kafka+flink集成
1.目的
1.1 Flink简介
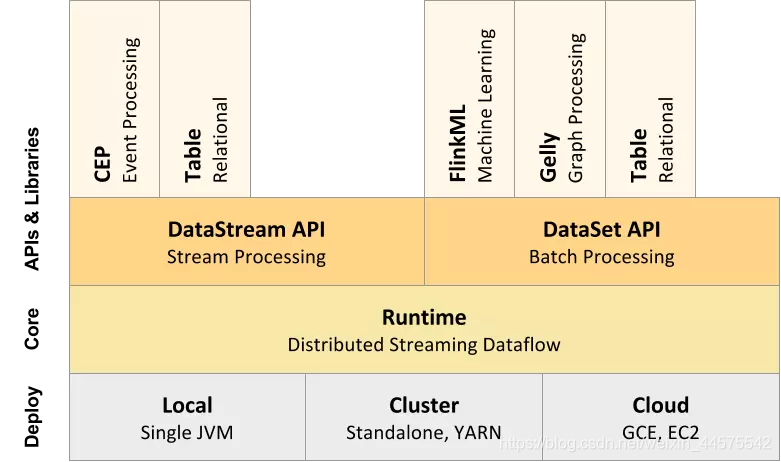
Apache Flink是一个面向数据流处理和批量数据处理的可分布式的开源计算框架,它基于同一个Flink流式执行模型(streaming execution model),能够支持流处理和批处理两种应用类型。
flink特性
支持批处理和数据流程序处理
优雅流畅的支持java和scala api
同时支持高吞吐量和低延迟
支持事件处理和无序处理通过SataStream API,基于DataFlow数据流模型
在不同的时间语义(时间时间,处理时间)下支持灵活的窗口(时间,技术,会话,自定义触发器)
仅处理一次的容错担保
自动反压机制
图处理(批) 机器学习(批) 复杂事件处理(流)
在dataSet(批处理)API中内置支持迭代程序(BSP)
高效的自定义内存管理,和健壮的切换能力在in-memory和out-of-core中
兼容hadoop的mapreduce和storm
1.2 Flink应用场景
事件驱动的应用程序
数据分析应用
数据管道应用
具体如下:
多种数据源(有时不可靠):当数据是由数以百万计的不同用户或设备产生的,它是安全的假设数据会按照事件产生的顺序到达,和在上游数据失败的情况下,一些事件可能会比他们晚几个小时,迟到的数据也需要计算,这样的结果是准确的。
应用程序状态管理:当程序变得更加的复杂,比简单的过滤或者增强的数据结构,这个时候管理这些应用的状态将会变得比较难(例如:计数器,过去数据的窗口,状态机,内置数据库)。flink提供了工具,这些状态是有效的,容错的,和可控的,所以你不需要自己构建这些功能。
数据的快速处理:有一个焦点在实时或近实时用例场景中,从数据生成的那个时刻,数据就应该是可达的。在必要的时候,flink完全有能力满足这些延迟。
海量数据处理:这些程序需要分布在很多节点运行来支持所需的规模。flink可以在大型的集群中无缝运行,就像是在一个小集群一样。
2.环境
| 内容 | 版本号 |
|---|---|
| 系统版本 | windows10 |
| JDK | 1.8.0_201 |
| kafka | 2.12-2.1.1 |
| zookeeper | 3.4.13 |
| Flink | 1.7.2 |
3.安装启动
环境安装请先参考:《windows下kafka的搭建及配置》
Flink安装:
官方下载地址:https://flink.apache.org/zh/downloads.html#section
解压后安装至F:\bigdata
命令窗口下启动
F:\bigdata\flink-1.7.2\bin\start-cluster.bat
打开浏览器输入
http://localhost:8081
安装成功
4.创建Flink工程
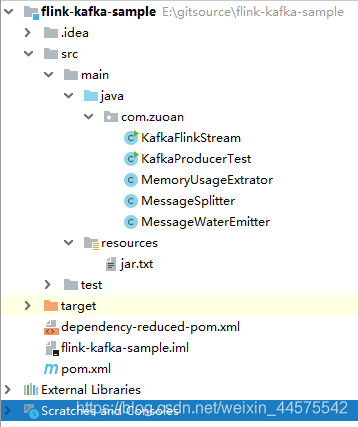
本例使用Intellij IDEA作为项目开发的IDE。首先创建Maven project,group为’com.zuoan’,artifact id为‘flink-kafka-sample’,version为‘1.0-SNAPSHOT’。整个项目结构如图所示:
5.添加依赖
POM文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zuoan</groupId>
<artifactId>flink-kafka-sample</artifactId>
<version>1.0-SNAPSHOT</version>
<description>flink+kafka实例</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.2</version>