论文:https://arxiv.org/pdf/1711.11585.pdf
代码:GitHub - NVIDIA/pix2pixHD: Synthesizing and manipulating 2048x1024 images with conditional GANs
pix2pixHD是pix2pix的重要升级,可以实现高分辨率图像生成和图片的语义编辑。对于一个生成对抗网络(GAN),学习的关键就是理解生成器、判别器和损失函数这三部分。pix2pixHD的生成器和判别器都是多尺度的,单一尺度的生成器和判别器的结构和pix2pix是一样的。损失函数由GAN loss、Feature matching loss和Content loss组成。
pix2pixHD的改进点有两个:1、高分辨率图像的生成。2、图片的语义编辑。
1.高分辨率图片的生成
为了生成高分辨率的图片,使用了:
- coarse-to-fine的生成器。
- multi-scale的判别器。这个比较简单,就是在三个不同尺度上判别,然后取平均。
- 更好的loss设计,总loss = GAN loss + Feature matching loss + Content loss。
- 使用Instance boundary map进行训练。
1.1 Coarse-to-fine generator

如上图,生成的流程:图片先经过一个生成器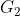
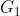
这么做的好处是,低分辨率的生成器会学习到全局的连续性(越粗糙的尺度感受野越大,越重视全局一致性),高分辨率的生成器会学习到局部的精细特征,因此生成的图片会兼顾局部特征和全局特征的真实性。如果仅使用高分辨率的图生成的话,精细的局部特征可能比较真实,但是全局的特征就不那么真实了。
1.2 Multi-scale discriminators
高分辨率图像合成对GAN鉴别器的设计提出了重大挑战。为了区分高分辨率的真实图像和合成图像,鉴别器需要有一个大的接收域。这将需要一个更深层次的网络或更大的卷积核,这两者都会增加网络容量,并可能导致过拟合。此外,这两种选择都需要更大的内存用于训练,这已经是高分辨率图像生成的稀缺资源。为了解决这个问题,我们提出使用多尺度鉴别器。我们使用3种具有相同网络结构但在不同图像尺度上运行的鉴别器。我们将把鉴别器称为D1、D2和D3。具体地说,我们对真实的和合成的高分辨率图像进行2倍和4倍的采样,以创建一个3个尺度的图像金字塔。然后训练鉴别器D1、D2和D3,分别在3个不同的尺度上区分真实图像和合成图像。
尽管鉴别器具有相同的结构,但在最粗糙的尺度上运行的鉴别器具有最大的接受域。它具有更全局的图像视图,可以引导生成器生成全局一致的图像。另一方面,在最佳尺度上的鉴别器鼓励生成器生成更精细的细节。这也使得从粗到细的生成器训练变得更容易,因为将低分辨率模型扩展到更高分辨率只需要在最好的级别上添加鉴别器,而不是从头开始重新训练。在没有多尺度鉴别器的情况下,我们发现生成的图像中经常出现许多重复的图案。
1.3 Improved adversarial loss
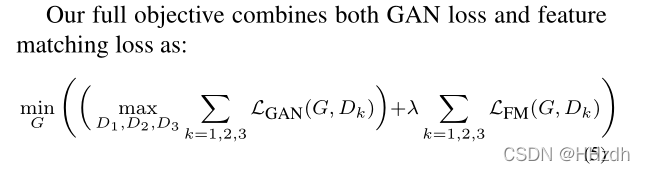
1.4 Using Instance Maps
现有的图像合成方法仅利用语义标签映射[5,21,25],每个像素值表示该像素的对象类。这张地图不能区分同一类别的物体。实例级语义标签映射包含每个单独对象的唯一对象ID。要合并实例映射,可以直接将其传递到网络中,或者将其编码为一个热向量。
然而,这两种方法在实践中都很难实现,因为不同的图像可能包含不同数量的同一类别的对象。或者,可以为每个类预先分配固定数量的通道(例如,10个),但当通道数量设置过小时,这种方法会失败,当通道数量过大时则会浪费内存。相反,我们认为实例映射提供的最关键的信息是对象边界,而这在语义标签映射中是不可用的。例如,当同一个类的对象彼此相邻时,单看语义标签映射并不能将它们区分开来。这在街景中尤其如此,因为很多停着的车或者步行的行人经常是挨着的,如图4a所示。但是,使用实例映射,分离这些对象就变得更容易了。
因此,为了提取该信息,我们首先计算实例边界图(图4b)。在我们的实现中,实例边界映射中的一个像素,如果它的对象ID不同于它的4个邻点,则为1,否则为0。然后,实例边界映射与语义标签映射的单热向量表示连接起来,并馈送到生成器网络中。类似地,鉴别器的输入是实例边界映射、语义标签映射和真实/合成图像的通道级联。图5b显示了使用对象边界进行改进的示例。我们在第4节中的用户研究还显示,使用实例边界地图训练的模型呈现出更逼真的对象边界。

1.5 Learning an Instance-level Feature Embedding
基于语义标签映射的图像合成是一个多个位映射问题。一个理想的图像合成算法应该能够使用相同的语义标签映射生成不同的、逼真的图像。最近,几个作品学习产生一个固定数量的离散输出给定相同的输入[5,15]或合成由控制的不同模式,一个潜在的编码,编码整个图像[66]。虽然这些方法解决了多模态图像合成问题,但它们不适合我们的图像处理任务,主要有两个原因。首先,用户无法直观地控制模型将生成哪种类型的图像[5,15]。其次,这些方法关注全局颜色和纹理变化,不允许对生成的内容进行对象级控制。
为了生成多样的图像并允许实例级控制,我们建议添加额外的低维特征通道作为生成器网络的输入。我们证明,通过操纵这些特征,我们可以灵活地控制图像合成过程。此外,请注意,由于特征通道是连续的数量,我们的模型,在原则上,能够生成无限多的图像。
为了生成低维特征,我们训练一个编码器网络,为图像中的每个实例找到一个低维特征向量,该向量对应于地面真实目标。我们的特色编码器体系结构是一个标准的编码器-解码器网络。为了确保每个实例中的特征是一致的,我们在编码器的输出中添加了一个实例化的平均池化层来计算对象实例的平均特征。然后将平均特性广播到实例的所有像素位置。图6显示了编码特性的一个示例。
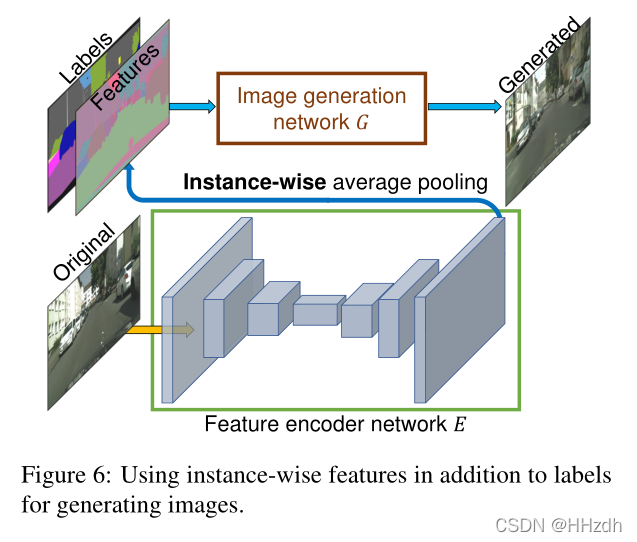
图片的语义编辑是一个新的有趣功能。从语义图到真实图的生成是一个一对多的映射,理想的模型应该可以根据同一个语义图生成真实且多样的图片。pix2pix的解决方法是在输入中增加一个低维特征通道。
- 首先和GAN网络一起训练一个编码器。
- 原始图片经过编码器,然后进行instance-wise average pooling操作,对每一个目标实例计算平均特征(Features),来保证每个目标实例特征的一致性。这个平均特征会被broadcast到该实例的每一个像素位置上。
- 输入图像比较多时,Features的每一类像素的值就代表了这类物体的先验分布。 使用编码器对所有训练图像提取特征,再进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的风格。
- 在推理阶段,从K个聚类中心选择某一个,和语义标签信息、实例信息结合作为输入,这样就能控制颜色/纹理风格。