一、数据库的相关概念
DB:数据库(Database)
- 即
存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据。
DBMS:数据库管理系统(Database Management System)
- 是一种
操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据。常见的
DBMS:
Oracle、MySQL、MS SQL Server、DB2、PostgreSQL、Access、Sybase、Informix…
SQL:结构化查询语言(Structured Query Language)
- 专门用来
与数据库通信的语言。
数据库管理系统、数据库和表的关系如图所示:
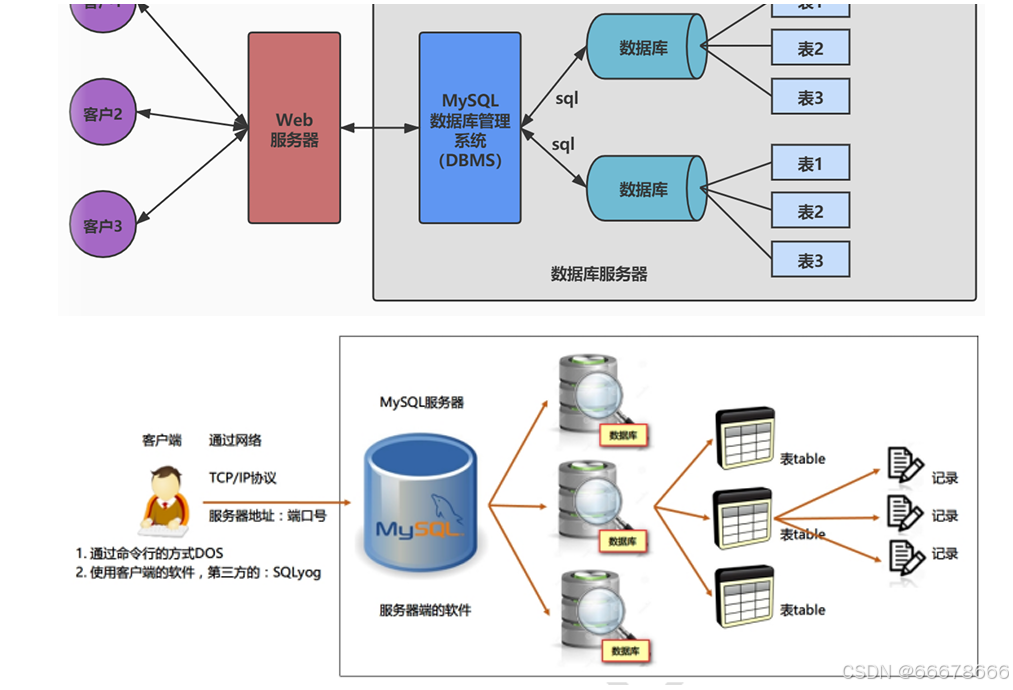
二、数据库的分类
关系型数据库(RDBMS)指采用了
关系模型来组织数据的数据库,以包含行和列的表格格式存储数据。列包含数据属性,行包含数据值。
这一系列的行和列被称为表,一组表组成了数据库。关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
关系型数据库
Oracle、MySQL、PostgreSQL、MariaDB、Microsoft SQL Server 、
非关系型数据库指数据以
对象的形式存储在数据库中,常用于存储非结构化的数据
非关系型数据库
mongodb、redis、hadoop、Oracle NoSQL…
三、MySQL服务的基础操作
启动和停止
方式一:手动开启或关闭
计算机——>右击管理——>服务和应用程序——>服务
方式二: 通过管理员身份运行命令窗口启动
net start MySQL服务名停止
net stop MySQL服务名
登录和退出
登录
方式一:通过mysql自带的客户端
开始菜单——>所有程序——>MySQL——>MySQL X.0 Command Line Client
- 注意:
仅限于 root 用户
方式二: 通过管理员身份运行命令窗口
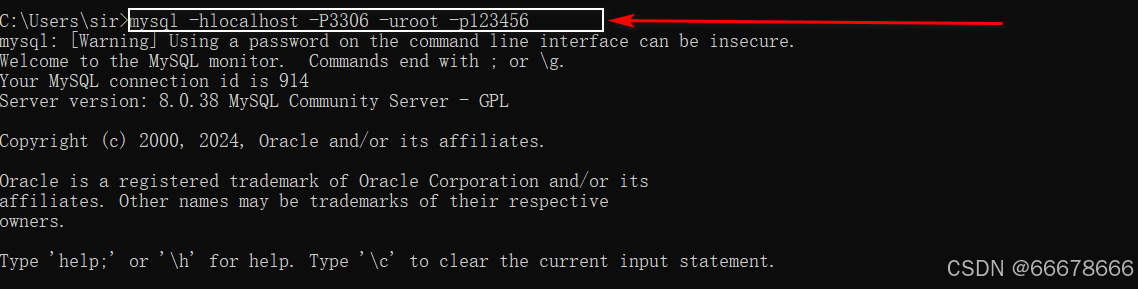
mysql -h 主机名 -P 端口号 -u 用户名 -p密码注意:
-p与密码之间不能有空格,其他参数名与参数值之间可以有空格也可以没有空格- 安全起见,建议命令
不要带密码,密码留在下行输入
mysql -h localhost -P 3306 -u root -p
Enter password:****
- 客户端和服务器在同一台机器上,所以输入
localhost或者IP地址127.0.0.1。同时,因为是连接本机:-hlocalhost就可以省略,如果端口号没有修改:-P3306也可以省略
mysql -u root -p
Enter password:****
- 使用密码登录之后输出日志:
mysql: [Warning] Using a password on the command line interface can be insecure.这只是一个
警告,而不是一个错误,它指出了在命令行中直接使用密码进行连接可能不安全。
退出
exit或quit
查看服务器的版本
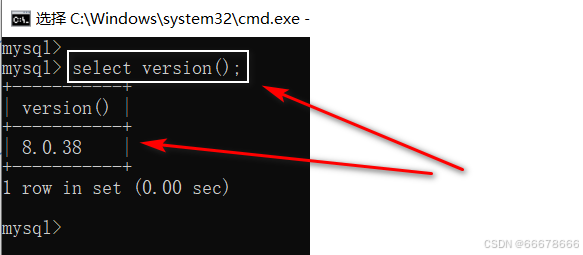
方式一:登录到mysql服务端
select version();
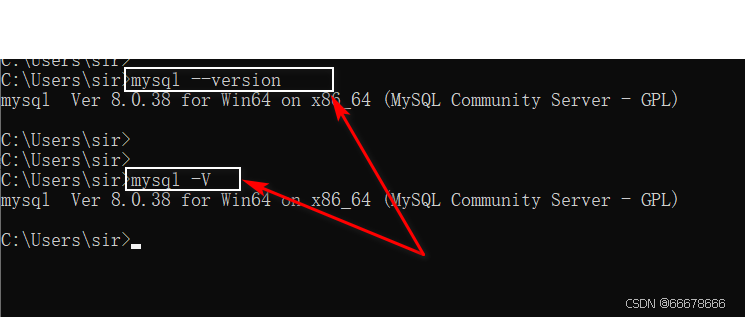
方式二:没有登录到mysql服务端
mysql --version或mysql -V
MySQL的常见命令
查看当前所有的数据库:
show databases;
打开指定的库:
use 数据库名
查看当前库的所有表:
show tables;
查看某个库的所有表格:
show tables from 数据库名;
创建数据库:
create database 数据库名;
创建数据库表:create table 表名称(
字段名 数据类型,
字段名 数据类型
);
删除数据库:
drop database 数据库名;
删除数据库表:
drop table 表名称;
四、SQL语言
1、分类
DML(Data Manipulation Language):数据操纵语言
- 用于
添加、删除、修改、查询数据库记录,并检查数据完整性
- 因
查询使用频繁,很多人把查询单独列出自成一类:
DQL(数据查询语言)

DDL(Data Definition Language):数据定义语言
- 用于
库和表的创建、修改、删除

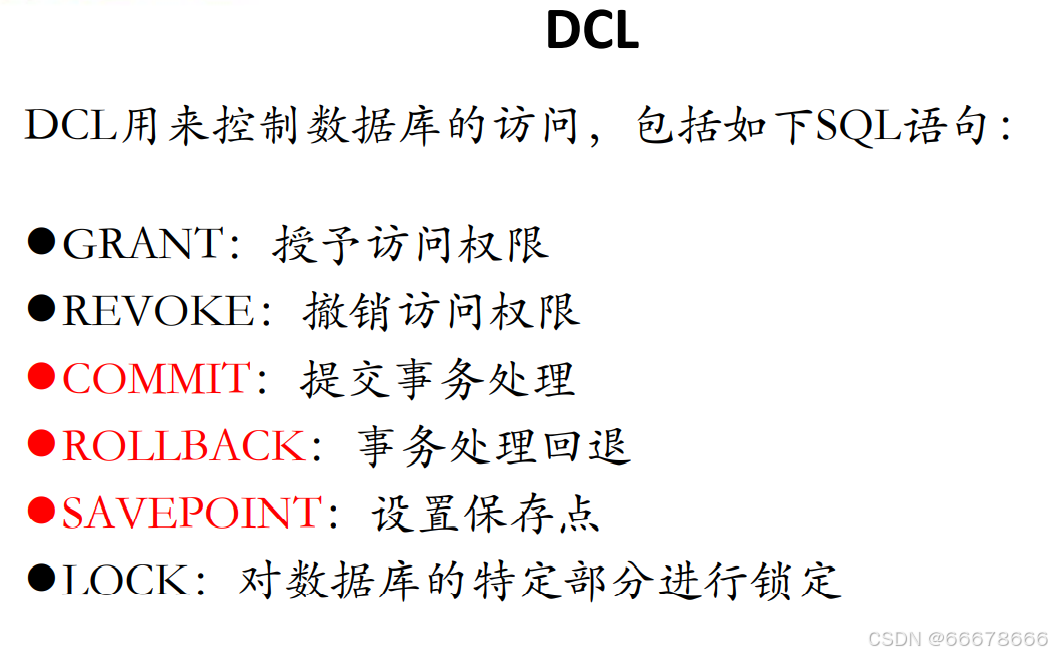
DCL(Data Control Language):数据控制语言
- 用于
定义用户的访问权限和安全级别
- 此外有人会将
COMMIT、ROLLBACK单独取出来称为
TCL(Transaction Control Language)事务控制语言
2、DML语言
INSERT
方式1、VALUES 的方式插入
注意:
VALUES也可以写成VALUE,但是VALUES是标准写法。
INSERT INTO 表名(字段名1,...) VALUES (值1,...);插入
1条数据:值的顺序和类型与字段必须一一对应
INSERT INTO 表名 VALUES (值1,值2,....);插入
1条数据:为表的所有字段按默认顺序插入数据,值的顺序和表中字段定义时的顺序相同
INSERT INTO 表名 VALUES (字段名1,...)
(值1,...),
(值1,...),
......
(值1,...);插入
多条数据
INSERT INTO 表名 VALUES
(值1,...),
(值1,...),
......
(值1,...);插入
多条数据:为表的所有字段按默认顺序插入数据
方式2、以查询结果的形式插入
INSERT INTO 目标表名
(字段名1,...)
SELECT
(字段名1,...)
FROM 源表名
[WHERE condition]
- 在
INSERT语句中加入子查询- 不必书写
VALUES- 子查询中的值列表应与
INSERT子句中的列名对应
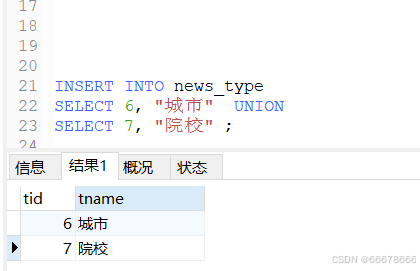
方式3、其他形式的多条插入(实际就是方式2)
INSERT INTO 表名
SELECT value1,value2.... UNION
SELECT value1,value2.... UNION
......
SELECT value1,value2.... ;
注意: 值列表应与 表中 列名一一对应
- 示例
UPDATE
修改(单)表
update 表名 set 字段1=新值,字段2=新值 ...... 【where 条件】
修改(多)表
SQL92 语法
update表1别名, 表2别名
set 字段1= 新值,字段2= 新值, …
where连接条件
and筛选条件 ;
SQL99 语法
update表1别名
inner|left|right join表2别名
on连接条件
set 字段1= 新值,字段2= 新值, …
where筛选条件 ;
DELETE
delete 删除
删除
单表
delete from 表名 【where 筛选条件】
SQL92 语法
delete 表1的别名, 表2的别名
from 表1别名,表2别名
where连接条件
and筛选条件 ;
注意:删除哪张表的数据就在delete后写哪张表名
SQL99 语法
delete 表1的别名, 表2的别名
from 表1别名
inner|left|right join表2别名
on连接条件
where筛选条件 ;
注意:删除哪张表的数据就在delete后写哪张表名
truncate 删除
truncate table 表名;
delete 和 truncate 区别
truncate不能加where条件,整张表的数据会全部删除,而delete可以加where条件truncate的效率高一些truncate删除不能回滚,delete删除可以回滚truncate删除带自增长的列的表后,如果再插入数据,数据从1开始
delete删除带自增长列的表后,如果再插入数据,数据从上一次的断点处开始

# 删除表
DROP TABLE IF EXISTS tab_indentity;
# 创建表时设置标识列
CREATE TABLE IF NOT EXISTS tab_indentity(
id INT PRIMARY KEY auto_increment,
NAME VARCHAR(20)
);
# 插入数据
INSERT INTO tab_indentity VALUES(66,"tom");
INSERT INTO tab_indentity VALUES(NULL,"jerry");
# 删除表数据
TRUNCATE TABLE tab_indentity;
DELETE FROM tab_indentity;
# 插入数据
INSERT INTO tab_indentity VALUES(NULL,"wang");
# 查询数据
SELECT * FROM tab_indentity;
# 展示表
SHOW TABLES;
# 设置步长
SET auto_increment_increment=1;
# 查看表中变量初始步长和起始值
SHOW VARIABLES like "%autocommit%";
#SELECT * FROM tab_indentity;
#INSERT INTO tab_indentity VALUES(1,"wang");
# DELETE 支持回滚操作
set autocommit = 0;
DELETE FROM tab_indentity;
ROLLBACK;
# TRUNCATE 不支持回滚操作
set autocommit = 0;
TRUNCATE TABLE tab_indentity;
ROLLBACK;
3、DQL语言
由于DQL语言内容较多,单独成篇了;详情查看博文:Mysql基础篇之DQL语言
4、DDL语言
库的管理
库的创建
CREATE DATABASE IF NOT EXISTS 库名【CHARACTER SET 字符编码】;字符集:
utf-8或gbk等;设置字符集可写可不写
库的更改(很少使用)
ALTER DATABASE 库名 CHARACTER SET 【字符编码 utf-8 或 gbk 】;安全起见,库很少会更改,即使更改也是更改字符集
库的删除
DROP DATABASE IF EXISTS 库名
表的管理
表的创建
示例:


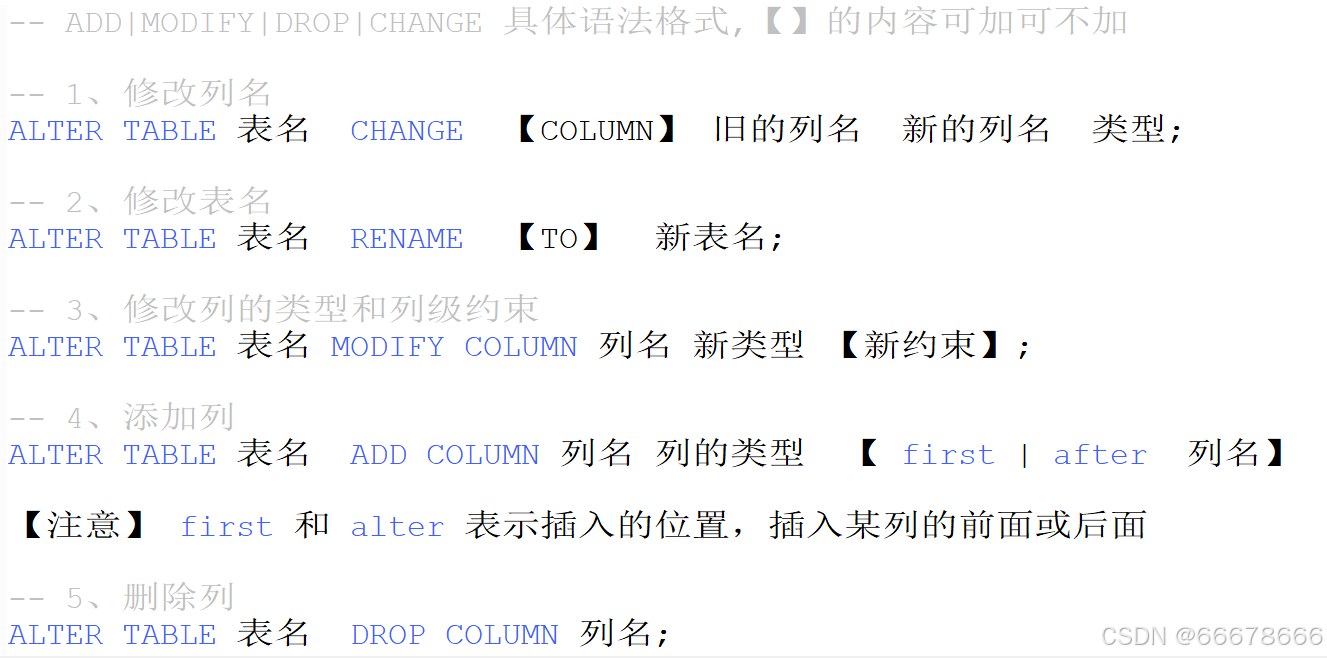
表的修改
示例:

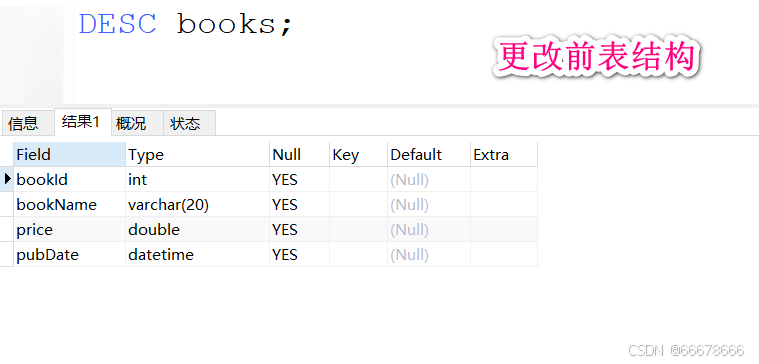
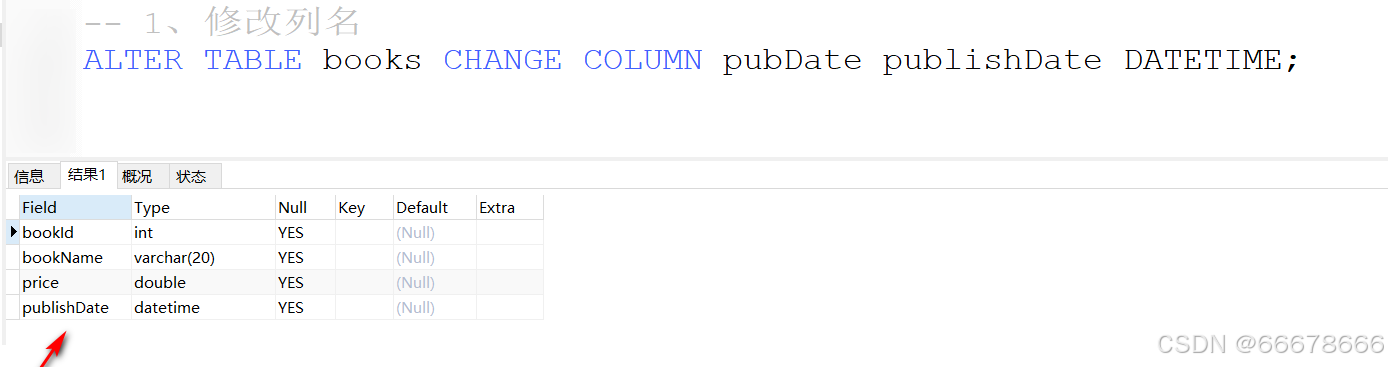
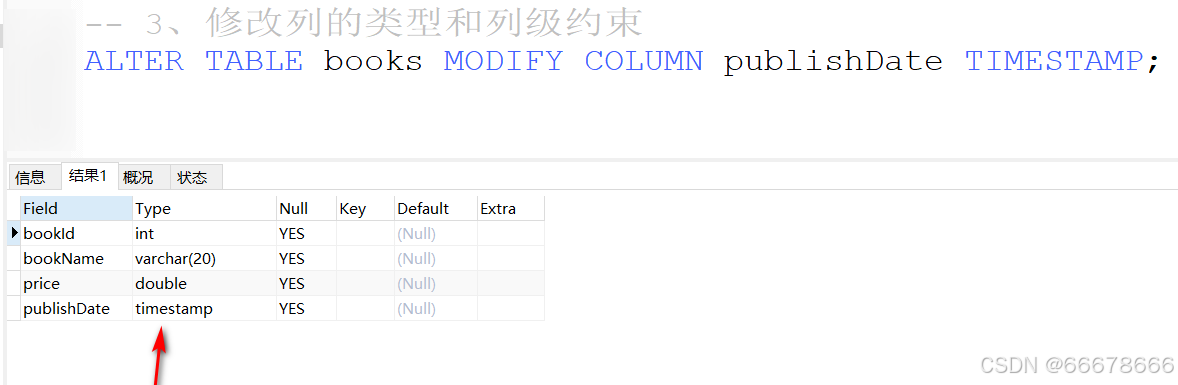
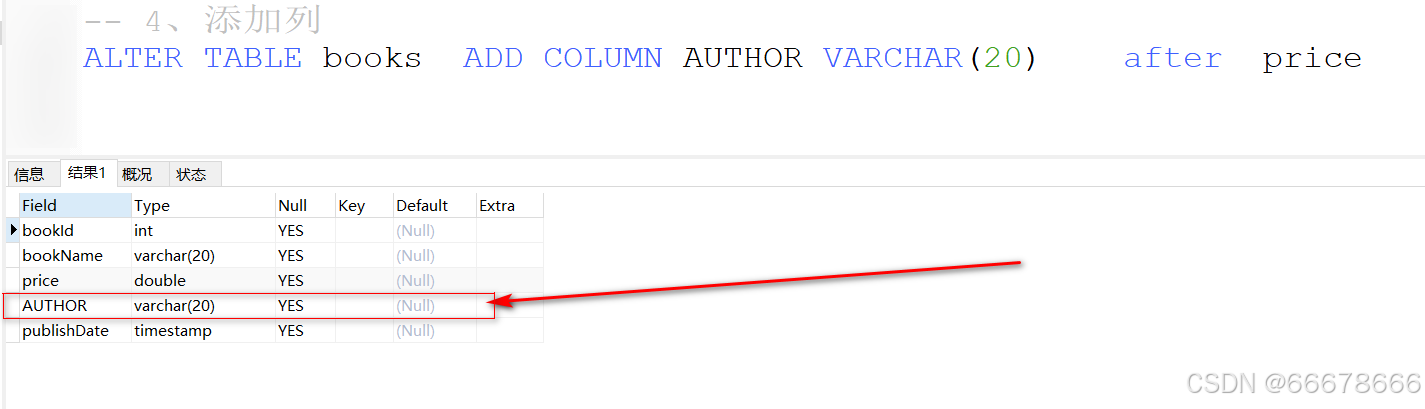
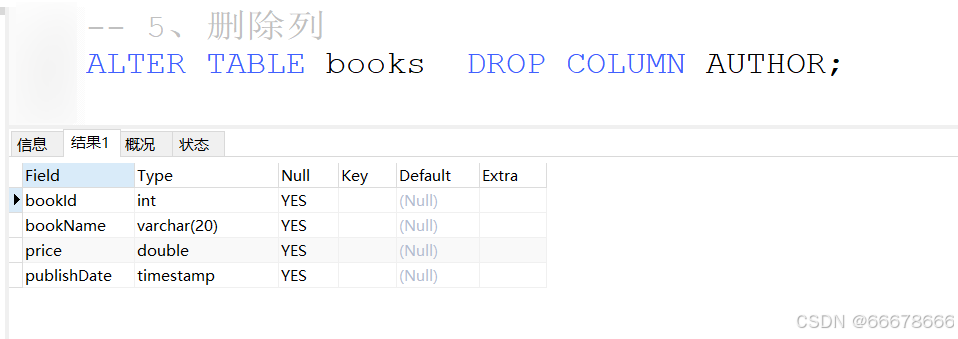

表的删除
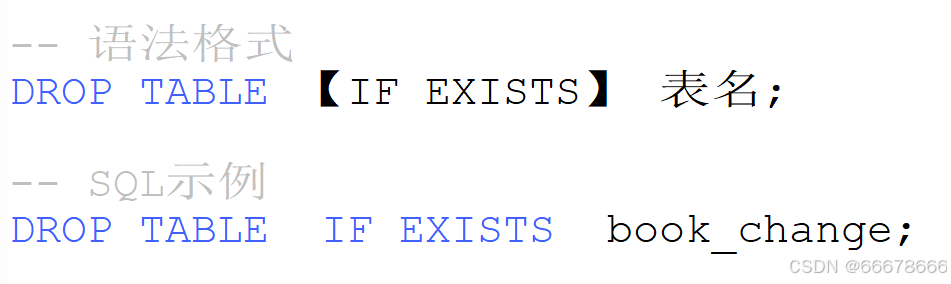
表的复制




数据类型
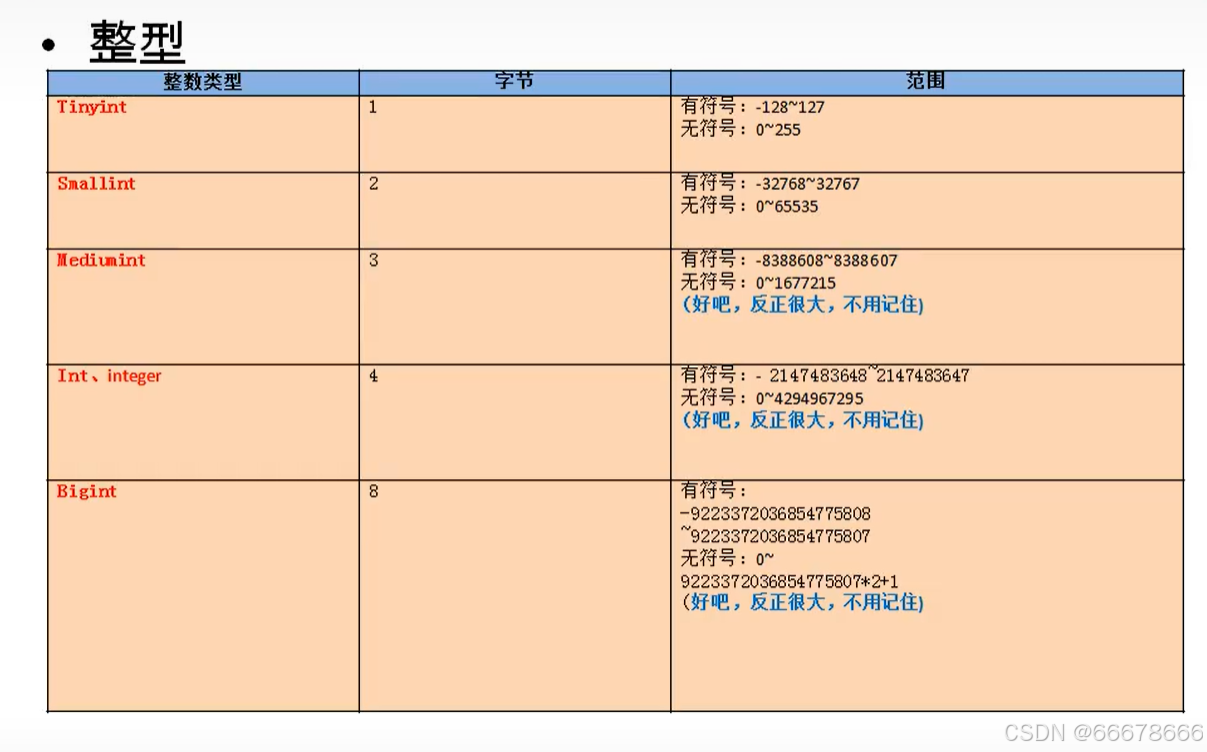
①数值型
整型
示例
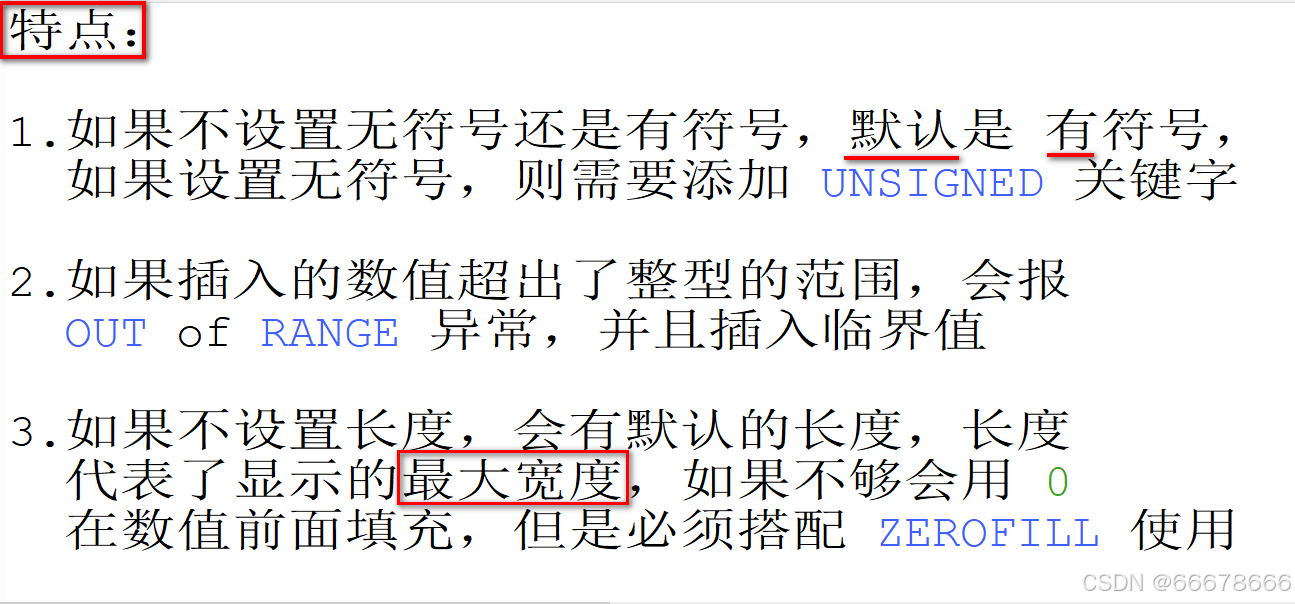
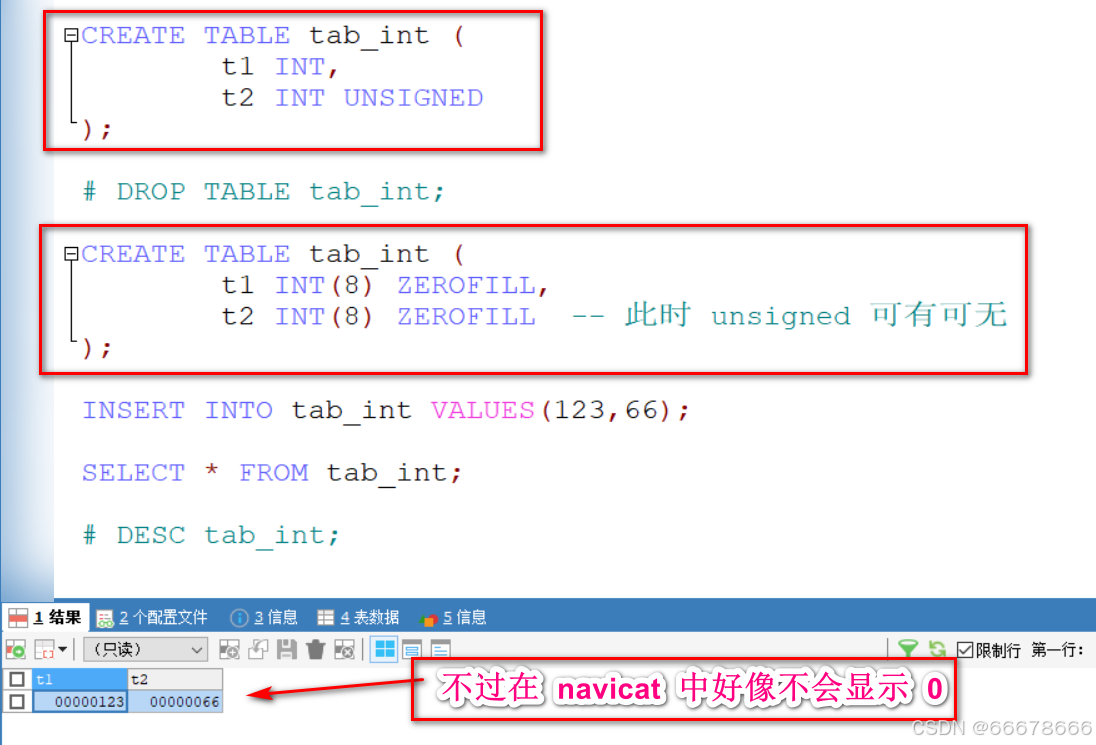
注意:

小数
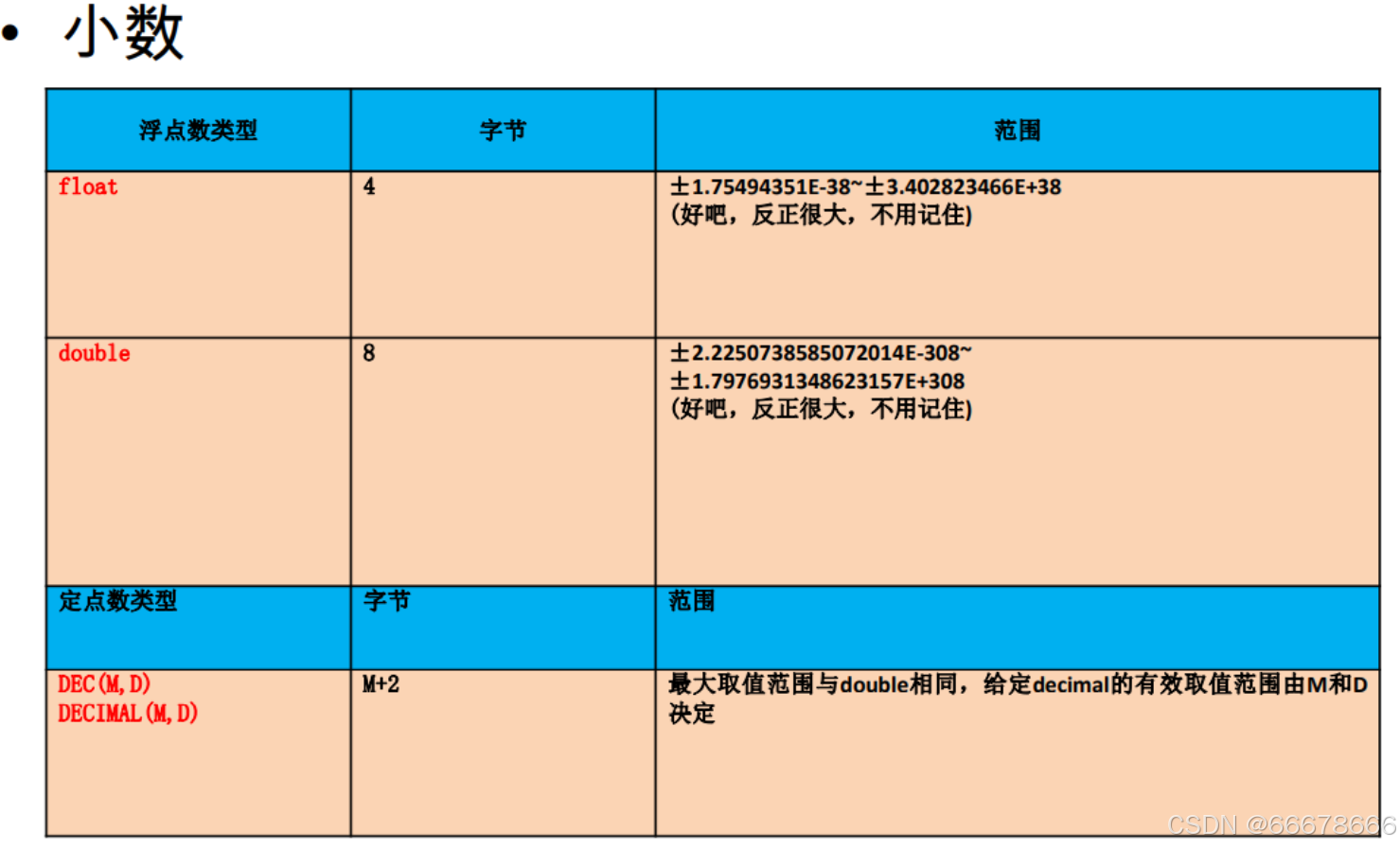
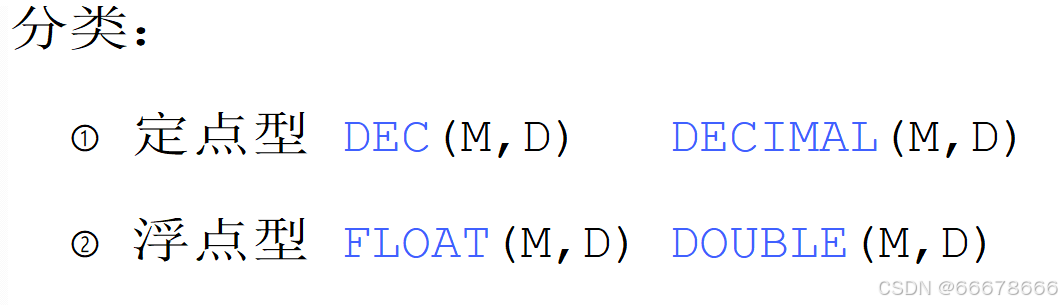

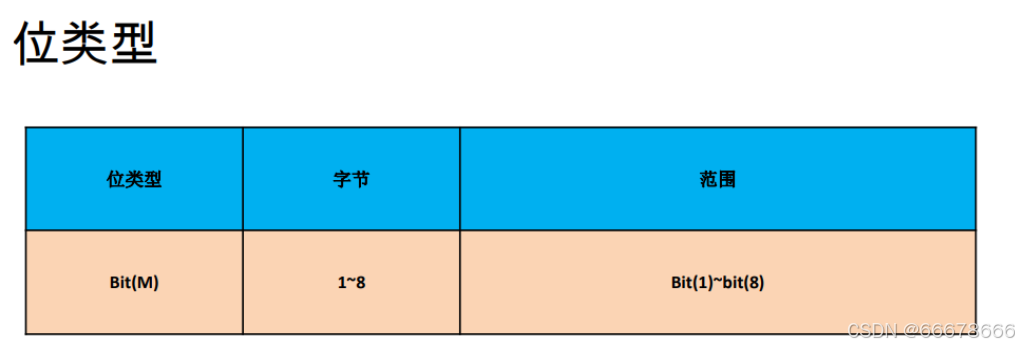
位类型
②字符型
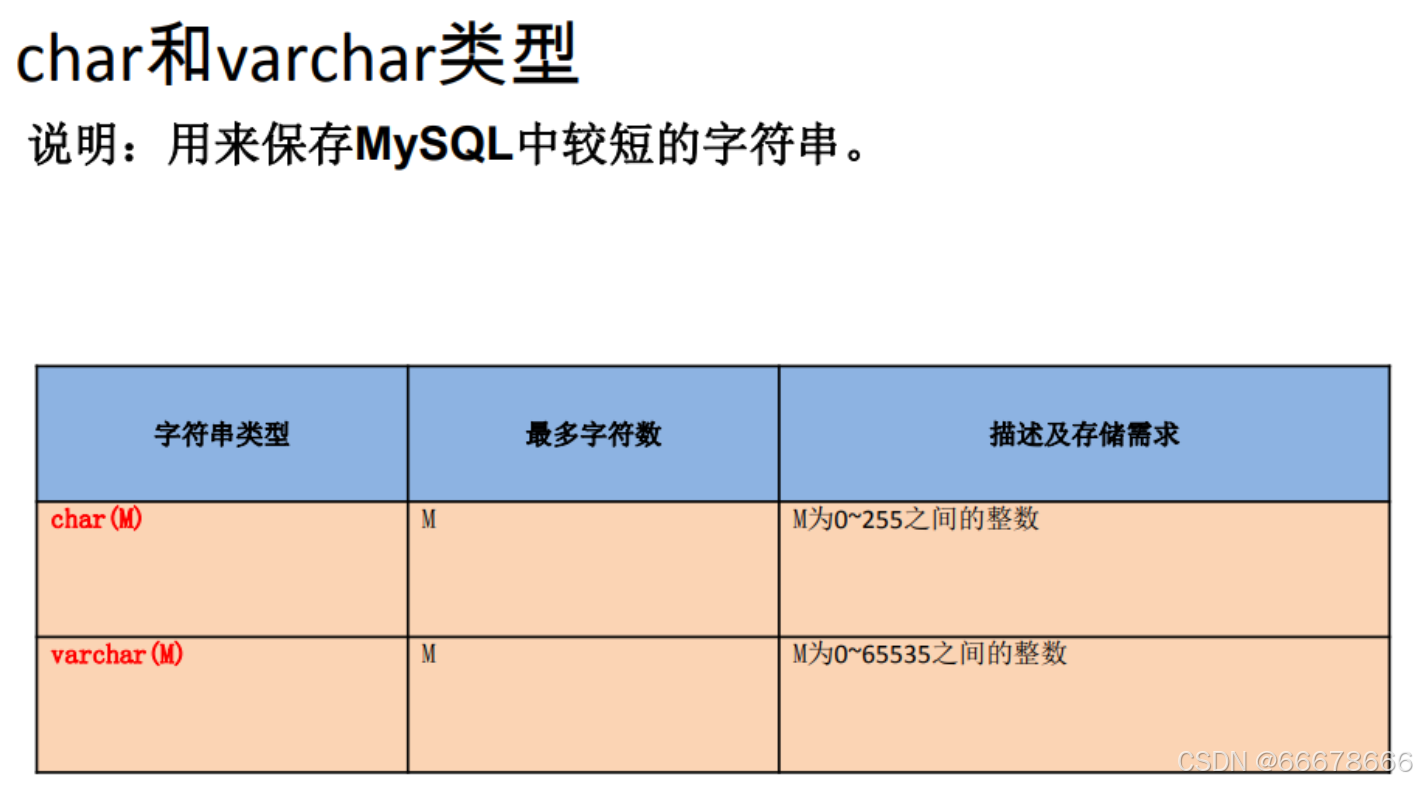

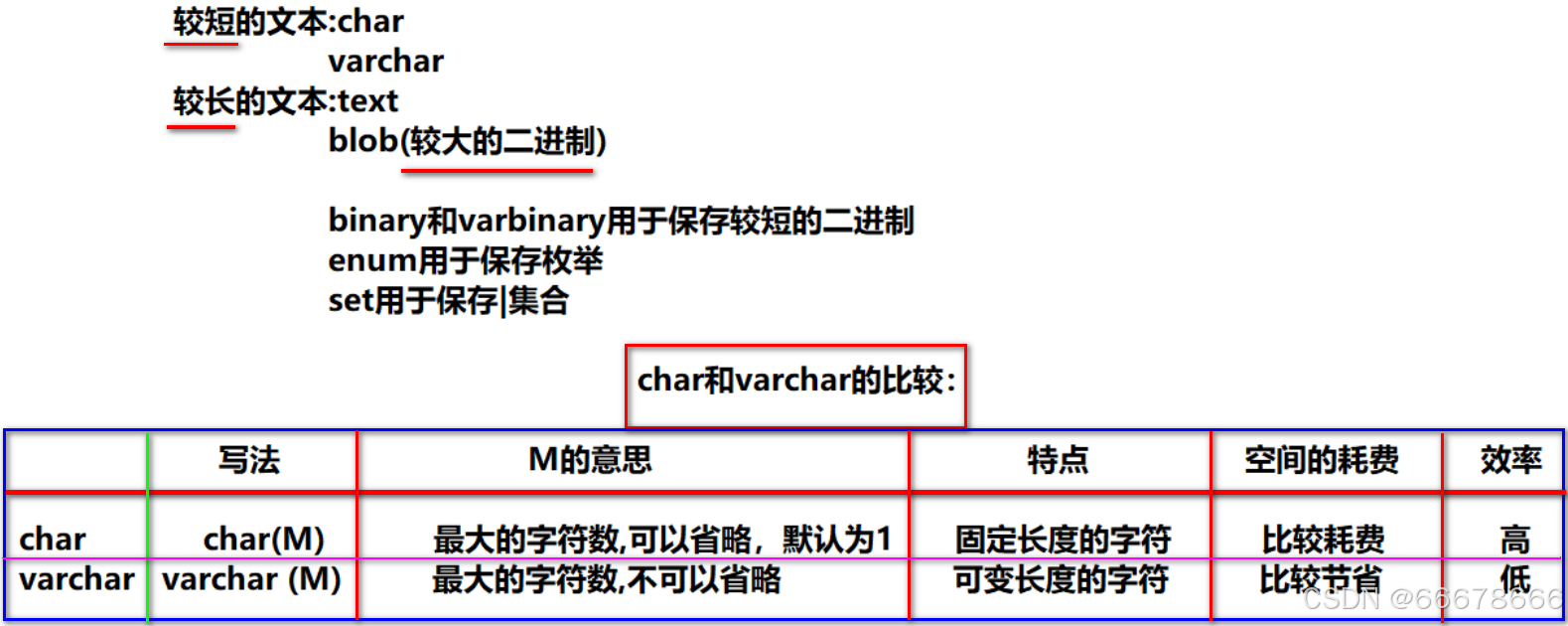
③日期型
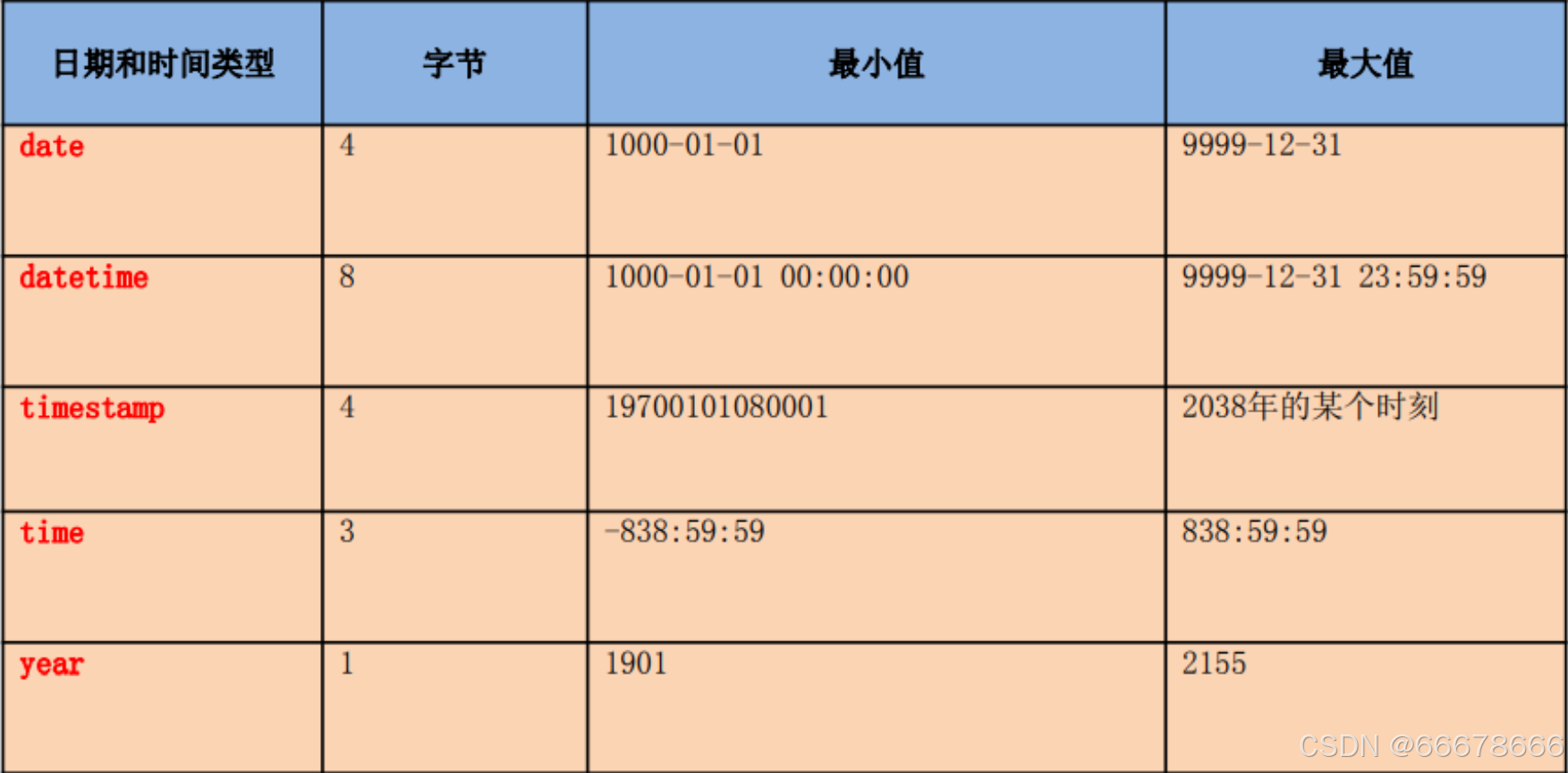

datetime和timestamp的区别

常见约束
作用
限制表中的数据,保证其准确性和可靠性,是表级的强制规定`
分类(六大约束)
NOT NULL 非空约束用于 保证 该
字段的值不能为空
DEFAULT 默认约束用于 保证 该
字段的值有默认值
PRIMARY KEY 主键约束用于 保证 该
字段的值有唯一性并且非空
UNIQUE 唯一约束用于 保证 该
字段的值具有唯一性,可以为空
CHECK 检查约束 【mysql中不支持】比如年龄、性别
FOREIGN KEY 外键约束用于
限制两个表的关系,用于 保证 该字段的值必须来自于主表的关联列的值,在从表添加外键约束,用于引用主表中某列的值
- 比如:学生表的专业编号,员工表的部门编号,员工表的工种编号
外键特点:
1、要求在从表设置外键关系
2、从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求
3、主表的关联列必须是一个key(一般是主键或唯一)
4、插入数据时,先插入主表,再插入从表;删除数据时,先删除从表,再删除主表
主键和唯一对比

添加约束的时机
1、约束的添加分类
1、
列级约束: 六大约束 语法上都支持,但 外键约束没有效果
2、表级约束: 除了非空、默认,其他的都支持

2、创建表时
添加列级约束语法:
直接在
字段名和类型后面追加约束类型即可。
只支持:默认、非空、主键、唯一
示例

添加表级约束语法:
在各个字段的
最下面
【constraint 约束名】 约束类型(字段名)
不支持:默认、非空
示例

CREATE TABLE stuinfo(
id INT,
stuname VARCHAR(20),
gender CHAR(1),
seat INT,
age INT,
majorid INT,
CONSTRAINT pk PRIMARY KEY(id), #主键
CONSTRAINT uq UNIQUE(seat), #唯一键
CONSTRAINT ck CHECK(gender ='男' OR gender = '女'),#检查
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)#外键
);
CREATE TABLE major(
id INT PRIMARY KEY,
majorName VARCHAR(20)
);
# DROP TABLE stuinfo;
# SHOW INDEX FROM stuinfo;
一般涉及
外键时添加表级约束,其他使用列级约束即可
示例

CREATE TABLE IF NOT EXISTS stuinfo(
id INT PRIMARY KEY,
stuname VARCHAR(20) NOT NULL,
gender CHAR(1),
seat INT UNIQUE,
age INT DEFAULT 18,
majorid INT,
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)#外键
);
CREATE TABLE major(
id INT PRIMARY KEY,
majorName VARCHAR(20)
);
3、修改表时
添加列级约束语法:
ALTER TABLE表名MODIFY COLUMN字段名 字段类型 新约束;
添加列级约束语法:
ALTER TABLE表名ADD【CONSTRAINT约束名】 约束类型(字段名) 【外键的引用】

4、删除约束

5、标识列(自增长列)
无需手动插入,
系统提供默认的序列值
特点:
1、标识列必须和主键搭配吗?
不一定,但是要求是一个key;主键、外键、唯一都叫key,所以都可以搭配2、一个表
最多有一个标识列3、标识列
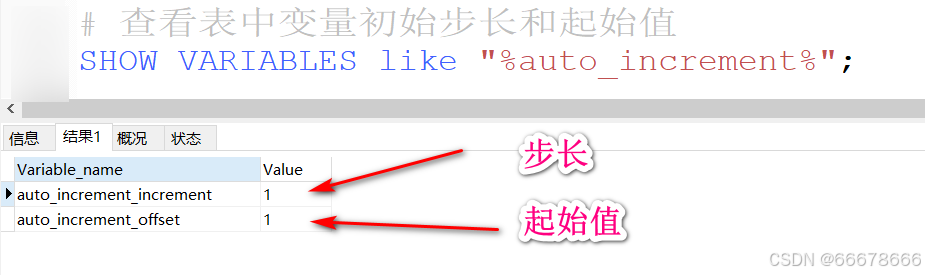
类型只能是数值型4、标识列可以通过下述sql 语句:
SET auto_increment_incremnet=3;
设置步长,可以通过手动插入值,设置起始值
查看表中变量初始步长和起始值
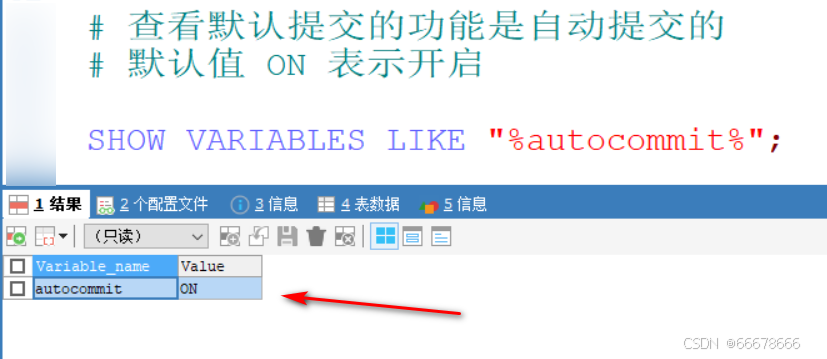
SHOW VARIABLES like "%auto_increment%";
设置步长
SET auto_increment_increment=1;
修改表时设置标识列
ALTER TABLEtab_indentityMODIFY COLUMNidINT PRIMARY KEY AUTO_INCREMENT;
修改表时删除标识列
ALTER TABLEtab_indentityMODIFY COLUMNidINT;


# 删除表
DROP TABLE IF EXISTS tab_indentity;
# 创建表时设置标识列
CREATE TABLE IF NOT EXISTS tab_indentity(
id INT PRIMARY KEY auto_increment,
NAME VARCHAR(20)
);
# 插入数据
INSERT INTO tab_indentity VALUES(null,"tom");
INSERT INTO tab_indentity VALUES(NULL,"jerry");
# 删除表数据
TRUNCATE TABLE tab_indentity;
DELETE FROM tab_indentity;
# 插入数据
INSERT INTO tab_indentity VALUES(NULL,"wang");
# 查询数据
SELECT * FROM tab_indentity;
# 展示表
SHOW TABLES;
# 设置步长
SET auto_increment_increment=1;
# 查看表中变量初始步长和起始值
SHOW VARIABLES like "%auto_increment%";
5、DCL语言(TCL 事务控制语言)
1、事务的特性
ACID:
原子性 Atomicity:一个事务不可再分割,要么 都执行 要么 都不执行一致性 Consistency:一个事务执行会使数据从一个 一致状态 切换到 另外一个一致状态隔离性 Isolation:一个事务的执行 不受 其他事务的 干扰持久性 Durability:一个事务一旦提交,则会 永久的改变 数据库的数据.`
2、事务的创建
1、隐式事务
- 事务
没有明显的开启和结束的标记,比如insert、update、delete语句
2、显式事务
- 事务
具有明显的开启和结束的标记
前提: 必须 先设置自动提交功能为禁用:set autocommit=0;
步骤1:
开启事务
set autocommit=0;
start transaction;------------------可选的步骤2:
编写事务中的sql语句(select insert update delete)
语句1;
...步骤3:
结束事务
commit;---------------------提交事务
或
rollback;------------------回滚事务
3、事务的并发问题

4、事务的隔离级别
| 事务的隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
READ UNCOMMITTED(读未提交) | √ | √ | √ |
READ COMMITTED(读已提交) | X | √ | √ |
REPEATABLE READ(可重复读) | X | X | √ |
SERIALIZABLE(串行化) | X | X | X |

查看隔离级别
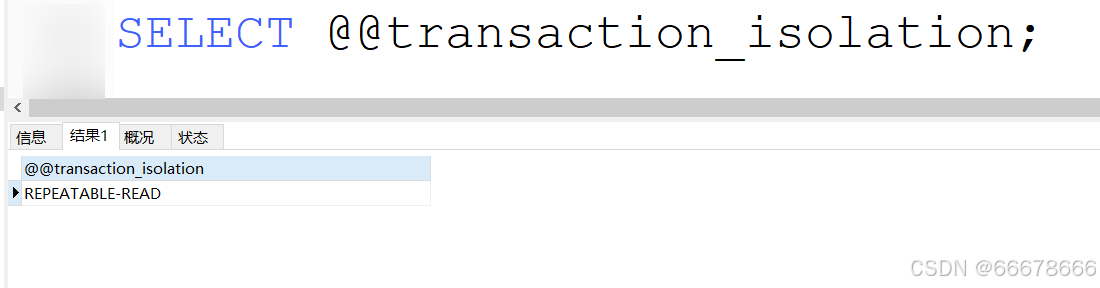
SELECT @@transaction_isolation;
SELECT @@GLOBAL.transaction_isolation;------查看全局的隔离级别
设置隔离级别① 设置
当前MySQL链接的隔离级别
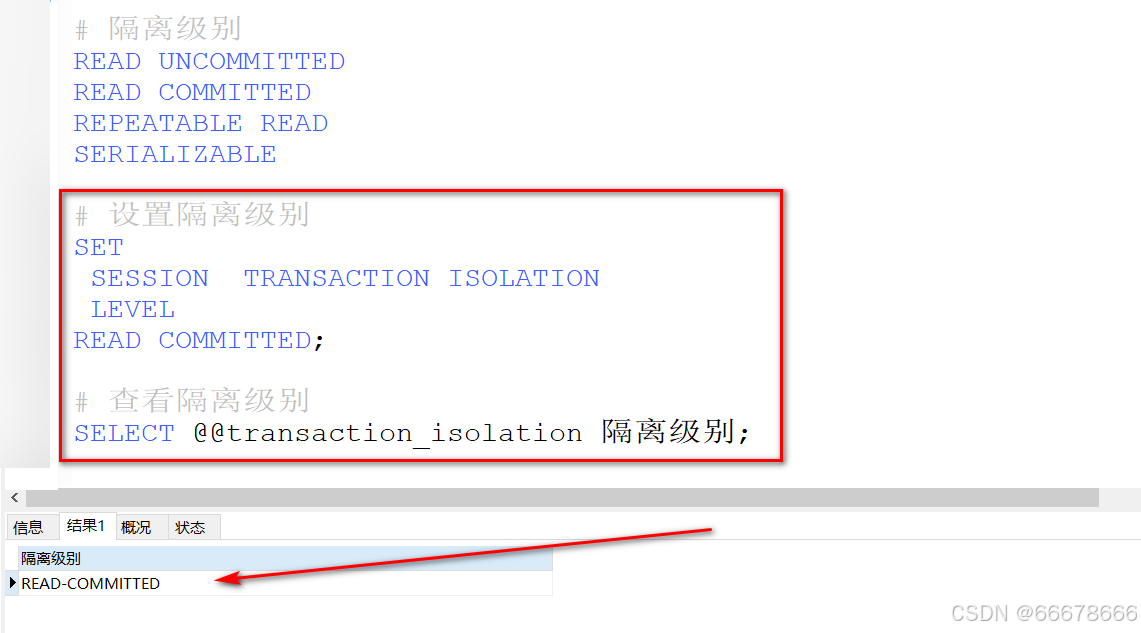
SET SESSION TRANSACTION ISOLATION LEVEL 隔离级别;
SESSION加不加都可以,但是不加的时候,执行后不会马上生效,所以最好加上。② 设置数据库系统
全局或会话的隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL 隔离级别;
SET SESSION TRANSACTION ISOLATION LEVEL 隔离级别;
SAVEPOINT的使用节点名:
设置保存点,要和ROLLBACK一起使用才有意义
用法:
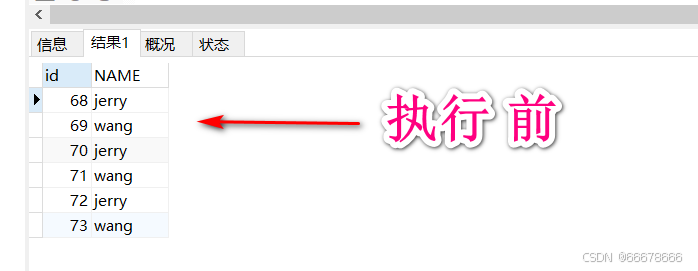
执行上述代码前:
执行上述代码后:


示例代码:
# 删除表
DROP TABLE IF EXISTS tab_indentity;
# 创建表时设置标识列
CREATE TABLE IF NOT EXISTS tab_indentity(
id INT PRIMARY KEY auto_increment,
NAME VARCHAR(20)
);
# 插入数据
INSERT INTO tab_indentity VALUES(66,"tom");
INSERT INTO tab_indentity VALUES(NULL,"jerry");
INSERT INTO tab_indentity VALUES(NULL,"wang");
# SAVEPOINT 节点名:设置保存点,
# 要和 ROLLBACK 一起使用才有意义
set autocommit = 0;
DELETE FROM tab_indentity WHERE id = 68;
SAVEPOINT a;#设置保存点
DELETE FROM tab_indentity WHERE id = 69;
ROLLBACK TO a;
SELECT * FROM tab_indentity;
五、视图
① 简述(理解、优点、应用场景等)
1、可以理解成
一张虚拟的表,只保存SQL逻辑,不保存查询结果.
2、视图和表的区别
3 、
视图和表的区别
- 复用
sql语句- 简化复杂的
sql操作,不必知道它的查询细节保护数据,提高安全性4、
应用场景
多个地方用到同样的查询结果- 该查询结果使用的
sql语句较复杂

② 视图的创建、修改、删除、查看
创建视图:
CREATE VIEW视图名AS查询语句;
查看视图:
DESC视图名;
SHOW CREATE VIEW视图名;
SHOW CREATE VIEW视图名\G;【
\G只是简化显示内容】
视图结构的修改:
CREATE OR REPLACE VIEW视图名AS查询语句;
或
ALTER VIEW视图名AS查询语句;
视图的删除:
DROP VIEW [if exists]视图名1,视图名2,视图名3;
- 用户可以一次删除
一个或者多个视图,前提是必须有该视图的drop权限
③ 视图数据 增、删、改、查
1、
查看视图的数据 ★
SELECT * FROM视图名;
2、
插入数据到视图
INSERT INTO视图名(字段名)VALUES(字段值);
3、
修改视图的数据
UPDATE视图名SET字段名=字段值WHERE条件;
4、
删除视图的数据
DELETE FROM视图名WHERE条件;
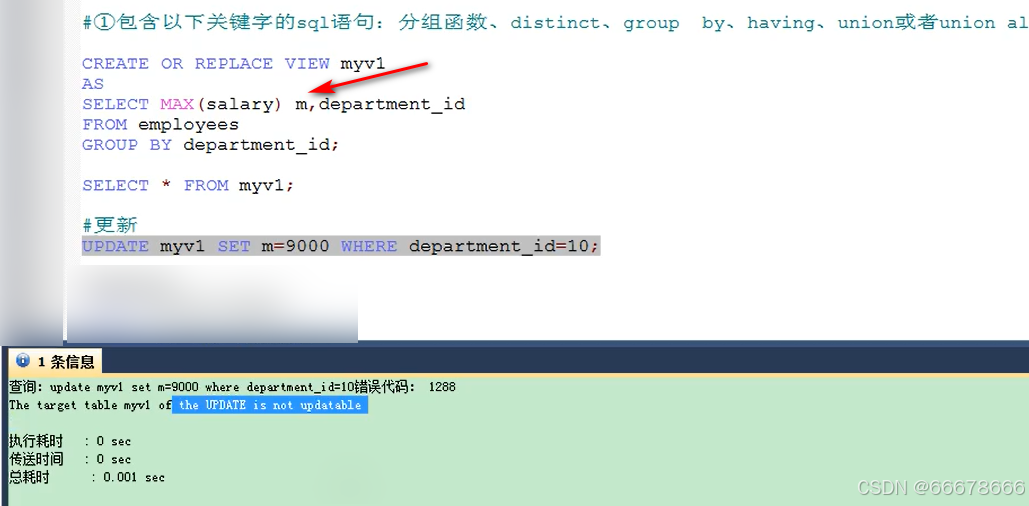
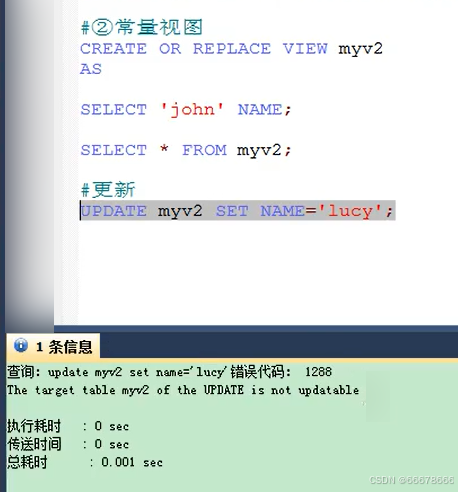
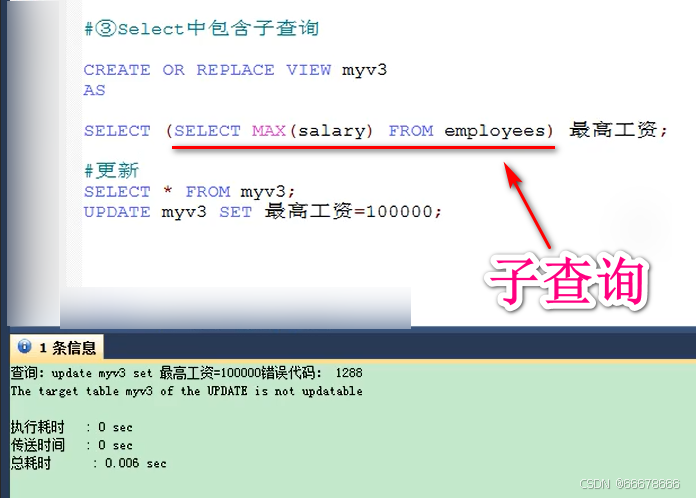
【注意】: 对
视图数据的增删改实际就是对源表数据的增删改;
实际应用中视图都是为简化查询而创建的,也不会对视图的数据进行增删改,而且这样做影响源表数据,会有安全问题,而且只有简单查询的视图才能进行数据增删改,如下述图片中的就无法对视图进行数据的增删改操作
示例:
其他大差不差,示例略

六、变量
系统变量
系统变量可以分为全局变量和会话变量
使用语法:
使用示例:



# GLOBAL|[SESSION] 全局或会话级别
# 1.查看所有系统变量
SHOW GLOBAL|[SESSION] VARIABLES;
# 2.查看满足条件的部分系统变量
SHOW GLOBAL|[SESSION] VARIABLES LIKE '%char%';
# 3.查看指定的系统变量的值
SELECT @@GLOBAL|[SESSION] 系统变量名;
# 4.为某个系统变量赋值
# 方式一:
SET GLOBAL|[SESSION] 系统变量名=值;
# 方式二:
SET @@GLOBAL|[SESSION] 系统变量名=值;
①查看所有会话变量
SHOW SESSION VARIABLES;
②查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE '%char%';
③查看指定的会话变量的值
SELECT @@AUTOCOMMIT;
SELECT @@SESSION.TRANSACTION_ISOLATION;
④为某个会话变量赋值
SET @@SESSION.TRANSACTION_ISOLATION='READ-UNCOMMITTED';
SET SESSION TRANSACTION_ISOLATION='READ-COMMITTED';
自定义变量
自定义变量可以分为用户变量和局部变量
用户变量



用户变量
作用域:
针对于当前会话(连接)有效
作用域同会话变量
可以应用在任何地方
即用在 begin end 的里面或外面
使用
①声明并初始化
SET @变量名=值;
SET @变量名:=值;
SELECT @变量名:=值;
②赋值(更新变量的值)
方式一:
SET @变量名=值;
SET @变量名:=值;
SELECT @变量名:=值;
方式二:
SELECT 字段 INTO @变量名
FROM 表;
③查看变量的值
SELECT @变量名;
注意
操作符 = 或 :=
SET 都两个都可以用
SELECT 只能用 :=
局部变量


局部变量
作用域
仅仅在定义它的 begin end 块中有效,
应用在 begin end 中的第一句话
使用
①声明
DECLARE 变量名 类型;
DECLARE 变量名 类型 【DEFAULT 变量的值】;
【类型为MySQL中的数据类型,
如:int, float, date, varchar(length)】
②赋值(更新变量的值)
方式一:
SET 局部变量名=值;
SET 局部变量名:=值;
SELECT @局部变量名:=值;
方式二:
SELECT 字段 INTO 局部变量名
FROM 表;
③查看变量的值
SELECT 局部变量名;
用户变量和局部变量的对比
| 自定义变量分类 | 作用域 | 定义位置 | 语法 |
|---|---|---|---|
用户变量 | 当前会话 | 会话的任何地方 | 加@符号,不用指定类型 |
局部变量 | BEGIN END中 | BEGIN END中的第一句话 | 一般不用加@,需要指定类型 |
七、存储过程和函数
存储过程
定义一组经过
预先编译的sql语句的集合
优点
提高了sql语句的复用性简化操作- 减少编译次数,和数据库服务器的链接次数,
提高了效率
分类
无返回无参- 仅仅带
in类型,无返回有参- 仅仅带
out类型,有返回无参- 既带
in又带out,有返回有参- 带
inout,有返回有参
注意:in、out、inout都可以在一个存储过程中带多个
参数模式解释:
in: 该参数只能作为输入参数
out: 该参数只能作为输出参数,即:返回值
inout: 该参数既能作为输入参数传入,又可以作为输出参数返回
语法
create procedure存储过程名(in|out|inout参数名 参数类型,…)
begin
存储过程体(一组合法的sql语句)
end
注意事项
- 如果 存储过程体
仅仅只有一句话,begin end可以省略- 存储过程体 中的每条
sql语句的结尾要求必须加分号- 存储过程 的
结尾可以使用delimiter重新设置
语法
delimiter结束标记
示例:
1.设置结束标记
delimiter$
2.创建存储过程结尾加上结束标记
create procedure存储过程名(in|out|inout参数名 参数类型,…)
begin
sql语句1;
sql语句2;
end $
3.调用存储过程
call存储过程名(实参列表)
示例

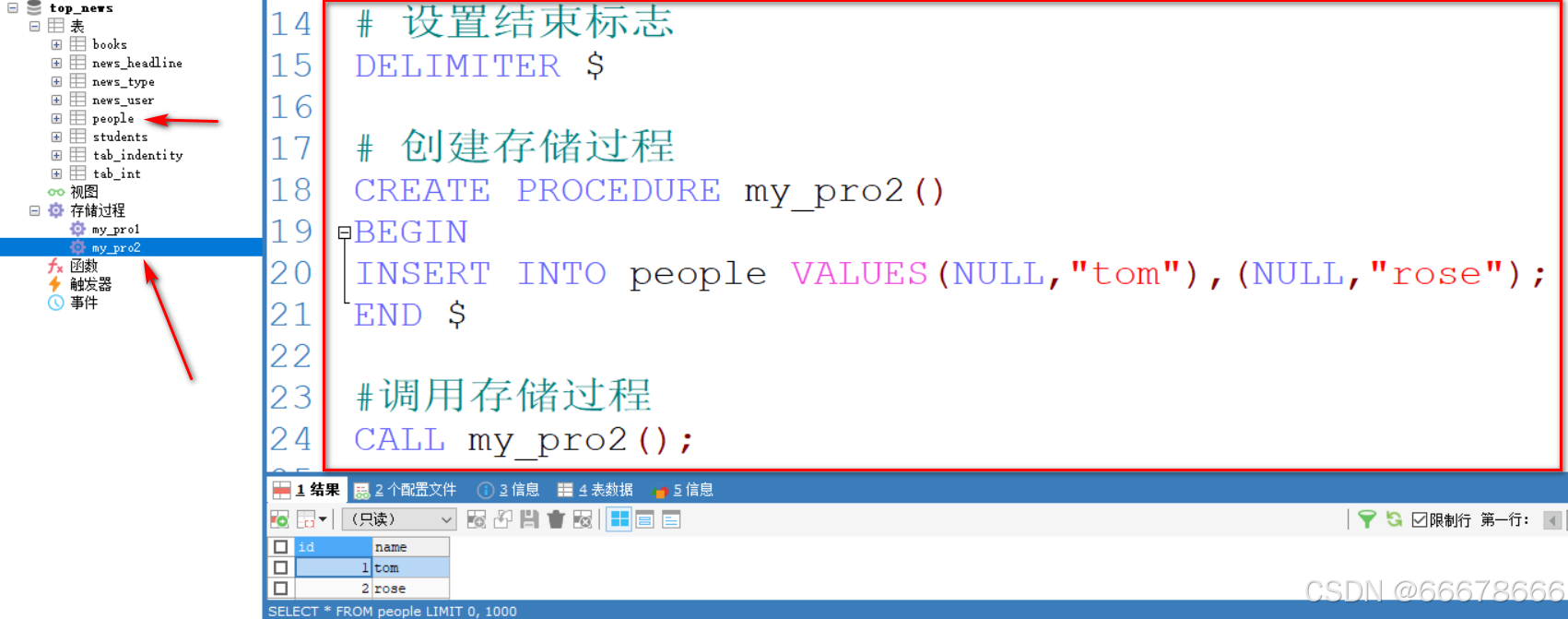
# 创建表
CREATE TABLE IF NOT EXISTS people(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
# 插入数据
#INSERT INTO students VALUES(null,"tom");
# 查询表
SELECT * FROM people;
# 设置结束标志
DELIMITER $
# 创建存储过程
CREATE PROCEDURE my_pro2()
BEGIN
INSERT INTO people VALUES(NULL,"tom"),(NULL,"rose");
END $
#调用存储过程
CALL my_pro2();
#删除存储过程
DROP PROCEDURE IF EXISTS my_pro2;
#删除表
DROP TABLE IF EXISTS people;
# 创建表
CREATE TABLE IF NOT EXISTS students(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
#查询表
SELECT * FROM students;
#插入数据
#INSERT INTO students VALUES(null,"tom");
#创建存储过程
CREATE PROCEDURE my_pro1()
BEGIN
INSERT INTO students VALUES(null,"tom"),(null,"rose");
END;
#调用存储过程
CALL my_pro1();
调用存储过程
call存储过程名 (实参列表)
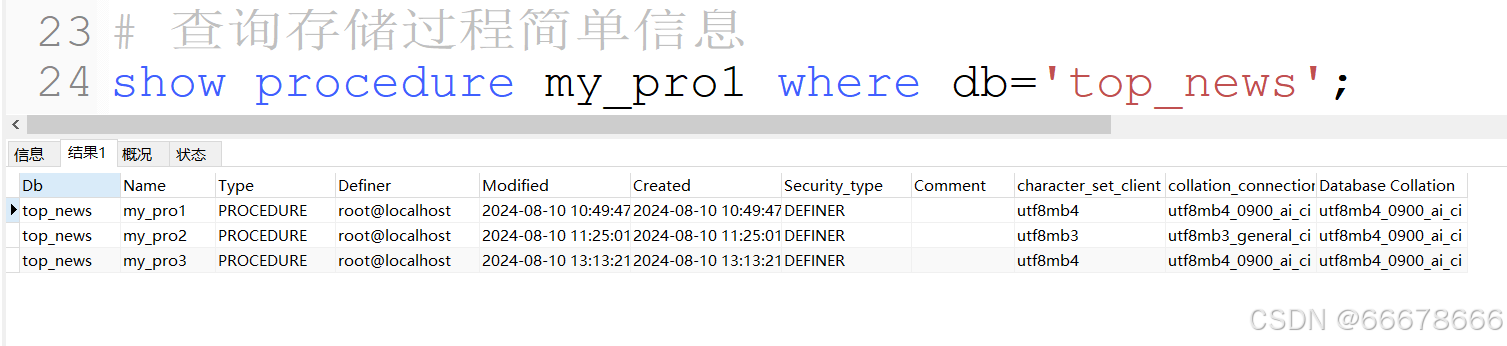
MySQL存储过程的查询简单信息
show procedure status where db=‘数据库名’;
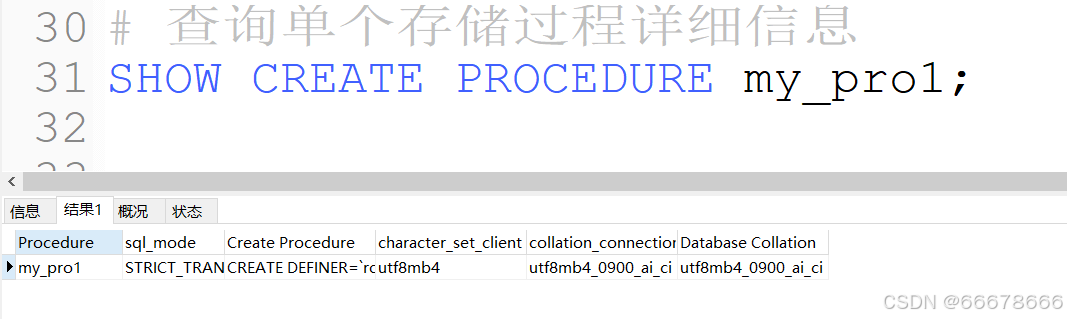
单个详细信息
SHOW CREATE PROCEDURE数据库.存储过程名;
MySQL存储过程的删除
DROP PROCEDURE IF EXISTS存储过程名称;
不支持一次删除多个
MySQL存储过程的注释格式
单行注释:-- 注释内容
多行注释:/* 注释内容 */
函数
定义一组经过
预先编译的sql语句的集合,批处理语句
优点
提高了sql语句的复用性简化操作- 减少编译次数,和数据库服务器的链接次数,
提高了效率
创建
create FUNCTION函数名(参数名 参数类型,…)
RETURNS返回值类型
begin
函数体
end
注意事项
参数列表包含两部分:参数名 参数类型函数体:肯定会有return语句,如果没有会报错;如果return语句没有放在函数体的最后,也不报错,但不建议;- 函数体中
仅有一句话,则可以省略 begin end- 使用
delimiter语句设置结束标记
调用
SELECT函数名(实参列表)
查看
SHOW CREATE FUNCTION函数名;
删除
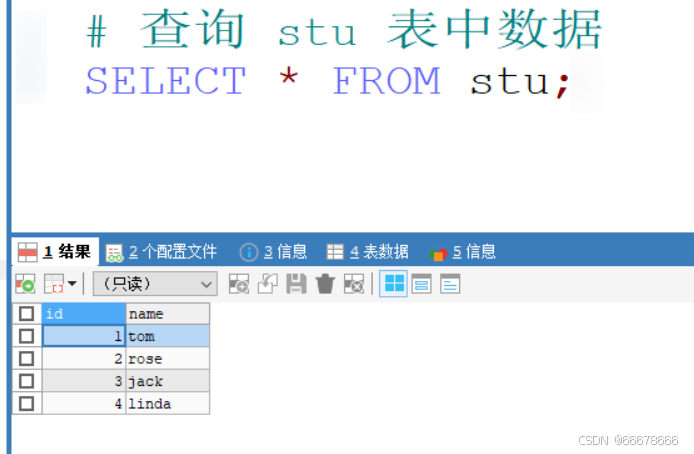
DROP FUNCTION IF EXISTS函数名;示例(
代码如下):
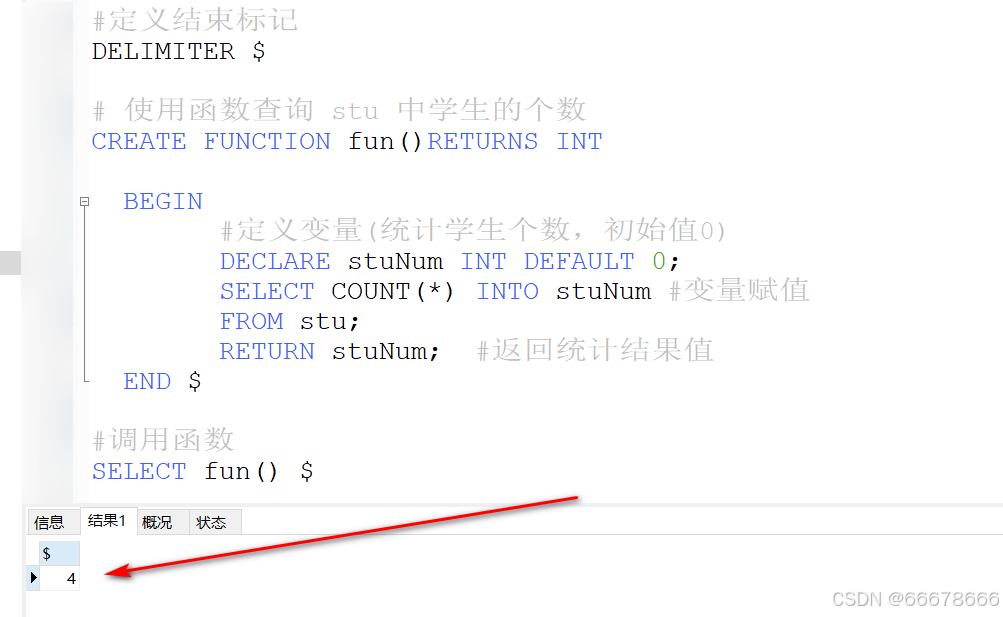
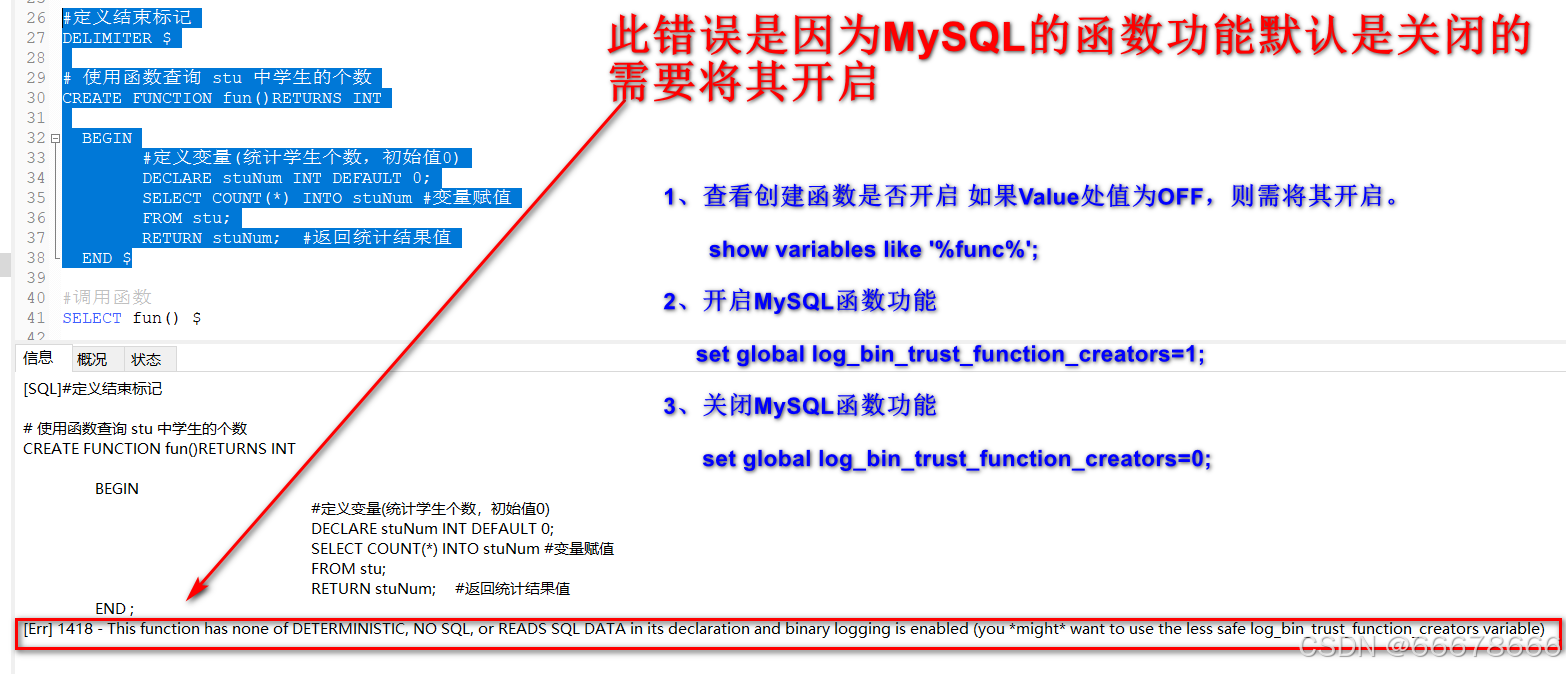
创建函数注意事项
注意事项
MySQL函数功能默认是关闭的,因此在创建函数前,首先查询其函数功能是否开启,否则关闭的情况下可能会出如下错误
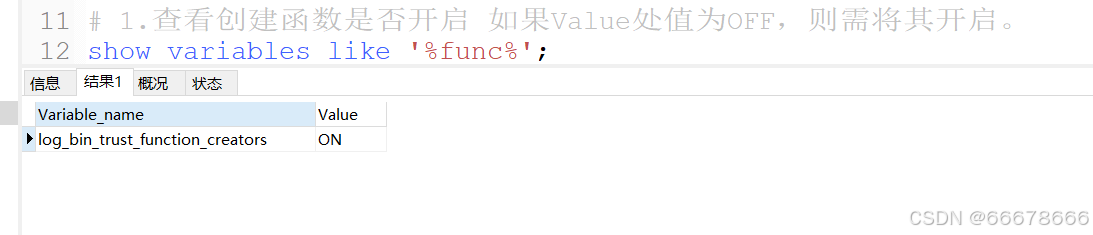
# 查看创建函数是否开启如果Value处值为OFF,则需将其开启。
show variables like %函数名%;
开启 MySQL函数功能
set global log_bin_trust_function_creators=1;
关闭 MySQL函数功能
set global log_bin_trust_function_creators=0;
# 创建表
CREATE TABLE IF NOT EXISTS stu(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
# 查询 stu 表中数据
SELECT * FROM stu;
# 1.查看创建函数是否开启 如果Value处值为OFF,则需将其开启。
show variables like '%func%';
# 2.开启MySQL函数功能
set global log_bin_trust_function_creators=1;
# 3.关闭MySQL函数功能
set global log_bin_trust_function_creators=0;
# 删除函数
DROP FUNCTION IF EXISTS fun;
#定义结束标记
DELIMITER $
# 使用函数查询 stu 中学生的个数
CREATE FUNCTION fun()RETURNS INT
BEGIN
#定义变量(统计学生个数,初始值0)
DECLARE stuNum INT DEFAULT 0;
SELECT COUNT(*) INTO stuNum #变量赋值
FROM stu;
RETURN stuNum; #返回统计结果值
END $
#调用函数
SELECT fun() $
存储过程和函数区别
| 分类 | 关键字 | 调用语法 | 返回值 | 应用场景 |
|---|---|---|---|---|
函数 | FUNCTION | SELECT 函数() | 只能有一个 | 适合做处理数据后返回一个结果 |
存储过程 | PROCEDURE | CALL 存储过程() | 可以有0个或多个 | 适合做批量插入、批量更新 |
八、流程控制结构
分类
分类
顺序结构分支结构循环结构
顺序结构
程序从上往下按顺序依次执行。没啥说的
分支结构
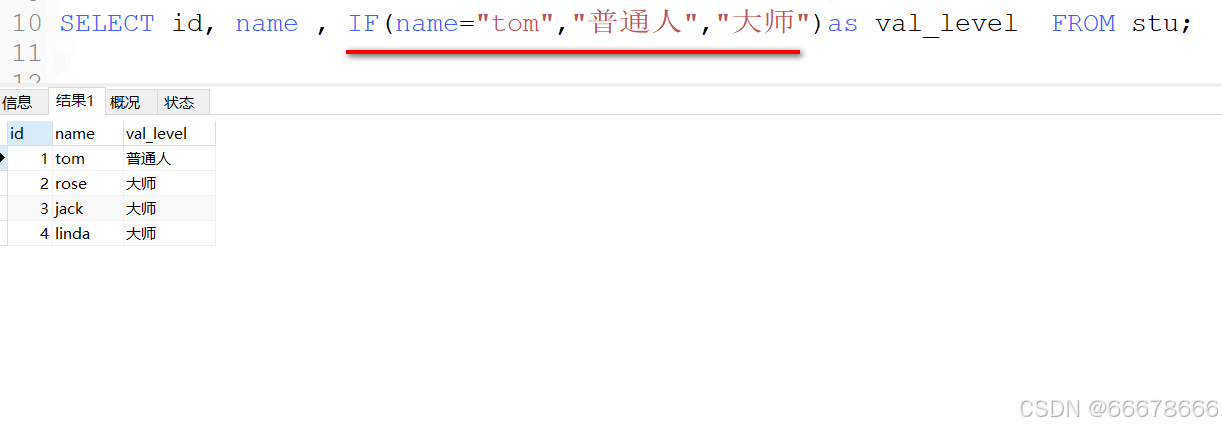
if函数
语法:
if(条件,值1,值2)
特点: 可以用在任何位置
示例:
case结构
情况一: 类似于
switch
case表达式|变量|字段|
when要判断的值1then结果1或语句1(如果是语句,需要加分号)
when要判断的值2then结果2或语句2(如果是语句,需要加分号)
…
else结果n或语句n(如果是语句,需要加分号)
end【case】(如果是放在begin end中需要加上case,如果放在select后面不需要)
情况二: 类似于
多重if语句
case表达式|变量|字段|
when要判断的条件1then结果1或语句1(如果是语句,需要加分号)
when要判断的条件2then结果2或语句2(如果是语句,需要加分号)
…
else结果n或语句n(如果是语句,需要加分号)
end【case】(如果是放在begin end中需要加上case,如果放在select后面不需要)


if结构/if elseif
语法:
if情况1 then语句1;
elseif情况2 then语句2;
...
else语句n;
end if;
特点:
- 实现
多重分支,只能用在begin end中
if 函数、case 结构、if 结构比较
| 分类 | 应用场合 |
|---|---|
if函数 | 简单双分支 |
case结构 | 等值判断 的多分支 |
if结构 | 区间判断 的多分支 |
循环结构
分类
while ···· end while[标签:]
while循环条件do
循环体;
end while[标签];
2.repeat···· end repeat[标签:]
repeat
循环体;
until结束循环的条件
end repeat[标签];
3.loop···· end loop[标签:]
loop
循环体;
end loop[标签];
loop循环不需要初始条件,这点和while循环相似,同时和repeat循环一>样不需要结束条件,leave语句的意义是离开循环。
可以模拟简单的死循环,想要中途退出,一定要搭配leave使用
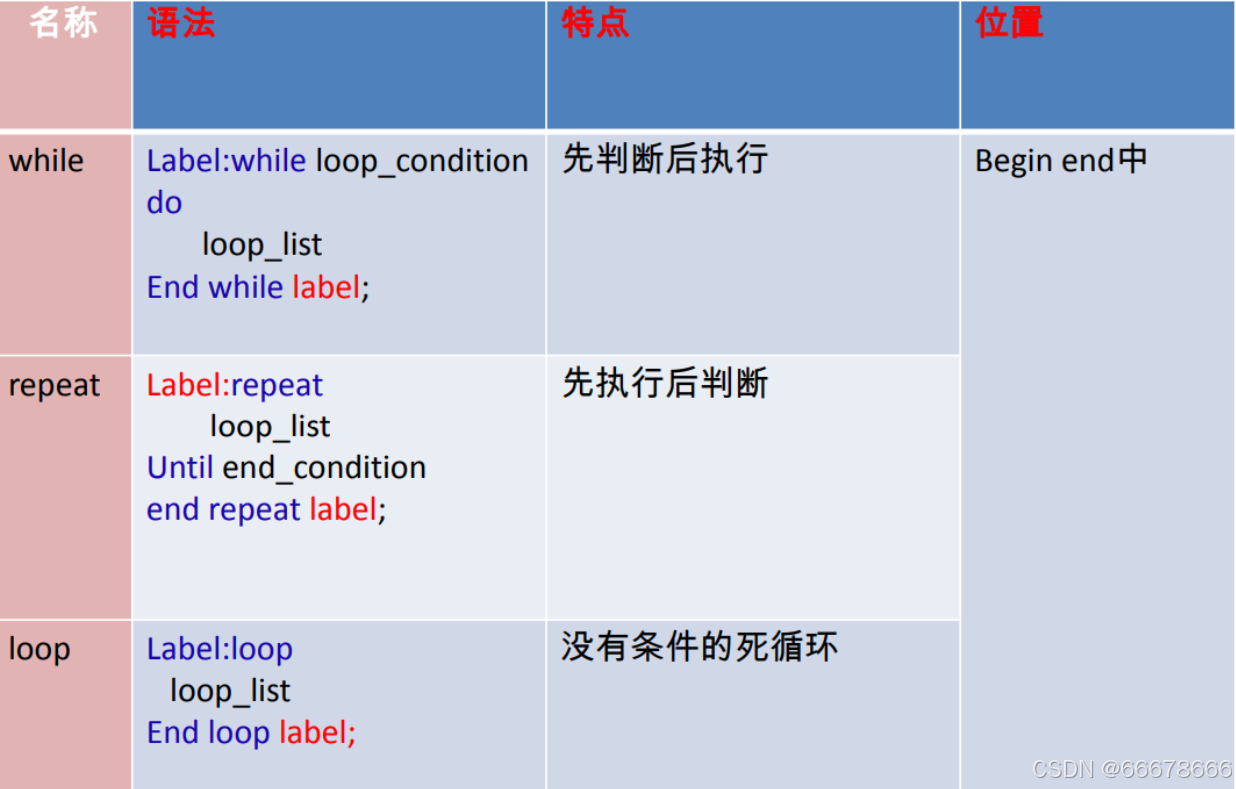
特点(可以参考代码演示理解)
- 只能放在
BEGIN END里面
- 如果要搭配
leave跳转语句,需要使用标签,否则可以不用标签>
iterate类似于continue,继续,结束当次循环,继续下一次循环;
leave类似于break,跳出,结束当前所在的循环,循环不再执行
代码演示
while ···· end while
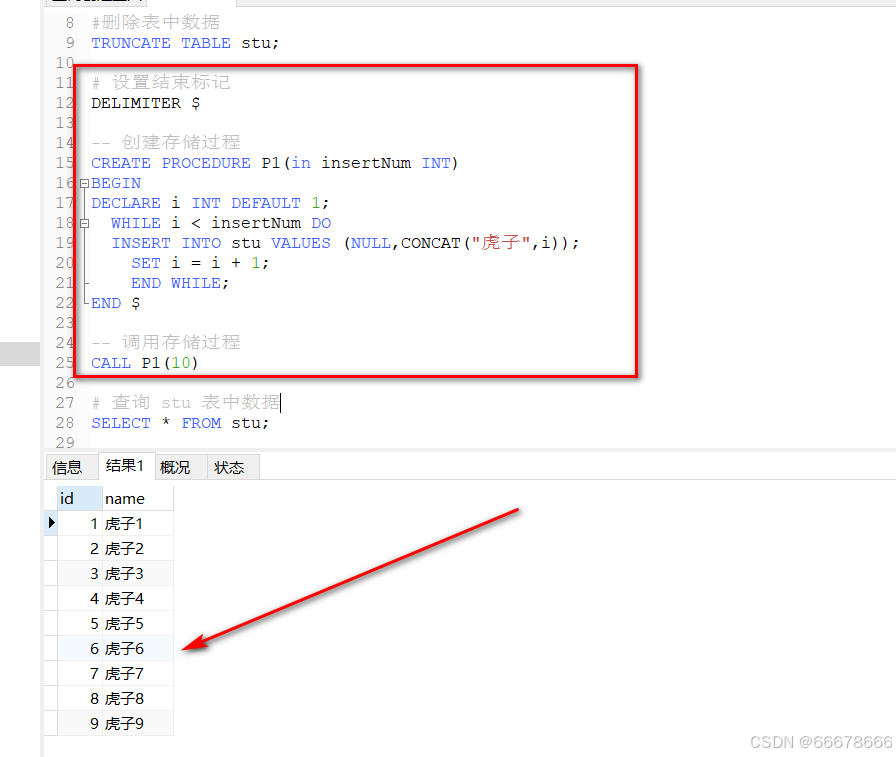
示例1:没有加入循环控制的语句
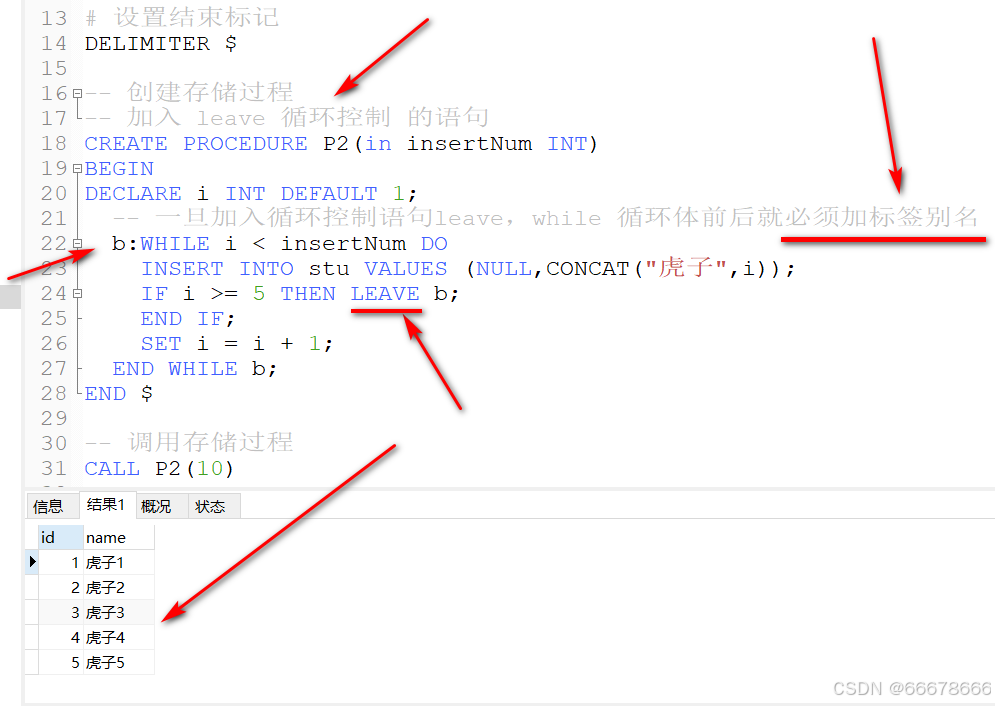
示例2:加入leave 循环控制的语句
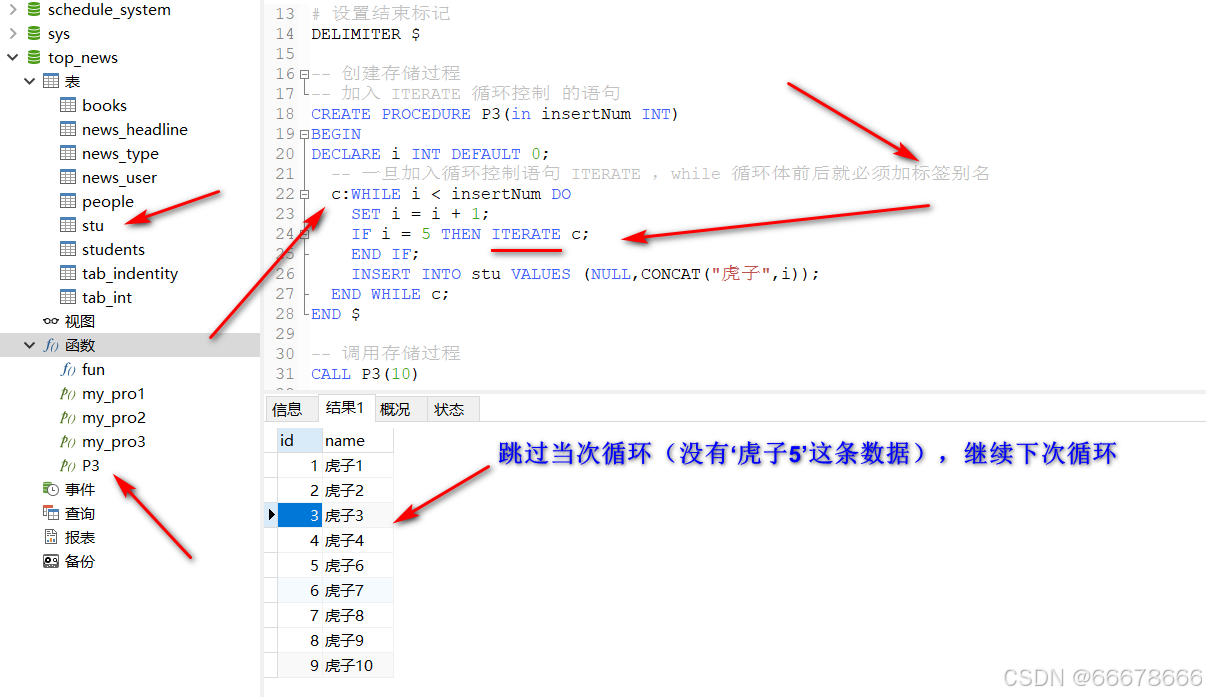
示例3:加入ITERATE 循环控制的语句
示例1代码:没有加入循环控制语句
# 创建表
CREATE TABLE IF NOT EXISTS stu(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
#删除表中数据
TRUNCATE TABLE stu;
# 设置结束标记
DELIMITER $
-- 创建存储过程
CREATE PROCEDURE P1(in insertNum INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i < insertNum DO
INSERT INTO stu VALUES (NULL,CONCAT("虎子",i));
SET i = i + 1;
END WHILE;
END $
-- 调用存储过程
CALL P1(10)
# 查询 stu 表中数据
SELECT * FROM stu;
示例2代码:加入循环控制 leave语句
# 创建表
CREATE TABLE IF NOT EXISTS stu(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
# 删除存储过程
DROP PROCEDURE IF EXISTS P2;
#删除表中数据
TRUNCATE TABLE stu;
# 设置结束标记
DELIMITER $
-- 创建存储过程
-- 加入 leave 循环控制 的语句
CREATE PROCEDURE P2(in insertNum INT)
BEGIN
DECLARE i INT DEFAULT 1;
-- 一旦加入循环控制语句leave,while 循环体前后就必须加标签别名
b:WHILE i < insertNum DO
INSERT INTO stu VALUES (NULL,CONCAT("虎子",i));
IF i >= 5 THEN LEAVE b;
END IF;
SET i = i + 1;
END WHILE b;
END $
-- 调用存储过程
CALL P2(10)
# 查询 stu 表中数据
SELECT * FROM stu;
示例3代码:加入ITERATE 循环控制语句
# 创建表
CREATE TABLE IF NOT EXISTS stu(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
# 删除存储过程
DROP PROCEDURE IF EXISTS P3;
#删除表中数据
TRUNCATE TABLE stu;
# 设置结束标记
DELIMITER $
-- 创建存储过程
-- 加入 ITERATE 循环控制 的语句
CREATE PROCEDURE P3(in insertNum INT)
BEGIN
DECLARE i INT DEFAULT 0;
-- 一旦加入循环控制语句 ITERATE ,while 循环体前后就必须加标签别名
c:WHILE i < insertNum DO
SET i = i + 1;
IF i = 5 THEN ITERATE c;
END IF;
INSERT INTO stu VALUES (NULL,CONCAT("虎子",i));
END WHILE c;
END $
-- 调用存储过程
CALL P3(10)
# 查询 stu 表中数据
SELECT * FROM stu;
repeat···· end repeat没有加入
循环控制的语句
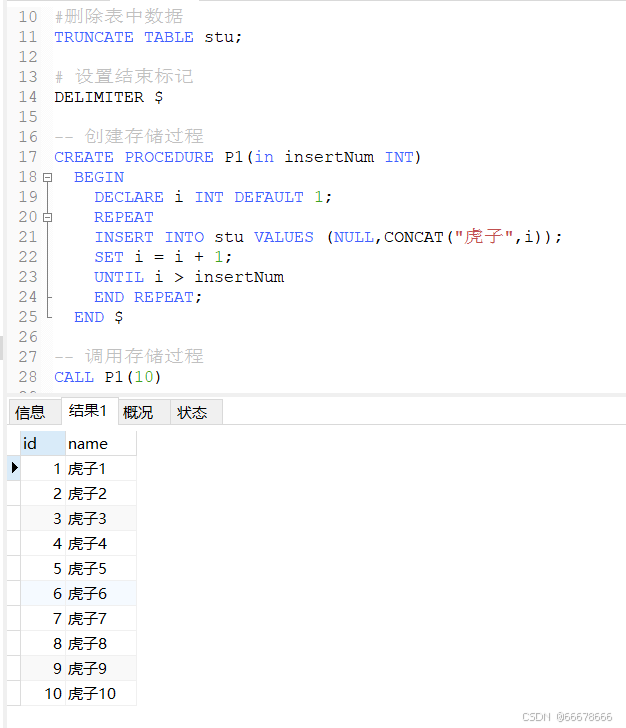
# 创建表
CREATE TABLE IF NOT EXISTS stu(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
# 删除存储过程
DROP PROCEDURE IF EXISTS P1;
#删除表中数据
TRUNCATE TABLE stu;
# 设置结束标记
DELIMITER $
-- 创建存储过程
CREATE PROCEDURE P1(in insertNum INT)
BEGIN
DECLARE i INT DEFAULT 1;
REPEAT
INSERT INTO stu VALUES (NULL,CONCAT("虎子",i));
SET i = i + 1;
UNTIL i > insertNum
END REPEAT;
END $
-- 调用存储过程
CALL P1(10)
# 查询 stu 表中数据
SELECT * FROM stu;
# 设置结束标记
DELIMITER $
-- 创建存储过程
-- 加入 ITERATE 循环控制 的语句
CREATE PROCEDURE P3(in insertNum INT)
BEGIN
DECLARE i INT DEFAULT 0;
-- 一旦加入循环控制语句 ITERATE ,while 循环体前后就必须加标签别名
c:WHILE i < insertNum DO
SET i = i + 1;
IF i = 5 THEN ITERATE c;
END IF;
INSERT INTO stu VALUES (NULL,CONCAT("虎子",i));
END WHILE c;
END $
-- 调用存储过程
CALL P3(10)
# 查询 stu 表中数据
SELECT * FROM stu;
loop ·····end loop
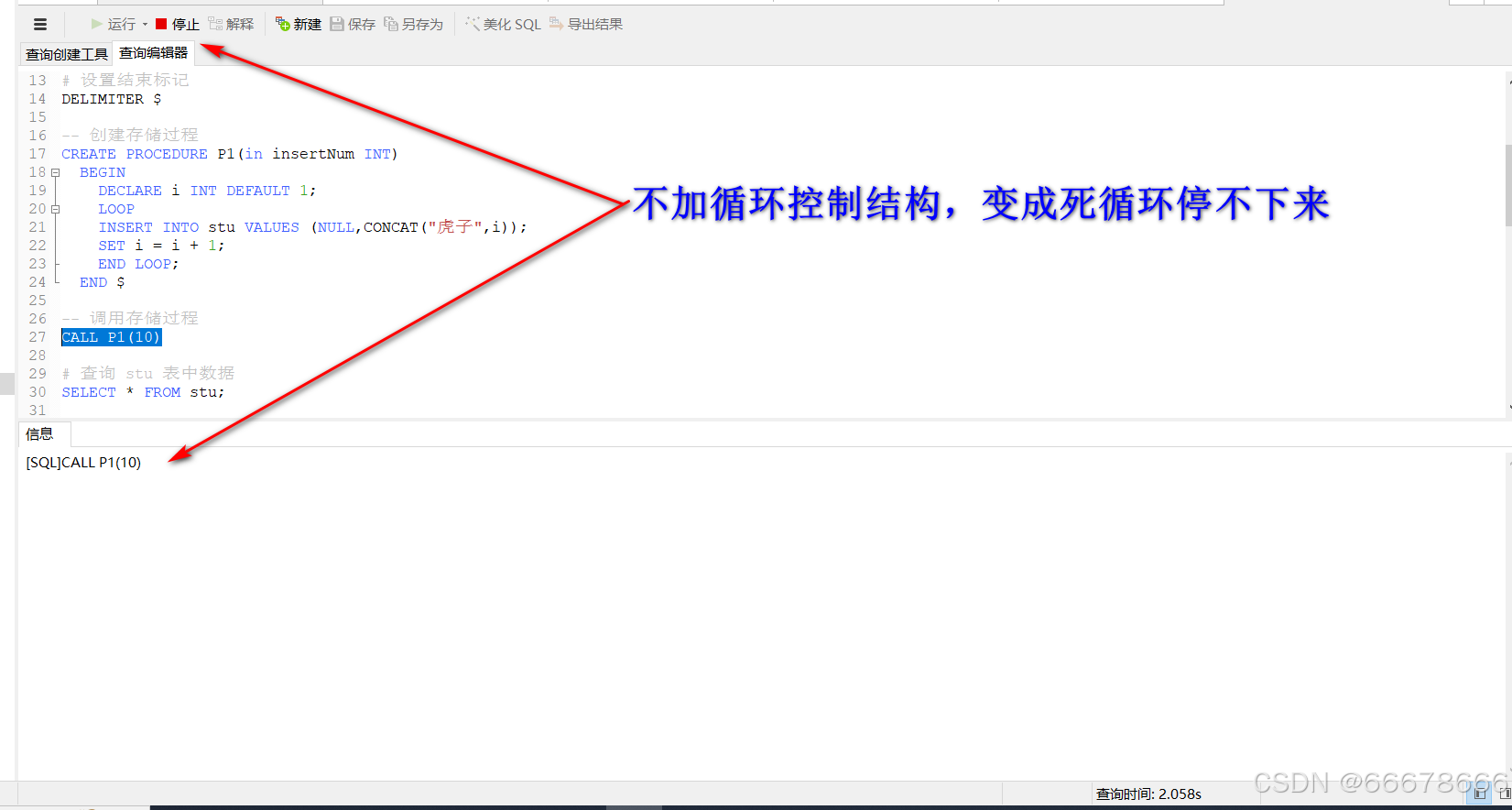
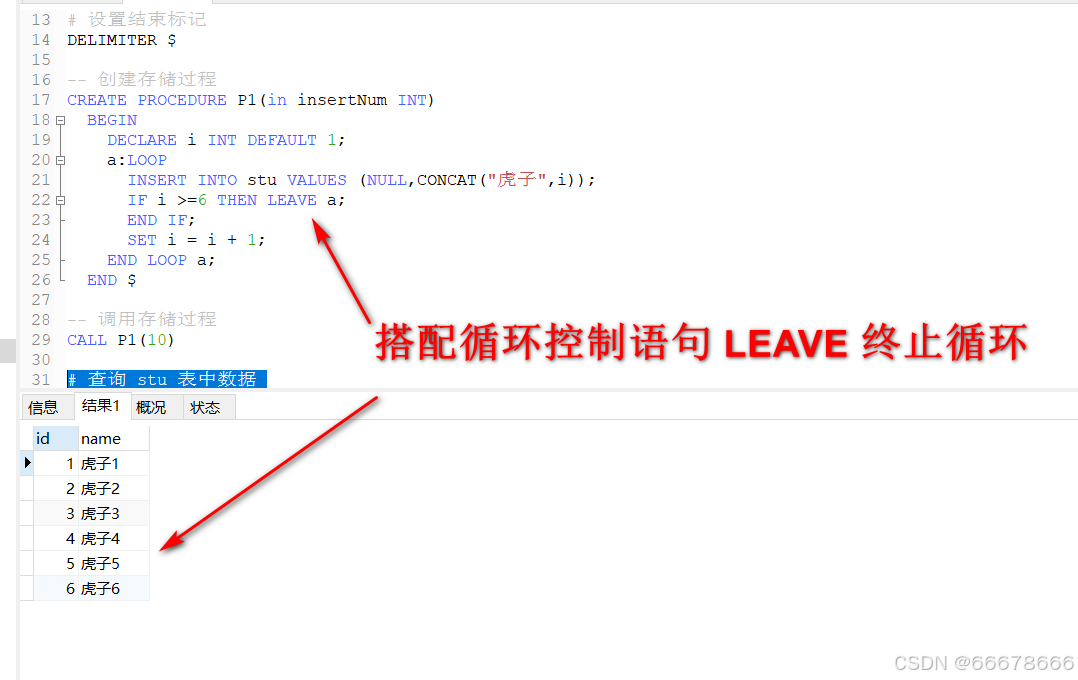
# 创建表
CREATE TABLE IF NOT EXISTS stu(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
# 删除存储过程
DROP PROCEDURE IF EXISTS P1;
#删除表中数据
TRUNCATE TABLE stu;
# 设置结束标记
DELIMITER $
-- 创建存储过程
CREATE PROCEDURE P1(in insertNum INT)
BEGIN
DECLARE i INT DEFAULT 1;
a:LOOP
INSERT INTO stu VALUES (NULL,CONCAT("虎子",i));
IF i >=6 THEN LEAVE a;
END IF;
SET i = i + 1;
END LOOP a;
END $
-- 调用存储过程
CALL P1(10)
# 查询 stu 表中数据
SELECT * FROM stu;
# 设置结束标记
DELIMITER $
-- 创建存储过程
-- 加入 ITERATE 循环控制 的语句
CREATE PROCEDURE P3(in insertNum INT)
BEGIN
DECLARE i INT DEFAULT 0;
-- 一旦加入循环控制语句 ITERATE ,while 循环体前后就必须加标签别名
c:WHILE i < insertNum DO
SET i = i + 1;
IF i = 5 THEN ITERATE c;
END IF;
INSERT INTO stu VALUES (NULL,CONCAT("虎子",i));
END WHILE c;
END $
-- 调用存储过程
CALL P3(10)
# 查询 stu 表中数据
SELECT * FROM stu;