CrowdHuman数据集转成VOC格式并训练模型
1. 介绍
The CrowdHuman dataset is large, rich-annotated and contains high diversity. CrowdHuman contains 15000, 4370 and 5000 images for training, validation, and testing, respectively. There are a total of 470K human instances from train and validation subsets and 23 persons per image, with various kinds of occlusions in the dataset. Each human instance is annotated with a head bounding-box, human visible-region bounding-box and human full-body bounding-box.
上面这一段是来自于官网的介绍。
简单说来,Crowdhuman整个数据集分成了三部分,其中训练集有15000张图片,验证集有4370张图片,测试集有5000张图片,有超过47万张人脸。
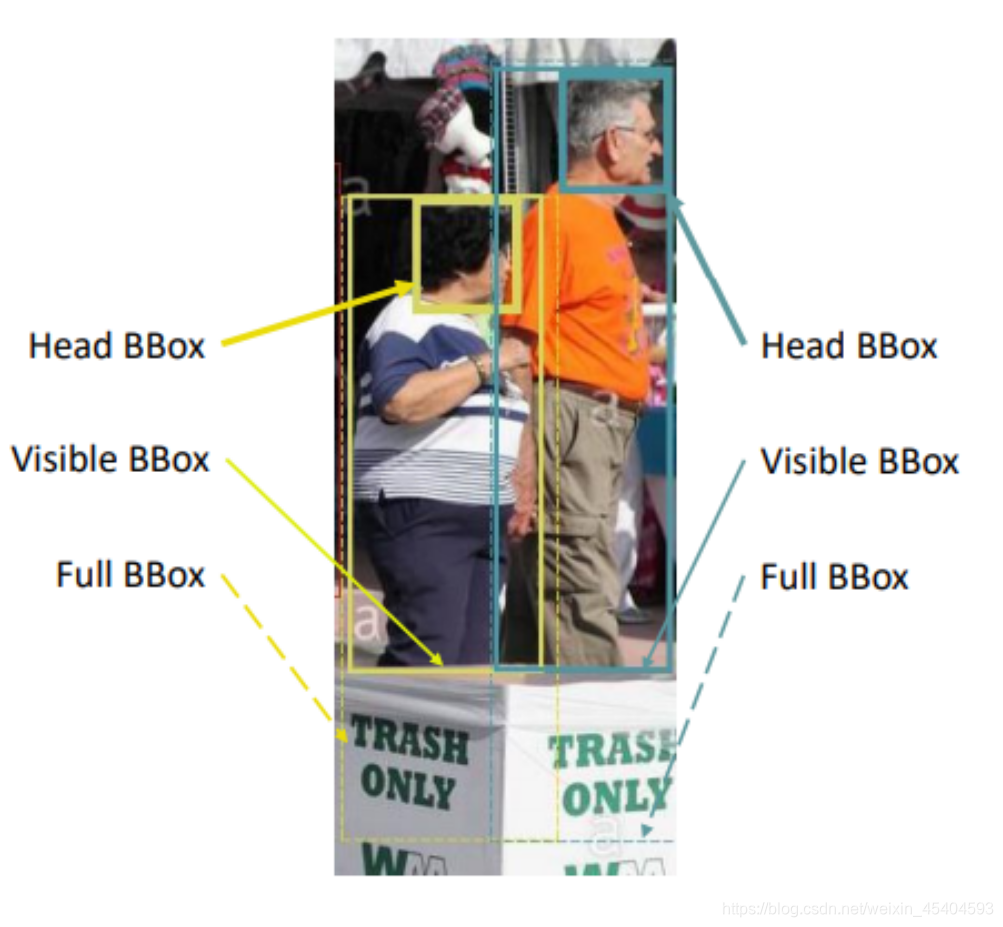
如上图所示,对于每张图片的标注来说,一共有三种情况:head bounding-box标注了人脸的区域;human visible-region标注了图片中可视的人体区域;full-body bounding-box标注了整个人体区域。
2. 数据集下载
下面是数据集的下载链接,百度云和Google Drive都可以进行下载。
注意也要下载相应的标注文件,也就是后缀为odgt的文件,下载界面中有对odjt文件的相应介绍。
http://www.crowdhuman.org/download.html
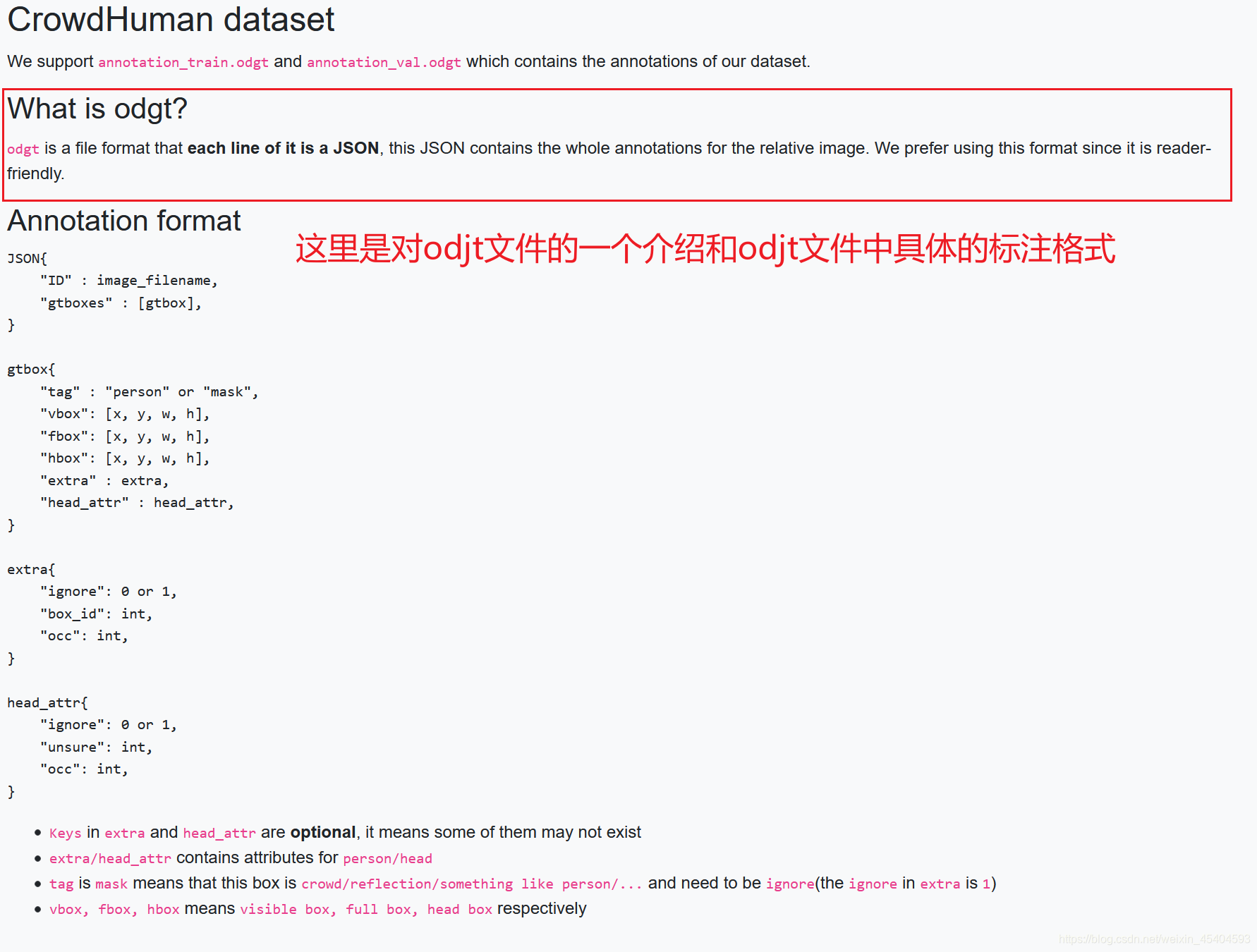
3. odjt文件的解析
odjt数据中保存的是json格式的数据,我用的darknet训练使用的是voc格式的数据,需要对原始的文件进行解析,具体解析的代码如下:
``
from xml.dom import minidom
import cv2
import os
import json
from PIL import Image
roadlabels = "E:\StudyCV\objc2voc/Annotations/"
roadimages = "E:\StudyCV\objc2voc/Images/"
fpath = "E:\StudyCV\objc2voc/annotation_train.odgt"
def load_func(fpath):
assert os.path.exists(fpath)
with open(fpath, 'r') as fid:
lines = fid.readlines()
records = [json.loads(line.strip('\n')) for line in lines]
return records
bbox = load_func(fpath)
if not os.path.exists(roadlabels):
os.makedirs(roadlabels)
for i0, item0 in enumerate(bbox):
print(i0)
# 建立i0的xml tree
ID = item0['ID'] # 得到当前图片的名字
imagename = roadimages + ID + '.jpg' # 当前图片的完整路径
savexml = roadlabels + ID + '.xml' # 生成的.xml注释的名字
gtboxes = item0['gtboxes']
img_name = ID
floder = 'CrowdHuman'
im = cv2.imread(imagename)
w = im.shape[1]
h = im.shape[0]
d = im.shape[2]
doc = minidom.Document() # 创建DOM树对象
annotation = doc.createElement('annotation') # 创建子节点
doc.appendChild(annotation) # annotation作为doc树的子节点
folder = doc.createElement('folder')
folder.appendChild(doc.createTextNode(floder)) # 文本节点作为floder的子节点
annotation.appendChild(folder) # folder作为annotation的子节点
filename = doc.createElement('filename')
filename.appendChild(doc.createTextNode(img_name + '.jpg'))
annotation.appendChild(filename)
source = doc.createElement('source')
database = doc.createElement('database')
database.appendChild(doc.createTextNode("Unknown"))
source.appendChild(database)
annotation.appendChild(source)
size = doc.createElement('size')
width = doc.createElement('width')
width.appendChild(doc.createTextNode("%d" % w))
size.appendChild(width)
height = doc.createElement('height')
height.appendChild(doc.createTextNode("%d" % h))
size.appendChild(height)
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode("%d" % d))
size.appendChild(depth)
annotation.appendChild(size)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode("0"))
annotation.appendChild(segmented)
# 下面是从odgt中提取三种类型的框并转为voc格式的xml的代码
# 不需要的box种类整段注释即可
for i1, item1 in enumerate(gtboxes):
# 提取全身框(full box)的标注
boxs = [int(a) for a in item1['vbox']]
# 左上点长宽--->左上右下
minx = str(boxs[0])
miny = str(boxs[1])
maxx = str(boxs[2] + boxs[0])
maxy = str(boxs[3] + boxs[1])
# print(box)
object = doc.createElement('object')
nm = doc.createElement('name')
nm.appendChild(doc.createTextNode('body')) # 类名: fbox
object.appendChild(nm)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode("Unspecified"))
object.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode("1"))
object.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode("0"))
object.appendChild(difficult)
bndbox = doc.createElement('bndbox')
xmin = doc.createElement('xmin')
xmin.appendChild(doc.createTextNode(minx))
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin.appendChild(doc.createTextNode(miny))
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax.appendChild(doc.createTextNode(maxx))
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax.appendChild(doc.createTextNode(maxy))
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
savefile = open(savexml, 'w')
savefile.write(doc.toprettyxml())
savefile.close()
注意:
第7行是要保存的标注的路径
第8行是图片保存的路径
第9行是odgt文件保存的路径
选择要保存的标注框的类型,可以通过改变第79行 “item1[‘vbox’]” 中参数的名称,可选有:vbox fbox hbox,分别对应:可看到的人体,完整人体,人脸,之后就可以将对应的信息保存在xml文件中,如果要同时保存多种信息,可以通过添加79-116行代码块进行添加。
按照上述步骤做就完成了,可以进行下一步的训练了。
参考链接
- https://github.com/jkjung-avt/yolov4_crowdhuman
- http://www.crowdhuman.org/download.html
- https://chtseng.wordpress.com/2019/12/13/crowdhuman-dataset-%E4%BB%8B%E7%B4%B9/