写在前面
上一篇文章中,我们深度解析了redis中的跳表结构,而b+树的结构我们很久之前就讲过了,那么我们知道了redis的有序集合用的是跳表,而mysql的innodb引擎用的是b+树存储,但这是为什么呢?为什么redis用跳表不用b+树,而mysql用b+树而不是跳表?这篇文章我们就来讲一下。
1. B+树和跳表结构对比
我们分别对这两个结构进行读、写操作两个场景来做分析。
1.1 B+树结构
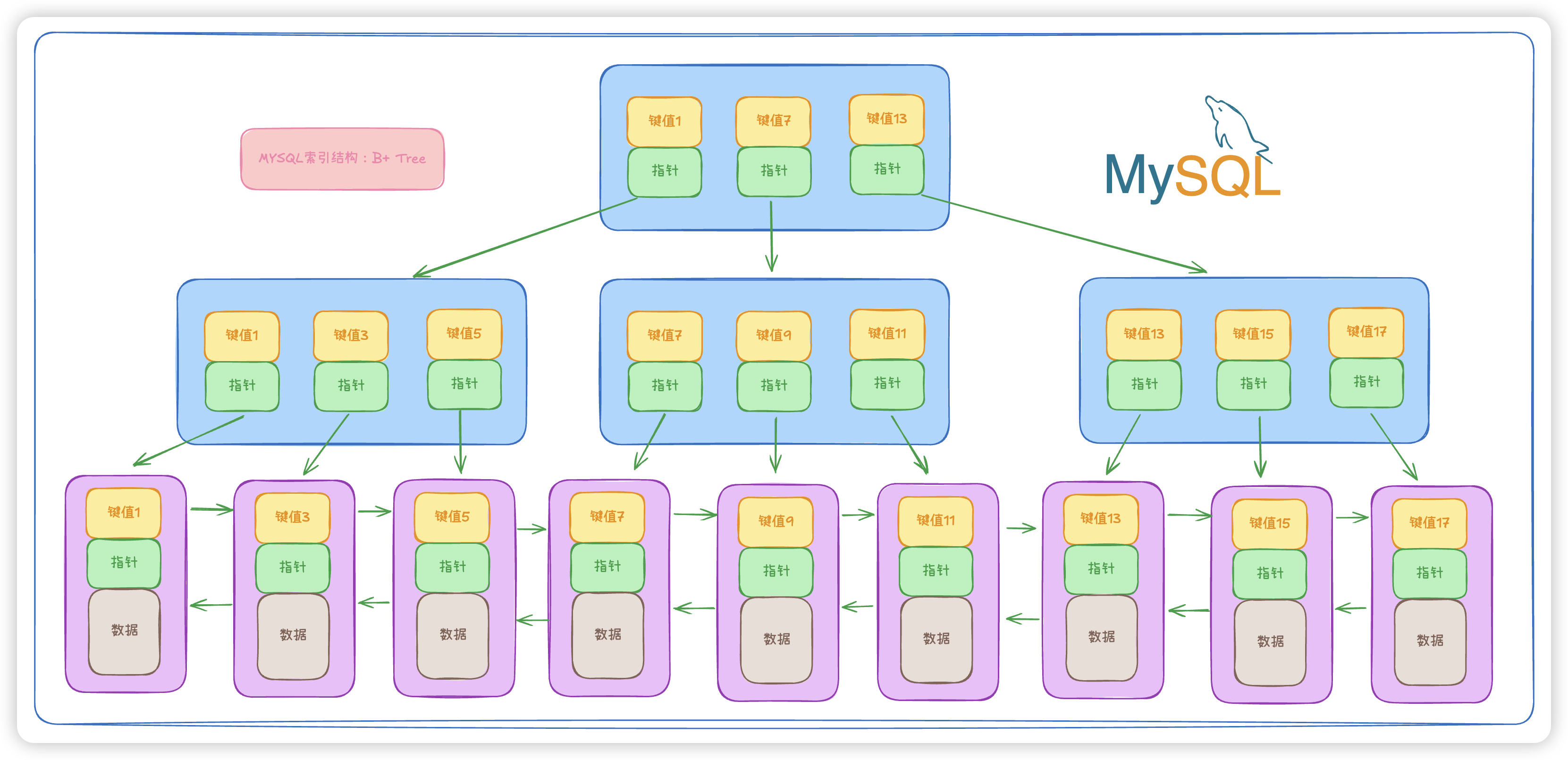
- 读操作:我们知道 B+树 的结构中每个结点都是一个16k的数据页,能存放较多的索引信息,三层左右就可以存储3kw左右的数据。查询一次数据,最多三次磁盘IO。
- 写操作:随着数据的增加,B+树为了保持自身平衡而需要调整自身的树高,这背后有相对复杂逻辑来做平衡调整。
所以B+树这类数据结构适合大量数据(相比于redis),而大量的数据肯定不能全放内存里,必定是需要存放在磁盘,而磁盘的读写又很慢,B+数的灵魂在于索引,索引作用是为了加速磁盘io。
但是redis又是一个内存数据库,索引在内存中的作用不大了,相反B+数复杂的平衡逻辑会使得插入变慢,redis这类追求高速的单进程数据库是不建议有这类慢操作的。
1.2 跳表结构
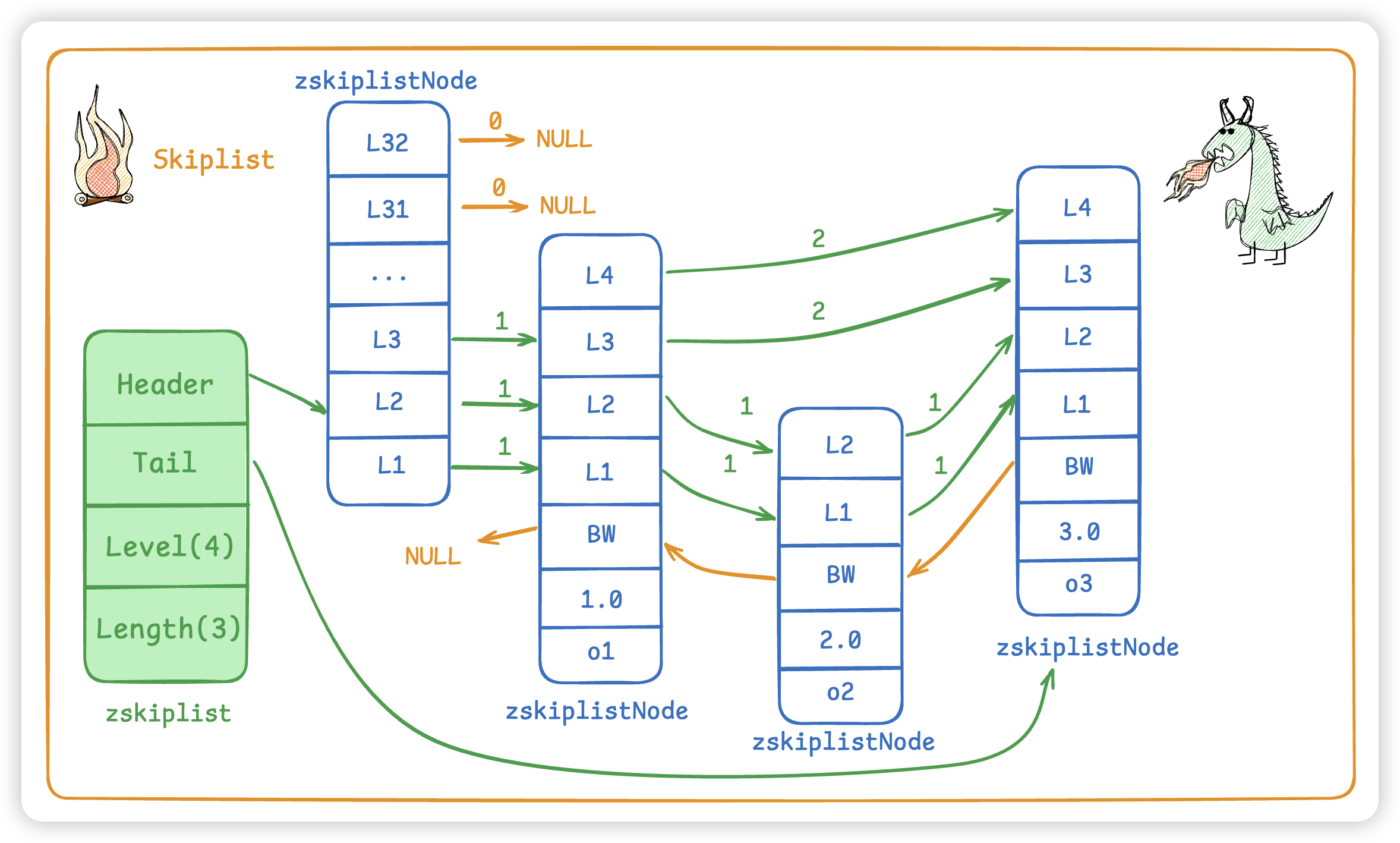
- 读操作:一个结点存放一条数据,如果像上面的mysql一样存储3kw左右的数据,
即使每次都能达到最优的二分,也要找2的25次方左右。当然redis也不会有哪个key会存储3kw的数据,这就算大key了,是不允许的。而且与磁盘io不同,内存是很快的。 - 写操作:与拆分合并数据页不同,一个节点直接插入一条数据。逻辑相对来说比较简单,也很快速,没有平衡的复杂过程。
2. 总结
Redis 使用跳表的原因:
- 内存数据库,查询、插入、删除的效率高,且实现简单,
适合高并发、低延迟的内存操作。 - 内存管理灵活,不需要像 B+树那样
复杂的节点分裂和合并操作,这些操作也比较耗时。并且B+的最大的索引优势在内存中作用不大。
MySQL 使用 B+树的原因:
- 适合磁盘存储和大规模数据,能够高效进行范围查询和排序,支持复杂的事务管理。
- 适合持久化存储,
在数据量很大的情况下,通过索引结构能够优化磁盘 I/O,B+树能够保持查询性能。。
参考
[1] https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf
[2] https://opensource.googleblog.com/2013/01/c-containers-that-save-memory-and-time.html