SVM算法
SVM:支持向量机
目的:解决感知机的问题
感知机问题:
1.泛化能力弱
2.只关注错误点,不考虑各类别的分布,就会出现过拟合
一:SVM介绍
1.svm思想
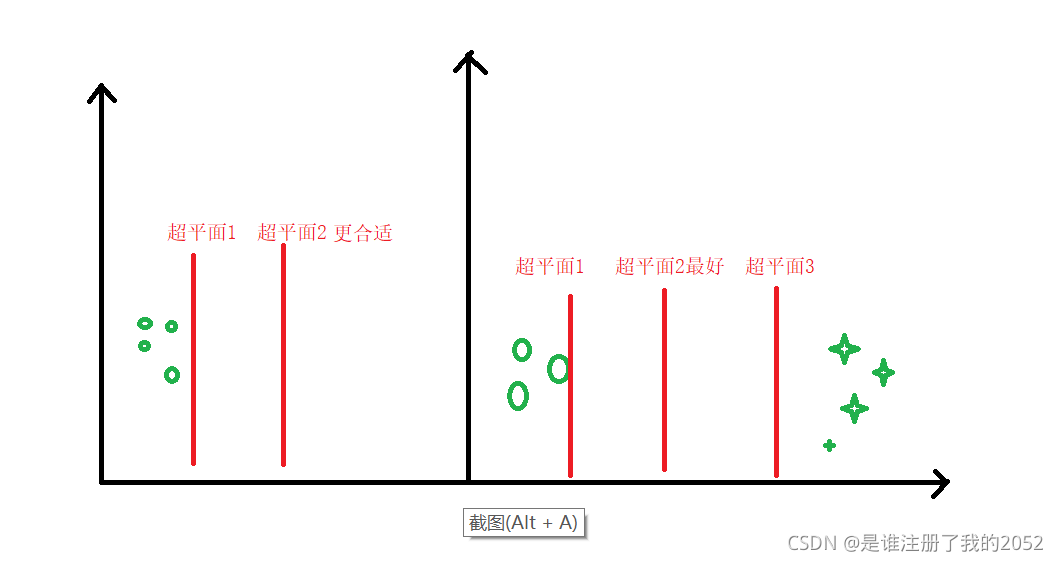
数据集中的点在分割之后离超平面越远越好
分割:理解为函数 f
超平面:理解为参数W , 决定函数的集合
分割和超平面理解为: f(W)
越远越好:
- 越远则预留的空间越大,可以容纳更多新的数据点,解决泛化能力
- 多个类别的时候要综合考虑类与类之间的距离
二.SVM模型
需要解决两个问题:
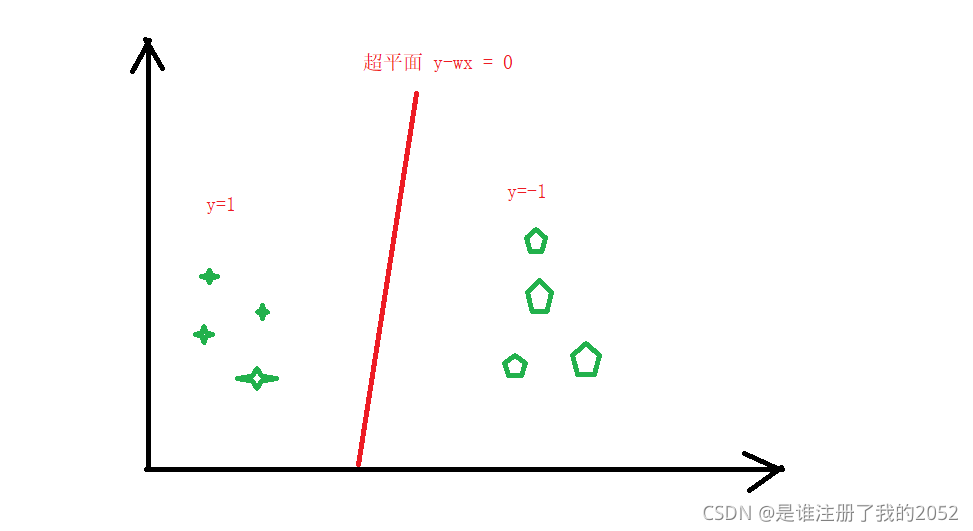
1.距离计算 max[marg(Wi,Xi)]
2.s.t 前提:所有分类都正确
- wx>0 , y=1
- wx<0 , y=-1
- 综合以上得出 y*wx>0
如图:
S V M 模 型 公 式 : 满 足 以 下 两 点 s . t 前 提 y × ( w x ) > 0 m a x [ m a r g ( W , X ) ] SVM模型公式:满足以下两点 \\ s.t前提 y × (wx) > 0 \\ max[marg(W,X)] SVM模型公式:满足以下两点s.t前提y×(wx)>0max[marg(W,X)]
三:SVM三个过程:间隔(建模),对偶(求解),核函数(升核)
3.1 间隔(建模)
第一步:距离公式和前提约束
距 离 公 式 : m a x ∣ W T X + b ∣ ∣ ∣ W ∣ ∣ 约 束 : s . t : y i ( W T x i + b ) > 0 距离公式:max{\frac{|W^TX+b|}{||W||}} \\ 约束:s.t : y_i(W^Tx_i+b)>0 距离公式:max∣∣W∣∣∣WTX+b∣约束:s.t:yi(WTxi+b)>0
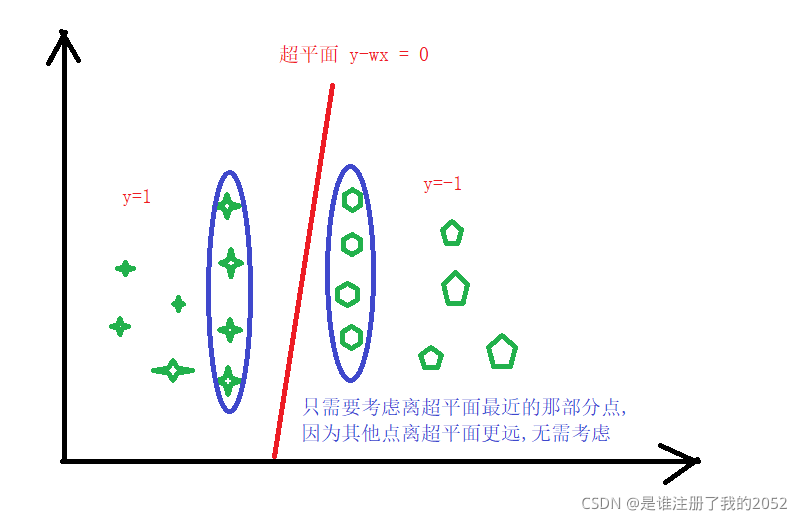
第二步:只需要考虑离超平面最近的点与超平面的距离即可
只 考 虑 离 超 平 面 最 近 的 点 : m a x ( m i n ∣ W T X + b ∣ ∣ ∣ W ∣ ∣ ) 约 束 : s . t : y i ( W T x i + b ) > 0 , 假 设 存 在 α > 0 , 则 y i ( W T x i + b ) = α > 0 所 以 s . t : m i n ( y i ( W T x i + b ) ) = α > 0 因 为 : y ∈ [ − 1 , 1 ] 所 以 : s . t : m i n ∣ W T x i + b ∣ = α 只考虑离超平面最近的点:max(min{\frac{|W^TX+b|}{||W||}}) \\ 约束:s.t : y_i(W^Tx_i+b)>0 , 假设存在α>0,则 y_i(W^Tx_i+b)=α>0 \\ 所以 s.t: min(y_i(W^Tx_i+b))=α>0 \\ 因为: y∈[-1,1] \\ 所以:s.t : min|W^Tx_i+b|=α 只考虑离超平面最近的点:max(min∣∣W∣∣∣WTX+b∣)约束:s.t:yi(WTxi+b)>0,假设存在α>0,则yi(WTxi+b)=α>0所以s.t:min(yi(WTxi+b))=α>0因为:y∈[−1,1]所以:s.t:min∣WTxi+b∣=α
第三步:简化距离公式
m a x α ∣ ∣ W ∣ ∣ s . t : m i n ( y i ( W T x i + b ) ) = α max\frac{α}{||W||} \\ s.t:min(y_i(W^Tx_i+b))=α max∣∣W∣∣αs.t:min(yi(WTxi+b))=α
第四步:缩放α
缩 放 α , 令 α = 1 , 则 公 式 简 化 为 : m a x 1 ∣ ∣ W ∣ ∣ s . t : m i n ( y i ( W T x i + b ) ) = 1 缩放α,令α=1,则公式简化为: \\ max\frac{1}{||W||} \\ s.t:min(y_i(W^Tx_i+b))=1 缩放α,令α=1,则公式简化为:max∣∣W∣∣1s.t:min(yi(WTxi+b))=1
第五步:根据二范式 ||W|| ,即W的平方再简化
m a x 1 ∣ ∣ W ∣ ∣ = m i n ∣ ∣ W ∣ ∣ = m i n W T W s . t : m i n ( y i ( W T x i + b ) ) = 1 即 y i ( W T x i + b ) > = 1 这 一 步 结 论 : m i n W T W s . t : y i ( W T x i + b ) > = 1 max\frac{1}{||W||}=min||W||=minW^TW \\ s.t:min(y_i(W^Tx_i+b))=1 即 y_i(W^Tx_i+b)>=1 \\ 这一步结论: \\ minW^TW \\ s.t:y_i(W^Tx_i+b)>=1 max∣∣W∣∣1=min∣∣W∣∣=minWTWs.t:min(yi(WTxi+b))=1即yi(WTxi+b)>=1这一步结论:minWTWs.t:yi(WTxi+b)>=1
第六步:数学上称为QP问题
凸 优 化 : m i n W T W N 个 约 束 , 因 为 x i ∈ [ 1 , N ] , s . t : y i ( W T x i + b ) > = 1 凸优化:minW^TW \\ N个约束,因为x_i∈[1,N] , s.t:y_i(W^Tx_i+b)>=1 凸优化:minWTWN个约束,因为xi∈[1,N],s.t:yi(WTxi+b)>=1
3.2 对偶(求解)
推导过程:有约束->无约束->对偶,上面结论是有约束
3.2.1 无约束推导过程:
求 解 : m i n W T W ∗ 1 2 s . t : 1 − y i ( W T x i + b ) < = 0 转 化 成 拉 格 朗 日 函 数 : 拉 格 朗 日 函 数 的 约 束 s . t : λ i > 0 , 表 达 式 L ( w , b , λ ) , 求 m a x ( L ( w , b , λ ) ) L ( w , b , λ ) = 1 2 W T W + ∑ i = 1 N λ i ( 1 − y i ( W T x i + b ) ) s . t : λ i > 0 因 为 拉 格 朗 日 求 m a x ( L ( w , b , λ ) ) , 同 时 拉 格 朗 日 中 的 1 − y i ( W T x i + b ) 不 再 限 制 范 围 , 则 可 以 假 设 假 设 1 : 1 − y i ( W T x i + b ) > 0 , 则 m a x ( L ( w , b , λ ) ) 趋 近 于 + ∞ 假 设 2 : 1 − y i ( W T x i + b ) < 0 , 则 m a x ( L ( w , b , λ ) ) 趋 近 于 1 2 W T W 所 以 : 最 终 结 合 S V M 和 拉 格 朗 日 公 式 表 达 式 = m i n ( m a x ( ( L ( w , b , λ ) ) ) , 这 个 m i n 是 来 自 于 距 离 公 式 S V M 模 型 等 价 于 m i n ( m a x ( ( L ( w , b , λ ) ) ) 再 根 据 拉 格 朗 日 公 式 的 取 值 范 围 ( + ∞ , 1 2 W T W ) 所 以 : m i n ( m a x ( ( L ( w , b , λ ) ) ) = m i n ( + ∞ , 1 2 W T W ) = m i n ( 1 2 W T W ) 最 终 求 解 的 是 无 约 束 的 函 数 : m i n ( 1 2 W T W ) 求解: \\ minW^TW*\frac{1}{2} \\ s.t : 1-y_i(W^Tx_i+b)<=0 \\ 转化成拉格朗日函数:拉格朗日函数的约束 s.t:λ_i>0 , 表达式L(w,b,λ),求max(L(w,b,λ)) \\ L(w,b,λ)=\frac{1}{2}W^TW+\sum_{i=1}^{N}λ_i(1-y_i(W^Tx_i+b)) \\ s.t:λ_i>0 \\ 因为拉格朗日求max(L(w,b,λ)),同时拉格朗日中的1-y_i(W^Tx_i+b)不再限制范围,则可以假设 \\ 假设1:1-y_i(W^Tx_i+b)>0,则max(L(w,b,λ))趋近于 +∞ \\ 假设2:1-y_i(W^Tx_i+b)<0,则max(L(w,b,λ))趋近于 \frac{1}{2}W^TW \\ 所以:最终结合SVM和拉格朗日公式表达式=min(max((L(w,b,λ))) , 这个min是来自于距离公式 \\ SVM模型等价于 min(max((L(w,b,λ))) \\ 再根据拉格朗日公式的取值范围(+∞,\frac{1}{2}W^TW) \\ 所以:min(max((L(w,b,λ)))=min(+∞,\frac{1}{2}W^TW)=min(\frac{1}{2}W^TW) \\ 最终求解的是无约束的函数:min(\frac{1}{2}W^TW) 求解:minWTW∗21s.t:1−yi(WTxi+b)<=0转化成拉格朗日函数:拉格朗日函数的约束s.t:λi>0,表达式L(w,b,λ),求max(L(w,b,λ))L(w,b,λ)=21WTW+i=1∑Nλi(1−yi(WTxi+b))s.t:λi>0因为拉格朗日求max(L(w,b,λ)),同时拉格朗日中的1−yi(WTxi+b)不再限制范围,则可以假设假设1:1−yi(WTxi+b)>0,则max(L(w,b,λ))趋近于+∞假设2:1−yi(WTxi+b)<0,则max(L(w,b,λ))趋近于21WTW所以:最终结合SVM和拉格朗日公式表达式=min(max((L(w,b,λ))),这个min是来自于距离公式SVM模型等价于min(max((L(w,b,λ)))再根据拉格朗日公式的取值范围(+∞,21WTW)所以:min(max((L(w,b,λ)))=min(+∞,21WTW)=min(21WTW)最终求解的是无约束的函数:min(21WTW)
3.3.2 对偶求解过程
第一步:对偶
因为对偶,所以符从下面转换
m
i
n
W
m
a
x
λ
L
(
W
,
λ
,
b
)
=
m
a
x
λ
m
i
n
W
L
(
W
,
λ
,
b
)
\frac{min}{W}\frac{max}{λ}L(W,λ,b) = \frac{max}{λ} \frac{min}{W}L(W,λ,b)
WminλmaxL(W,λ,b)=λmaxWminL(W,λ,b)
第二步:求导
L ( W , λ , b ) = 1 2 W T W + ∑ i = 1 N λ i ( 1 − y i ( W T x i + b ) ) 求 极 值 , 就 是 当 导 数 = 0 的 情 况 下 , 所 以 需 要 对 函 数 进 行 求 导 1. 对 W 求 导 , ∂ L ( W , λ , b ) ∂ W = W − ∑ i = 1 N λ i y i x i = 0 , 所 以 W = ∑ i = 1 N λ i y i x i 2. 对 b 求 导 , ∂ L ( W , λ , b ) ∂ b = − ∑ i = 1 N λ i y i = 0 , 所 以 ∑ i = 1 N λ i y i = 0 L(W,λ,b)=\frac{1}{2}W^TW+\sum_{i=1}^{N}\lambda_i(1-y_i(W^Tx_i+b)) \\ 求极值,就是当导数=0的情况下,所以需要对函数进行求导 \\ 1.对W求导,\frac{\partial L(W,λ,b)}{\partial W}=W-\sum_{i=1}^{N}\lambda_iy_ix_i=0,所以W=\sum_{i=1}^{N}\lambda_iy_ix_i \\ 2.对b求导,\frac{\partial L(W,λ,b)}{\partial b}=-\sum_{i=1}^{N}\lambda_iy_i=0,所以\sum_{i=1}^{N}\lambda_iy_i=0 L(W,λ,b)=21WTW+i=1∑Nλi(1−yi(WTxi+b))求极值,就是当导数=0的情况下,所以需要对函数进行求导1.对W求导,∂W∂L(W,λ,b)=W−i=1∑Nλiyixi=0,所以W=i=1∑Nλiyixi2.对b求导,∂b∂L(W,λ,b)=−i=1∑Nλiyi=0,所以i=1∑Nλiyi=0
第三步:把第二步的结果代入函数,使用特殊符号代替W,简化函数书写
从 第 二 步 结 果 中 , 使 用 Δ 代 替 W , 简 化 书 写 第 二 步 结 果 : 1. Δ = W = ∑ i = 1 N λ i y i x i , 2. ∑ i = 1 N λ i y i = 0 代 入 函 数 简 化 之 后 L = 1 2 Δ T Δ + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i ( Δ T x i + b ) = 1 2 Δ T Δ + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i Δ T x i − ∑ i = 1 N λ i y i b 因 为 ∑ i = 1 N λ i y i = 0 , 所 以 最 终 L = 1 2 Δ T Δ + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i Δ T x i 从第二步结果中,使用\Delta 代替W,简化书写 \\ 第二步结果:1.\Delta=W=\sum_{i=1}^{N}\lambda_iy_ix_i ,2. \sum_{i=1}^{N}\lambda_iy_i=0 \\ 代入函数简化之后L = \frac{1}{2}\Delta^T\Delta+\sum_{i=1}^{N}\lambda_i-\sum_{i=1}^{N}\lambda_iy_i(\Delta^Tx_i+b) \\ = \frac{1}{2}\Delta^T\Delta+\sum_{i=1}^{N}\lambda_i-\sum_{i=1}^{N}\lambda_iy_i\Delta^Tx_i-\sum_{i=1}^{N}\lambda_iy_ib \\ 因为 \sum_{i=1}^{N}\lambda_iy_i=0,所以最终 L=\frac{1}{2}\Delta^T\Delta+\sum_{i=1}^{N}\lambda_i-\sum_{i=1}^{N}\lambda_iy_i\Delta^Tx_i 从第二步结果中,使用Δ代替W,简化书写第二步结果:1.Δ=W=i=1∑Nλiyixi,2.i=1∑Nλiyi=0代入函数简化之后L=21ΔTΔ+i=1∑Nλi−i=1∑Nλiyi(ΔTxi+b)=21ΔTΔ+i=1∑Nλi−i=1∑NλiyiΔTxi−i=1∑Nλiyib因为i=1∑Nλiyi=0,所以最终L=21ΔTΔ+i=1∑Nλi−i=1∑NλiyiΔTxi
第四步:由于第三步简化之后,是需要条件的,所以最终结果是带约束的函数
m a x λ L ( λ ) = 1 2 Δ T Δ + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i Δ T x i s . t : λ i ≥ 0 , ∑ i = 1 N λ i y i = 0 \frac{max}{\lambda}L(\lambda) =\frac{1}{2}\Delta^T\Delta+\sum_{i=1}^{N}\lambda_i-\sum_{i=1}^{N}\lambda_iy_i\Delta^Tx_i \\ s.t: \lambda_i\geq0 , \sum_{i=1}^{N}\lambda_iy_i=0 λmaxL(λ)=21ΔTΔ+i=1∑Nλi−i=1∑NλiyiΔTxis.t:λi≥0,i=1∑Nλiyi=0
现在函数 L(λ) 就是关于 λ 的函数,可以通过拉格朗日 / 梯度下降的范式求解得到 λ 的值
然后通过 λ 的值再反推 W 的值,
第五步:通过KKT条件求解 b 的值
K K T 条 件 { ∂ L ( λ ) ∂ λ 1 − y i ( W T x i + b ) ≤ 0 λ i ≥ 0 λ i ( 1 − y i ( W T x i + b ) ) = 0 , 这 个 公 式 是 K K T 条 件 的 最 重 要 的 KKT条件\begin{cases} \frac{\partial L(\lambda)}{\partial \lambda} \\ 1-y_i(W^Tx_i+b)\leq0 \\ \lambda_i \geq0 \\ \lambda_i(1-y_i(W^Tx_i+b))=0 , 这个公式是KKT条件的最重要的 \end{cases} KKT条件⎩⎪⎪⎪⎨⎪⎪⎪⎧∂λ∂L(λ)1−yi(WTxi+b)≤0λi≥0λi(1−yi(WTxi+b))=0,这个公式是KKT条件的最重要的
通过KKT条件进行求解b:
因
为
:
λ
i
(
1
−
y
i
(
W
T
x
i
+
b
)
)
=
0
成
立
,
所
以
1.
当
λ
i
=
0
时
,
1
−
y
i
(
W
T
x
i
+
b
)
可
以
不
等
于
0
,
这
部
分
数
据
代
表
非
最
接
近
超
平
面
的
点
2.
当
λ
i
≠
0
时
,
1
−
y
i
(
W
T
x
i
+
b
)
=
0
,
这
部
分
数
据
代
表
距
离
超
平
面
最
近
的
点
,
看
下
图
解
释
因为: \lambda_i(1-y_i(W^Tx_i+b))=0 成立,所以 \\ 1.当 \lambda_i=0时,1-y_i(W^Tx_i+b) 可以不等于0 , 这部分数据代表非最接近超平面的点 \\ 2.当 \lambda_i\neq0时,1-y_i(W^Tx_i+b)=0,这部分数据代表距离超平面最近的点,看下图解释
因为:λi(1−yi(WTxi+b))=0成立,所以1.当λi=0时,1−yi(WTxi+b)可以不等于0,这部分数据代表非最接近超平面的点2.当λi=0时,1−yi(WTxi+b)=0,这部分数据代表距离超平面最近的点,看下图解释
解释一下哪些是离超平面最接近的点:
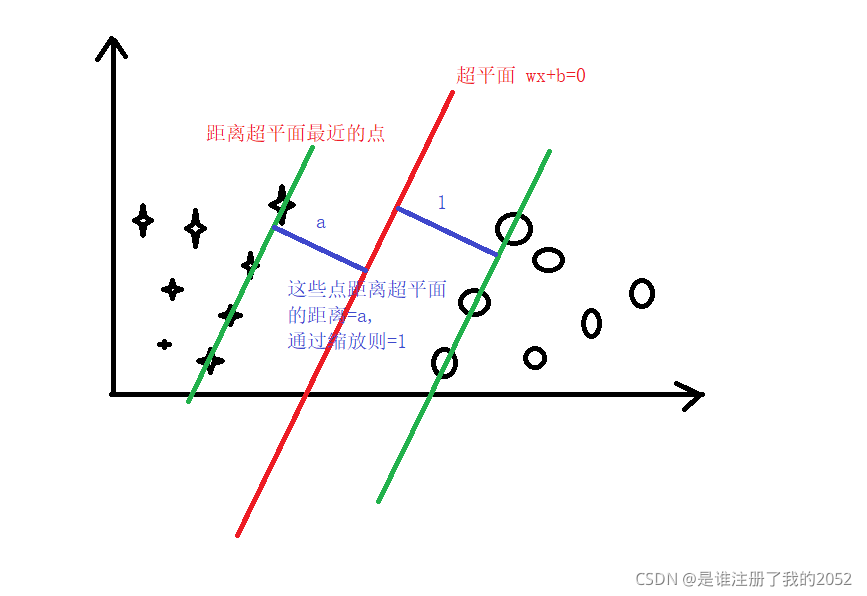
由于缩放的结果,可以使用离超平面最近的点的数据可以求得 b 的值:
1
−
y
i
(
W
T
x
i
+
b
)
=
0
,
把
离
超
平
面
最
近
的
点
(
x
i
,
y
i
)
代
入
公
式
,
即
可
得
到
b
的
解
1-y_i(W^Tx_i+b)=0 , 把离超平面最近的点(x_i,y_i)代入公式,即可得到 b 的解
1−yi(WTxi+b)=0,把离超平面最近的点(xi,yi)代入公式,即可得到b的解