@TOC(Redis相关)
Redis 底层数据结构
字符串底层存储
在Redis 中,字符串有三种存储编码方式: int编码 、embstr编码和raw编码
int编码
当value是一个整数且值大小不超过8个字节,就会是哟红int编码,ptr直接存储数值
embstr 编码
embstr对象用于存储比较短的字符串,embstr编码中RedisObject结构与ptr指向的SDS 结构在内存中是连续的,内存分配次数和内存释放次数均是一次。
raw编码会分别调用两次内存分配函数来分别创建RedisObject结构个SDS结构。
hash对象
Redis中,hash类型的value可以是一个hash表,底层编码可以是ziplist,也可以是hashtable。
默认情况下,当元素个数小于512个时,底层使用ziplist存储数据。
ziplist
元素保存的字符串长度较短且元素个数较少。(长度小于64字节,个数小于512),出于节约内存考虑,hash表会使用ziplist作为底层实现,ziplist是一块连续的内存,里面每一个节点保存了对应的key和value,然后每个节点很紧凑地存储在一起。
优点是: 没有冗余空间
缺点是: 插入新元素需要调用realloc扩展内存,这可能会导致内存重分配
hashtable
元素比较多是就会使用hashtable编码作为底层实现。此时RedisObject的ptr指针指向一个dict结构,dict结构中的ht数组有两个元素h[0]和h[1]。通常h[0]保存键值对,h[1]只在渐进式rehash时使用,hashtable是通过链地址法来解决冲突的。
Zset
Zset在存储时会将元素按照score从低到高排列,底层是通过跳表实现的。
ziplist
当元素较少时(元素长度小于64字节,且元素个数小于128),Zset的底层编码使用ziplist实现,所有元素按照score从低到高排序。
skiplist + dict
当元素较多时,使用skiplist + dict来实现。skiplist存储元素的值和score,并且将所有元素按照分值有序排列。便于以O(logN)的时间复杂度插入,删除,更新,及根据Score进行范围性查找。
dict存储元素的值和Score的映射关系,便于以O(1)的时间复杂度查找元素对应的分值。
跳表
跳表就是层次化的链表结构,它由多个链表组成。只有底层的链表保存节点数据,一般来说每两个节点选出一个节点作为下一级索引的节点,让下一级 索引的节点数量为本机索引节点数量的一半。依次类推直至最顶层索引节点数为1。
原理是每次查找数据时,先在最上层查找,然后再定位到下一层,层层定位,直至最终找到目标数据。这种方式不用遍历整个链表,而是跳跃着差,这样就使得查找时间复杂度退化到了logn
为什么不使用List、红黑树或平衡二叉树呢?
List是顺序㽾,访问速度很快,但是添加和删除操作是O(N)操作。至于红黑树和平衡二叉树,每次更新redis的值,都要消耗O(logn)的复杂度调整树结构,而跳跃表只需要调整局部链表结构就行,显然跳跃表更适合。
跳跃表支持平均O(logN)、最坏O(N)的复杂度进行节点查找,还可以通过顺序性操作来批量处理节点。
在大部分情况下,跳跃表的效率与平衡树媲美,但是跳跃表的实现要比平衡树要来得更为简单。
缓存
缓存穿透
查询一个不存在的数据,mysql查询不到数据也不会写入缓存中,导致每次查询都要访问数据库。
单key穿透
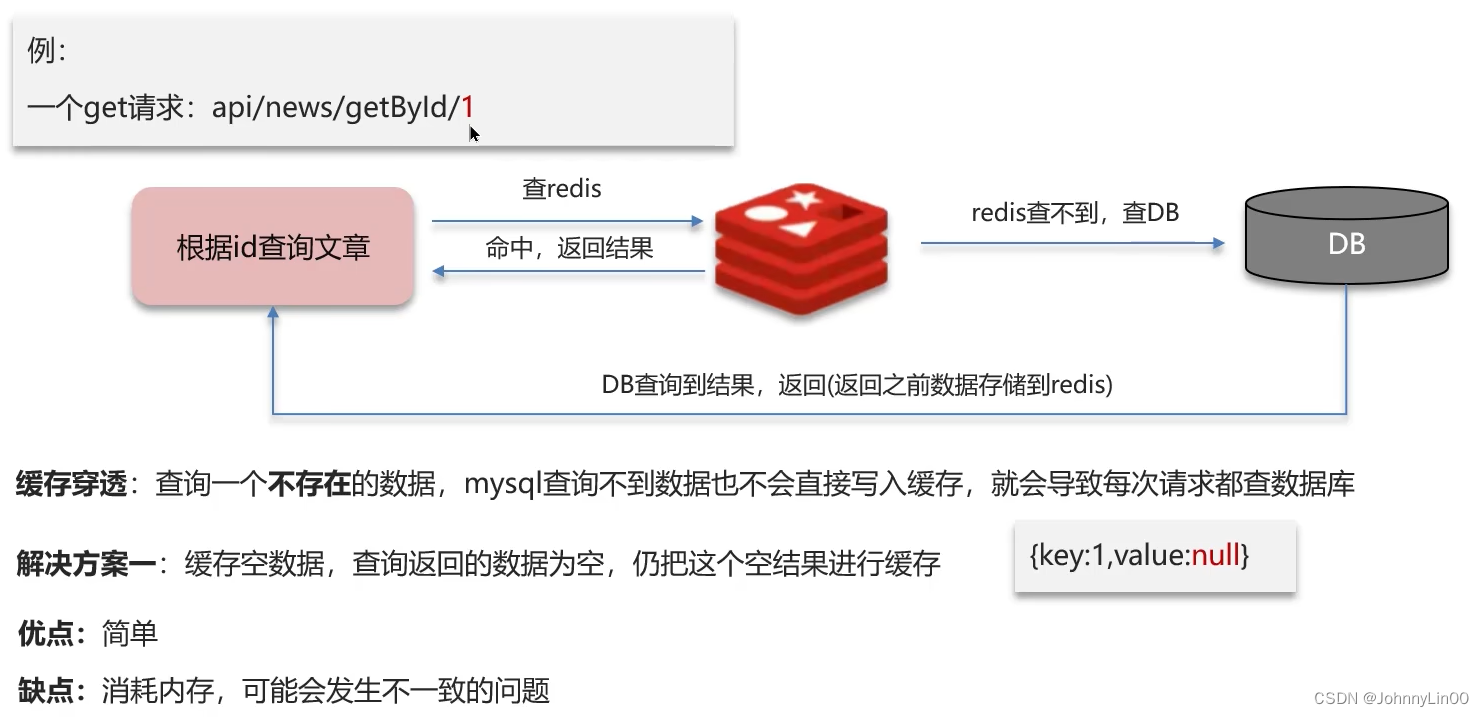
多key穿透

Redis持久化策略
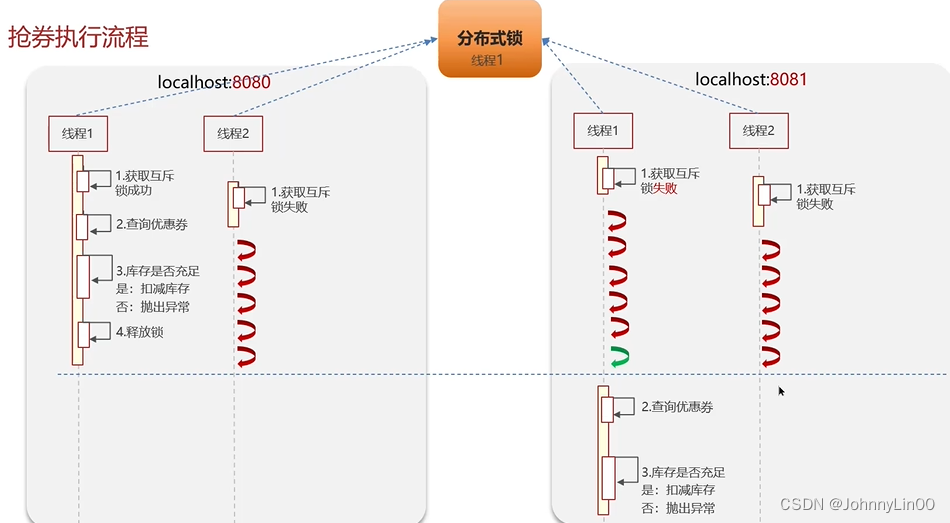
重复排队、并发超卖、数据不一致
分布式锁
使用分布式锁后的抢券流程
设计分布式锁的要点
- 互斥性。对同一个key进行操作。
- 防止误解锁。value值唯一,作为客户端的身份标识。
- 防止出现死锁。 过期时间,续锁。
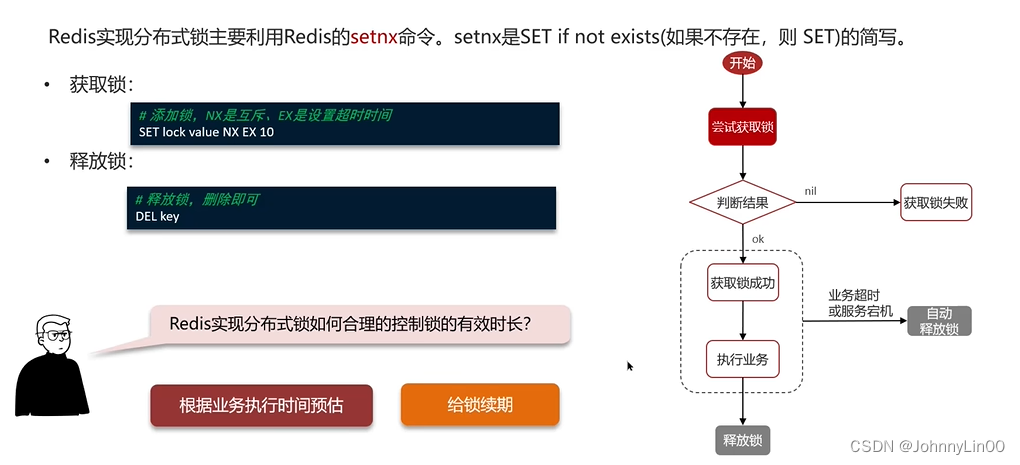
redis分布式锁
Redission实现的分布式锁

- watch dog,客户端没有设置过期时间时自动续期。
- 锁重试,while。
- 加锁,过期时间设置等操作都是基于Lua脚本。
Redission实现可重入锁

- 哈希结构中的VALUE记录线程id和可重入次数。
Redission实现的分布式锁——主从一致
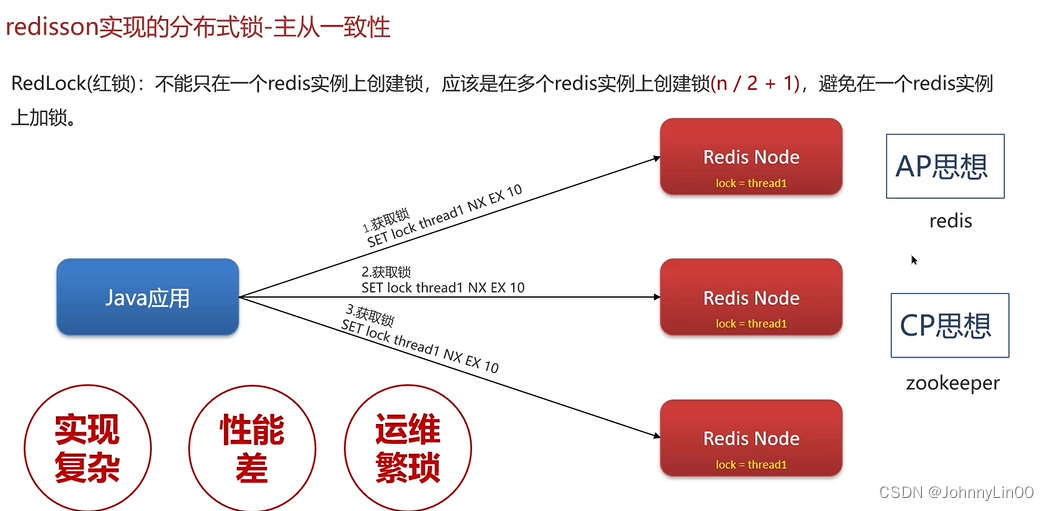
- 单机多线程下存在并发问题。 – 在JVM层面加锁,如synchronized或ReentrantLock
- 分布式部署下存在超卖问题。 --使用Redis分布式锁,加解锁。
String value = UUID.random().toString();
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value); //加锁
stringRedisTemplate.delte(REDIS_LOCK)
- 秒杀业务逻辑代码块出现异常时可能无法释放掉锁。 — 增加try -catch 语句块 在finally代码块释放锁
- 部署了秒杀服务的服务器宕机 – 对lockkey 增加过期时间的设定
5. 原子性考虑。 加锁和设置过期时间非原子操作
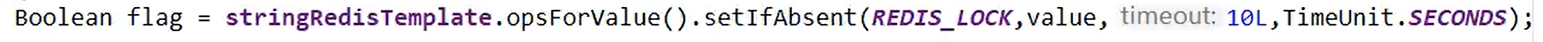
EX seconds – Set the specified expire time, in seconds.
PX milliseconds – Set the specified expire time, in milliseconds.
- 误删其他事务的锁。 必须在删除锁之前判断是否是自己的加的锁。
- 判断是否是自己加的锁 与 解锁非原子性操作,那么会出现判断加锁与解锁不是同一个客户端导致误解锁
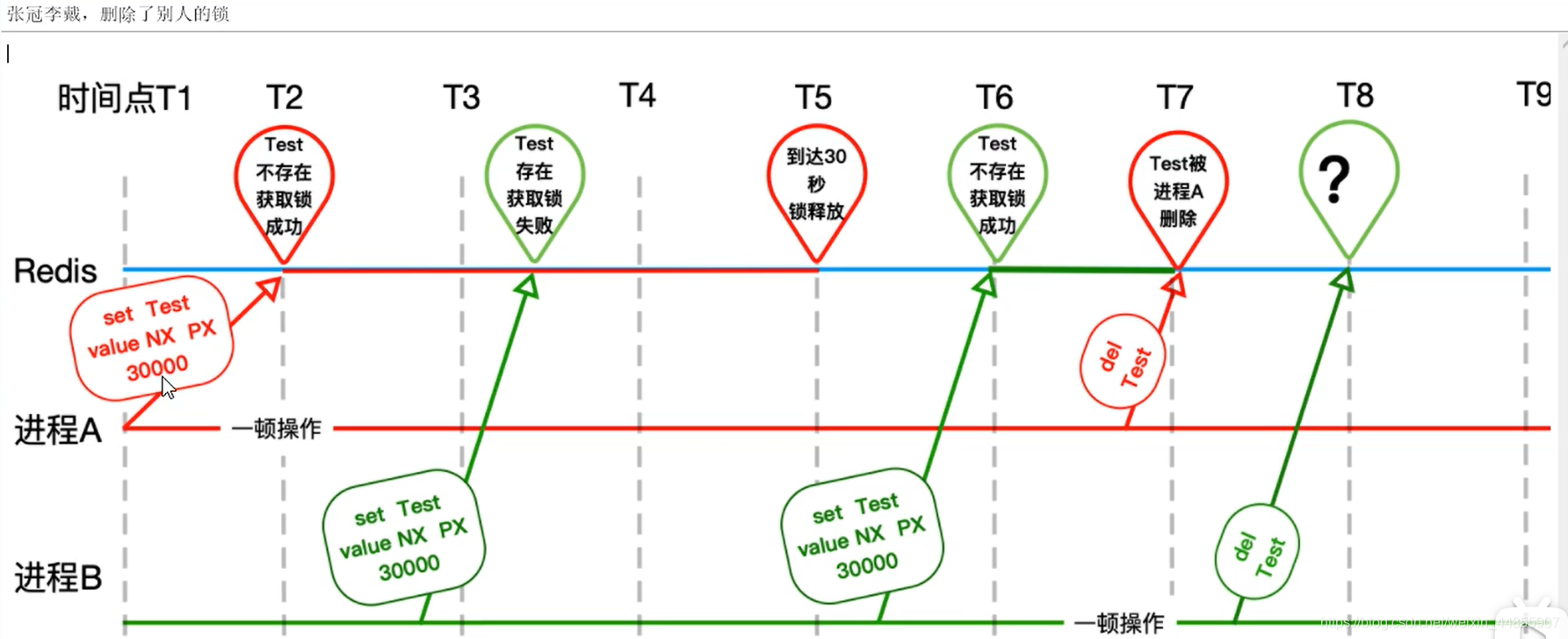


-
利用LUA脚本
-
使用Redis的事务
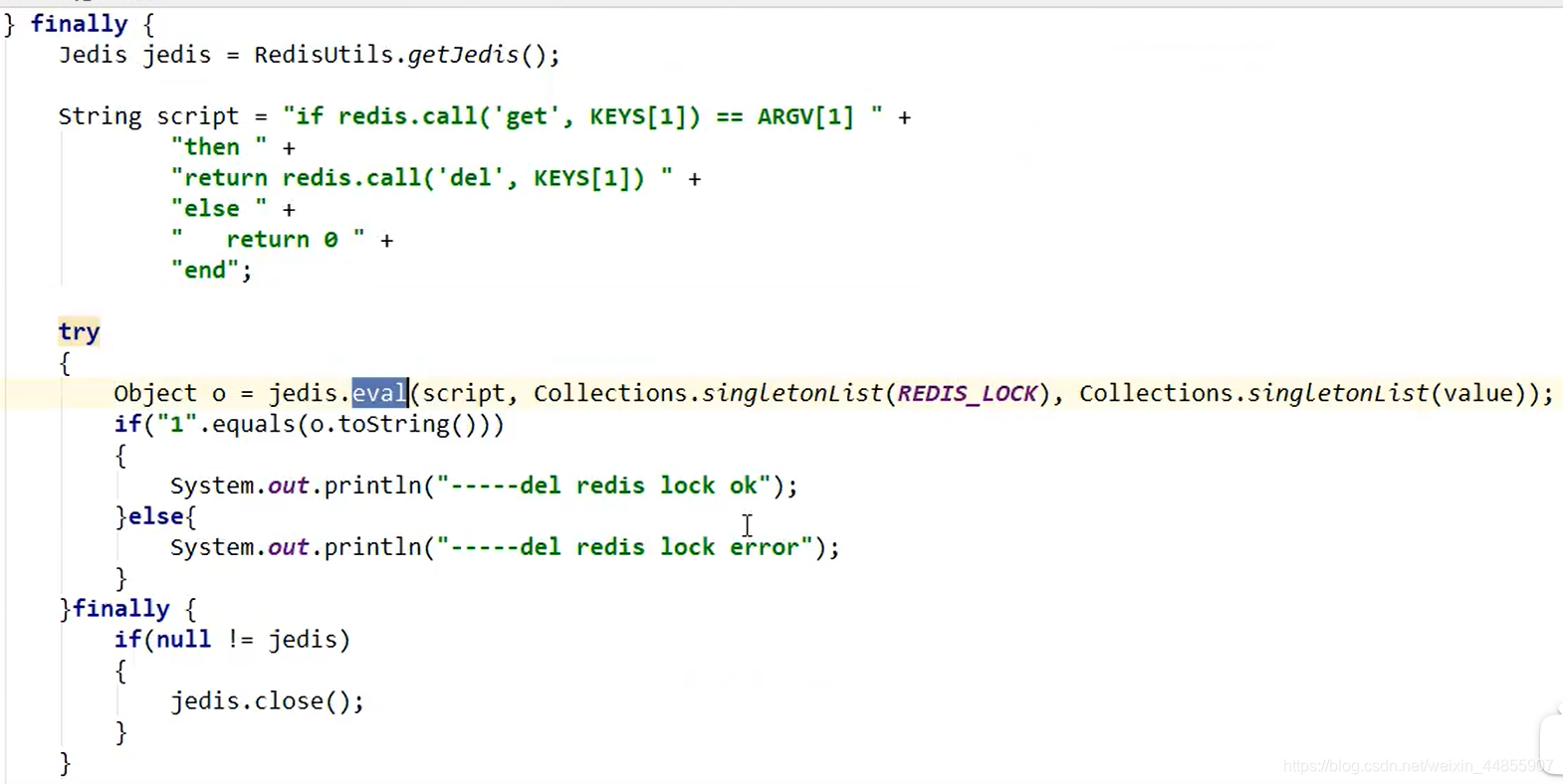
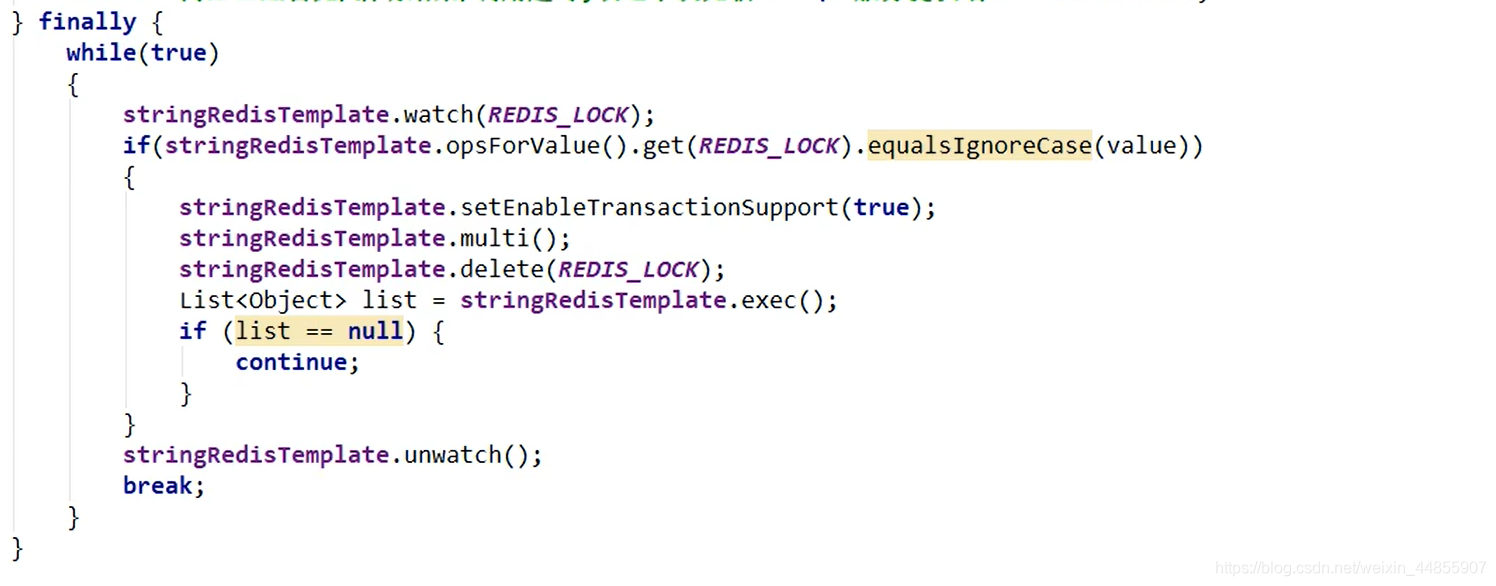
仍然存在 redisLock 过期时间小于业务执行时间的问题,也就是如何实现分布式锁的续期问题。
再者在集群环境下还存在Redis的主从不一致
Redison



- 在超高并发下,可能出现IllegalMonitorStateException


select … for update后,对所在行加了互斥锁,而你使用select …在Innodb里是快照读,是不涉及到锁的问题的,如果想要验证加锁是否成功,需要对查询加共享锁 lock in share mode或互斥锁for update
注意需要两个会话都开启事务:
select * from tmp_file_bk limit 0,10 for update;
之后会话2,使用
select * from tmp_file_bk where id = 106 lock in share mode ;
也无法访问到
Redis是单线程还是多线程
Redis在6.0之前使用的是单线程,对网络IO以及键值对的读写都是由一个线程完成的,但是持久化、集群数据同步都是由额外的线程完成的。
在6.0之后引入了多线程,但是其多线程限于网络请求和响应,对于键值对的读写仍然是单线程的,因此是线程安全的。
Redis单线程为什么还怎么快
- Redis作为缓存,是基于内存操作的。
- Redis命令执行是单线程的,没有上下文切换的开销。
- 基于IO多路复用机制提升了RedisIO的利用率。
- 高效的数据存储结构。
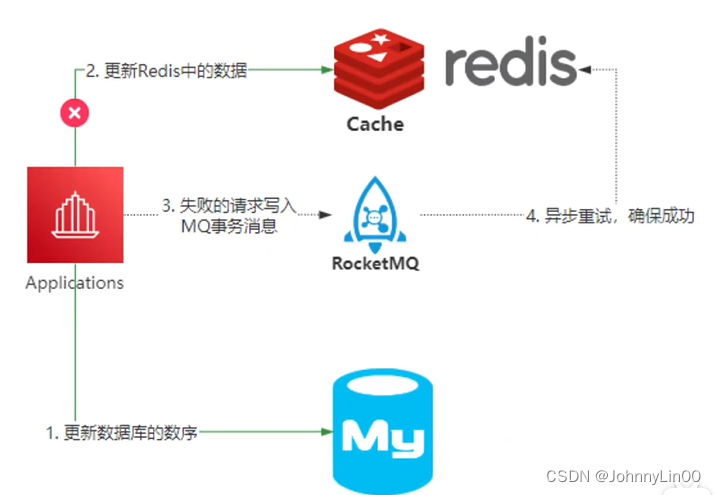
Redis和数据库的一致性如何保证
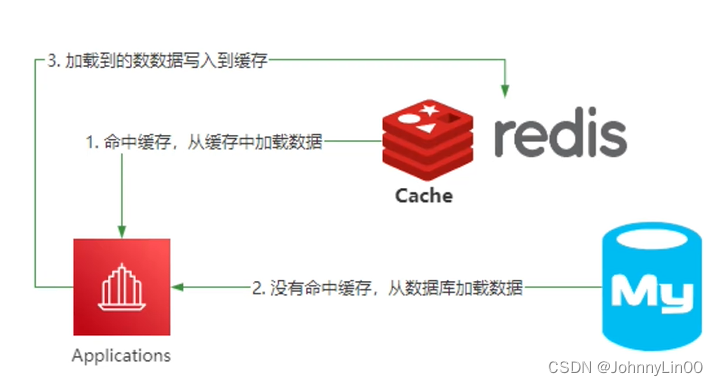
1、先更新数据库,再更新缓存。
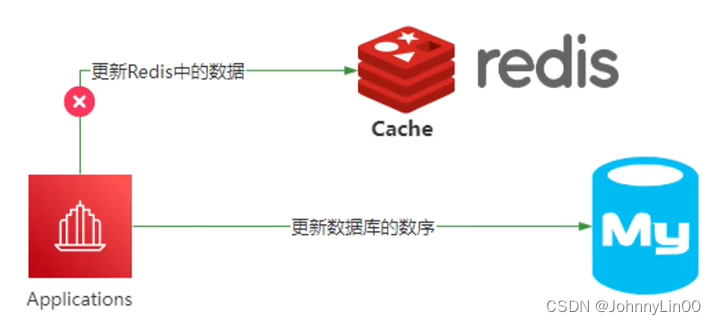
2、先删除缓存,在更新数据库。
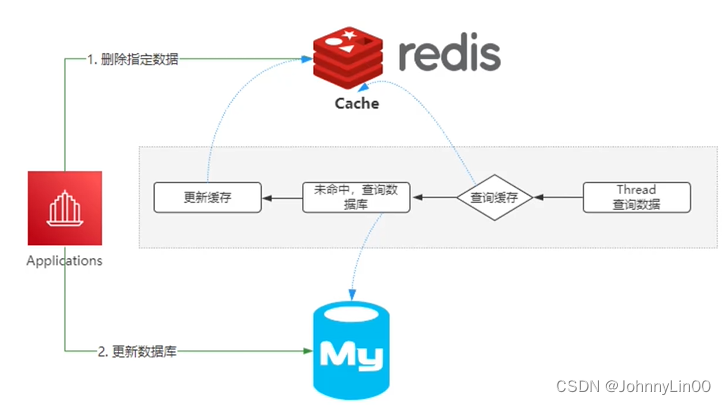
无法保证原子操作,只能采用最终一致性。
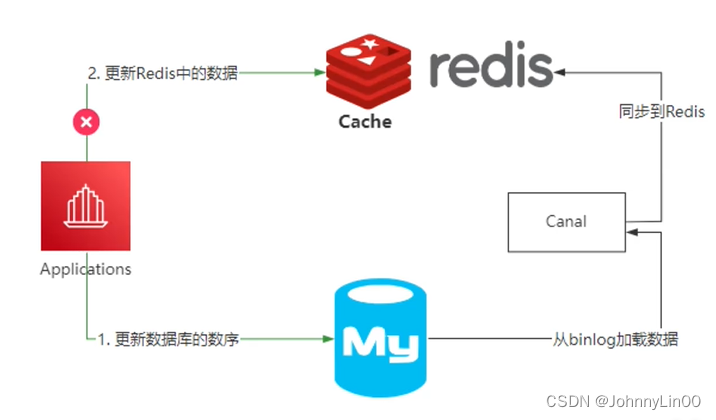
1、基于RocketMQ的可靠性消息通信来实现消息的最终一致性。
2、通过Canal组件监控MySQL数据库中binlog,将更新后的数据写同步到redis中。