【1】引言
前序学习了线性回归的基础知识,了解到最小二乘法可以做线性回归分析,但为何最小二乘法如此准确,这需要从概率论的角度给出依据。
因此从本文起,需要花一段时间来回顾概率论的基础知识。
【2】古典概型
古典概型是我们最熟悉的概率模型,简而言之就是有限个元素参与抽样,每个元素被抽样的概率相等。
古典概型有个点需要注意:
1.每个变量的概率相同,p{xi}=p{xj}=k;
2.放回抽样和不放回抽样的概率相等。
推导:
假设有m个红球,n个黄球,d个人抽取球,每人抽一个球,问第i(i=1,2,...k)个人抽到黄球的概率是多少,记抽样后放回的情况为A1,记抽样后不放回的情况为A2,则有:
(1)对于A1,因为抽样后放回,每次抽取又回到起始点,所以每个人抽取到黄球的概率都是:
(2)对于A2,因为抽样后不放回,每次抽取的基数不一致,所以:
第一个人抽样的时候,由(m+n)种情况;第二个人抽样的时候,由(m+n-1)种情况...第d个人抽样的时候,由(m+n-d+1)种情况,所有抽取到情况数应该是(m+n)(m+n-1)...(m+n-d+1),可以记作
当第i个人抽取到黄球,相当于在n个黄球中取到一个,有n种可能,此处记作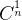
,所以,此时第i 个人抽取到情况数应该是:
由此可见,p(A1)=p(A2)。
实际上有另一种快速理解的办法:当第i 个人抽取到黄球,其他人就是在m+n-1个球当中抽d-1个球,这时候的总情况数就是,由于第i 个人抽取到黄球的也有n种情况,所以有p(A2)的计算式。
【3】总结
回顾了古典概型的知识。