Pytorch: 目标检测网络概述,指标计算和使用预训练网络
Copyright: Jingmin Wei, Pattern Recognition and Intelligent System, School of Artificial and Intelligence, Huazhong University of Science and Technology
本教程不商用,仅供学习和参考交流使用,如需转载,请联系本人。
Reference
RCNN(Regions with CNN Features)
SSD(Single Shot MultiBox Detector)
华中科技大学 AIA 学院-计算机视觉课件
《深度学习之 Pytorch 物体检测实战》
注:物体检测的教程使用的数据集主要为 ImageNet,COCO,PASCAL VOC 这三个常用的目标检测数据集,相关数据集下载和使用方式请自行查阅资料。
import numpy as np
import sys
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import os
import torchvision
import torch
import torchvision.transforms as transforms
物体检测技术
在计算机视觉众多的技术领域中,物体检测是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于物体检测。此外,由于每张图像中物体的数量、大小及姿态各不相同,也就是非结构化的输出,这是与图像分类非常不同的一点, 并且物体时常会有遮挡截断,物体检测技术也极富挑战性,从诞生以来始终是研究学者最为关注的焦点领域之一。
物体检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类别。 对于图中的人,我们要求检测器输出 5 5 5 个量:物体类别, x min , y min , x max , x max x_{\min}, y_{\min},x_{\max},x_{\max} xmin,ymin,xmax,xmax 当然,对于一个边框,检测器也可以输出中心点与宽高的形式,这两者是等价的。
在计算机视觉中,图像分类、物体检测与图像分割是最基础、也是目前发展最为迅速的 3 3 3 个领域。
图像分类:输入图像往往仅包含一个物体,目的是判断每张图像是什么物体,是图像级别的任务,相对简单,发展也最快。
物体检测:输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的-一个任务。
图像分割:输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。
传统方式
在利用深度学习做物体检测之前传统算法对于物体的检测通常分为区域选取、特征提取与特征分类这 3 3 3 个阶段。
区 域 选 取 → 特 征 提 取 → 特 征 分 类 区域选取\rightarrow 特征提取\rightarrow 特征分类 区域选取→特征提取→特征分类
- 区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。
- 特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如 SIFT 和 HOG 等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。
- 特征分类:最后,对上一步得到的特征进行分类,通常使用如SVM, AdaBoost的分类器。
目标检测网络
深度学习时代的物体检测发展过程如图所示。深度神经网络大量的参数可以提
取出鲁棒性和语义性更好的特征,并且分类器性能也更优越。 2014 2014 2014 年的 RCNN(Regions with CNN features) 算是使用深度学习实现物体检测的经典之作,从此拉开了深度学习做物体检测的序幕。

R-CNN
参考文章:Rich feature hierarchies for accurate object detection and semantic segmentation
其主要算法分为 4 4 4 个阶段:
-
候选区域生成:每张图像会采用 Selective Search 方法,生成 1000 − 2000 1000-2000 1000−2000 个候选区域。
-
特征提取:针对每个生成的候选区域,归一化为统一尺寸,使用深度卷积网络提取候选区域的特征。
-
类别判断:将 CNN 特征送入每一类 SVM 分类器,判别候选区域是否属于该类。
-
位置精修:使用回归器惊喜修正候选框位置。
在 RCNN 基础上, 2015 2015 2015 年的 Fast RCNN 实现了端到端的检测与卷积共享。
Fast R-CNN
参考文章:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Fast R-CNN 是两阶段方法的奠基性工作,提出的 RPN 网络取代 Selecctive Search 算法使得检测任务可以由神经网络端到端地完成。
其具体操作方法是将 RPN 放在最后一个卷积层之后,RPN直接训练得到候选区域。RPN 网络的特点在于通过滑动窗口的方式实现候选框的提取,在特征映射上滑动窗口,每个滑动窗口位置生成 9 9 9 个不同尺度、不同宽高的候选窗口,提取对应 9 9 9 个候选窗口的特征,用于目标分类和边框回归。
目标分类只需要区分候选框内特征为前景或者北京,与 Fast R-CNN 类似,边框回归确定更精确的目标位置。
之后,Faster RCNN 提出锚框(Anchor)这一划时代的思想, 将物体检测推向了第一个高峰。在 2016 2016 2016 年,YOLO v1 实现了无锚框(Anchor-Free)的一阶检测,SSD 实现了多特征图的一阶检测,这两种算法对随后的物体检测也产生了深远的影响,在后续教程中将分别用一章的篇幅详细介绍。
YOLO
参考文章:You Only Look Once: Unified, Real-Time Object Detection
YOLO(You Only Look Once) 是经典的单目标检测算法,将目标区域预测和目标类别预测整合于单个神经网络模型中,实现在准确率较高的情况下快速检测与识别目标。YOLO的主要优点是检测速度快、全局处理使得背景错误相对较少、泛化性能好。但是YOLO由于其设计思想的局限,所以会在小目标检测时有些困难。
算法流程如下:
首先将图像划分为 S × S S\times S S×S 个网格,然后在每个网格上通过深度卷积网络给出其物体所述的类别判断(图像使用不同的颜色表示),并在网格基础上生成 B 个边框(box),每个边框预测 5 5 5 个回归值,其中前 4 4 4 个值表示边框位置,第五个值表征这个边框含有物体的概率和位置的准确程度。最后经过 NMS 非极大值抑制过滤得到最后的预测框。
在 2017 2017 2017 年,FPN 利用特征金字塔实现了更优秀的特征提取网络,Mask RCNN 则在实现了实例分割的同时,也提升了物体检测的性能。进入 2018 2018 2018 年后,物体检测的算法更为多样,如使用角点做检测的 CornerNet ,使用多个感受野分支的 TidentNet ,使用中心点做检测的 CenterNet 等。
在物体检测算法中,物体边框从无到有,边框变化的过程在一定程度上体现了检测是一阶的还是两阶的。
- 两阶:两阶的算法通常在第一阶段专注于找出物体出现的位置,得到建议框,保证足够的准召率(Recall),然后在第二个阶段专注于对建议框进行分类,导找更精确的位置)典型算法如 RCNN, Faster RCNN 。两阶的算法通常精度准更高,但速度较慢。当然,还存在例如 Cascade RCNN 这样更多阶的算法。
- 一阶:一阶的算法将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置与类别的预测,方法通常更为简单,依赖于特征融合、(Focal Loss 等优秀的网络经验,速度一般比两阶网络更快,但精度会有所损失,典型算法如 SSD, YOLO, RetinaNet 等。
Anchor 是一个划时代的思想,最早出现在 Faster RCNN 中,其本质上是一系列大小宽高不等的先验框,均匀地分布在特征图上,利用特征去预测这些 Anchors 的类别,以及与真实物体边框存在的偏移。Anchor 相当于给物体检测提供了一个梯子,使得检测器不至于直接从无到有地预测物体,精度往往较高,常见算法有 Faster RCNN, SSD, YOLO v2 等。
当然,还有一部分无锚框的算法,思路更为多样,有直接通过特征预测边框位置的方法,如 YOLO v1 等。最近也出现了众多依靠关键点来检测物体的算法,如 CornerNet, CenterNet 等。
技术应用领域
由于检测性能的迅速提升,物体检测也是深度学习在工业界取得大规模应用的领域之以下列举了 5 5 5 个广泛应用的领域。
- 安防:受深度学习的影响,安防领域近年来取得了快速的发展与落地。例如广为人知的人脸识别技术,在交通卡口、车站等已有了成熟的应用。此外,在智慧城市的安防中,行人与车辆的检测也是尤为重要的一环。 在安防领域中,有很大的趋势是将检测技术融入到摄像头中,形成智能摄像头,以海康威视、地平线等多家公司最为知名。
- 自动驾驶:自动驾驶的感知任务中,行人、车辆等障碍物的检测尤为重要。由于涉及驾驶的安全性,自动驾驶对于检测器的性能要求极高,尤其是召回率这个指标,自动驾驶也堪称人工智能应用的"珠穆朗玛峰"。此外,由于车辆需要获取障碍物相对于其自身的三维位置,因此通常在检测器后还需要增加很多的后处理感知模块。
- 机器人:工业机器人自动分拣中,系统需要识别出要分拣的各种部件,这是极为典型的机器人应用领域。此外,移动智能机器人需要时刻检测出环境中的各种障碍物,以实现安全的避障与导航。从广泛意义来看,自动驾驶车辆也可以看做是机器人的一种形式。
- 搜索推荐:在互联网公司的各大应用平台中,物体检测无处不在。例如,对于包含特定物体的图像过滤、筛选、推荐和水印处理等,在人脸、行人检测的基础上增加更加丰富的应用,如抖音等产品。
- 医疗诊断:基于人工智能与大数据,医疗诊断也迎来了新的春天,利用物体检测技术,我们可以更准确、迅速地对 CT, MR 等医疗图像中特定的关节和病症进行诊断。
评价指标
对于一个检测器,我们需要制定一 定的规则来评价其好坏,从而选择需要的检测器。对于图像分类任务来讲,由于其输出是很简单的图像类别,因此很容易通过判断分类正确的图像数量来进行衡量。
Intersection of Union(IoU)
物体检测模型的输出是非结构化的, 事先并无法得知输出物体的数量、位置、大小等,因此物体检测的评价算法就稍微复杂一些。 对于具体的某个物体来讲,我们可以从预测框与真实框的贴合程度来判断检测的质量,通常使用 IoU(Intersection of Union) 来量化贴合程度。
IoU 的计算方式如图所示,使用两个边框的的交集集与并集的比值,就可以得到 IoU, 公式如下所示。显而易见,loU 的取值区间是 [ 0 , 1 ] [0,1] [0,1] , IoU 值越大,表明两个框重合越好。
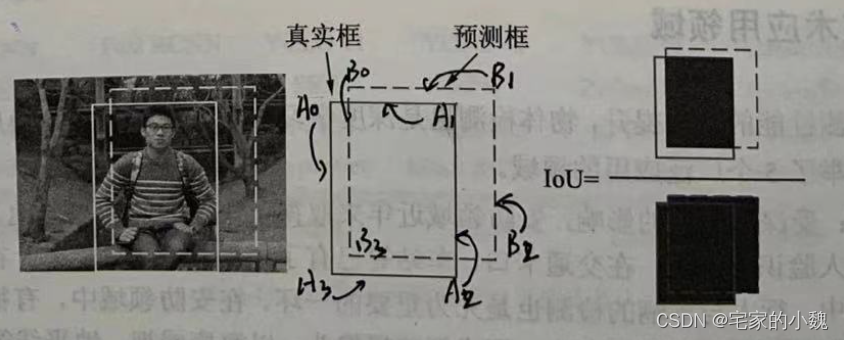
I o U A , B = S A ∩ S B S A ∪ S B IoU_{A,B}=\frac{S_A\cap S_B}{S_A\cup S_B} IoUA,B=SA∪SBSA∩S