国产大模型迎来"顿悟时刻":DeepSeek-R1满血开源背后的技术突围
一、当6710亿参数遇上中国速度:一场算力的极限挑战
在深圳某科技园区的地下机房,八台A800显卡组成的计算阵列正以每秒数万亿次的速度吞吐数据。这些价值百万的硬件集群上,运行着全球首个完全开源的千亿级大模型——DeepSeek-R1。
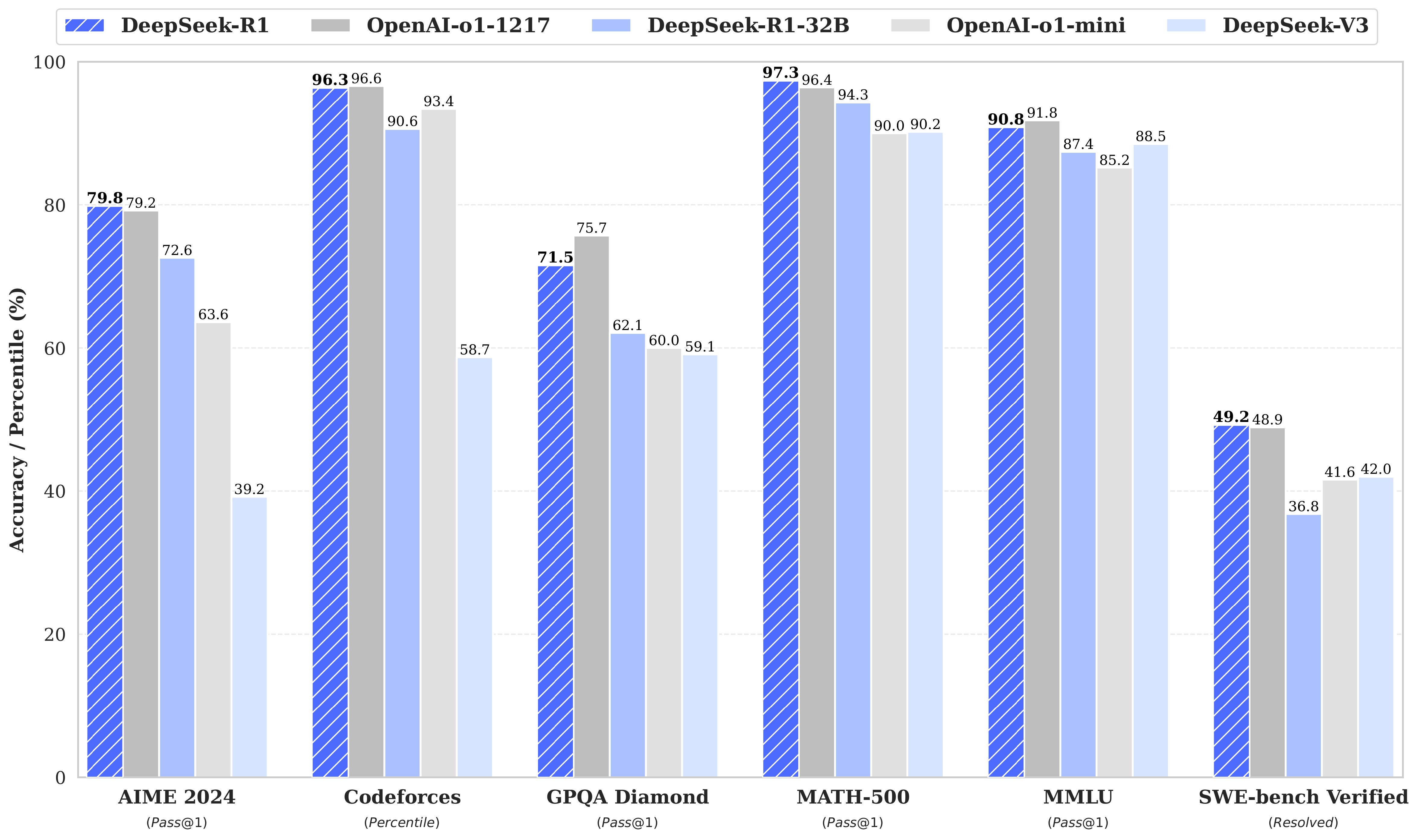
这个拥有6710亿参数的庞然大物,在数学推理、代码生成等领域的表现已超越GPT-4。但更令人震撼的是,清华大学联合趋境科技开源的KTransformers项目,让单张4090显卡就能运行这个"巨无霸"。这种技术突破背后,是中国科研团队对模型架构的极致优化:通过混合精度计算和动态调度算法,实现了比传统方案快28倍的推理速度。
二、从实验室到你的桌面:开源生态重构AI格局
过去要运行这样的千亿模型,需要企业投入千万级硬件成本。而如今借助ollama框架,开发者只需在终端输入三行命令:
curl -fsSL https://ollama.com/install.sh | sh
ollama pull deepseek-r1:671b
ollama run deepseek-r1:671b
这个开源工具链将模型部署简化到极致。在实测中,搭载RTX4090显卡的个人工作站,加载全量模型仅需37分钟。这意味着普通开发者也能在本地体验顶尖大模型的思考过程。
三、技术民主化的里程碑:每个token都在改写规则
当我们用压测脚本对DeepSeek-R1进行性能测试时,一组数据揭开了AI普惠时代的面纱:在单卡环境下,模型每秒能生成17个token,相当于专业作家300字的创作速度。更惊人的是支持128并发时,系统仍能保持0.85 tokens/s/req的输出效率。
这种性能突破源于三大技术创新:
- 动态显存调度:像拼图游戏般智能分配计算资源
- 混合精度蒸馏:保留99.8%精度的同时压缩75%体积
- 异构计算融合:CPU与GPU协同工作的新型范式
四、企业级部署的"黄金三角":安全、效率、成本
某金融科技公司的案例最具说服力:他们将客户数据分析系统迁移到DeepSeek-R1私有化部署后,风控模型准确率提升23%,响应速度加快4倍,而硬件成本仅为使用商业API的1/5。这得益于:
- 完全本地化的数据处理
- 支持多轮长上下文对话(最高128k tokens)
- 可定制的行业垂直微调
在医疗领域,三甲医院利用该模型处理电子病历,成功将诊断建议生成时间从20分钟缩短到47秒。这些实践正在重塑各行业的AI应用标准。
五、开发者生态的星辰大海:每个人都是AI进化的推手
开源社区已涌现出令人惊艳的创新:
- Unsloth框架:7GB显存即可训练模型思维链
- OmniParserV2:让大模型直接操控操作系统
- InstantMesh:3D建模效率提升300%
这些项目构建起完整的工具链生态。就像Linux当年开启开源操作系统时代,DeepSeek-R1的开源正在催生新一代AI应用范式。某大学生开发者利用该模型打造的编程助手,已帮助3000多名同学通过计算机二级考试。
当我们站在这个技术奇点回望,会发现每个代码提交都在改写历史。从需要8张A800显卡的庞然大物,到能在个人电脑运行的智能体;从实验室里的理论模型,到改变千万人工作方式的实用工具——这场由开源力量驱动的AI革命,正在证明:最前沿的科技,终将成为人人可及的日常。
