出划分标准时,使用无监督聚类算法将文档集划分为语义相似的文档组;当有标签信息时,使用监督分类法将文档组划分为语义相似的文档组。(将这一阶段称为基于嵌入的文档聚类,它需要一个经过预训练或微调的编码器来生成文档的嵌入)。
- 在第二阶段,我们使用新的基于transformer的解码器为每个聚类生成摘要。在训练阶段,解码器模型从冻结编码器获得的嵌入中生成文档。然后,使用训练好的解码器根据簇中心的嵌入生成摘要
2.MODEL
1.介绍无监督MDS任务:
给出多个文档 D = { d 1 , d 2 , … , d n } D=\{d_{1},d_{2},\ldots,d_{n}\} D={d1,d2,…,dn},其中 n n n 是文档总数。任务目标时为每组相似文档预测一个句子组成的摘要。在没有给出划分标准的情况下,应使用无监督聚类算法将文档集 D D D 划分为相似的组,在有标签信息的情况下,则应使用监督分类法。
无论使用哪种技术,都将相似文档的分组步骤称为文档聚类。文档聚类步骤会产生 K K K 的文档组 D = { g 1 , g 2 , … , g K } D=\{g_{1},g_{2},\ldots,g_{K}\} D={g1,g2,…,gK},其中每个组 g i g_{i} gi 都包含相似文档(文档聚类使用了硬分配,即 D$ 中的给定文档 d j d_{j} dj只能属于一个组)。
本文的目标是学习两个模型 F F F 和 N N N,其中 (1) F F F 用于文档聚类步骤;(2) N N N 用于为每个群组生成摘要。
2.介绍提出的Absformer流程:
Absformer一种基于 Transformer 的两阶段抽象 MDS 方法。第一阶段是文档聚类步骤,第二阶段是摘要生成步骤。
本文使用 DistilBERT来获取文档级表征。选择使用 DistilBERT 作为聚类和生成模型的有两个原因:
- 首先,DistilBERT比循环架构更能捕捉长程依赖关系。
- 其次,DistilBERT 的体积较小,性能与 BERT 相当,
2.1.Pretraining of Encoder,预训练DistilBERT:
使用mask语言建模(MLM)目标,屏蔽率为文档中 15%的子标记。预训练阶段结束后,预训练的 DistilBERT 将被用作编码器 F F F 来计算文档的表示
2.2.步骤1—基于文档的聚类embedding:
预训练 DistilBERT 模型 F F F 计算出的文档嵌入可以作为无监督聚类算法的输入,以获得语义相似文档的聚类。文档 d i d_{i} di 的表示形式为 R e p ( d i ) Rep(d_{i}) Rep(di):
R
e
p
(
d
i
)
=
[
CLS
]
x
1
x
2
…
x
n
i
[
SEP
]
(1)
Rep(d_{i})=[\text{CLS}]x_{1}x_{2}\ldots x_{n_{i}}[\text{SEP}] \tag{1}
Rep(di)=[CLS]x1x2…xni[SEP](1)
编码器
F
F
F 将一个文档
d
i
d_{i}
di 的表示形式(用
R
e
p
(
d
i
)
Rep(d_{i})
Rep(di) 表示)作为输入,以计算嵌入值
d
i
‾
∈
R
h
\overline{d_{i}}\in\mathbb{R}^{h}
di∈Rh,该嵌入值是
F
F
F 中 [CLS] 标记的隐藏状态提取的。
2.2.1.步骤1—Cluster Documents Without Label Information,无标签文档聚类:
基于DistilBERT的文档嵌入 o v e r l i n e D = { d 1 → , d 2 → , … , d n → } overline{D}=\{\overrightarrow{d_{1}},\overrightarrow{d_{2}},\ldots, \overrightarrow{d_{n}}\} overlineD={d1,d2,…,dn}被输入无监督聚类算法中,以获得 K K K文档聚类。本文使用 k-means 聚类算法。
经过聚类步骤,得到了 K K K 的文档簇 D = { g 1 , g 2 , … , g K } D=\{g_{1},g_{2},\ldots,g_{K}\} D={g1,g2,…,gK},其中每个簇是由来自 D D D 的 ∣ g i ∣ |g_{i}| ∣gi∣ 文档和一个聚类中心 C g i C_{g_{i}} Cgi 组成的。本文用 C g i ‾ \overline{C_{g_{i}}} Cgi表示k-means步骤得到的聚类嵌入。为了减少异常值的影响,计算每个文档的聚类权重,其值为
w
d
j
i
=
min
d
k
i
∈
g
i
d
i
s
t
(
C
g
i
,
d
k
i
)
d
i
s
t
(
C
g
i
,
d
j
i
)
(2)
w_{d_{j}^{i}}=\frac{\min_{d_{k}^{i}\in g_{i}}dist(C_{g_{i}},d_{k}^{i})}{dist( C_{g_{i}},d_{j}^{i})}\tag{2}
wdji=dist(Cgi,dji)mindki∈gidist(Cgi,dki)(2)
其中:
d
i
s
t
(
C
g
i
,
d
k
i
)
=
L
n
o
r
m
2
(
C
g
i
‾
,
d
k
i
‾
)
(3)
dist(C_{g_{i}},d_{k}^{i})=L_{norm}^{2}(\overline{C_{g_{i}}},\overline{d_{k}^{ i}}) \tag{3}
dist(Cgi,dki)=Lnorm2(Cgi,dki)(3)
L
n
o
r
m
2
(
v
1
,
v
2
)
L_{norm}^{2}(v_{1},v_{2})
Lnorm2(v1,v2) 表示两个向量
v
1
v_{1}
v1 和
v
2
v_{2}
v2 之间的Euclidean norm。然后,使用文档的簇级权重更新每个簇
g
i
g_{i}
gi 的中心嵌入
C
g
i
‾
\overline{C_{g_{i}}}
Cgi:
C
g
i
‾
=
∑
j
=
1
∣
g
i
∣
w
d
j
i
d
j
i
‾
∑
j
=
1
∣
g
i
∣
w
d
j
i
(4)
\overline{C_{g_{i}}}=\frac{\sum_{j=1}^{|g_{i}|}w_{d_{j}^{i}}\overline{d_{j}^{ i}}}{\sum_{j=1}^{|g_{i}|}w_{d_{j}^{i}}}\tag{4}
Cgi=∑j=1∣gi∣wdji∑j=1∣gi∣wdjidji(4)
从编码器
F
F
F 中获得的文档和中心embedding将被输入到摘要生成步骤,并在摘要生成训练和推理过程中保持冻结。
2.2.2.步骤1—Cluster Documents With Label Information,有标签信息的文档聚类:
在微调阶段,D中的每个文档 d i ∈ D d_{i}\in D di∈D都与L中的标签 l i ∈ L l_{i}\in L li∈L相关联,其中 L L L是标签集。预训练的 DistilBERT 模型被用作编码器 F F F,微调一个分类层,该分类层的维度为 L L L的标签数
与不带标签信息的文档聚类类似,每个簇都应与一个簇中心相关联,每个文档都应属于一个簇,并有一个成员权重,以减少异常值的影响。对于给定的文档 d i d_{i} di,将其预测的概率作为权重
第二步是预测 d i d_{i} di 的聚类(用 c i c_{i} ci 表示)和成员权重(用 w i \text{w}_{i} wi 表示):
c
i
=
argmax
l
∈
L
p
i
[
l
]
w
i
=
max
l
∈
L
p
i
[
l
]
(7)
c_{i}=\operatorname*{argmax}_{l\in L}p_{i}[l]\ \\ w_{i}=\operatorname*{max}_{l\in L}p_{i}[l] \tag{7}
ci=l∈Largmaxpi[l] wi=l∈Lmaxpi[l](7)
聚类中心的计算方法与使用公式 (4) 对无标签信息的文档进行聚类的情况类似。最后,得到
∣
L
∣
|L|
∣L∣文档簇
D
=
{
g
1
,
g
2
,
…
,
g
∣
L
∣
}
D=\{g_{1},g_{2},\ldots,g_{|L|}\}
D={g1,g2,…,g∣L∣},其中每个簇
g
i
=
{
d
1
i
、
d
2
i
,
…
,
d
∣
g
i
∣
i
}
g_{i}=\{d_{1}^{i}、d_{2}^{i},\ldots,d_{|g_{i}|}^{i}\}
gi={d1i、d2i,…,d∣gi∣i} 由来自
D
D
D 的
∣
g
i
∣
|g_{i}|
∣gi∣ 文档和一个聚类中心
C
g
i
C_{g_{i}}
Cgi 组成。
2.3.步骤2—Summary Generation,摘要生成:
2.3.1.步骤2—Encoder-Decoder Model,编码-解码器:
在摘要生成训练过程中,编码器 F F F 应保持冻结状态,以保留文档和聚类中心嵌入。本文直接使用F输出的嵌入 { d 1 ‾ , d 2 ‾ , … , d n ‾ } \{\overline{d_{1}},\overline{d_{2}},\ldots,\overline{d_{n}}\} {d1,d2,…,dn}作为解码器模型的输入。
本文的解码器与基于DistilBERT的 F F F 具有相同的块数。为了将文档嵌入纳入解码过程,本文还在 Absformer 的解码器中加入了一个交叉注意层,类似于 T5 模型。
2.3.2.步骤2—Decoder Training,解码器训练:
解码器 N N N 是通过下一个标记预测任务来训练的。本文使用加权交叉熵损失来训练解码器 N N N,以便将训练重点放在重建接近聚类中心的文档上。形式上,大小为 B B B 的一批文档的解码器损失函数 L N L_{N} LN 由以下公式给出:
L N = − ∑ l ∈ B ∑ j = 1 T l w d l j + 1 l o g P ( t j ∣ t 0 j − 1 ) (9) L_{N}=-\sum_{l\in B}\sum_{j=1}^{T_{l}}w_{d_{l}^{j+1}}logP\left(t_{j}\mid t _{0}^{j-1}\right)\tag{9} LN=−l∈B∑j=1∑Tlwdlj+1logP(tj∣t0j−1)(9)
2.3.3.步骤2—Summary Decoding,摘要解码:
在训练解码器 N N N 从编码器 F F F 获得的嵌入中重建文档后,最后一步是生成每个聚类的摘要。
每个簇的中心 C g i ‾ \overline{C_{\mathbf{g_{i}}}} Cgi 被用作解码器 N N N 的输入。每个解码块的交叉注意头使用集群的中心嵌入 C g i ‾ \overline{C_{\mathbf{g_{i}}}} Cgi 来计算键和值矩阵,这样就能从最后一个解码块的输出中获得每个时间戳的集群感知嵌入。每个时间戳的输出嵌入被转发到解码器 N N N 的语言模型头,以计算所有词汇的概率分布。
3.数据集:
Amazon Reviews:该数据集包含从亚马逊产品数据集中提取的 6 类产品中收集的 3,461,603 条亚马逊评论。每条评论都附有 5 星评级。每种产品都有 30 条黄金摘要,
Yelp Reviews:该数据集包含 1,297,880 条评论。考虑了 7 类产品。
3.原文阅读
Abstract
多文档摘要(MDS)是指将多个文档中的文本总结为一个简明摘要的任务。生成的摘要能以几句话的形式提供重要内容,从而节省阅读多份文件的时间。抽象 MDS 的目的是利用自然语言生成技术为多个文档生成连贯流畅的摘要。在本文中,我们考虑了无监督抽象 MDS 的情况,即只有文档而没有提供真实摘要,我们提出了 Absformer,一种基于 Transformer 的无监督抽象摘要生成新方法。我们的方法包括两个步骤:第一步,使用掩码语言建模(MLM)目标作为预训练任务,对基于 Transformer 的编码器进行预训练,以便将文档聚类为语义相似的组;第二步,训练基于 Transformer 的解码器,为文档聚类生成抽象摘要。据我们所知,我们是第一个成功将基于 Transformer 的模型用于解决无监督抽象 MDS 任务的公司。我们使用来自不同领域的三个真实数据集对我们的方法进行了评估,结果表明,与基于抽象方法的最先进方法相比,我们的方法在评估指标方面有了实质性的改进,而且还能推广到来自不同领域的数据集。
1. Introduction
在这个大数据时代,文本数据的快速增长使得理解和挖掘这些数据成为一项非常耗时的任务。文本摘要技术有助于高效地分析文本数据。重要信息可以从多个文档中总结出来,这就是多文档总结(MDS)。多种基于深度学习(DL)的 MDS 方法都依赖于大量的文档摘要对注释数据来进行监督训练。然而,在许多领域,这种有监督的数据并不可用,而且制作成本高昂。因此,研究人员将重点放在了无监督学习环境上,在这种环境下,只有文档而没有真实摘要。无监督 MDS 的早期研究提出了基于提取的无监督 MDS 方法。随后,研究人员又致力于开发 MDS 的抽象方法,以生成信息量更大、更简洁的摘要。
介绍现有的MDS方法:
现有的 MDS 方法将 LSTM 和 GRU 等循环架构纳入基于自动编码器的架构中。近年来,人们提出了深度语境化语言模型,如 BERT和 RoBERTa,通过利用 Transformer架构来解决多种任务,该架构已被证明能比递归架构更好地捕捉长程依赖关系。特别是,基于 Transformer 的 seq2seq 模型在有监督的 MDS 中取得了最先进的结果。在无监督 MDS 设置中,基于 Transformer 的模型尚未被探索。例如,在基于自编码器的无监督 MDS 模型中加入 Transformer 仍然是一项具有挑战性的任务,因为真实摘要无法获取以用于训练端到端模型。因此,最先进的基于 Transformer 的端到端编码器-解码器模型,不能直接用于生成摘要。
介绍本文提出的方法:
我们提出的_Absformer_是一种基于transformer的新型模型,用于无监督多文档_抽象_摘要。我们的目标是为每组语义相似的文档预测由一组句子组成的摘要。因此,Absformer 是一种用于无监督 MDS 的两阶段方法。在第一阶段,当没有给出划分标准时,我们使用无监督聚类算法将文档集划分为语义相似的文档组;当有标签信息时,我们使用监督分类法将文档组划分为语义相似的文档组。我们将这一阶段称为基于嵌入的文档聚类,它需要一个经过预训练或微调的编码器来生成文档的嵌入。我们的研究表明,根据标准的屏蔽语言建模(MLM)目标对编码器进行预训练,可以得到语义相似的文档聚类。此外,如果有用于微调编码器的标签信息,这些聚类还能得到增强。在第二阶段,我们使用新的基于变换器的解码器为每个聚类生成摘要。在训练阶段,解码器模型从冻结编码器获得的嵌入中生成文档。然后,使用训练好的解码器根据簇中心的嵌入生成摘要,这与之前的工作相同。Absformer 的一个重要设计选择是,编码器应在摘要生成训练期间保持冻结,以保留文档聚类信息中的文档和聚类中心嵌入。因此,与传统的文本到文本编码器-解码器模型相比,我们将编码器和解码器解耦,这样在第二阶段,Absformer 直接将嵌入层信息作为输入,而不是将标记层信息作为输入,并生成标记层序列作为输出。我们发现,使用冻结编码器的相应权重初始化 Absformer 解码器的嵌入层、解码器块和语言模型头,可以在生成摘要方面获得更好的结果,并在训练阶段更快地收敛。我们注意到,编码器和解码器的层数与 DistilBERT 相同,而 DistilBERT 的规模更小,性能与 BERT 相当,因为我们的目标是在保持合理的时间和内存复杂度的同时,获得准确的文档聚类和简明的摘要。
- 我们提出了一种基于transformer的新方法,称为 Absformer,用于无监督 MDS。Absformer 是一种分两个阶段的方法。在第一阶段,我们通过对编码器进行标准mask语言建模(MLM)目标的预训练,将初始文档集聚类为语义相似的文档组。当有标签信息时,可以对聚类进行增强,从而对编码器进行微调。
- 在第二阶段,我们会训练一个基于transformer的解码器模型,该模型会根据从冻结编码器中获得的嵌入生成文档。然后,利用训练好的解码器从聚类中心的嵌入式编码生成摘要。
- 为了提高 Absformer 的时间和记忆复杂度,我们在编码器和解码器上使用了与 DistilBERT 相同的架构。为了加快收敛速度,我们使用冻结编码器的相应权重初始化嵌入层、自关注和交叉关注的解码器块以及 Absformer 解码器的语言模型头。
- 我们在三个数据集(公共和内部文档语料库)上进行了实验,结果表明我们的新方法优于最先进的基于抽象的基线方法,并可推广到来自多个部门的文档集。
2.RELATED WORK
2.1.Multi-Document Summarization
多文档摘要(MDS)是指将多个文档中的文本总结为简明摘要的任务。根据是否有真实摘要,MDS 可分为两类:第一类是在训练阶段有真实摘要时,称为有监督 MDS ;第二类是在训练阶段没有真实摘要时,称为无监督 MDS。
现有的 MDS 总结方法可分为三类,即提取式总结、抽象式总结和混合式总结。提取式摘要技术从多个文档中选择突出部分,以形成简明摘要。提取方法通常由两部分组成:句子排序和句子选择。抽象 MDS的目的是利用自然语言生成技术为多个文档生成连贯流畅的摘要。混合式 MDS旨在结合提取式和抽象式摘要技术,以提高生成摘要的质量。
在过去几年中,基于 DL 的方法在文本、图像和语音数据方面取得了最先进的成果,在多项任务中取得了显著的改进。DL 模型经过端到端训练,可自动提取特征并建立模型。这大大减少了传统特征工程方法所需的人力,并使模型能够捕捉特定的特征,而这些特征在多个任务中都优于手工创建的特征。在 DL 模型取得成功后,研究人员开始专注于探索 MDS 中的 DL。不同的神经架构被用于 MDS。例如,递归架构,包括递归神经网络(RNN)、长短期记忆(LSTM)和门控递归单元(GRU),已被作为多种方法的主要组成部分[13, 14, 33, 74]。此外,卷积神经网络(CNN)也被纳入多种 MDS 方法中。最近,图神经网络的成功推动了包括 MDS 在内的各种任务的研究。
近年来,深度语境化语言模型,如 BERT、RoBERTa、DeBERTa和 DistilBERT,已被提出用于解决多种信息检索和自然语言处理(NLP)任务 。与传统的词嵌入不同,预训练的神经语言模型是上下文式的,一个标记的表示是整个句子的函数。
2.2.Unsupervised Multi-Document Summarization
对于无监督 MDS,早期的研究提出了基于提取的无监督 MDS 方法。随后,研究人员又集中开发了用于 MDS 的抽象方法。在多种无监督 MDS 方法中,LSTM 被用作主要组件。Chu 等人[13]提出了一种基于自动编码器的方法,称为Meansum,其中编码器和解码器都采用了 LSTM。Meansum 为固定数量的文档(8 个文档)生成摘要。Meansum 的摘要处理流程首先是对基于 LSTM 的编码器获得的文档嵌入进行平均,以计算摘要的嵌入。然后,生成的嵌入被转发给基于 LSTM 的解码器,以生成摘要。编码器和解码器的训练使用两个损失函数进行监控,即平均摘要相似性损失和自动编码器重建损失。前者限制生成的摘要在语义上与原始文档相似,后者指导 Meansum 使用带有教师强迫的序列到序列交叉熵损失来重建原始文档。
在 Coavoux 等人提出的方法中,LSTM 也被用作主要组成部分。作者提出了一种无监督抽象概括神经模型,用于对产品评论进行观点概括。该方法采用基于方面的聚类技术,将涉及相同方面的评论进行分组。然后,基于 LSTM 的解码器为每个方面生成摘要。解码器由聚类表示初始化,以便生成作为摘要的标记序列。聚类表示是使用每个聚类中最突出句子的嵌入平均值计算得出的。突出度分数是使用聚类模型确定的,该模型为评论中的每个句子分配一个置信度分数。对于摘要解码,采用 top-k 抽样解码来预测下一个标记。
Amplayo 等人提出了一种名为 DenoiseSum 的方法,在这种方法中,去噪自编码器被用于无监督摘要生成。使用单词、句子和文档级噪声技术创建多个噪声版本的评论。在编码器和解码器中都使用了 LSTM 来获取上下文嵌入,从而对评论进行去噪并生成摘要。
多种无监督 MDS 方法采用变异自动编码器 (VAE) 模型生成摘要。Brazinskas 等人[7]提出了一种基于 VAE 的模型,称为 CopyCat,用于意见摘要。CopyCat 使用两种损失函数进行训练:一种是重建损失,用于从潜在表征中恢复原始评论;另一种是 Kullback-Leibler (KL) 发散,用于惩罚计算后验与前验的偏差。在生成阶段,对评论的潜在向量进行平均,计算出摘要表示,然后对摘要表示进行解码,生成摘要标记。
Iso 等人[26]的研究表明,平均聚合会造成摘要退化问题,导致摘要泛滥。作者提出了一种名为 "凸聚合意见摘要(COOP)"的方法,该方法计算评论潜向量的加权平均值作为摘要表示,权重的估计是为了最大化生成摘要与评论之间的词语重叠。Nguyen 等人[45]提出了一种基于特定类别 VAE 的无监督评论摘要模型。该模型使用一个独立的分类器,将每篇评论归入预定义的类别。Isonuma 等人[27]使用递归高斯混合物对潜在空间中的句子粒度进行建模,并生成多种粒度的摘要。
3. Problem Statement
介绍无监督MDS任务:
在无监督 MDS 中,给出多个文档 D = { d 1 , d 2 , … , d n } D=\{d_{1},d_{2},\ldots,d_{n}\} D={d1,d2,…,dn},其中 n n n 是文档总数。任务包括为每组相似文档预测由一组句子组成的摘要。这意味着,在没有给出划分标准的情况下,应使用无监督聚类算法将文档集 D D D 划分为相似的组,在有标签信息的情况下,则应使用监督分类法。在本文的其余部分,无论使用哪种技术,我们都将相似文档的分组步骤称为文档聚类。文档聚类步骤会产生 K K K 的文档组 D = { g 1 , g 2 , … , g K } D=\{g_{1},g_{2},\ldots,g_{K}\} D={g1,g2,…,gK},其中每个组 g i g_{i} gi 都包含相似文档(文档聚类步骤中使用了硬分配,这意味着 D$ 中的给定文档 d j d_{j} dj 只能属于一个组)。
我们的目标是学习两个模型 F F F 和 N N N,其中 (1) F F F 用于文档聚类步骤,以便分割输入空间;(2) N N N 用于为文档聚类步骤中获得的每个群组生成一个连贯的摘要。
4. Absformer: Document Clustering
介绍提出的Absformer流程:
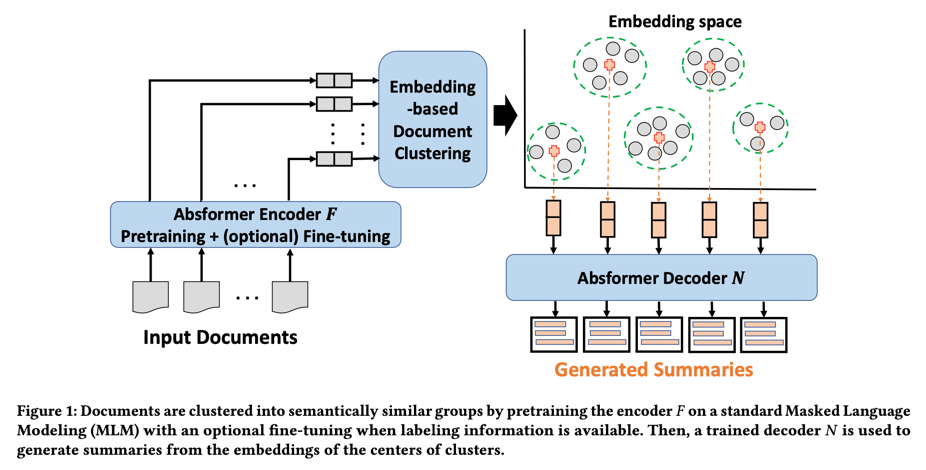
在本节中,我们将介绍我们提出的 Absformer 方法,这是一种基于 Transformer 的两阶段抽象 MDS 方法。我们首先介绍第一阶段(包括文档聚类步骤),然后介绍第二阶段(包括摘要生成步骤)。我们的方法概览如图 1 所示。
现有的无监督 MDS 方法使用 LSTM 作为主要组件来获得文档级或句子级表征。在我们提出的模型中,我们将transformer作为两个阶段的主要组件。特别是,我们使用 DistilBERT(由多层transformer块组成)来获取文档级表征。我们选择使用 DistilBERT 作为聚类和生成模型的主要组件有两个原因。首先,DistilBERT 利用了 Transformer 的自我注意功能,该功能比循环架构更能捕捉长程依赖关系。其次,DistilBERT 的体积较小,性能与 BERT 相当,而我们的目标是在保持合理的时间和内存复杂度的同时,获得准确的文档聚类和连贯的摘要。
4.1.Pretraining of Encoder
预训练DistilBERT:
我们使用标准的mask语言建模(MLM)目标,屏蔽率为文档中 15%的子标记。形式上,给定自然语言标记 x = x 1 , x 2 , … , x n \mathbf{x}=x_{1},x_{2},\ldots,x_{n} x=x1,x2,…,xn的序列,我们训练一个 DistilBERT 屏蔽语言模型,旨在从屏蔽序列中恢复 x \mathbf{x} x中的子标记。mask特殊标记(用 [MASK] 表示)用于替换 x m = { x i 1 , . . . , x i m } x_m=\{x_{i_{1}},...,x_{i_{m}}\} xm={xi1,...,xim} 中的标记子集,从而得到屏蔽序列 x ~ \widetilde{\mathbf{x}} x 。掩码 DistilBERT 语言模型计算掩码标记的概率分布 p θ ( x m ∣ x ~ ) p_{\mathbf{\theta}}\left(\mathbf{x}_{m}\mid\tilde{\mathbf{x}}\right) pθ(xm∣x~),其中 θ \mathbf{\theta} θ 是掩码 DistilBERT 语言模型的参数。
参数 t h e t a \mathbf{theta} theta是通过使用初始文档集合 D D D最大化 p θ ( x m ∣ x ~ ) p_{\mathbf{\theta}}\left(\mathbf{x}_{m}\mid\tilde{\mathbf{x}}\right) pθ(xm∣x~)来更新的。预训练阶段结束后,预训练的 DistilBERT 将被用作编码器 F F F 来计算文档的表示,如果在基于嵌入的文档聚类过程中使用了标签信息,那么参数 θ \mathbf{\theta} θ 将与多层感知器(MLP)共同调整;如果在计算出的文档表示之上使用了无监督聚类,那么参数 θ \mathbf{\theta} θ 将被冻结。
4.2.Embedding-based Document Clustering
基于文档的聚类embedding:
我们为每组语义相似的文档生成摘要。预训练 DistilBERT 模型 F F F 通过使用 MLM 目标作为预训练任务来捕捉语义匹配信号。因此, F F F 计算出的文档嵌入可以作为无监督聚类算法的输入,以获得语义相似文档的聚类。文档 d i d_{i} di 的表示形式为 R e p ( d i ) Rep(d_{i}) Rep(di):
R
e
p
(
d
i
)
=
[
CLS
]
x
1
x
2
…
x
n
i
[
SEP
]
(1)
Rep(d_{i})=[\text{CLS}]x_{1}x_{2}\ldots x_{n_{i}}[\text{SEP}] \tag{1}
Rep(di)=[CLS]x1x2…xni[SEP](1)
其中,
d
i
=
x
1
x
2
…
x
n
i
d_{i}=x_{1}x_{2}\ldots x_{n_{i}}
di=x1x2…xni 是
n
i
n_{i}
ni 标记的序列,[CLS] 和 [SEP] 是 DistilBERT 的特殊标记,它们被添加到序列中,类似于单句分类设置。
编码器 F F F 将一个文档 d i d_{i} di 的表示形式(用 R e p ( d i ) Rep(d_{i}) Rep(di) 表示)作为输入,以计算嵌入值 d i ‾ ∈ R h \overline{d_{i}}\in\mathbb{R}^{h} di∈Rh,该嵌入值是使用 DistilBERT 模型 F F F 中最后一个transformer块中 [CLS] 标记的隐藏状态提取的,其中 h h h 是嵌入值的维度。
4.2.1. Cluster Documents Without Label Information
无标签文档聚类:
基于transformer的文档嵌入 o v e r l i n e D = { d 1 → , d 2 → , … , d n → } overline{D}=\{\overrightarrow{d_{1}},\overrightarrow{d_{2}},\ldots, \overrightarrow{d_{n}}\} overlineD={d1,d2,…,dn}被转发到无监督聚类步骤,以获得 K K K文档聚类。在本文中,我们使用 k-means 聚类算法,该算法已被证明在聚类结果方面非常有效,而且在时间和内存复杂度方面也很高效。我们将研究更先进的无监督聚类算法作为未来的发展方向。
经过聚类步骤,我们得到了 K K K 的文档簇 D = { g 1 , g 2 , … , g K } D=\{g_{1},g_{2},\ldots,g_{K}\} D={g1,g2,…,gK},其中每个簇 g i = { d 1 i 、 d 2 i , … , d ∣ g i ∣ i } g_{i}=\{d_{1}^{i}、d_{2}^{i},\ldots,d_{|g_{i}|}^{i}\} gi={d1i、d2i,…,d∣gi∣i} 是由来自 D D D 的 ∣ g i ∣ |g_{i}| ∣gi∣ 文档和一个聚类中心 C g i C_{g_{i}} Cgi 组成的。我们用 C g i ‾ \overline{C_{g_{i}}} Cgi表示k-means步骤得到的聚类嵌入。为了减少异常值的影响,我们计算每个文档的聚类权重,其值为
w
d
j
i
=
min
d
k
i
∈
g
i
d
i
s
t
(
C
g
i
,
d
k
i
)
d
i
s
t
(
C
g
i
,
d
j
i
)
(2)
w_{d_{j}^{i}}=\frac{\min_{d_{k}^{i}\in g_{i}}dist(C_{g_{i}},d_{k}^{i})}{dist( C_{g_{i}},d_{j}^{i})}\tag{2}
wdji=dist(Cgi,dji)mindki∈gidist(Cgi,dki)(2)
其中:
d
i
s
t
(
C
g
i
,
d
k
i
)
=
L
n
o
r
m
2
(
C
g
i
‾
,
d
k
i
‾
)
(3)
dist(C_{g_{i}},d_{k}^{i})=L_{norm}^{2}(\overline{C_{g_{i}}},\overline{d_{k}^{ i}}) \tag{3}
dist(Cgi,dki)=Lnorm2(Cgi,dki)(3)
L
n
o
r
m
2
(
v
1
,
v
2
)
L_{norm}^{2}(v_{1},v_{2})
Lnorm2(v1,v2) 表示两个向量
v
1
v_{1}
v1 和
v
2
v_{2}
v2 之间的欧氏规范。然后,我们使用文档的簇级权重更新每个簇
g
i
g_{i}
gi 的中心嵌入
C
g
i
‾
\overline{C_{g_{i}}}
Cgi:
C
g
i
‾
=
∑
j
=
1
∣
g
i
∣
w
d
j
i
d
j
i
‾
∑
j
=
1
∣
g
i
∣
w
d
j
i
(4)
\overline{C_{g_{i}}}=\frac{\sum_{j=1}^{|g_{i}|}w_{d_{j}^{i}}\overline{d_{j}^{ i}}}{\sum_{j=1}^{|g_{i}|}w_{d_{j}^{i}}}\tag{4}
Cgi=∑j=1∣gi∣wdji∑j=1∣gi∣wdjidji(4)
从编码器
F
F
F 中获得的文档和中心的嵌入信息将被转发到摘要生成步骤,并在摘要生成训练和推理过程中保持冻结。
4.2.2. Cluster Documents With Label Information
有标签信息的文档聚类:
无监督聚类步骤会根据 MLM 目标生成语义相似的聚类。在有些情况下,除了语义相似性之外,还需要为具有更多共同特征的文档生成摘要。例如,如果 D D D 是由产品评论组成的,那么一项有趣的任务就是为相似的产品或相似的评分生成摘要。换句话说,在这种情况下,标签信息或聚类标准是由产品类型或评分分数明确提供的。因此,预训练的 DistilBERT 模型应使用可用的标签信息进行微调,以获得具有共同特征的语义相似的聚类。
在微调阶段,D中的每个文档 d i ∈ D d_{i}\in D di∈D都与L中的标签 l i ∈ L l_{i}\in L li∈L相关联,其中 L L L是标签集(例如评分分数和产品类型)。预训练的 DistilBERT 模型被用作编码器 F F F,其参数 θ \boldsymbol{\theta} θ与任务特定的软最大层 W W W 共同训练,后者被添加到 DistilBERT 的顶部,以预测 L 中给定标签 l 的概率:
p
(
l
∣
d
i
‾
θ
)
=
softmax
(
W
d
i
‾
θ
)
(5)
p\left(l\mid\overline{d_{i}}^{\boldsymbol{\theta}}\right)=\text{softmax}( W\overline{d_{i}}^{\boldsymbol{\theta}}) \tag{5}
p(l∣diθ)=softmax(Wdiθ)(5)
DistilBERT 的参数(用
θ
\boldsymbol{\theta}
θ 表示)和软最大层参数
W
W
W 是通过最大化真实标签的对数概率来微调的。
微调阶段的结果是 ∣ L ∣ |L| ∣L∣聚类,其中 ∣ L ∣ |L| ∣L∣是 L L L的标签数。与不带标签信息的文档聚类类似,每个簇都应与一个簇中心相关联,每个文档都应属于一个簇,并有一个成员权重,以减少异常值的影响。对于给定的文档 d i d_{i} di,第一步是计算 d i d_{i} di 在以下范围内的概率分布中的所有标签:
p
i
=
softmax
(
W
d
i
‾
θ
)
(6)
p_{i}=\text{softmax}\left(W\overline{d_{i}}^{\theta}\right) \tag{6}
pi=softmax(Wdiθ)(6)
其中,
p
i
∈
R
∣
L
∣
p_{i}\in\mathbb{R}^{|L|}
pi∈R∣L∣ 是预测概率向量。第二步是预测
d
i
d_{i}
di 的聚类(用
c
i
c_{i}
ci 表示)和成员权重(用
w
i
\text{w}_{i}
wi 表示):
c
i
=
argmax
l
∈
L
p
i
[
l
]
w
i
=
max
l
∈
L
p
i
[
l
]
(7)
c_{i}=\operatorname*{argmax}_{l\in L}p_{i}[l]\ \\ w_{i}=\operatorname*{max}_{l\in L}p_{i}[l] \tag{7}
ci=l∈Largmaxpi[l] wi=l∈Lmaxpi[l](7)
聚类中心的计算方法与使用公式 (4) 对无标签信息的文档进行聚类的情况类似。最后,我们得到
∣
L
∣
|L|
∣L∣文档簇
D
=
{
g
1
,
g
2
,
…
,
g
∣
L
∣
}
D=\{g_{1},g_{2},\ldots,g_{|L|}\}
D={g1,g2,…,g∣L∣},其中每个簇
g
i
=
{
d
1
i
、
d
2
i
,
…
,
d
∣
g
i
∣
i
}
g_{i}=\{d_{1}^{i}、d_{2}^{i},\ldots,d_{|g_{i}|}^{i}\}
gi={d1i、d2i,…,d∣gi∣i} 由来自
D
D
D 的
∣
g
i
∣
|g_{i}|
∣gi∣ 文档和一个聚类中心
C
g
i
C_{g_{i}}
Cgi 组成。
在本文的其余部分,无论在聚类阶段是否存在标签信息,我们都用 K K K 表示聚类的数量。例如,图 1 描述了 K = 5 K=5 K=5 的情况。总之,文档聚类阶段的结果是:(1)语义相似的簇 { g 1 , g 2 , … , g K } \{g_{1},g_{2},\ldots,g_{K}\} {g1,g2,…,gK},其特征是簇中心为 C g 1 ‾ , C g 2 ‾ , … , C g K ‾ \overline{C_{g_{1}}},\overline{C_{g_{2}}},\ldots,\overline{C_{g_{K}}} Cg1,Cg2,…,CgK、和成员权重为 w d i e ( i ) \text{w}_{d_{i}^{e(i)}} wdie(i)的文档,其中 c ( i ) c(i) c(i) 是与 d i d_{i} di 相关联的聚类,以及 (2) 经过训练的基于 DistilBERT 的编码器模型 F F F,用于将文档映射到嵌入空间。文档聚类阶段的输出被转发到摘要生成步骤,以便为每个聚类 g k g_{k} gk 生成一个连贯的抽象摘要。
5. Absformer: Summary Generation
第二步,摘要生成:
基于预训练transformer的模型在文本摘要方面取得了最先进的成果。例如,PEGASUS是一种基于编码器-解码器transformer的模型,用于有监督的抽象总结。在有监督的抽象总结中给出了真实的总结,因此编码器和解码器都是经过联合训练的。在本文中,我们将讨论无监督抽象摘要,这样就不能直接应用基于transformer的端到端编码器-解码器模型来生成摘要。我们建议训练一个基于transformer的解码器模型 N N N,该模型可从冻结编码器 F F F 获得的嵌入中生成文档。然后,如图 1 所示,使用训练好的解码器 N N N 从聚类中心的嵌入式数据生成摘要。
5.1.Encoder-Decoder Model
Absformer 的一个重要设计选择是,在摘要生成训练过程中,编码器 F F F 应保持冻结状态,以保留文档聚类信息,即文档和聚类中心嵌入,如图 1 的嵌入空间所示。因此,我们直接使用嵌入 { d 1 ‾ , d 2 ‾ , … , d n ‾ } \{\overline{d_{1}},\overline{d_{2}},\ldots,\overline{d_{n}}\} {d1,d2,…,dn}作为解码器模型的输入。与传统的文本到文本编码器-解码器模型相比,Absformer 的解码器部分将embedding-level信息作为输入,而不是token-level信息,并生成token-level sequence作为输出。
我们提出的解码器与基于 DistilBERT 的编码器模型 F F F 具有相同的块数。 F F F 中的每个块由自注意层和前馈层组成。为了将文档嵌入纳入解码过程,我们还在 Absformer 的解码器中加入了一个交叉注意层,类似于 T5 模型。除了解码器模块,基于 DistilBERT 的解码器模型还由嵌入层和语言模型头组成。
5.1.1. Embedding Layer
在每个时间戳中,解码器生成一个标记,以便从输入嵌入中生成文档标记,或从群集中心的嵌入中生成摘要标记。token-level嵌入来自解码器 N N N 中的嵌入层。该嵌入层由单词嵌入和位置嵌入组成,并使用编码器的嵌入层进行初始化,以纳入编码器 F F F 所获取的标记级知识。嵌入层的输出被转发到 N N N 的第一个解码器块。
5.1.2. Decoder Block
每个区块由三个部分组成,即自注意头、交叉注意头和前馈层。
自我注意头:这是一个基于transformer的层,有 12 个注意头。共有 6 个自我注意层,每个层都使用冻结编码器 F F F 中的各自自我注意进行初始化。与随机初始化自我注意头相比,从编码器 F F F 初始化收敛更快,损失更低。与递归架构相比,基于transformer器的自注意头能更好地捕捉长距离依赖关系,因此即使对于长序列(最大标记数为 512),生成的标记也更准确。在时间戳 t t t 获取的深度上下文嵌入会被转发到交叉注意头。
交叉注意头:从自我注意头获得的嵌入只依赖于时间戳 t t t 之前生成的标记。为了将编码器嵌入信息纳入解码过程,我们添加了一个交叉注意头,以计算上下文和编码器感知嵌入信息。交叉注意也是一个基于transformer的层,有 12 个注意头。共有 6 个交叉注意层。
形式上,在来自交叉注意力层的给定注意力头中,引入了三个参数矩阵:查询矩阵 Q ( Q i n R h × h Q(Qin\mathbb{R}^{h\times h} Q(QinRh×h)、密钥矩阵 K ( K ∈ R h × h K(K\in\mathbb{R}^{h\times h} K(K∈Rh×h)和值矩阵 V ( V ∈ R h × h V(V\in\mathbb{R}^{h\times h} V(V∈Rh×h)。对于给定的文档 d i d_{i} di,假设生成的 t t t 标记的嵌入用 E t ∈ R t × h a E_{t}\in\mathbb{R}^{t\times h_{a}} Et∈Rt×ha 表示,标记嵌入 E t E_{t} Et 和编码器嵌入 d i ‾ \overline{d_{i}} di 之间的交叉关注度
因此,密钥输出 K \mathcal{K} K 和值输出 V \mathcal{V} V 是通过编码器嵌入 d i ‾ \overline{d_{i}} di 计算出来的,而查询输出则是通过生成的标记嵌入 E t E_{t} Et 计算出来的。从交叉注意头获得的上下文和编码器感知嵌入信息将被转发到前馈层。我们注意到,我们还使用冻结编码器 F F F 的自注意参数对交叉注意头进行了初始化。
前馈层: 该层由一个包含 2 个线性层的前馈网络和一个归一化层组成。这些神经组件通过编码器 F F F 的相应前馈层进行初始化。区块 l l l 的前馈层输出转发至区块 l + 1 l+1 l+1 的自注意头。
5.1.3. Language Model Head
下一个标记预测用于训练解码器 N N N。换句话说,在每个时间戳 t t t 中,解码器 N N N 应输出与位置 t + 1 t+1 t+1 相对应的标记。语言模型头将从最后一个解码块中获得的长度为 t t t 的序列嵌入作为输入,并输出解码器 N N N 所有词汇的概率分布(与编码器 F F F 的词汇相同)。为了加快解码训练的收敛速度,我们使用在文档聚类阶段对编码器 F F F 进行 MLM 预训练时的语言模型头来初始化解码器的语言模型头。解码器的语言模型头由第一线性层、GELU 激活层、归一化层和第二线性层组成,输出层的维度等于解码器的词汇量。
Decoder Training
解码器 N N N 是通过教师强制下一个标记预测任务来训练的。我们不使用标准的交叉熵损失来重建原始文档,而是使用加权交叉熵损失来训练解码器 N N N,以便将训练重点放在重建接近聚类中心的文档上。因此,我们减少了异常值对生成摘要的影响。形式上,大小为 B B B 的一批文档的解码器损失函数 L N L_{N} LN 由以下公式给出:
L
N
=
−
∑
l
∈
B
∑
j
=
1
T
l
w
d
l
j
+
1
l
o
g
P
(
t
j
∣
t
0
j
−
1
)
(9)
L_{N}=-\sum_{l\in B}\sum_{j=1}^{T_{l}}w_{d_{l}^{j+1}}logP\left(t_{j}\mid t _{0}^{j-1}\right)\tag{9}
LN=−l∈B∑j=1∑Tlwdlj+1logP(tj∣t0j−1)(9)
其中,
T
l
T_{l}
Tl 是文档
d
l
d_{l}
dl 的长度,
t
j
t_{j}
tj 是文档
d
l
d_{l}
dl 的第 j 个标记,
t
0
j
−
1
t_{0}^{j-1}
t0j−1 是文档
d
l
d_{l}
dl 到标记
j
−
1
j-1
j−1 的序列。
5.3.Summary Decoding
在训练解码器 N N N 从编码器 F F F 获得的嵌入中重建文档后,最后一步是生成每个聚类的摘要。如图 1 所示,每个簇的中心 C g i ‾ \overline{C_{\mathbf{g_{i}}}} Cgi 被用作解码器 N N N 的输入。更具体地说,每个解码块的交叉注意头使用集群的中心嵌入 C g i ‾ \overline{C_{\mathbf{g_{i}}}} Cgi 来计算键和值矩阵,这样我们就能从最后一个解码块的输出中获得每个时间戳的集群感知嵌入。每个时间戳的输出嵌入被转发到解码器 N N N 的语言模型头,以计算所有词汇的概率分布。
文献中提出了多种方法,从计算出的词汇概率分布中选择下一个标记。我们在实验中发现,top-p和 top-K采样的组合能带来最佳的生成摘要质量。特别是:(1) 使用 top-p 采样时,可以根据下一个词的概率分布动态地增加或减少候选标记集;(2) 使用 top-K 采样时,可以丢弃概率分布很低的标记。我们将进行 S S S 次摘要解码,从而为每个聚类得到 S S S 个不同的摘要。
与 Coavoux 等人类似,根据每个摘要的嵌入与聚类中心嵌入之间的余弦相似度 C g i ‾ \overline{C_{\mathbf{g_{i}}}} Cgi,对给定聚类 g i g_{i} gi 生成的 S S S 摘要进行排序,以便只保留与每个聚类语义相似的摘要。摘要的嵌入使用编码器 F F F 计算。
6. Evaluation
6.1.Data Collections
6.1.1. Amazon Reviews
该数据集由 Oposum 语料库组成,其中包含从亚马逊产品数据集中提取的 6 类产品(箱包、蓝牙、靴子、键盘、电视、真空吸尘器)中收集的 3,461,603 条亚马逊评论。每条评论都附有 5 星评级。每种产品都有 30 条金摘要,在测试阶段仅用于评估我们提出的模型和基线生成的摘要。
6.1.2. Yelp Reviews
该数据集包含大量没有黄金标准摘要的评论。每条评论都附有五星评级。与 Chu 等人的做法类似,少于 50 条评论的业务会被删除,以便有足够的评论为每个产品进行总结。该数据集包含 1,297,880 条评论。我们考虑了 7 类产品(购物、家庭服务、美容与水疗、健康与医疗、酒吧、酒店与旅游、餐饮)。每种产品都有 20 条金摘要,仅用于在测试阶段评估我们的模型和基线生成的摘要。
6.1.3. Ticket Data from Network Equipment
我们的工作源于总结网络设备票单数据的业务需求。当移动网络中出现问题时,就会打开一个票单来详细描述问题。每张票据都包含多条描述问题的信息。票单通常由测试人员确定的单位解决。为了加快解决票单的过程,测试人员可以利用以前的票单来解决常见问题。然而,对于测试人员来说,阅读以前的票单以查找类似问题是一项非常耗时的任务。因此,将几组相似的测试卷汇总成一个简明的摘要可以帮助测试人员只关注给定测试卷组中共有的重要部分。我们提出的方法 Absformer 将用于生成票单组的摘要,这些摘要将作为测试人员解决给定票单的额外信息来源。票单总数为 400k。为了保证票单数据的机密性,我们不能展示票单和摘要的样本。
总之,亚马逊和 Yelp 的评论被视为短文档,而票据则被视为长文档,构成每张票据的句子数量要多得多。
6.2.Baselines
我们将所提出的 Absformer 方法与以下无监督abstravive MDS 基线进行了比较。
6.2.1. Aspect + MTL
使用基于方面的聚类方法对评论进行聚类。然后,使用多任务学习(MTL)训练基于 LSTM 的生成模型。
6.2.2. MeanSum
Meansum 的摘要处理流程首先是对从基于 LSTM 的编码器获得的文档嵌入进行平均,以计算摘要的嵌入。然后,生成的嵌入被转发给基于 LSTM 的解码器,以生成摘要。编码器和解码器的训练使用两个损失函数进行监控,即平均摘要相似性损失和自动编码器重建损失。
6.2.3. Copycat
它是一个基于 VAE 的模型,使用两种损失函数进行训练:一种是重建损失,用于从潜在表征中恢复原始评论;另一种是库尔贝克-莱布勒(KL)发散,用于惩罚计算后验与先验的偏差。在生成阶段,对评论的潜在向量进行平均,计算出摘要表示,然后对摘要表示进行解码,生成摘要标记。
6.2.4. DenoiseSum
使用多种噪声技术创建了许多噪声版本的评论。LSTM 在编码器和解码器中都有使用,编码器用于获取上下文嵌入,解码器用于去噪评论并生成摘要。
6.2.5. RecurSum
递归高斯混合物对潜在空间中的句子粒度进行建模,并生成具有多种粒度的摘要。
6.3.Experimental Setup
我们的模型使用 PyTorch 和 NVIDIA RTX A6000 实现。维度 h h h 等于 768。对于每个数据集,编码器使用 MLM 进行 50 次epochs预训练,批量大小为 32。学习率为 1e-4,权重衰减为 0.01,热身阶段为 80,000 步。为了利用标注信息对编码器进行微调,对模型进行了 10 次epochs训练,批量大小为 32。学习率为 3e-5,学习率从热身阶段开始线性下降,热身阶段学习率上升。验证集上的最佳模型被保存到第二阶段。在第二阶段的训练步骤中,我们对解码器进行了 40 次批量大小为 8 的epochs训练,学习率为 1e-4,权重衰减为 0.01,热身阶段为 20,000 步。序列的最大长度为 512,我们使用标记 ID 1 作为生成序列的起始标记。对于摘要解码,摘要 S S S 的数量等于 10。top-K 为 50,top-p 为 0.95。
6.4.Experimental Results
我们使用三种 ROUGE评分来评估我们提出的方法和基线的性能:ROUGE-1 (R-1)、ROUGE-2 (R-2) 和 ROUGE-L (R-L)。
6.4.1. Results on Amazon Dataset
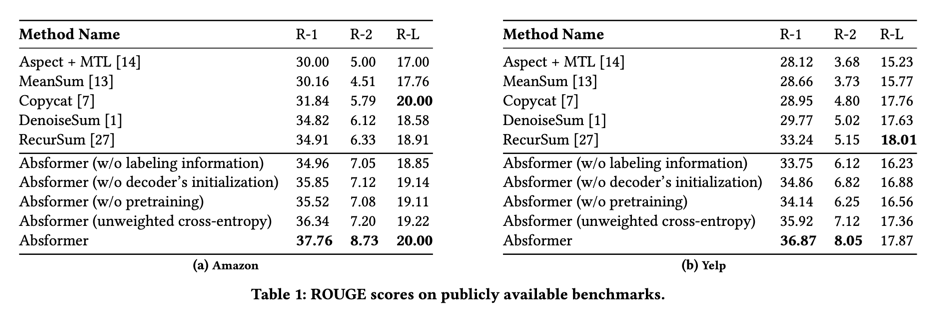
表 1(a) 显示了不同方法在亚马逊评论中的表现。我们发现,我们提出的方法 Absformer 在 R-1 和 R-2 方面的表现优于基线方法。获得较高的 R-L 分数具有挑战性,因为在我们的设置中,我们将成千上万的文档总结为一个简短的摘要,不太可能从摘要中获得与地面实况摘要中的句子完全匹配的长序列。
为了证明我们所提出的方法中每个组成部分的重要性,我们介绍了 Absformer 的消减研究结果。在 Absformer(不含标签信息)中,我们为文件集群生成摘要,这些文件集群是通过使用 k-means 对基于 MLM 的嵌入进行聚类而得到的。在 Absformer(不含解码器初始化)中,解码器由 vanilla DistilBERT 初始化,而不是使用编码器中的相应参数来初始化嵌入层、解码器块和解码器的语言模型头。在 Absformer(无预训练)中,编码器直接在目标数据集上进行微调。在 Absformer(非加权交叉熵)中,所有权重 w d i e l l ( i ) w_{d^{ell\ (i)}_{i}} wdiell (i) 都等于 1。我们的全模型 Absformer 优于所有四种系统变体,这证明了以下几点的重要性:(1) 使用编码器中的相应参数初始化解码器的嵌入层、解码器块和语言模型头;(2) 标签信息;(3) 编码器的预训练;(4) 训练解码器时的非加权交叉熵损失 N N N。
与在编码器和解码器中使用 BERT 架构相比,Absformer 基于 DistilBERT 的架构在生成阶段的速度提高了68%,测试阶段的 ROUGE 分数也没有显著下降(在摘要生成中保留了98%的 BERT 性能)。
6.4.2. Results on Yelp Dataset
表 1(b) 显示了不同方法在 Yelp 评论集上的性能。与亚马逊数据集的结果一致,我们在 Yelp 数据集上的结果显示,Absformer 在 R-1 和 R-2 两项上的表现均优于所有基线和系统变体。
6.4.3. Results on Ticket Data from Network Equipment
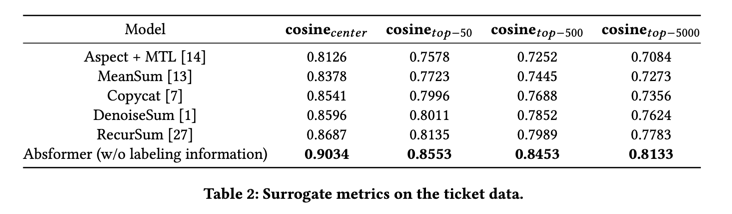
与亚马逊和 Yelp 数据集不同的是,亚马逊和 Yelp 数据集在测试阶段有地面实况摘要子集来报告 ROUGE 分数,而机票数据在测试阶段没有地面实况摘要。因此,我们无法在该数据集上报告 ROUGE 分数来评估生成摘要的质量。相反,我们使用代用指标来评估票据数据生成摘要的质量。与 MeanSum(Kumar 等人,2017 年)类似,作为第一个替代指标,我们报告了编码生成的摘要与所有 K K K 聚类的聚类嵌入之间的平均余弦相似度( c o s i n e c e n t e r cosine_{center} cosinecenter)。第二个替代指标是编码生成的摘要与所有 K K K 簇中每个簇的前 k k k 票之间的平均余弦相似度( c o s i n e t o p − k cosine_{top-k} cosinetop−k)。机票数据中没有标签信息,因此使用 Absformer(不含标签信息)生成摘要。
表 2 显示,Absformer 的代用指标优于基线。Absformer 生成的摘要嵌入与中心的嵌入很接近,平均余弦相似度约为 0.9。对于每个集群中的前 k k k 票,当 k k k 增加时,我们的方法和基线方法的编码摘要与前 k k k 票的嵌入之间的平均余弦相似度都会降低。这表明在一般情况下对大量文件进行摘要的难度很大,这模拟了真实的案例场景,因此是一个重要的研究方向。
6.4.4. Learning Curves of Absformer
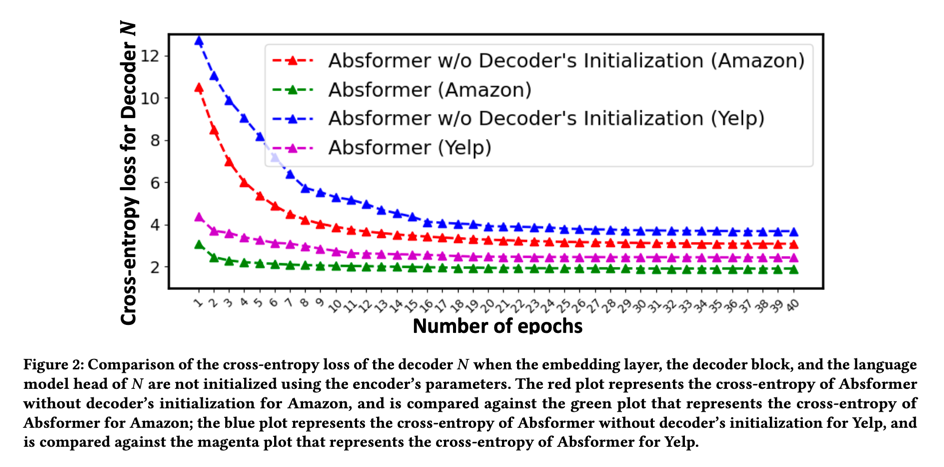
图 2 显示了解码器 N N N 在验证集上的交叉熵损失。对于这两个数据集,用编码器 F F F 的相应参数初始化嵌入层、解码器块和 N N N 的语言模型头,可以降低交叉熵损失,加快收敛速度。如图 2 所示,对解码器进行初始化后,我们的全模型 Absformer 不需要训练 40 个历时就能收敛。只需对解码器 N N N 进行 10 次历时训练,就足以在验证集上获得较小的交叉熵损失。
6.4.5. Examples of Generated Summaries
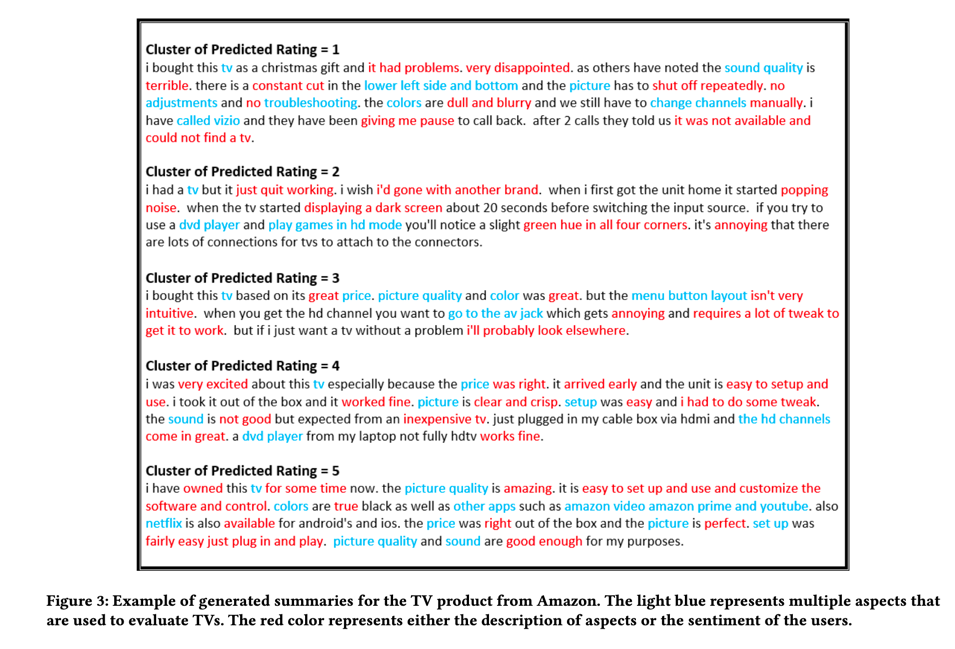
图 3 展示了 Absformer 从亚马逊数据集的电视产品中生成摘要的示例。我们为所有 5 个群组生成摘要,其中每个群组代表不同的预测评级。图 3 强调了我们的摘要器所捕捉到的多个方面。例如,摘要涵盖了_音质、画质、色彩、调节、故障排除、价格、菜单按钮、设置_等。摘要对每个方面的功能进行了描述,低评分侧重于问题和故障,高评分侧重于功能完善的方面。摘要还强调了用户的情绪,其中负面情绪在低评分群组中使用_disappointed_(失望)和_terrible_(糟糕)等词来表达,正面情绪在高评分群组中使用_very excited_(非常兴奋)和_good enough_(足够好)等词来表达。我们的摘要非常流畅,抓住了评论的要点。
7 CONCLUSIONS
在本文中,我们提出了一种新的无监督 MDS 方法,即 Absformer。我们已经证明,我们基于transformer的双阶段模型可以为具有语义相似文档的聚类生成连贯流畅的摘要。我们基于 Transformer 的解码器是通过从冻结编码器获得的嵌入中生成文档来训练的。然后,训练有素的解码器从聚类中心生成摘要。提高时间和内存复杂度以及实现快速con- vergence是我们提出的模型所考虑的要点。我们在三个数据集上进行了实验,结果表明,我们的新方法优于最先进的基线方法,并且适用于多个领域的文档集。一项消融研究显示了四个组成部分的重要性: (1) 用编码器中的相应参数初始化嵌入层、解码器块和解码器的语言模型头;(2) 标签信息;(3) 编码器的预训练;(4) 非加权交叉熵损失。
未来的工作包括:(1) 研究将 Absformer 纳入变异自动编码器 (VAE) 框架的可能性,以便对编码器和解码器进行端到端训练;(2) 总结每个产品的评论,以提高 R-L 分数。