本文为 Django 学习笔记的讲解。
Django 对各种数据库都提供了很好的支持,并提供了统一的 API 接口,我们操作数据库的过程实际上就是通过操作模型实现的。因此,我们可以根据不同的业务需求选择不同的数据库。
运行环境
- Windows 10
- Pycharm Community Edition 2020.1.3
- Django 3.0.8
所有的代码见【Django】系列。
ORM
我们首先需要介绍 ORM 的相关知识。ORM 就是“对象-关系-映射”。其任务是根据对象的类型生成表结构,并将对象、列表的操作转换为 SQL 语句,也可以将 SQL 语句查询到的结果转换为对象、列表。其优点是极大的减轻了开发人员的工作量,无需因数据库的变更而修改代码。其示意图及功能如下:
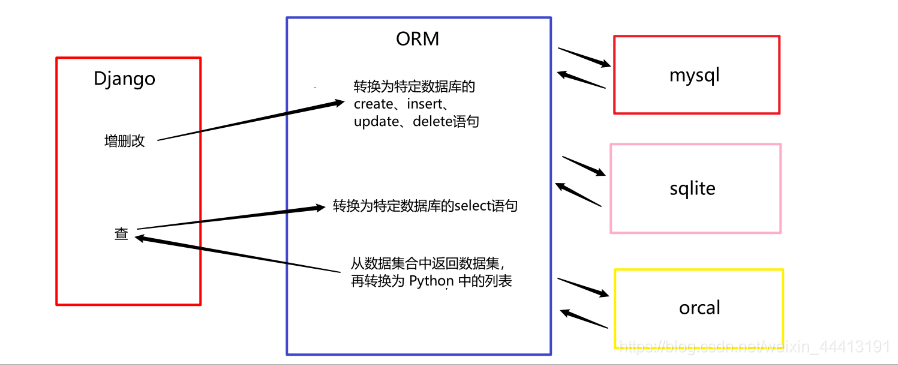
定义模型
模型、属性、表、字段的关系
通过前面几篇文章的讲解,相信这 4 者的关系你肯定已经非常熟悉了:一个模型类在数据库中对应一张表,在模型中定义的属性对应(该模型)对照表中的一个字段。
定义属性
见 Django 定义属性总结。这里给出本文定义的模型:
创建模型类
见 跑通 Django。这里给出本文定义的模型:
class Grades(models.Model):
gname = models.CharField(max_length=20)
gdate = models.DateTimeField()
ggirlnum = models.IntegerField()
gboynum = models.IntegerField()
isDelete = models.BooleanField(default=False)
def __str__(self):
return self.gname
# class Meta:
# db_table = "grades"
class Students(models.Model):
sname = models.CharField(max_length=20)
sgender = models.BooleanField(default=True)
sage = models.IntegerField(db_column="age")
scontend = models.CharField(max_length=20)
isDelete = models.BooleanField(default=False)
# 关联外键
sgrade = models.ForeignKey("Grades", on_delete=models.CASCADE)
def __str__(self):
return self.sname
lastTime = models.DateTimeField(auto_now=True, null=True) # 说明见定义属性
createTime = models.DateTimeField(auto_now_add=True, null=True)# 说明见定义属性
# class Meta:
# # 定义数据表的表名
# db_table = "students"
# # 对象按id字段排序,['id']升序,['-id']降序
# ordering = ['id']
元选项
我们可以在模型中定义 Meta 类,用于设置元信息。Meta 类中有两个成员,分别为 db_table 和 ordering。
db_table 用来定义数据表的表名,推荐使用小写字母,数据表名默认为“项目名小写_类名小写”。
ordering 为对象的默认排序字段,在获取对象的列表时使用。注意排序会增加数据库的开销。
class Meta:
db_table = "grades"
class Meta:
# 定义数据表的表名
db_table = "students"
# 对象按id字段排序,['id']升序,['-id']降序
ordering = ['id']
随后生成迁移文件并执行迁移,启动数据库查询建表语句,以上操作见跑通 Django。成功修改表名:

模型成员
类属性(取数据)
objects
通过学习之前的文章,相信大家已经对 objects 很熟悉了,objects 是 Manager 类型的一个对象,用来与数据库进行交互。我们之前的跑通 Django 中已经使用过一些相关的技巧了。当定义模型类没有指定管理器时,Django 就会为模型创建一个名为 objects 的管理器。
自定义管理器
我们也可以自定义管理器来扩展管理器的功能。当为模型指定模型管理器时,Django 就不再为模型类生成 objects 模型管理器。
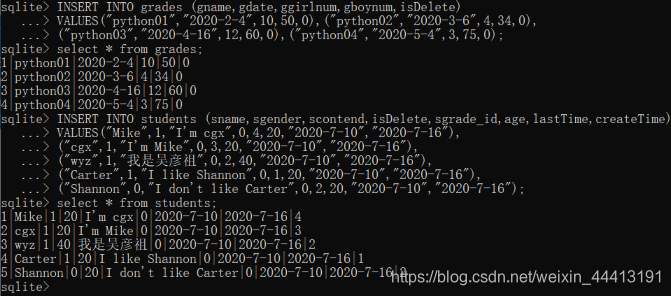
我们首先在数据库中插入一些数据,打开数据库的操作见跑通 Django 。
INSERT INTO grades (gname,gdate,ggirlnum,gboynum,isDelete)
VALUES("python01","2020-2-4",10,50,0),("python02","2020-3-6",4,34,0),
("python03","2020-4-16",12,60,0),("python04","2020-5-4",3,75,0);
INSERT INTO students (sname,sgender,scontend,isDelete,sgrade_id,age,lastTime,createTime)
VALUES("Mike",1,"I'm cgx",0,4,20,"2020-7-10","2020-7-16"),
("cgx",1,"I'm Mike",0,3,20,"2020-7-10","2020-7-16"),
("wyz",1,"我是吴彦祖",0,2,40,"2020-7-10","2020-7-16"),
("Carter",1,"I like Shannon",0,1,20,"2020-7-10","2020-7-16"),
("Shannon",0,"I don't like Carter",0,2,20,"2020-7-10","2020-7-16");
此时数据库中 grades 和 students 表中的数据为:
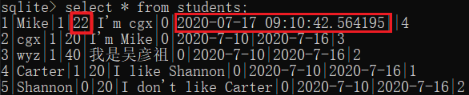
这里简单验证一下定义属性中的 auto_now=True,输入命令 python manage.py shell,在 shell 中对 Students 的一个对象进行修改:
>>> from myApp.models import Students
>>> stu = Students.objects.get(pk=1)
>>> stu
<Students: Mike>
>>> stu.sage = 22 # 修改年龄
>>> stu.save()
此时数据库中 students 表中第一个学生的年龄和修改时间发生了改变:
在添加完数据后,来自定义管理器。在模型中添加:
class Students(models.Model):
# 自定义模型管理器
# 当自定义模型管理器,objects就不存在了
stuObj = models.Manager()
此时重启 shell,用 objects 查看类成员,发现 objects 已经不存在。只能用 stuObj 进行查看:

自定义管理器 Manager 类
我们前面自定义管理器 stuObj 只是给 objects 换了个名字,功能并没有变化。要想让功能有所扩展,需要自定义管理器 Manager 类。自定义管理器 Manager 类可向管理器类中添加额外的方法,还可以通过重写 get_queryset() 方法来修改管理器返回的原始查询集。这个知识很重要,以后数据库和网页表单对接就要靠这个。
class StudentsManager(models.Manager):
def get_queryset(self):
return super(StudentsManager, self).get_queryset().filter(isDelete=False)
class Students(models.Model):
# 自定义模型管理器
# 当自定义模型管理器,objects就不存在了
stuObj = models.Manager()
stuObj2 = StudentsManager()
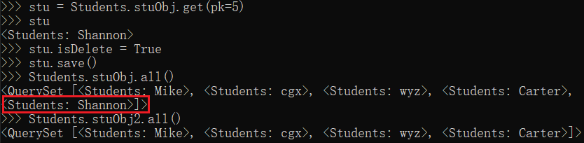
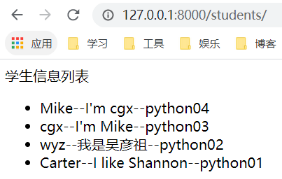
在 shell 中将 Shannon.isDelete 置为 True,然后分别利用 stuObj 和 stuObj2 对 Students 类中的所有成员进行显示:
我们再将筛选过的学生信息显示到浏览器页面中,可见 Shannon 已经被删除。如果这一步还没有掌握,参考 Django 模板基本操作:
创建对象(存数据)
在跑通 Django 中,我们对数据库进行添加数据时,在 shell 中创建了对象,但 django 不会对数据库进行读写,只有调用 save() 时才会与数据库交互。python 中 __init__ 方法已经在父类 models.Model 中使用,在自定义的模型类中无法使用。因此我们 __init__ 只能创建一个空对象,还需对其进行赋值。我们有两种方法创建对象。
一种是在模型类中添加类方法。这种方法类似 C++ 中的构造函数。
class Students(models.Model):
# 定义一个类方法创建对象
@classmethod # 表明方法为类方法
def creatStudent(cls, name, age, gender, contend, grade, lastT, createT, isD=False):# cls表示Students,若无@classmethod则直接使用Students
stu = cls(sname = name, sage = age, sgender = gender,
scontend = contend, sgrade = grade, lastTime = lastT,
createTime = createT, isDelete = isD)
return stu
我们添加一个学生对方法进行验证。在浏览器中输入 127.0.0.1:8000/addstudent/ 添加一个学生。首先配置 url(见模板基本操作),再定义视图。
def addstudent(request):
grade = Grades.objects.get(pk=1)
stu = Students.creatStudent("lcw", 44, True, "I'm lcw", grade, "2020-7-19", "2020-7-2")
stu.save()
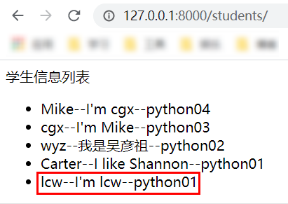
return HttpResponse("add success!")
在浏览器中添加学生:
添加成功:
另一种是在自定义管理器中添加方法。对应前面“向管理器类中添加额外的方法”。我们期望通过代码 stu = Students.stuObj2.createStudent()。首先在 models.py 中的自定义管理器中添加方法:
class StudentsManager(models.Manager):
def creatStudent(self, name, age, gender, contend, grade, lastT,
createT, isD=False):
# stu = Students() # 若限定为Students则只能用来初始化学生,使用self具有通用性
stu = self.model()
print(type(stu))# 查看stu的类型
得到打印结果,stu 为 Students 类型,说明 self.model() 使用正确:

此时我们完善上面的代码,给对象的属性赋值。可以看作为创建空对象然后对属性赋值,与 shell 中创建对象类似:
class StudentsManager(models.Manager):
def get_queryset(self):
return super(StudentsManager, self).get_queryset().filter(isDelete=False)
def creatStudent(self, name, age, gender, contend, grade, lastT,
createT, isD=False):
# stu = Students()
stu = self.model()
# print(type(stu))
stu.sname = name
stu.sage = age
stu.sgender = gender
stu.scontend = contend
stu.sgrade = grade
stu.lastTime = lastT
stu.createTime = createT
return stu
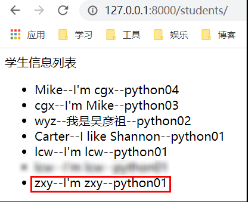
在视图中进行 save 操作后,查看结果:
模型查询
概述
数据库的查询是一个十分常用且重要的操作。因为我们需要把数据库中的数据显示在视图中,查询操作就必不可少。前面在模型管理器中我们已经接触过查询集的概念了,查询集表示从数据库获取的对象集合。但我们可以用多个过滤器函数,基于所给的参数过滤查询集。从 sql 角度来说,查询集和 select 语句等价,过滤器就像 where 条件。
查询集
在自定义管理器中我们说过,可以在管理器上调用查过滤器方法返回查询集,因为返回的为查询集,因此我们可以使用链式调用。查询集是惰性执行的,创建查询集不会进行数据访问,直到用这条数据的时候才会访问数据库,这样可以提高数据库查询操作的性能。我们也可以通过迭代、序列化、与 if 合用的方法直接访问数据。
返回查询集的方法称为过滤器
-
all():返回查询集所有数据 -
filter():返回符合条件的数据。filter(键=值,键=值)或filter(键=值).filter(键=值) -
exclude():过滤掉符合条件的数据,与filter()相反。 -
oreder_by():排序 -
values():一条数据是一个对象(字典形式),返回一个列表:在 shell 中使用
values()查询:而
all()返回的列表中是对象:


返回单个数据
-
get():返回一个满足条件的对象。如果没找到会引发"模型类.DoesNotExist"异常,如果找到多个对象,会引发"模型类.MultipleObjectsReturned"异常。def students2(request): # 报异常 studentsList = Students.stuObj2.get(sgender=True) return HttpResponse("error!")
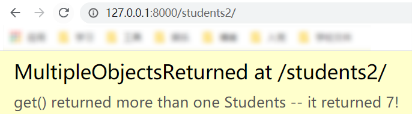
这种情况下使用 get() 可用 try 进行异常处理,多个对象使用过滤器返回查询集。
-
count():返回当前查询集中对象的个数 -
first()和last():返回查询集中第一个和最后一个数据 -
exists():判断查询集中是否有数据,如果有返回True。
限制查询集
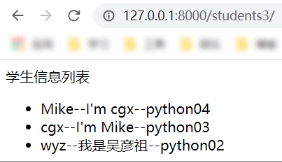
因为查询集返回的是一个列表,因此我们可以使用下标的方法进行限制,相当于 sql 中的 limit 语句。我们可以对前 3 条数据进行查询:
def students3(request):
studentsList = Students.stuObj2.all()[0:3] # 下标不能是负数
return render(request, 'myApp/students.html', {"students": studentsList})
得到结果:
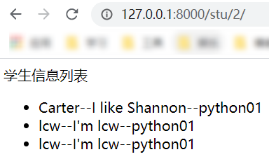
我们想要输入 127.0.0.1:8000/stu/x 显示第 x 页的信息,分页显示学生。
def stupage(request, page):
# 0-3 3-6
# 1 2
# page*3
page = int(page)
studentsList = Students.stuObj2.all()[(page - 1) * 3: page * 3]
return render(request, 'myApp/students.html', {"students": studentsList})
显示分页结果:
查询集的缓存
每个查询集都包含一个缓存,其作用与计算机组成原理的 cache 原理相同。
字段查询
概述
实现了 sql 中 where 语句,是方法 filter(), exclude(), get() 的参数。使用 属性名称__比较运算符 进行查询,外键查询时使用 属性名_id。还可以查询转义。like 语句中使用 % 是为了匹配占位,匹配数据中的 %(where like '\%'),语法:filter(sname_contains='%')。
比较运算符
-
exact:判断,大小写敏感。filter(isDelete=False) -
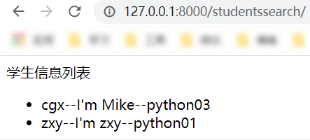
contains:是否包含。我们举例对名字中包含 x 的学生进行查询。def studentssearch(request): studentsList = Students.stuObj2.filter(sname__contains="x") return render(request, 'myApp/students.html', {"students": studentsList})查询结果:
-
startswith和endswith:以 value 开头或结尾。filter(sname__startswith="c") -
isnull和isnotnull:判断为空 -
in:是否包含在范围内。filter(pk__in=[1, 3]) -
gt, gte, lt, lte:大于,大于等于,小于,小于等于。filter(sage__gt=30) -
year, month, day, week_day, hour, minute, second:时间。filter(lastTime__year=2020) -
跨关联查询:处理
join查询,使用模型类名__属性名__比较运算符。例如查询描述中带有’cgx’的数据是属于哪个班级的:filter(students__scontend__contains='cgx')。 -
查询快捷:pk 代表主键。
聚合函数
可以使用 aggregate() 函数返回聚合函数的值。聚合函数包括 Avg, Count, Max, Min, Sum,函数的意思从名字易知。例如用 aggregate(Max('sage')) 可以取出学生的年龄最大值,使用哪个聚合函数就引入哪个:from django.db.models import Max。
F 对象
F 对象十分简单,是过滤器的参数,可以使用模型的 A 属性和 B 属性进行比较。例如我们可以找出女生人数大于男生的班级,使用 filter(ggirlnum__gt=F('gboynum')),其中引入 from django.db.models import F。并且还支持 F 对象的算数运算,例如找出女生人数大于男生人数+20 的班级:filter(ggirlnum__gt=F('gboynum')+20)
Q 对象
Q 对象也是过滤器参数。在前面介绍的过滤器参数中,参数之间为’&'的关系,我们可以用 Q 对象实现功能更丰富的逻辑关系。例如 or:filter(Q(pk__lte=4)|Q(sage__gt=50)) 找出主键 ≤4 或年龄大于 50 的学生。再例如 ~:filter(~Q(pk__lte=4)) 找出主键 >4 的学生。
至此,模型的所有内容就讲解完了,其中最重要且最常用的就是查询操作。反复练习,熟能生巧!