辐射神经场算法——NeRF算法详解
辐射神经场算法——NeRF算法详解
NeRF(Neural Radiance Fields)是2020年ECCV会议上的Best Paper,一石激起千层浪,在此之后的两三年的各大顶会上相关文章层出不穷,其影响力可见一斑,NeRF通过隐式表达的方式将新视角合成任务(Novel View Synthesis Task)推向了一个新的高度。那么,什么是“新视角合成任务”呢?什么是“隐式表达”呢?
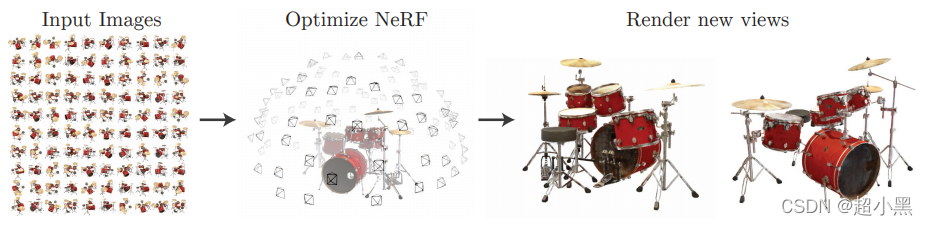
“新视角合成任务"指的是对于某一场景给定某些视角下的观测(图片),通过算法合成新视角下的观测(图片)的任务,如下图所示:
"隐式表达"指的是在渲染过程不对目标物体或者场景进行显示地建模,如果是从SLAM方向过来的同学解决该任务一个很直观的想法就是通过SFM的方法对目标进行三维稠密重建,然后再通过相机模型反投影到新视角下,这种具备三维表达的方法就是典型的显示表达。而NeRF则是通过一个全连接网络替换三维稠密重建的过程,我们并不知道目标在三维空间中的长什么样子,但是可以通过在三维空间中进行采样和积分获得目标在新视角的观测。具体的过程我们在下文进行详细介绍。
1. Volume Rendering方法
NeRF是将神经网络应用于传统物理模型的一个典型例子,我们可以先了解Volume Rendering这一物理模型的定义,这一部分是介绍传统的Volume Rendering方法,仅仅相当于背景介绍,如果想了解NeRF积分公式的推导过程也可以直接跳到第二部分。Volume Rendering在维基百科的定义如下:
立体渲染(英语:Volume rendering),又称为体绘制,是一种用于显示离散三维采样数据集的二维投影的技术。
一个典型的三维数据集是CT或者磁共振成像采集的一组二维切面图像。通常这些数据是按照一定规则如每毫米一个切面,并且通常有一定数目的图像像素。这是一个常见的立体晶格的例子,每个体素用当前体素附近区域的采样值表示。
为了渲染三维数据集的二维投影,首先需要定义相机相对于几何体的空间位置。另外,需要定义每个点即体素的不透明性以及颜色,这通常使用RGBA(red, green, blue, alpha)传递函数定义每个体素可能值对应的RGBA值。
下面我们从Volume Rendering的原理进行推到,并最终会获得和NeRF中的积分公式:
Volume Rendering针对的对象通常为半透明材质,比如烟、云等,发生如下现象:
吸收(absorption):光能转化为介质内其它形式的能(如热能);
外散射(out-scattering):光打在介质粒子上散射到其它方向去了;
自发光(emission):介质内其它形式的能(如热能)转化成光能;
内散射(in-scattering):其它方向来的光打在介质粒子上恰好散射到本方向上;
其中前两者使光线亮度衰减,后两者使光线亮度增强。
为了获得最终的积分公式,我们将从先从微分方程开始推导
一条沿
ω
\omega
ω方向行进的光线,在上任取一点
P
P
P,
P
P
P点出线元为
d
t
dt
dt,光线在经过点
P
P
P之前亮度为
L
L
L,通过
P
P
P亮度获得增量
d
L
dL
dL
对于吸收:
d
L
=
−
σ
a
∗
L
∗
d
t
dL=-\sigma_{a} * L*dt
dL=−σa∗L∗dt其中
σ
a
\sigma_{a}
σa为absorption coefficient,表示点
P
P
P处由于吸收亮度衰减的线密度,上式表明入射亮度越大吸收越大。
对于外散射:
d
L
=
−
σ
s
∗
L
∗
d
i
d L=-\sigma_{s} * L* d_{i}
dL=−σs∗L∗di其中
σ
s
\sigma_{s}
σs为scattering coefficient,表示点
P
P
P处由于散射亮度衰减比例的线密度,上式也表明了入射亮度越大散射越大。
对于自发光:
d
L
=
L
e
∗
d
t
d L=L_{\mathrm{e}} * d t
dL=Le∗dt上式表明自发光的亮度不受入射光线亮度的影响。
对于内散射:
假设亮度为
L
i
L_i
Li的光线
ω
i
\omega_i
ωi方向射向
P
P
P点,则其中
σ
s
∗
d
t
\sigma_{s}*d_t
σs∗dt比例的亮度发生散射,其中
σ
s
\sigma_{s}
σs和外散射公式中的
σ
s
\sigma_{s}
σs含义相同。这部分亮度中有
p
(
ω
i
→
ω
)
d
ω
i
p\left(\omega_{i} \rightarrow \omega\right)d\omega_i
p(ωi→ω)dωi比例恰好散射到
ω
\omega
ω方向上,其中,
p
(
ω
i
→
ω
)
p\left(\omega_{i} \rightarrow \omega\right)
p(ωi→ω)为相phase function,表示从
ω
i
\omega_i
ωi方向射入的光散射到
ω
\omega
ω方向的概率密度。所以
ω
i
\omega_{i}
ωi方向的光线
L
i
L_i
Li贡献的内散射亮度为:
L
i
σ
s
d
t
∗
p
(
ω
i
→
ω
)
d
ω
i
L_{i} \sigma_{s} d t^{*} p\left(\omega_{i} \rightarrow \omega\right) d \omega_{i}
Liσsdt∗p(ωi→ω)dωi由于所有方向都对内散射亮度都有贡献,所以对上述做球面积分,即得到点
P
P
P处因内散射增加的总亮度为:
d
L
=
∫
Ω
L
i
σ
s
d
t
∗
p
(
ω
i
→
ω
)
d
ω
i
=
(
σ
s
∫
Ω
p
(
ω
i
→
ω
)
L
i
d
ω
i
)
d
t
d L=\int_{\Omega} L_{i} \sigma_{s} d t * p\left(\omega_{i} \rightarrow \omega\right) d \omega_{i}=\left(\sigma_{s} \int_{\Omega} p\left(\omega_{i} \rightarrow \omega\right) L_{i} d \omega_{i}\right) d t
dL=∫ΩLiσsdt∗p(ωi→ω)dωi=(σs∫Ωp(ωi→ω)Lidωi)dt综合吸收、外散射、自发光、内散射四种效应可以得到:
d
L
=
−
σ
a
∗
L
∗
d
t
−
σ
s
∗
L
∗
d
t
+
L
e
∗
d
t
+
(
σ
s
∫
Ω
p
(
ω
i
→
ω
)
L
i
d
ω
i
)
∗
d
t
d L=-\sigma_{a} * L* d t-\sigma_{s} * L* d t+L_{e} * d t+\left(\sigma_{s} \int_{\Omega} p\left(\omega_{i} \rightarrow \omega\right) L_{i} d \omega_{i}\right) * d t
dL=−σa∗L∗dt−σs∗L∗dt+Le∗dt+(σs∫Ωp(ωi→ω)Lidωi)∗dt为了简化公式,我们可以令:
σ
t
=
σ
a
+
σ
s
\sigma_{t}=\sigma_{a}+\sigma_{s}
σt=σa+σs
S
=
L
e
+
σ
s
∫
Ω
p
(
ω
i
,
ω
)
L
i
d
ω
i
S=L_{e}+\sigma_{s} \int_{\Omega} p\left(\omega_{i}, \omega\right) L_{i} d \omega_{i}
S=Le+σs∫Ωp(ωi,ω)Lidωi则方程简化为:
d
L
d
t
=
−
σ
t
L
+
S
\frac{d L}{d t}=-\sigma_{t} L+S
dtdL=−σtL+S这就是我们需要的传输方程,其中
σ
t
\sigma_t
σt被称为attenuation coefficient或者extinction coefficient。
S
S
S为自发光和内散射的和,通常被成为source term,
−
σ
t
L
-\sigma_{t} L
−σtL通常被成为attenuation term。
有了微分方程,接下来我们就可以对其进行求解
如果忽略自发光和内散射,则传输方程可以简化齐次线性微分方程为 d L d t = − σ t ( t ) L \frac{d L}{d t}=-\sigma_{t}(t) L dtdL=−σt(t)L其通解为: L = C e − ∫ σ t ( t ) d t = C e − ∫ 0 t σ t ( x ) d x L=C e^{-\int \sigma_{t}(t) d t}=C^{} e^{-\int_{0}^{t} \sigma_{t}(x) d x} L=Ce−∫σt(t)dt=Ce−∫0tσt(x)dx代入初值 t = 0 t=0 t=0时 L = L 0 L=L_0 L=L0,解得 C = L 0 C=L_0 C=L0,因此: L = L 0 e − ∫ 0 t σ t ( x ) d x L=L_{0} e^{-\int_{0}^{t} \sigma_{t}(x) d x} L=L0e−∫0tσt(x)dx这是不考虑自发光和内散射情况下的方程的解,表示亮度为 L 0 L_0 L0的光线经过 t t t这么长距离后的亮度。特别地,如果 σ t \sigma_t σt为常数,则简化为: L = L 0 e − σ t t L=L_{0} e^{-\sigma_{t} t} L=L0e−σtt即光线穿越均匀的参与截止过程中,亮度呈指数衰减,这就是比尔定律。通常我们定义光学厚度为 τ ( p ( 0 ) → p ( t ) ) = ∫ 0 t σ t ( x ) d x \tau(p(0) \rightarrow p(t))=\int_{0}^{t} \sigma_{t}(x) d x τ(p(0)→p(t))=∫0tσt(x)dx定义亮度衰减系数为 T r ( p ( 0 ) → p ( t ) ) = e − ∫ 0 t σ t ( x ) d x = e − τ ( p ( 0 ) → p ( t ) ) T_{r}(p(0) \rightarrow p(t))=e^{-\int_{0}^{t} \sigma_{t}(x) d x}=e^{-\tau(p(0) \rightarrow p(t))} Tr(p(0)→p(t))=e−∫0tσt(x)dx=e−τ(p(0)→p(t))
如果我们考虑所有现象,则微分方程非齐次线性微分方程为:
d
L
d
t
=
−
σ
t
(
t
)
L
+
S
(
t
)
\frac{d L}{d t}=-\sigma_{t}(t) L+S(t)
dtdL=−σt(t)L+S(t)其通解(推导过程参考一阶非齐次线性微分方程 - 推导通解公式)为
L
=
e
−
∫
σ
t
(
t
)
d
t
∫
S
(
t
)
e
∫
σ
t
(
t
)
d
t
d
t
+
C
e
−
∫
σ
t
(
t
)
d
t
L=e^{-\int \sigma_{t}(t) d t} \int S(t) e^{\int \sigma_{t}(t) d t} d t+C e^{-\int \sigma_{t}(t) d t}
L=e−∫σt(t)dt∫S(t)e∫σt(t)dtdt+Ce−∫σt(t)dt我们对其进行恒等变形:
L
=
e
−
∫
0
t
σ
t
(
x
)
d
x
∫
0
t
S
(
x
)
e
∫
0
x
σ
t
(
u
)
d
u
d
x
+
C
e
−
∫
0
t
σ
t
(
x
)
d
x
L=e^{-\int_{0}^{t} \sigma_{t}(x) d x} \int_{0}^{t} S(x) e^{\int_{0}^{x} \sigma_{t}(u) d u} d x+C^{} e^{-\int_{0}^{t} \sigma_{t}(x) d x}
L=e−∫0tσt(x)dx∫0tS(x)e∫0xσt(u)dudx+Ce−∫0tσt(x)dx
L
=
∫
0
t
S
(
x
)
e
∫
0
x
σ
t
(
u
)
d
u
e
−
∫
0
t
σ
t
(
u
)
d
u
d
x
+
C
e
−
∫
0
t
σ
t
(
x
)
d
x
L=\int_{0}^{t} S(x) e^{\int_{0}^{x} \sigma_{t}(u) d u} e^{-\int_{0}^{t} \sigma_{t}(u) d u} d x+C^{} e^{-\int_{0}^{t} \sigma_{t}(x) d x}
L=∫0tS(x)e∫0xσt(u)due−∫0tσt(u)dudx+Ce−∫0tσt(x)dx
L
=
∫
0
t
S
(
x
)
e
−
∫
x
t
σ
t
(
u
)
d
u
d
x
+
C
e
−
∫
0
t
σ
t
(
x
)
d
x
L=\int_{0}^{t} S(x) e^{-\int_{x}^{t} \sigma_{t}(u) d u} d x+C^{} e^{-\int_{0}^{t} \sigma_{t}(x) d x}
L=∫0tS(x)e−∫xtσt(u)dudx+Ce−∫0tσt(x)dx
L
=
∫
0
t
S
(
x
)
T
r
(
p
(
x
)
→
p
(
t
)
)
d
x
+
C
T
r
(
p
(
0
)
→
p
(
t
)
)
L=\int_{0}^{t} S(x) T_{r}(p(x) \rightarrow p(t)) d x+C^{} T_{r}(p(0) \rightarrow p(t))
L=∫0tS(x)Tr(p(x)→p(t))dx+CTr(p(0)→p(t))代入初值
t
=
0
t=0
t=0时
L
=
L
0
L=L_0
L=L0,解的
C
=
L
0
C=L_0
C=L0,所以
L
=
∫
0
t
S
(
x
)
T
r
(
p
(
x
)
→
p
(
t
)
)
d
x
+
L
0
T
r
(
p
(
0
)
→
p
(
t
)
)
L=\int_{0}^{t} S(x) T_{r}(p(x) \rightarrow p(t)) d x+L_{0} T_{r}(p(0) \rightarrow p(t))
L=∫0tS(x)Tr(p(x)→p(t))dx+L0Tr(p(0)→p(t))这是所有现象情况下的方程的解,表示亮度为
L
0
L_0
L0的光线经过
t
t
t这么长距离后的亮度。我们进一步分析,
p
(
t
)
p(t)
p(t)处的亮度由两部分组成:
第一部分:
C
T
r
(
p
(
0
)
→
p
(
t
)
)
C^{} T_{r}(p(0) \rightarrow p(t))
CTr(p(0)→p(t))是
p
(
0
)
p(0)
p(0)处的输入亮度
L
0
L_0
L0经过
T
r
(
p
(
0
)
→
p
(
t
)
)
T_{r}(p(0) \rightarrow p(t))
Tr(p(0)→p(t))衰减后的亮度
第二部分:
S
(
x
)
T
r
(
p
(
x
)
→
p
(
t
)
)
S(x) T_{r}(p(x) \rightarrow p(t))
S(x)Tr(p(x)→p(t))是
p
x
px
px处自发光和内散射亮度之和
S
(
x
)
S(x)
S(x)经过
T
r
(
p
(
0
)
→
p
(
t
)
)
T_{r}(p(0) \rightarrow p(t))
Tr(p(0)→p(t))衰减后的亮度,由于
p
(
0
)
p(0)
p(0)到
p
(
t
)
p(t)
p(t)上各点都产生自发光和内散射,因此其积分是从
0
0
0到
t
t
t的。
2. NeRF中的积分公式推导
以上是在图形学中Volume Rendering方法的一种定义,下面我们看看该方法在NeRF中是如何定义的(以下并非官方推导,觉得有问题的同学欢迎交流):
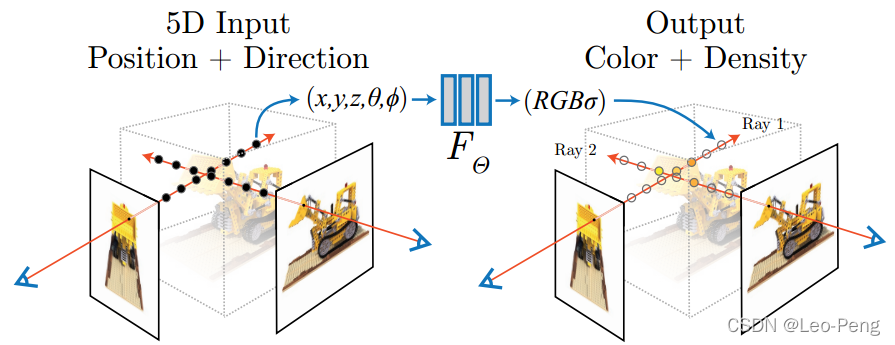
如上图所示,在原始NeRF中,我们想要获得的是新视角下的图像,将经过相机光心和图像平面上像素的这样一条射线(图中射线的方向和Volume Rendering推导过程中的光线的方向是相反的,但是这并不影响最后的结果)我们标记为
r
(
t
)
=
o
+
t
d
\boldsymbol{r}(t)=\boldsymbol{o}+t \boldsymbol{d}
r(t)=o+td,其中
o
\boldsymbol{o}
o为射线原点,
d
\boldsymbol{d}
d为射线角度,下面我们开始推导:
NeRF的任务主要是对颜色进行Rendering,而不是对亮度进行Rendering,因此我们Volume Rendering的对象不再是
L
(
t
)
L(t)
L(t)而是
C
(
t
)
\boldsymbol{C}(t)
C(t),颜色主要是由光线的波长决定,而光线通过半透明物体时波长会发生变化,也即颜色会发生变化,这种变化的规则遵循Alpha Blending原理:
C
a
=
(
1
−
α
)
C
b
+
α
C
o
\boldsymbol{C}_{a} = (1-\alpha)\boldsymbol{C}_{b}+\alpha\boldsymbol{C}_{o}
Ca=(1−α)Cb+αCo其中
α
\alpha
α为不透明度,
C
a
\boldsymbol{C}_{a}
Ca为Blending后的颜色,
C
b
\boldsymbol{C}_{b}
Cb为Blending前的颜色,
C
o
\boldsymbol{C}_{o}
Co为半透明物体的颜色,我们令
α
=
σ
d
t
\alpha=\sigma dt
α=σdt,其中
σ
\sigma
σ为单位不透明度,我们对上式进行恒等变形:
C
a
−
C
b
=
σ
(
C
o
−
C
b
)
d
t
\boldsymbol{C}_{a}-\boldsymbol{C}_{b}=\sigma(\boldsymbol{C}_{o}-\boldsymbol{C}_{b})dt
Ca−Cb=σ(Co−Cb)dt我们令
σ
(
t
)
=
σ
\sigma(t)=\sigma
σ(t)=σ和
c
(
t
)
=
C
o
\boldsymbol{c}(t)=\boldsymbol{C}_o
c(t)=Co均为随射线位置
t
t
t变化的指,进一步变换成微分形式有:
d
C
d
t
=
−
σ
(
t
)
C
+
σ
(
t
)
c
(
t
)
\frac{d\boldsymbol{C}}{dt}=-\sigma(t) \boldsymbol{C}+\sigma(t) \boldsymbol{c}(t)
dtdC=−σ(t)C+σ(t)c(t)这样就得到了和上面Volume Rendering几乎相同的非齐次线性微分方程,其通解为:
C
=
e
−
∫
σ
(
t
)
d
t
∫
σ
(
t
)
c
(
t
)
e
∫
σ
(
t
)
d
t
d
t
+
C
e
−
∫
σ
(
t
)
d
t
\boldsymbol{C}=e^{-\int \sigma(t) d t} \int \sigma(t) \boldsymbol{c}(t) e^{\int \sigma(t) d t} d t+C e^{-\int \sigma(t) d t}
C=e−∫σ(t)dt∫σ(t)c(t)e∫σ(t)dtdt+Ce−∫σ(t)dt在NeRF相关的问题中我们规定
t
n
t_n
tn和
t
f
t_f
tf为积分的最近端和最远端
C
=
e
−
∫
t
n
t
f
σ
(
t
)
d
t
∫
t
n
t
f
σ
(
t
)
c
(
t
)
e
∫
t
f
t
σ
(
s
)
d
s
d
t
+
C
e
−
∫
t
n
t
f
σ
(
t
)
d
t
\boldsymbol{C}=e^{-\int_{t_n}^{t_f} \sigma(t) d t} \int_{t_n}^{t_f} \sigma(t) \boldsymbol{c}(t) e^{\int_{t_f}^{t} \sigma(s) d s} d t+C^{} e^{-\int_{t_n}^{t_f} \sigma(t) dt}
C=e−∫tntfσ(t)dt∫tntfσ(t)c(t)e∫tftσ(s)dsdt+Ce−∫tntfσ(t)dt
C
=
∫
t
n
t
f
σ
(
t
)
c
(
t
)
e
∫
t
f
t
σ
(
s
)
d
s
e
−
∫
t
n
t
f
σ
(
s
)
d
s
d
t
+
C
e
−
∫
t
n
t
f
σ
(
t
)
d
t
\boldsymbol{C}=\int_{t_n}^{t_f} \sigma(t) \boldsymbol{c}(t) e^{\int_{t_f}^{t} \sigma(s) d s} e^{-\int_{t_n}^{t_f} \sigma(s) d s} d t+C^{} e^{-\int_{t_n}^{t_f} \sigma(t) d t}
C=∫tntfσ(t)c(t)e∫tftσ(s)dse−∫tntfσ(s)dsdt+Ce−∫tntfσ(t)dt
C
=
∫
t
n
t
f
σ
(
t
)
c
(
t
)
e
−
∫
t
t
n
σ
(
s
)
d
s
d
t
+
C
e
−
∫
t
n
t
f
σ
(
t
)
d
t
\boldsymbol{C}=\int_{t_n}^{t_f} \sigma(t) \boldsymbol{c}(t) e^{-\int_{t}^{t_n} \sigma(s) d s} d t+C^{} e^{-\int_{t_n}^{t_f} \sigma(t) dt}
C=∫tntfσ(t)c(t)e−∫ttnσ(s)dsdt+Ce−∫tntfσ(t)dt我们认为射线的初值为零,即
C
=
0
C=0
C=0,那么经过这条射线积分在图像平面上获得的颜色为:
C
(
r
)
=
∫
t
n
t
f
T
(
t
)
⋅
σ
(
r
(
t
)
)
⋅
c
(
r
(
t
)
,
d
)
d
t
\boldsymbol{C}(r)=\int_{t_{n}}^{t_{f}} T(t) \cdot \sigma(\boldsymbol{r}(t)) \cdot \boldsymbol{c}(\boldsymbol{r}(t), \boldsymbol{d}) d t
C(r)=∫tntfT(t)⋅σ(r(t))⋅c(r(t),d)dt
T
(
t
)
=
exp
(
−
∫
t
n
t
σ
(
r
(
s
)
)
d
s
)
T(t)=\exp \left(-\int_{t_{n}}^{t} \sigma(\boldsymbol{r}(s)) d s\right)
T(t)=exp(−∫tntσ(r(s))ds)以上就是NeRF公式的推导过程,其中有些比如从远往近处积分和从近往远处积分值应该是相同的这样一些细节没有做过多强调,我们理解NeRF的积分公式是如何推导过来就可以了,在网上有些博客中,说
σ
\sigma
σ是一条射线
r
\boldsymbol{r}
r在经过
t
t
t处的一个无穷小的粒子时被终止的概率,或者说是不透明度,是有道理的。而衰减公式
T
(
t
)
T(t)
T(t)则是累计透明度,是这条射线
t
n
t_n
tn从到
t
t
t一路上没有击中任何粒子的概率,也是合理的。
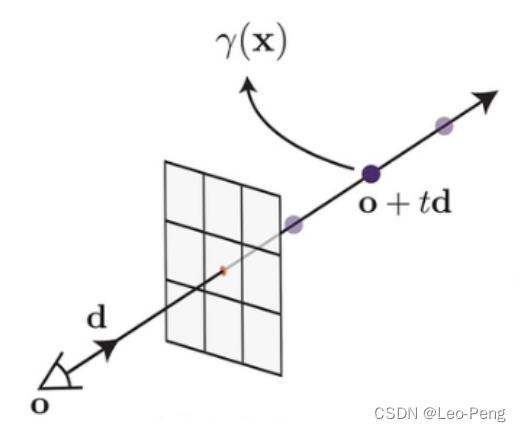
在具体的代码实现中,程序是无法进行连续积分的,因此在以上的基础上还需要进行离散化,首先,在射线上进行均匀随机采样获取采样点,这里要注意的是是均匀随机采样,而不是均匀采样,因此在训练过程中同一条射线采样点也会不相同,但也正式因为是均匀随机采样,才尽可能避免了因为采样点的频率而限制了NeRF的分辨率。
第 i i i个采样点可以表示为: t i = U [ t n + i − 1 N ( t f − t n ) , t n + i N ( t f − t n ) ] t_{i}=\boldsymbol{U}\left[t_{n}+\frac{i-1}{N}\left(t_{f}-t_{n}\right), t_{n}+\frac{i}{N}\left(t_{f}-t_{n}\right)\right] ti=U[tn+Ni−1(tf−tn),tn+Ni(tf−tn)]基于这些采样点,我们可以讲上述积分简化为求和的形式: C ^ ( r ) = ∑ i = 1 N T i ⋅ ( 1 − exp ( − σ i ⋅ δ i ) ) ⋅ c i \hat{C}(\boldsymbol{r})=\sum_{i=1}^{N} T_{i} \cdot\left(1-\exp \left(-\sigma_{i} \cdot \delta_{i}\right)\right) \cdot \boldsymbol{c}_{i} C^(r)=i=1∑NTi⋅(1−exp(−σi⋅δi))⋅ci其中, δ i = t i + 1 − t i \delta_{i}=t_{i+1}-t_{i} δi=ti+1−ti是邻近两个采样点之间的距离。此处 T ( t ) T(t) T(t)为 T i = exp ( − ∑ j = 1 i − 1 σ j δ j ) T_{i}=\exp \left(-\sum_{j=1}^{i-1} \sigma_{j} \delta_{j}\right) Ti=exp(−j=1∑i−1σjδj)我们根据像素坐标生成一条射线,在射线上均匀随机采样,将采样点的位置和射线角度输入一个全卷积网络,网络输出该采样点的颜色和不透明度,按照上述公式积分采样点的颜色和不透明度,基于这样的方式,我们就可以从任意角度中渲染出图片。
3. NeRF中应用的技巧
如果直接将全卷积网络应用到上述方法中,效果其实是不尽人意的,为此,NeRF的作者还引入了Positional Encoding和Hierarchical Volume Sampling,最终NeRF才达到令人惊艳的效果。
3.1 Positional Encoding
Positional Encoding类似于傅里叶变换,在图像降噪领域中,一种很经典的处理方式就是通过傅里叶变换将空域输入转到频域,以达到升维和提取有效信息的作用。在NeRF中也是如此,Positional Encoding的公式如下:
γ
(
p
)
=
(
sin
(
2
0
π
p
)
,
cos
(
2
0
π
p
)
,
⋯
,
sin
(
2
L
−
1
π
p
)
,
cos
(
2
L
−
1
π
p
)
)
\gamma(p)=\left(\sin \left(2^{0} \pi p\right), \cos \left(2^{0} \pi p\right), \cdots, \sin \left(2^{L-1} \pi p\right), \cos \left(2^{L-1} \pi p\right)\right)
γ(p)=(sin(20πp),cos(20πp),⋯,sin(2L−1πp),cos(2L−1πp))其中
p
p
p为输入,即射线上采样点的位置和射线入射方向,
L
L
L为Positional Encoding的维度,是一个可以调整的超参,L越大相当于提取了更高频的信息,网络对应也会输出更高频的内容,关于Positional Encoding的研究NeRF的作者还有一篇专门的论文Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains,感兴趣的读者可以进一步深入。在NeRF原论文中也有相关的Ablation Study如下:

3.2 Hierarchical Volume Sampling
NeRF最终的效果还和采样点的分布以及采样点频率相关,在没有采样点分布的先验的情况下,如果想要达到较高的精度就需要较高的采样点频率,这样势必会造成更大的计算量,为了解决这个问题,作者提出了Hierarchical Volume Sampling方法,即先按照均匀随机采样进行一次粗采样,将粗采样的输出的不透明度结果转化为分布,再根据分布进行一次精采样,最后NeRF训练的损失也是粗采样和精采样结果相加的结果,这样就实现了一个自动化Coarse-To-Fine的训练过程。
关于Positional Encoding和Hierarchical Volume Sampling这两个技巧很好理解,在其他博客中也有非常详细的介绍,在此我就不再赘述。
4. NeRF代码简析
NeRF相关的代码推荐kwea123/nerf_pl,代码结构很清晰,而且注释也很清楚,我们选取其中最核心的部分代码如下,在其中补充了一些和本文相关的注释:
def render_rays(models,
embeddings,
rays,
N_samples=64,
use_disp=False,
perturb=0,
noise_std=1,
N_importance=0,
chunk=1024*32,
white_back=False,
test_time=False
):
"""
Render rays by computing the output of @model applied on @rays
Inputs:
models: list of NeRF models (coarse and fine) defined in nerf.py
embeddings: list of embedding models of origin and direction defined in nerf.py
rays: (N_rays, 3+3+2), ray origins, directions and near, far depth bounds
N_samples: number of coarse samples per ray
use_disp: whether to sample in disparity space (inverse depth)
perturb: factor to perturb the sampling position on the ray (for coarse model only)
noise_std: factor to perturb the model's prediction of sigma
N_importance: number of fine samples per ray
chunk: the chunk size in batched inference
white_back: whether the background is white (dataset dependent)
test_time: whether it is test (inference only) or not. If True, it will not do inference
on coarse rgb to save time
Outputs:
result: dictionary containing final rgb and depth maps for coarse and fine models
"""
# 这个闭包函数输入一系列采样点的xyz和dir,通过Positional Encoding(也就是代码中的embdding_xyz函数)、
# MLP网络推理和积分等操作最终输出对应像素的颜色和相机坐标系下的深度
def inference(model, embedding_xyz, xyz_, dir_, dir_embedded, z_vals, weights_only=False):
"""
Helper function that performs model inference.
Inputs:
model: NeRF model (coarse or fine)
embedding_xyz: embedding module for xyz
xyz_: (N_rays, N_samples_, 3) sampled positions
N_samples_ is the number of sampled points in each ray;
= N_samples for coarse model
= N_samples+N_importance for fine model
dir_: (N_rays, 3) ray directions
dir_embedded: (N_rays, embed_dir_channels) embedded directions
z_vals: (N_rays, N_samples_) depths of the sampled positions
weights_only: do inference on sigma only or not
Outputs:
if weights_only:
weights: (N_rays, N_samples_): weights of each sample
else:
rgb_final: (N_rays, 3) the final rgb image
depth_final: (N_rays) depth map
weights: (N_rays, N_samples_): weights of each sample
"""
N_samples_ = xyz_.shape[1]
# Embed directions
xyz_ = xyz_.view(-1, 3) # (N_rays*N_samples_, 3)
if not weights_only:
dir_embedded = torch.repeat_interleave(dir_embedded, repeats=N_samples_, dim=0)
# (N_rays*N_samples_, embed_dir_channels)
# Perform model inference to get rgb and raw sigma
B = xyz_.shape[0]
out_chunks = []
for i in range(0, B, chunk):
# Embed positions by chunk
xyz_embedded = embedding_xyz(xyz_[i:i+chunk]) # 这里就是对空间坐标进行Positional Encoding的部分
if not weights_only:
xyzdir_embedded = torch.cat([xyz_embedded,
dir_embedded[i:i+chunk]], 1)
else:
xyzdir_embedded = xyz_embedded
# 这里就是MLP网络推理部分
out_chunks += [model(xyzdir_embedded, sigma_only=weights_only)]
out = torch.cat(out_chunks, 0)
if weights_only:
sigmas = out.view(N_rays, N_samples_)
else:
rgbsigma = out.view(N_rays, N_samples_, 4)
rgbs = rgbsigma[..., :3] # (N_rays, N_samples_, 3)
sigmas = rgbsigma[..., 3] # (N_rays, N_samples_)
# 这一部分就是离散积分的准备部分,每一行表示一个ray,每一列是一个采样点,保存的是采样点间的距离
# Convert these values using volume rendering (Section 4)
deltas = z_vals[:, 1:] - z_vals[:, :-1] # (N_rays, N_samples_-1)
delta_inf = 1e10 * torch.ones_like(deltas[:, :1]) # (N_rays, 1) the last delta is infinity
deltas = torch.cat([deltas, delta_inf], -1) # (N_rays, N_samples_)
# Multiply each distance by the norm of its corresponding direction ray
# to convert to real world distance (accounts for non-unit directions).
deltas = deltas * torch.norm(dir_.unsqueeze(1), dim=-1)
# 注意在训练的过程中除了采样点的位置增加随机部分,在输出的sigma部分也会加入随机的成分
# 这应该是数一种正则化的操作
noise = torch.randn(sigmas.shape, device=sigmas.device) * noise_std
# 这里就是正式根据离散积分公式对权重和结果进行积分,包括下面的求和部分,这里矩阵操作上的大家在纸上画一画应该就明白了
# compute alpha by the formula (3)
alphas = 1-torch.exp(-deltas*torch.relu(sigmas+noise)) # (N_rays, N_samples_)
alphas_shifted = torch.cat([torch.ones_like(alphas[:, :1]), 1-alphas+1e-10], -1) # [1, a1, a2, ...]
weights = alphas * torch.cumprod(alphas_shifted, -1)[:, :-1] # (N_rays, N_samples_)
weights_sum = weights.sum(1) # (N_rays), the accumulated opacity along the rays
# equals "1 - (1-a1)(1-a2)...(1-an)" mathematically
if weights_only:
return weights
# compute final weighted outputs
rgb_final = torch.sum(weights.unsqueeze(-1)*rgbs, -2) # (N_rays, 3)
depth_final = torch.sum(weights*z_vals, -1) # (N_rays)
if white_back:
rgb_final = rgb_final + 1-weights_sum.unsqueeze(-1)
return rgb_final, depth_final, weights
# Extract models from lists
model_coarse = models[0]
embedding_xyz = embeddings[0]
embedding_dir = embeddings[1]
# Decompose the inputs
N_rays = rays.shape[0]
rays_o, rays_d = rays[:, 0:3], rays[:, 3:6] # both (N_rays, 3)
near, far = rays[:, 6:7], rays[:, 7:8] # both (N_rays, 1)
# Embed direction
dir_embedded = embedding_dir(rays_d) # (N_rays, embed_dir_channels)
# 在NeRF中我们是需要给定一个采样范围的,分别就是代码中的near和far,采样如下所示,可以在欧氏空间均匀采样
# 也可以在逆深度坐标系下均匀采样,通常前者主要用于NDT坐标系
# Sample depth points
z_steps = torch.linspace(0, 1, N_samples, device=rays.device) # (N_samples)
if not use_disp: # use linear sampling in depth space
z_vals = near * (1-z_steps) + far * z_steps
else: # use linear sampling in disparity space
z_vals = 1/(1/near * (1-z_steps) + 1/far * z_steps)
z_vals = z_vals.expand(N_rays, N_samples)
# 这是粗采样部分,要注意其中有一个perburb_rand,也就是均匀随机采样中的随机部分
if perturb > 0: # perturb sampling depths (z_vals)
z_vals_mid = 0.5 * (z_vals[: ,:-1] + z_vals[: ,1:]) # (N_rays, N_samples-1) interval mid points
# get intervals between samples
upper = torch.cat([z_vals_mid, z_vals[: ,-1:]], -1)
lower = torch.cat([z_vals[: ,:1], z_vals_mid], -1)
perturb_rand = perturb * torch.rand(z_vals.shape, device=rays.device)
z_vals = lower + (upper - lower) * perturb_rand
xyz_coarse_sampled = rays_o.unsqueeze(1) + \
rays_d.unsqueeze(1) * z_vals.unsqueeze(2) # (N_rays, N_samples, 3)
# 以下是进行粗采样结果的推理
if test_time:
weights_coarse = \
inference(model_coarse, embedding_xyz, xyz_coarse_sampled, rays_d,
dir_embedded, z_vals, weights_only=True)
result = {'opacity_coarse': weights_coarse.sum(1)}
else:
rgb_coarse, depth_coarse, weights_coarse = \
inference(model_coarse, embedding_xyz, xyz_coarse_sampled, rays_d,
dir_embedded, z_vals, weights_only=False)
result = {'rgb_coarse': rgb_coarse,
'depth_coarse': depth_coarse,
'opacity_coarse': weights_coarse.sum(1)
}
# 接下来是精采样的采样和推理部分
if N_importance > 0: # sample points for fine model
z_vals_mid = 0.5 * (z_vals[: ,:-1] + z_vals[: ,1:]) # (N_rays, N_samples-1) interval mid points
z_vals_ = sample_pdf(z_vals_mid, weights_coarse[:, 1:-1],
N_importance, det=(perturb==0)).detach()
# detach so that grad doesn't propogate to weights_coarse from here
z_vals, _ = torch.sort(torch.cat([z_vals, z_vals_], -1), -1)
xyz_fine_sampled = rays_o.unsqueeze(1) + \
rays_d.unsqueeze(1) * z_vals.unsqueeze(2)
# (N_rays, N_samples+N_importance, 3)
model_fine = models[1]
rgb_fine, depth_fine, weights_fine = \
inference(model_fine, embedding_xyz, xyz_fine_sampled, rays_d,
dir_embedded, z_vals, weights_only=False)
result['rgb_fine'] = rgb_fine
result['depth_fine'] = depth_fine
result['opacity_fine'] = weights_fine.sum(1)
return result
以上主要是对NeRF的基本原理进行介绍,基于原始NeRF改进的一些方法我整理在另外一篇博客中辐射神经场算法——NeRF++ / Wild-NeRF / Mipi-NeRF / BARF / NSVF / Semantic-NeRF,感兴趣的读者可以参考。有问题欢迎交流~