本篇论文解决问题
(1)图像分辨率不清晰
(2)图像生成多个相同物体时会模糊
(3)实现人机交互
创新点:multiscale generators and discriminators
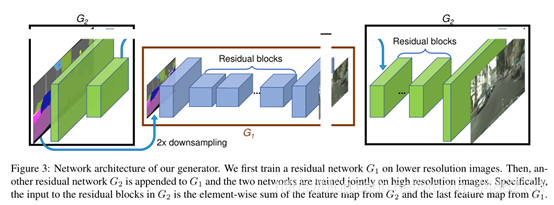
生成器由两部分组成,G1和G2,其中G2又被割裂成两个部分。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样。显然,越粗糙的尺度感受野越大,越关注全局一致性。
Coarse-to-fine generator
G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
Multi-scale discriminators
使用3个具有相同网络结构但在不同图像尺度下工作的鉴别器。把鉴别器称为D1, D2和D3。
具体来说,我们对真实的和合成的高分辨率图像进行2和4倍的采样,以创建一个3个尺度的图像金字塔。然后训练识别器D1、D2和D3分别在3个不同的尺度区分真实图像和合成图像。尽管鉴别器具有相同的体系结构,但在最粗尺度上操作的鉴别器具有最大的接受域。
它具有更全局的图像视图,可以指导生成器生成全局一致的图像。另一方面,在最细尺度上的鉴别器鼓励生成器产生更细的细节。这也使得训练从粗到细的生成器变得更容易,因为将低分辨率模型扩展到高分辨率模型只需要在最细级别添加discriminator,而不是从头开始重新训练。在没有多尺度鉴别器的情况下,我们观察到在生成的图像中经常出现许多重复的模式。
因为有了多个判别器所以起先的学习问题就变成了一个多任务学习问题:
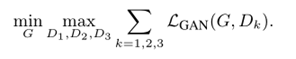
Improved adversarial loss
最初的损失函数
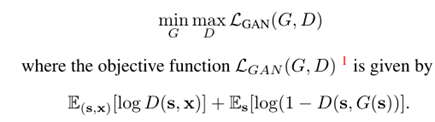
feature matching loss
将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss,其中T为层数,Ni为每层元素数。
我们的完整目标结合了GAN损失和特征匹配损失:
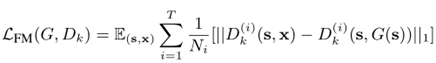
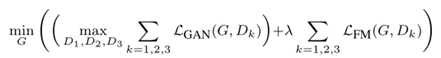
使用Instance-level的结果来进行训练解决问题2
根据个体分割的结果求出Boundary map
将Boundary map与输入的语义标签concatenate到一起作为输入
Boundary map求法很简单,直接遍历每一个像素,判断其4邻域像素所属语义类别信息,如果有不同,则置为1。
以上就是我这篇文章的笔记,如有错误,还希望大家能指出,先表示感谢。