A Causal Inference Look at Unsupervised Video Anomaly Detection 论文阅读
文章信息:

发表于:2022AAAI
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/20053
源码:无
Abstract
无监督视频异常检测是一项无需任何形式的标注正常/异常训练数据的任务,这项任务虽然具有挑战性,但对工业应用和学术研究都具有重要意义。现有方法通常采用迭代的伪标签生成过程。然而,这些方法缺乏对伪标签生成过程对训练影响的系统性分析。此外,它们还忽略了对长期时序依赖的考虑,这是不合理的,因为异常事件的定义依赖于长期时序上下文。为此,我们首先提出了一个因果图,用于分析伪标签生成过程中的混杂效应。接着,我们引入了一个基于因果推断的简单而有效的框架,用于消除噪声伪标签的影响。最后,我们在推断阶段进行基于反事实的模型集成,将长期时序上下文与局部图像上下文相结合,从而完成最终的异常检测。在六个标准基准数据集上的大量实验表明,我们提出的方法显著优于现有的最新方法,验证了我们框架的有效性。
Introduction
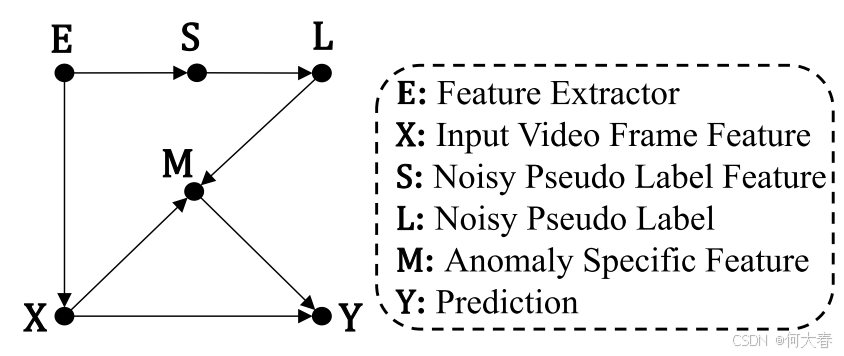
图 1:所提出的因果图,用于解释带噪伪标签的因果效应。
视频异常检测(Video Anomaly Detection, VAD)指的是检测视频帧中显著偏离正常模式的异常事件,例如异常的行人运动模式、交通事故和被抛出的物体等。由于这一任务在实际中的重要性,它吸引了工业界和学术界的广泛研究。这些研究中的大多数都遵循一种典型设置,即数据集中要么有一组标注的异常事件,要么训练数据集必须仅包含正常视频,这在一定程度上限制了此类研究的广泛应用。与之相对,另一类研究则致力于设计完全无监督的算法,即在这种设置下,不提供任何形式的标注正常/异常训练数据。在本文中,我们聚焦于这种无监督视频异常检测(Unsupervised Video Anomaly Detection, UVAD)。为了进行训练监督,通常采用自训练方法,并结合迭代的伪标签生成,这是一种被广泛研究和使用的技术。
$
尽管使用上述伪标签训练的异常检测模型表现出具有竞争力的性能,但其性能提升主要来源于正确的伪标签。由于缺乏对错误伪标签所带来的负面影响的系统性分析,性能的进一步提升受到了限制。为了更好地理解噪声伪标签的影响并深入研究这一现象,我们从因果推断的角度研究这一问题。根据图1,UVAD任务旨在学习一个能够估计 ( P(Y|X,M) ) 的模型。伪标签生成过程( E → S → L E → S → L E→S→L)会产生噪声伪标签集合 L L L,用于监督异常特定特征表示 M M M 的学习(即 P ( Y ∣ X , M ) P(Y|X,M) P(Y∣X,M) 中的 M M M)。
一方面,正确的伪标签有助于异常特定特征表示 M M M的学习,从而带来显著的性能提升。这在图1中表示为中介因果路径( X → M → Y X → M → Y X→M→Y)。另一方面,错误的伪标签通过后门路径( X ← E → S → L → M → Y X ← E → S → L → M → Y X←E→S→L→M→Y)混淆了 X X X 和 Y Y Y 之间的关系。后门路径的定义是:路径的一端箭头指向 X X X,另一端箭头指向 Y Y Y,导致 X X X 和 Y Y Y 假相关。换句话说,这条因果路径会带来负面影响,将一些异常/正常事件与正常/异常标签错误关联,从而误导分类器,导致偏向错误预测。因此,我们推测上述两条因果路径的混合因果效应是性能瓶颈的主要原因之一。此外,长期时序上下文与图像帧外观之间的交互对于区分异常视频帧至关重要。现有方法通过收集一小范围的邻近视频帧作为输入来实现这些交互,但这种方法缺乏充分利用视频活动中长期时序上下文的能力,因为短期时序上下文通常包含不一致的时序信息(参考文献:Yu et al., 2020; Pang et al., 2020; Ionescu et al., 2017; Giorno, Bagnell, 和 Hebert, 2016; Wang et al., 2018)。
基于上述分析,我们提出了一种新的两阶段因果推断管道,旨在消除噪声伪标签的影响并结合长期时序上下文。具体来说,在第一阶段,我们通过保留有益的中介路径并去除后门路径(如图3所示),实现去混杂训练。然后,在第二阶段,我们通过基于反事实的模型集成,将第一阶段训练的模型预测结果与相同模型在输入替换为基于长期滑动窗口的上下文特征但保持中介变量 M M M 不变的预测结果相加,从而实现模型集成(如图4所示)。需要注意的是,第二阶段不需要额外的训练,这意味着我们只需进行两次推断即可获得反事实模型集成的预测结果,这种方法轻量且无需额外开销。整个管道如图5所示。
综上所述,本文有以下贡献:
-
据我们所知,我们是首个从因果推断的角度研究噪声伪标签在无监督视频异常检测(UVAD)中的影响,并发现伪标签生成过程中存在一种混杂效应,这种效应限制了性能的进一步提升。
-
我们引入了一种迭代的两阶段因果推断框架,用于消除噪声伪标签的影响。具体而言,我们通过因果干预进行去混杂训练,以消除有害的后门因果路径,并结合训练好的模型执行基于反事实的长期时序上下文集成。
-
我们的方法显著超越了所有现有方法,在六个标准数据集上达到了新的最先进性能。
Related Works
Unsupervised Video Anomaly Detection.Giorno 等人(Giorno, Bagnell 和 Hebert, 2016)首次提出了 UVAD 问题,并提出使用置换检验来检测帧序列中的变化,以识别哪些帧与之前的所有帧存在显著差异。Ionescu 等人(Ionescu et al., 2017)去除了置换检验,改用解屏蔽(unmasking)方法,根据分类准确性的变化来衡量异常性。Wang 等人(Wang et al., 2018)从自编码器的角度出发,解决了 UVAD 任务。与我们工作最相似的是 Pang 等人(Pang et al., 2020),他们首次采用 Sp+iForest(Liu, Ting 和 Zhou, 2012)生成视频帧的伪标签,并以端到端的方式迭代训练了一个自监督的深度有序回归模型。然而,我们的工作与其在以下几个方面有所不同:
- 我们从因果推断的角度分析了伪标签生成在 Pang 等人(2020)方法中的作用,并发现其对 P ( Y ∣ X , M ) P(Y|X,M) P(Y∣X,M) 存在混杂效应。
- 我们提出通过后门调整方法显式消除混杂效应,即通过对伪标签特征 S S S 进行分层(干预),阻断 X ← E → S → L → M → Y X ← E → S → L → M → Y X←E→S→L→M→Y 的路径。
- 我们通过基于反事实的模型集成将长期时序上下文的先验信息注入模型预测中,并且计算成本可以忽略不计。
Causal Inference.这是一种统计工具,可以帮助模型推断感兴趣变量之间的因果效应。因果推断已在统计学、心理学、经济学和社会学中被广泛研究和应用(Morgan and Winship, 2014; Chernozhukov, Fernández-Val, and Melly, 2009; Rubin, 2005; Petersen, Sinisi, and van der Laan, 2006; Pearl, 2001)。近年来,因果推断在许多计算机相关问题中的应用研究显著增加,包括自然语言处理(Liu et al., 2021; Keith, Jensen, and O’Connor, 2020)、计算机视觉(Tang et al., 2020; Zhang et al., 2020; Wang et al., 2020)、机器人学(Ahmed et al., 2021)等领域。我们采用了 Pearl 图模型(Pearl, 2009)中的图形化表示法,但针对 UVAD 任务提出了一种定制的因果图。据我们所知,这是首次尝试研究伪标签生成过程在 UVAD 中的混杂效应。此外,我们通过基于反事实的特征替换,建模了长期时序上下文与局部图像帧外观之间的交互。
Method
Problem Formulation
General Settings.
给定一组视频帧
I
=
{
I
i
}
i
=
1
K
\mathbb{I}=\{I_i\}_{i=1}^K
I={Ii}i=1K,其中
K
K
K表示视频帧的总数,提取的特征集合表示为
X
=
{
x
i
}
i
=
1
K
\boldsymbol{X}=\{\boldsymbol{x}_i\}_{i=1}^K
X={xi}i=1K,其中
x
i
∈
R
D
b
\boldsymbol{x}_i \in \mathbb{R}^{D_b}
xi∈RDb。我们将整体的噪声伪标签集合定义为
L
=
A
∪
N
=
{
l
i
∣
l
i
=
c
,
c
∈
C
=
{
0
,
1
}
}
i
=
1
K
L = A \cup N = \{l_i \,|\, l_i = c, \, c \in \mathcal{C} = \{0, 1\}\}_{i=1}^K
L=A∪N={li∣li=c,c∈C={0,1}}i=1K,其中伪异常标签集合为
A
A
A,伪正常标签集合为
N
N
N。
C
\mathcal{C}
C 表示标签集合,0 表示正常事件,1 表示异常事件。我们将 UVAD 任务表述为:
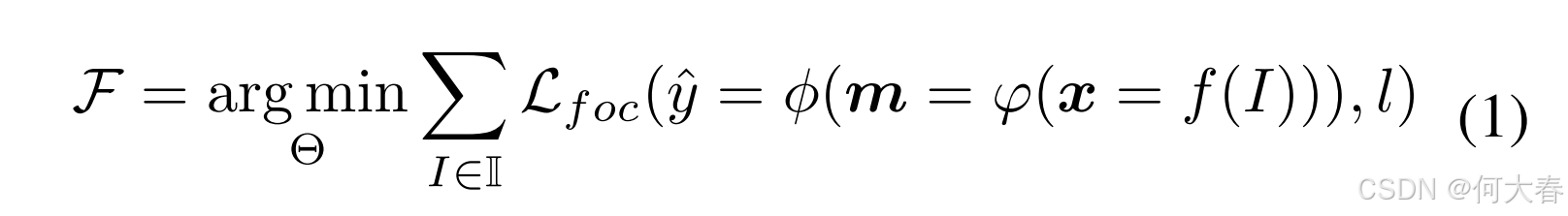
我们的目标是通过一个卷积神经网络学习一个异常检测器 F \mathcal{F} F。该网络由以下组件组成:
- 一个主干网络 f ( ⋅ ; Θ b ) : R H × W × 3 → R D b f(\cdot; \Theta_b): \mathbb{R}^{H \times W \times 3} \to \mathbb{R}^{D_b} f(⋅;Θb):RH×W×3→RDb,将输入视频帧 I I I 转换为特征 x \boldsymbol{x} x;
- 一个异常表示学习模块 φ ( ⋅ ; Θ a ) : R D b → R D s \varphi(\cdot; \Theta_a): \mathbb{R}^{D_b} \to \mathbb{R}^{D_s} φ(⋅;Θa):RDb→RDs,将特征 x \boldsymbol{x} x 转换为异常特定表示 m \boldsymbol{m} m;
- 一个异常分数回归层 ϕ ( ⋅ ; Θ s ) : R D s → R \phi(\cdot; \Theta_s): \mathbb{R}^{D_s} \to \mathbb{R} ϕ(⋅;Θs):RDs→R,学习将 m \boldsymbol{m} m 预测为异常分数 y y y。
整体的参数集合为 Θ = { Θ b , Θ a , Θ s } \Theta = \{\Theta_b, \Theta_a, \Theta_s\} Θ={Θb,Θa,Θs},通过焦点损失(Focal Loss, Lin et al. 2017) L foc \mathcal{L}_{\text{foc}} Lfoc 进行优化。
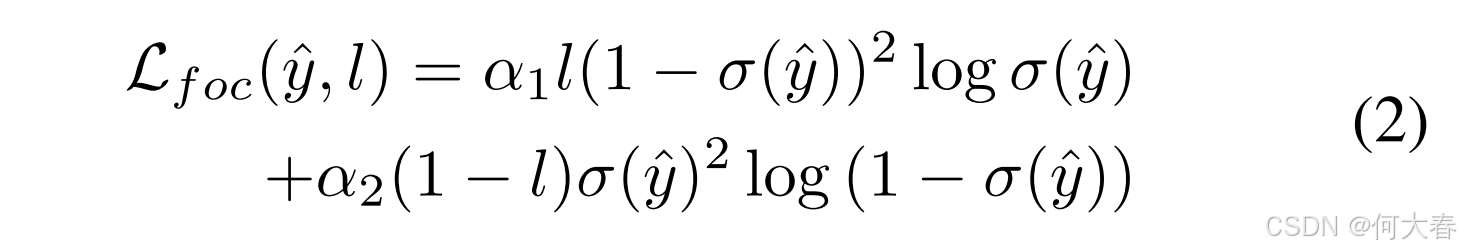
其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是标准的 sigmoid 函数 α 1 \alpha_1 α1 和 α 2 \alpha_2 α2 是超参数。
A Strong Baseline.接下来,我们按照 (Pang et al., 2020) 中的逻辑介绍强基线异常检测器 F \mathcal{F} F的训练过程。
Round 0:初始伪标签集合 L 0 L_0 L0 的生成,我们使用在 ImageNet (Krizhevsky, Sutskever, and Hinton, 2012) 上预训练的 ResNet-50 CNN (He et al., 2016) 作为 f ( ⋅ ) f(\cdot) f(⋅) 来提取特征 X X X。然后,采用一种无监督算法为 L 0 L_0 L0 生成初始伪标签。确实,有许多算法可以用于此任务,例如自编码器网络(Wang et al., 2018)。然而,为了与 (Pang et al., 2020) 进行公平比较,我们采用了孤立森林算法(Liu, Ting, and Zhou, 2012)。该算法通过随机选择一个特征并在该特征的最大值与最小值之间随机选择一个分割值来隔离异常事件。这相当于构建一片随机树的森林,其中每个树节点的特征和分割点都是随机选择的。隔离一个样本所需的分割次数等于从根节点到终止节点的路径长度。对这片随机树森林中的路径长度进行平均可以作为正常性的度量。
具体来说,给定一个随机子集 R ⊂ X R \subset X R⊂X 和 x ∈ R x \in R x∈R, x x x 的异常分数定义为:
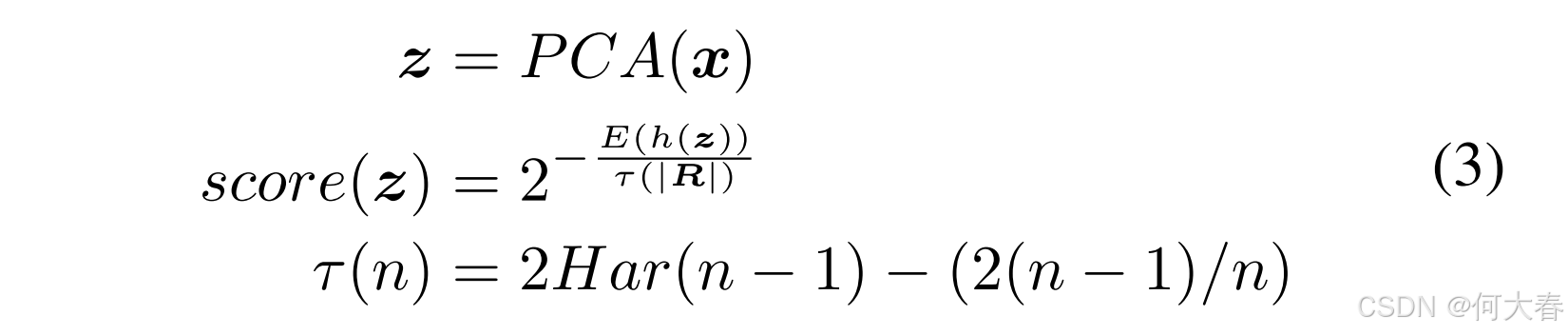
其中, P C A ( ⋅ ) PCA(\cdot) PCA(⋅) 是主成分分析函数,用于保留 99 % 99\% 99% 的解释方差。 h ( z ) h(\boldsymbol{z}) h(z)表示 z \boldsymbol{z} z的路径长度,即从根节点到叶子节点在一棵孤立树中遍历的边数。 E ( h ( z ) ) E(h(\boldsymbol{z})) E(h(z)) 表示从多棵孤立树中获得的 h ( z ) h(\boldsymbol{z}) h(z) 的平均值。 ∣ R ∣ |\boldsymbol{R}| ∣R∣表示 R \boldsymbol{R} R 中样本的总数。 H a r ( ⋅ ) Har(\cdot) Har(⋅)是调和数, τ ( ⋅ ) \tau(\cdot) τ(⋅) 是归一化项。
Round 1:使用 L 0 L_0 L0进行学习 ,通过上一轮计算得到的 L 0 L_0 L0,我们利用公式 (1) 进行学习以获得 F 1 \mathcal{F}_1 F1。然后,使用 F 1 \mathcal{F}_1 F1 对伪标签集合重新采样,生成 L 1 L_1 L1。
Round 2 to T:自监督伪标签学习过程。通过自训练并迭代生成伪标签,逐步优化伪标签集合 (L) 的质量。具体来说,使用已训练的 F t \mathcal{F}_t Ft 生成新的伪标签集合 L t L_t Lt,并利用 L t L_t Lt 训练新的 F t + 1 \mathcal{F}_{t+1} Ft+1。这一过程迭代 T T T 轮,直到性能达到稳定状态。
A Causal Inference Look At UVAD
Analysis.我们提出了如图 1 所示的因果图,用于分析上述 F \mathcal{F} F的训练问题。以下是对因果图定义的简要介绍:
图 1 中的因果图由六个关键变量组成:特征提取器 ( E (E (E)、带噪声的伪标签特征 ( S (S (S)、带噪声的伪标签 ( L (L (L)、输入视频帧特征( X X X)、异常特定特征表示( M M M)以及模型预测结果( Y Y Y)。该因果图基本包含两部分:
- 伪标签生成部分,通过路径 E → S → L E \to S \to L E→S→L 表示,包括第 0 轮及后续轮次中的伪标签生成过程;
- 模型训练部分,包括以下路径:
- E → X E \to X E→X,表示公式 (1) 中的 x = f ( I ) x = f(I) x=f(I);
- X → M → Y X \to M \to Y X→M→Y,表示 y ^ = ϕ ( m = φ ( x = f ( I ) ) ) \hat{y} = \phi(m = \varphi(x = f(I))) y^=ϕ(m=φ(x=f(I)));
- L → M ← X L \to M \gets X L→M←X,表示 L foc ( y ^ , l ) \mathcal{L}_{\text{foc}}(\hat{y}, l) Lfoc(y^,l)。
此外,路径 X → Y X \to Y X→Y 表示 X X X 和 Y Y Y 之间的直接因果作用,也是我们希望实现的目标。
如前一节所述,已训练模型 F F F 的性能无法直接反映 X X X和 Y Y Y 之间的因果关系,因为存在明显的后门路径 X ← E → S → L → M → Y X \gets E \to S \to L \to M \to Y X←E→S→L→M→Y,使得 X X X和 Y Y Y 产生虚假的依赖关系。正确的伪标签通过路径 X → M → Y X \to M \to Y X→M→Y 帮助 F F F 学习更好的异常特定表示空间,而错误的伪标签则通过后门路径扭曲了这一空间。因此,这为进一步提升性能提供了可能性。
De-confounded Training with Causal Intervention.
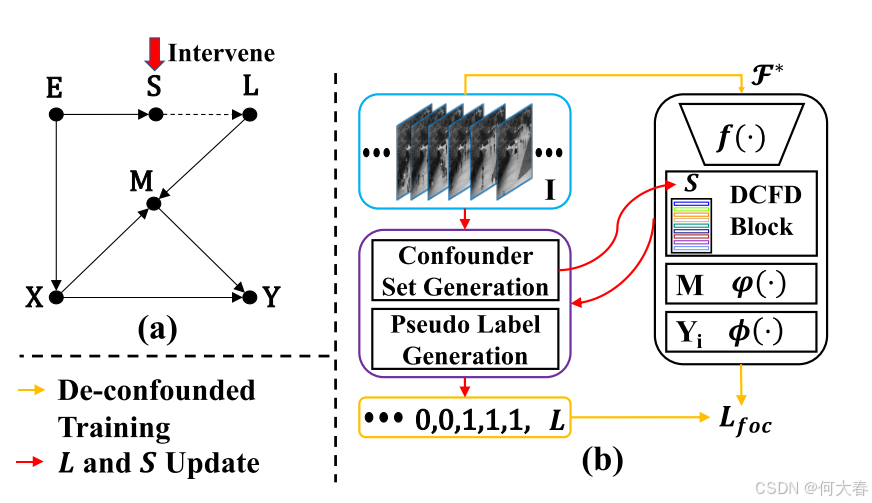
图 3:所提出的去混淆训练的概述。(a)表示经过干预的因果图。(b)展示了具体的实现过程。特别是,伪标签集 (L) 和混淆变量集 (S) 通过红色箭头线迭代生成;随后,按照橙色箭头线进行去混淆训练过程。DCFD 模块是方程(8)中描述的去混淆过程。
为了解决上述问题,我们提出了一个经过干预的因果图来解决伪标签生成过程中的混杂偏差,如图 3 所示。调整后的因果图通过阻断 X ← E → S → L → M → Y X \gets E \to S \to L \to M \to Y X←E→S→L→M→Y的因果链来阻止混杂路径,从而使伪标签生成过程不再与模型学习产生虚假的相关性。因此,基于该因果图的学习可以实现 X X X 和 Y Y Y之间的直接因果效应,用公式表示为 P ( Y ∣ do ( X ) , M ) = ∑ s P ( Y ∣ X , M , S = s ) P ( s ) P(Y|\text{do}(X),M) = \sum_s P(Y|X,M, S = s)P(s) P(Y∣do(X),M)=∑sP(Y∣X,M,S=s)P(s)。这种技术被称为后门调整(Backdoor Adjustment,Pearl 2001),其基本思想是将总体划分为相对于 S S S同质的子群体,分别评估 X X X对 Y Y Y的作用,然后对结果求平均值。
需要注意的是,我们选择 S S S是因为它是唯一可分割且可以执行后门调整的变量,而特征提取器 E E E 和带噪声的伪标签 L L L 无法进行分割。为此,我们将基于 P ( Y ∣ do ( X ) , M ) P(Y|\text{do}(X),M) P(Y∣do(X),M) 学习的模型定义为 F ∗ F^* F∗,而 P ( Y ∣ do ( X ) , M ) P(Y|\text{do}(X),M) P(Y∣do(X),M) 的实现为:
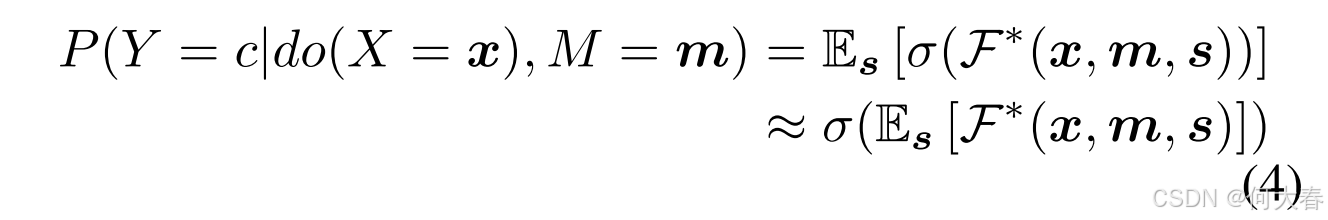
其中, F ∗ \mathcal{F}^* F∗输出样本 x x x 属于类别 c c c的无偏预测对数值。由于 E s [ ⋅ ] \mathbb{E}_s\left[\cdot\right] Es[⋅] 需要计算成本较高的采样过程,因此我们采用方程 (7) 中所示的近似方法。
Counterfactual Based Long-range Temporal Context
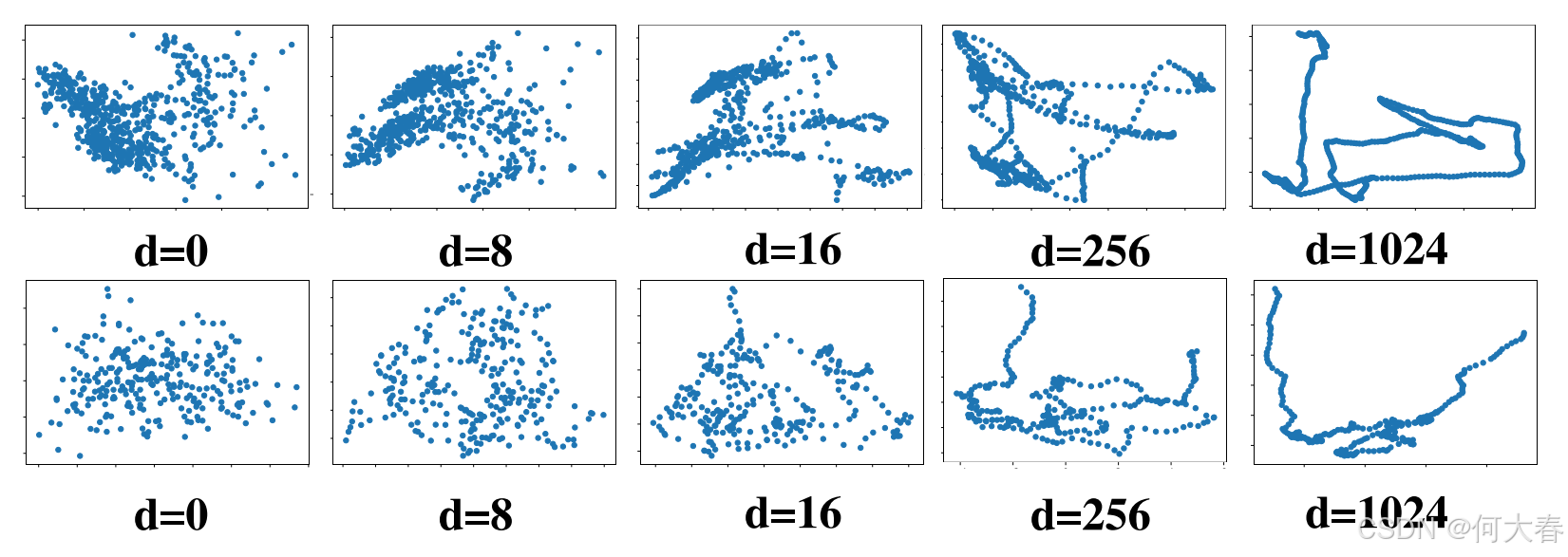
图 2:UCSD Ped2(第一行)和 Avenue(第二行)的时间上下文,从短范围 ( d = 0 (d=0 (d=0)到长范围( d = 1024 d=1024 d=1024)。
Ensemble.在上述去混淆训练中训练的模型基础上,我们通过向模型预测中注入远程时间上下文先验进一步提升模型能力。在视频异常检测(VAD)中,提取鲁棒的时间上下文对判定异常事件至关重要。现有方法通常将时间上下文建模为相邻视频帧的短时间范围,而忽略了远程时间上下文。然而,不同的短时间上下文表示可能存在显著差异并具有较大的变化,这不利于捕获鲁棒的时间上下文表示。相反,远程时间上下文表示更为稳定,且随着视频播放的变化较小。
这一现象在图2中得到了说明:我们绘制了随着相邻帧数量增加,时间上下文特征的变化情况:(1)最左列表示短范围(0个相邻帧)的时间上下文特征投影到二维图像平面上的结果;(2)最右列显示了远程范围(1024个相邻帧)的时间上下文特征投影到二维图像平面上的结果。显然,与远程时间上下文相比,短时间范围的时间上下文特征表示噪声更大,而远程时间上下文则表现出更平滑和清晰的模式。
为此,我们提出通过图4的第二部分所示的反事实特征替换来建模远程时间上下文。由于正常预测对数值和远程时间上下文预测对数值的幅值不同,我们在将其相加进行模型集成之前,对来自 F ∗ \mathcal{F}^* F∗的正常预测和远程预测的对数值进行归一化处理。最终类别 c c c 的异常预测得分 O ( ⋅ ) O(\cdot) O(⋅) 定义如下:
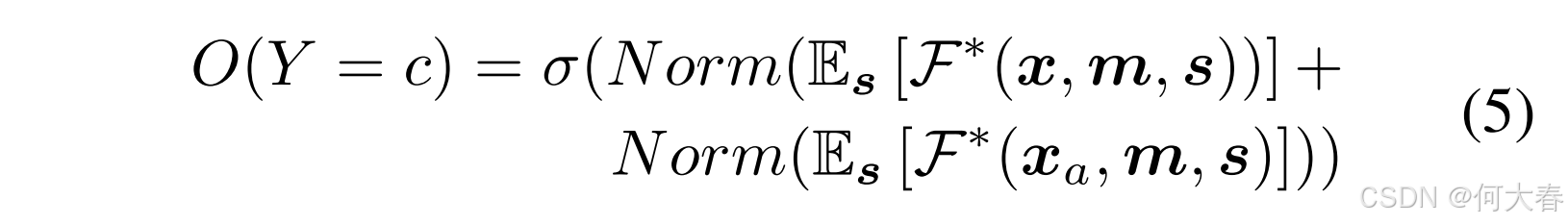
其中,
x
a
=
(
∑
i
=
−
d
d
x
i
)
/
2
d
\boldsymbol{x}_a = \left( \sum_{i=-d}^d \boldsymbol{x}_i \right) / 2d
xa=(∑i=−ddxi)/2d 是以
x
\boldsymbol{x}
x 为中心,窗口大小为
d
d
d的滑动窗口的平均特征。
归一化对数值公式为
Norm(logit)
=
(
logit
−
μ
)
/
δ
\text{Norm(logit)} = (\text{logit} - \mu) / \delta
Norm(logit)=(logit−μ)/δ,其中
μ
\mu
μ 是所有帧的所有对数值的均值,
δ
\delta
δ 是所有帧的所有对数值的标准差。
总体公式:异常预测问题的整体公式定义为对 O ( ⋅ ) O(·) O(⋅)分数的测量。
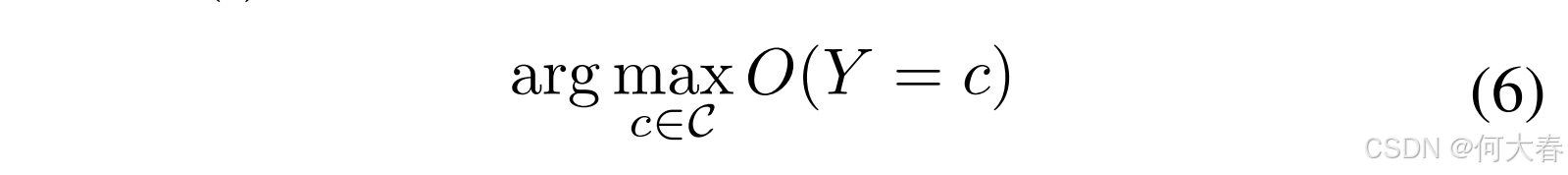
De-confounded Training
如前一小节所述,我们提出使用后门调整来推导去混淆模型。其核心思想是通过对变量 E E E、 S S S 或 L L L 之一进行分层(干预),以阻断后门路径。然而,伪标签生成过程的分层可以通过对伪标签特征 S S S 进行分层来实现,因为 L L L 仅由 E E E 生成的特征集 S S S 决定,而对 L L L 或 E E E 进行分层是不可行的。因此,我们定义 S S S 的分层为 S = { s i } i = 1 N s \boldsymbol{S} = \{\boldsymbol{s}_i\}_{i=1}^{N_s} S={si}i=1Ns,其中 s i ∈ R D b \boldsymbol{s}_i \in \mathbb{R}^{D_b} si∈RDb, N s N_s Ns 是表示混杂变量集 S \boldsymbol{S} S 大小的超参数。
由于实际中噪声伪标签特征的数量通常较多,在具体实现中,我们利用主成分分析(PCA)结合K-Means来学习混杂变量集 S S S。因此,公式 (4) 的整体表达形式为:
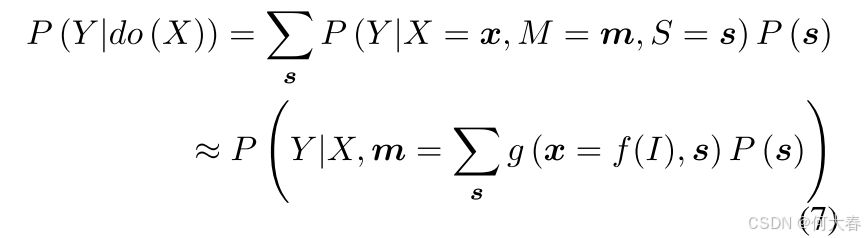
其中,近似通过归一化加权几何平均 (Normalized Weighted Geometric Mean, Xu 等人, 2015b) 实现(详见补充文档)。阻断后门路径使得 X X X 有公平的机会将每个 s s s 纳入 Y Y Y的预测中,受先验 P ( s ) P(\boldsymbol{s}) P(s)的约束。函数 g ( ⋅ ) g(\cdot) g(⋅) 定义如下:
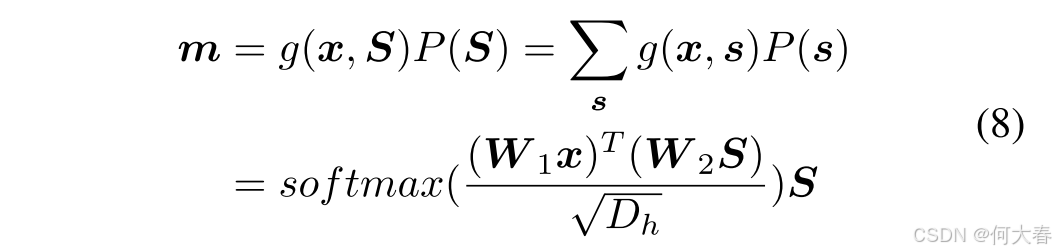
其中, P ( s i ) = ∣ s i ∣ ∑ j ∣ s j ∣ P(\boldsymbol{s}_i) = \frac{|\boldsymbol{s}_i|}{\sum_j |\boldsymbol{s}_j|} P(si)=∑j∣sj∣∣si∣,其中 ∣ s i ∣ |\boldsymbol{s}_i| ∣si∣ 表示簇 s i \boldsymbol{s}_i si 中样本的数量。参数 W 1 , W 2 ∈ R D h × D b \boldsymbol{W}_1, \boldsymbol{W}_2 \in \mathbb{R}^{D_h \times D_b} W1,W2∈RDh×Db是可学习参数,用于将 x \boldsymbol{x} x 和 s i \boldsymbol{s}_i si 投影到一个联合空间中。 D h \sqrt{D_h} Dh 是用于特征归一化的常量缩放因子。
在实现中,为了更好地表示异常特定特征,我们进一步设置 M = m ⊕ M = \boldsymbol{m}^\oplus M=m⊕,其中 m ⊕ = c o n c a t ( x , m ) \boldsymbol{m}^\oplus = concat(\boldsymbol{x}, \boldsymbol{m}) m⊕=concat(x,m)。
最后,本节中定义的模型 F ∗ \mathcal{F}^* F∗使用 L f o c \mathcal{L}_{foc} Lfoc进行训练。
Counterfactual Temporal Context Ensemble
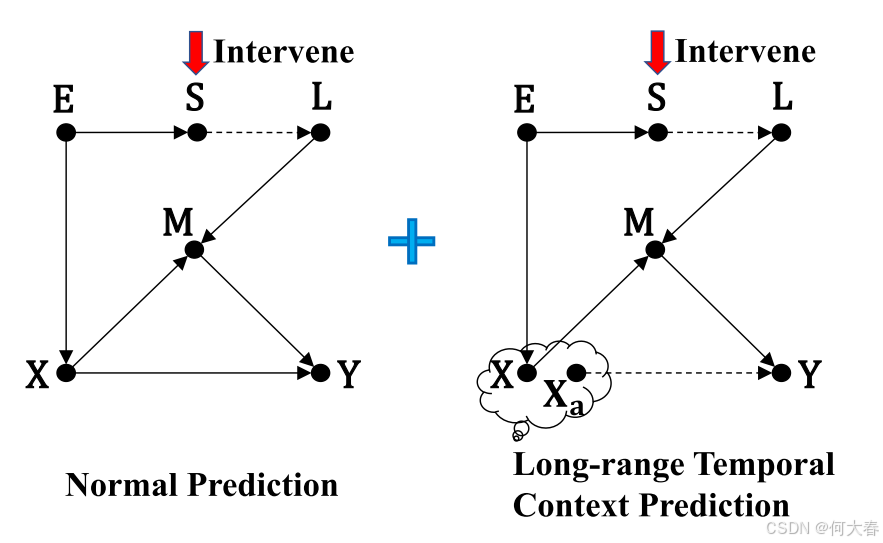
图4:反事实长时序上下文模型集成用于计算最终输出的异常预测logits。左部分表示 P ( Y = c ∣ d o ( X ˙ = x ) , M = m ⊕ ) P(Y=c|do(\dot{X}=\boldsymbol{x}),M=\boldsymbol{m}^\oplus) P(Y=c∣do(X˙=x),M=m⊕),右部分表示 P ( Y = c ∣ d o ( X ˙ = x a ) , M = m a ⊕ ) P(Y=c|do(\dot{X}=\boldsymbol{x}_a),M=\boldsymbol{m}_a^\oplus) P(Y=c∣do(X˙=xa),M=ma⊕)。
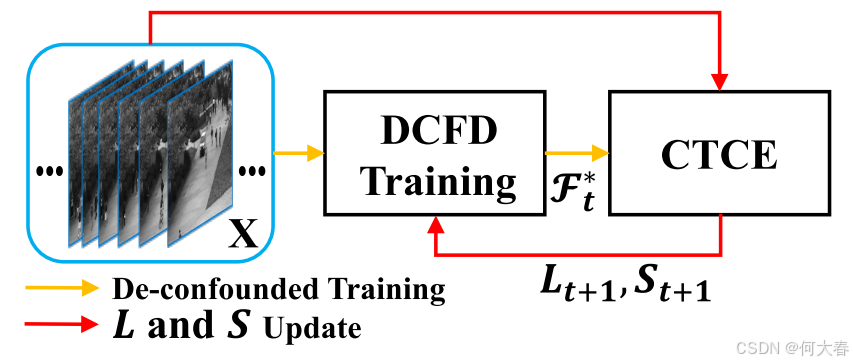
图5:两阶段迭代的总体流程。DCFD训练如图3所示,CTCE是图4所示的反事实时序上下文集成。
在前一小节中训练好的模型 F ∗ \mathcal{F}^* F∗ 的基础上,我们旨在将长时序上下文先验信息注入到模型预测中。给定输入的视频帧 I I I,方程(5)中的第一项通过正常推理获得,输入为 x = f ( I ) \boldsymbol{x} = f(I) x=f(I),因此 m ⊕ = concat ( x , m ) \boldsymbol{m}^\oplus = \text{concat}(\boldsymbol{x}, \boldsymbol{m}) m⊕=concat(x,m)。方程(5)中的第二项实现为反事实特征替换。换句话说,我们设置 m a ⊕ = concat ( x a , m ) \boldsymbol{m}_a^\oplus = \text{concat}(\boldsymbol{x}_a, \boldsymbol{m}) ma⊕=concat(xa,m),然后通过后续的融合层。也就是说,将滑动窗口中心的均值特征 x a \boldsymbol{x}_a xa 作为输入,同时保持其他部分不变。该实现模仿了长时序上下文 x a \boldsymbol{x}_a xa 和局部图像上下文 m \boldsymbol{m} m 之间的交互。通过这样的解耦设计,第一项保持了去混淆的异常预测,而第二项则结合了长时序上下文与局部图像上下文之间的交互。将两者相加类似于模型集成。方程(5)的实现定义如下:
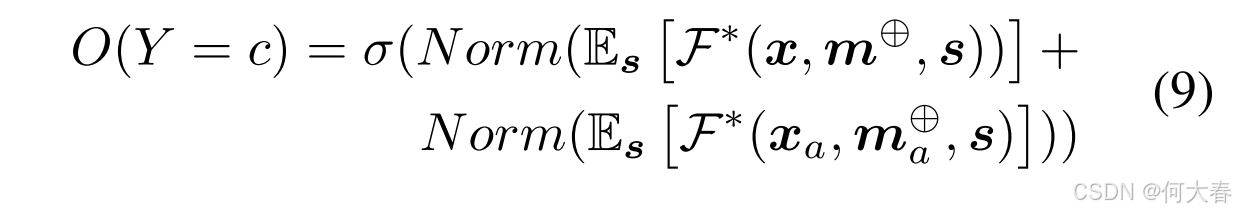
Self-supervised Pseudo Label Learning
为此,我们提出了去混淆训练模块和基于反事实的长时序上下文集成模块。按照(Pang 等人,2020)的做法,我们采用与强基线相同的自监督伪标签学习设置。具体来说,在第0轮,我们使用前面提到的孤立森林算法初始化伪标签 L L L 为 L 0 L_0 L0。混淆集 S S S 首先使用骨干网络 f ( ⋅ ) f(\cdot) f(⋅) 初始化为 S 0 S_0 S0。然后,在第1轮,我们执行去混淆训练以获得优化后的模型参数 F 1 ∗ \mathcal{F}_1^* F1∗,接着通过反事实时序上下文集成模块将 S 0 S_0 S0 更新为 S 1 S_1 S1,并将 L 0 L_0 L0 更新为 L 1 L_1 L1。在第2轮及之后,这一自监督伪标签学习过程将重复进行,持续进行 T ˉ \bar{T} Tˉ 轮。总体而言,尽管我们的框架属于自监督伪标签学习范式,但我们的贡献在于明确去除伪标签生成过程所带来的混淆偏差,并以反事实方式结合了长时序上下文先验信息。后续的实验进一步表明,我们的模型性能显著超越了之前的最新技术水平(SOTA)。
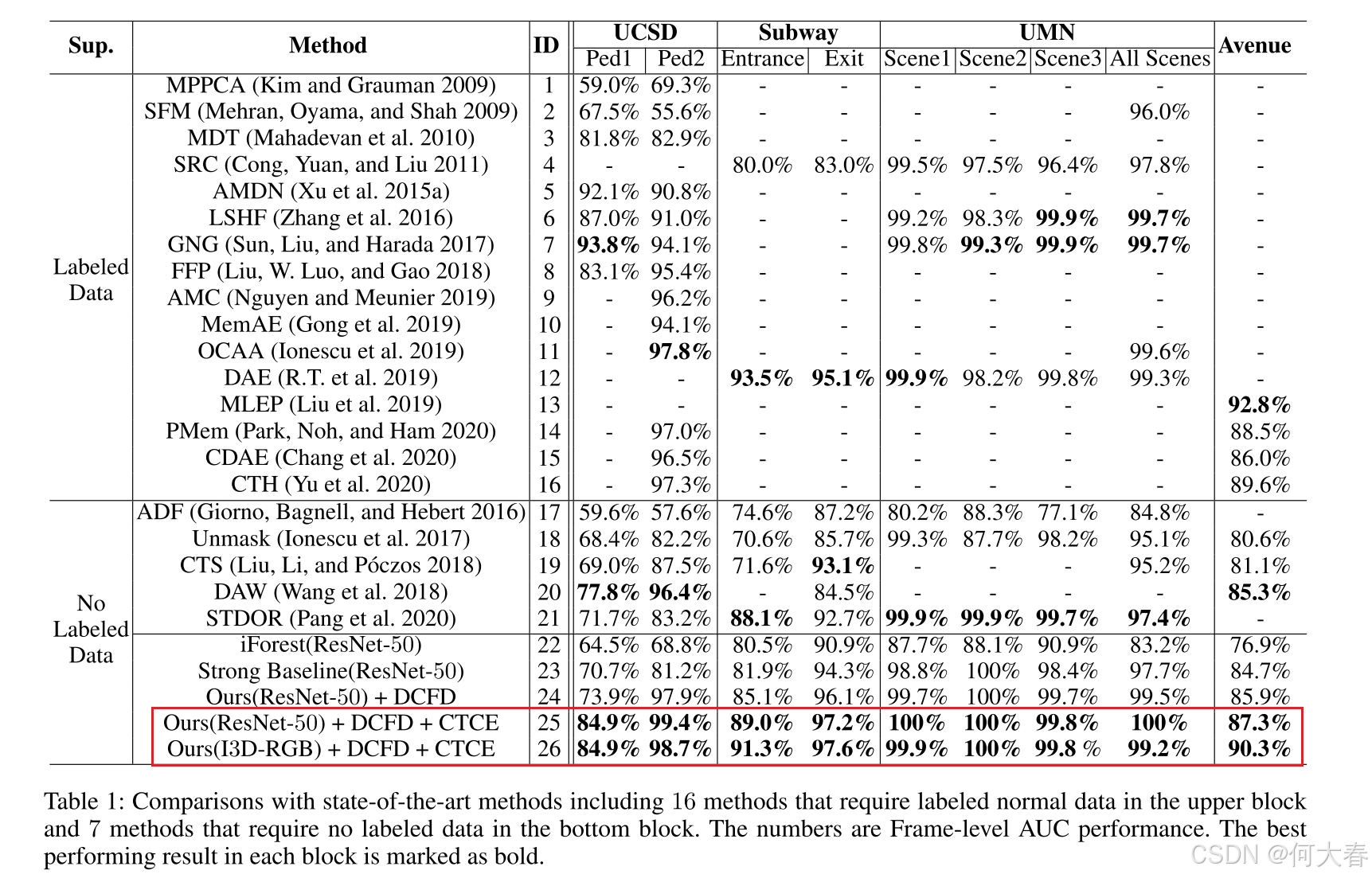
Experiments
Conclusion
我们从因果推断的角度分析了噪声伪标签和长时间上下文对无监督视频异常检测的影响。随后,我们提出了去混淆训练和反事实时间上下文集成方法,以增强无监督视频异常检测中常用的自监督伪标签学习过程。整体框架简单、计算效率高,并且对噪声伪标签具有较强的鲁棒性。我们在六个基准数据集上对所提出的流程进行了广泛验证,实验结果表明,我们的方法显著优于所有先前的方法,充分证明了其优越性。然而,设计更好的因果图或特征解耦方法可能会进一步提升模型在无监督视频异常检测中的性能。
阅读总结
从因果关系分析视频异常检测的论文还是少一点的,可惜暂时这方面的论文我还没找到有相关代码的,希望这方面的作者可以开源。