最近做uni-app项目,遇到中文排序,使用indexedList组件布局渲染。自己也是查询了很多资料,https://www.cnblogs.com/wteng/p/5658972.html展现了一种方法。但是自己测试怎么也不对,不知道是不是环境问题或者是自己代码写错了。代码如下所示
interface Curr {
letter: string,
data: string[]
}
function pySegSort(arr: string[]): any[] {
let letters: string[] = "*abcdefghjklmnopqrstwxyz".split('');
let zh: string[] = "阿八嚓哒妸发旮哈讥咔垃痳拏噢妑七呥扨它穵夕丫砸".split('');
let segs: any[] = []
letters.forEach((code, i) => {
let curr: Curr = { letter: code, data: [] }
arr.forEach(word => {
if (!zh[i - 1] || word.localeCompare(zh[i - 1], "zh-CN") >= 0 && word.localeCompare(zh[i], "zh-CN") == -1) {
curr.data.push(word);
}
})
if (curr.data.length) {
curr.data.sort((a, b) => a.localeCompare(b, "zh-CN"));
segs.push(curr);
}
})
return segs
}
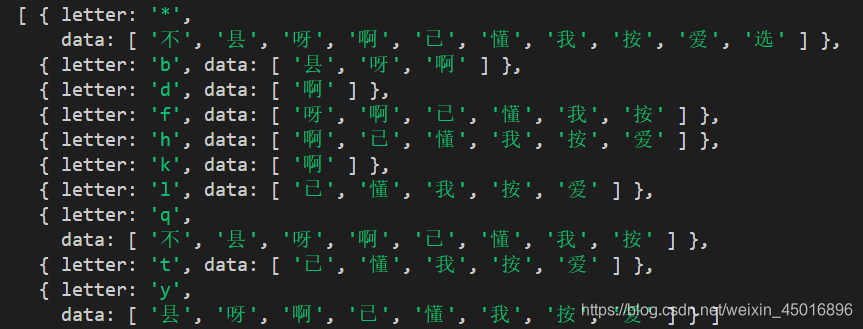
console.log(pySegSort(["我", "不", "懂", "爱", "啊", "按", "已", "呀", "选", "县"]));
后来我就想着把汉字转成拼音,再根据拼音进行排序。汉字转拼音可以根据此链接https://www.cnblogs.com/kinnjee/p/4160060.html自行转换。汉字转换为拼音之后则需要将其按字母分类,代码如下:
import PY from '../../static/js/PY.js' // 根据上面链接编写得js文件
// arr就是名字数组
pySegSort(arr) {
let letters ="*ABCDEFGHJKLMNOPQRSTWXYZ".split('');
let segs = {};
let indexedList = []
// 创建一个以26个为key的对象
letters.forEach(item => {
segs[item] = [];
})
arr.forEach(item => {
// 取姓氏并返回姓氏的拼音首字母
let a = PY.ConvertPinyin(item).substr(0,1)
// 在A-z之中写入对应字母的对象数组中,否则传入*对象数组里
/[A-z]/.test(a) ? segs[a.toLocaleUpperCase()].push(item) :segs['*'].push(item)
})
// 循环segs对象,转换为indexList组件需要的格式
for (const [key, value] of Object.entries(segs)) {
value.length && indexedList.push({letter: key, data: value})
}
indexedList.forEach(item => {
if(item.data.length > 1) {
// 这里是给相同拼音首字母进行排序
item.data = item.data.sort((a,b) => {return a.localeCompare(b)})
}
})
return indexedList;
},