文章目录
「章节总览」
【hadoop组件—HDFS https://blog.csdn.net/weixin_45404884/article/details/140488744】
【hadoop组件—MapReduce https://blog.csdn.net/weixin_45404884/article/details/140577542】
【hadoop组件—YARN https://blog.csdn.net/weixin_45404884/article/details/140578055】
一、hadoop概念
Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会开发和维护。
Hadoop 为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集,并且支持在单台计算机到几千台计算机之间进行扩展。
Hadoop 使用 Java 开发,所以可以在多种不同硬件平台的计算机上部署和使用。其核心部件包括分布式文件系统 (Hadoop DFS,HDFS) 和 MapReduce。
二、 Hadoop核心组件
- Hadoop HDFS(分布式文件存储系统):解决海量数据存储
- Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
- Hadoop MapReduce(分布式计算框架):解决海量数据计算
三、Hadoop集群
Hadoop集群包括两个集群:HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起
- 两个集群都是标准的主从架构集群
HDFS集群:
- 主角色:NameNode
- 从角色:DataNode
- 主角色辅助角色:SecondaryNameNode
YARN集群:
- 主角色:ResourceManager
- 从角色:NodeManager
四、Hadoop安装包目录结构
| 目录 | 说明 |
|---|---|
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
| etc | Hadoop配置文件所在的目录 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
| share | Hadoop各个模块编译后的jar包所在的目录,官方自带示例。 |
五、Hadoop默认的四个核心配置文件
- core-site.xml : 核心模块配置
- hdfs-site.xml: hdfs文件系统模块配置
- mapred-site.xml: MapReduce模块配置
- yarn-site.xml : yarn模块配置
六、HDFS
1.前言
(1)文件系统
文件系统是一种存储和组织数据的方法,实现了数据的存储、分级组织、访问和获取等操作,使得用户对文件访问和查找变得容易;
- 文件系统使用树形目录的抽象逻辑概念代替了硬盘等物理设备使用数据块的概念,用户不必关心数据底层存在硬盘哪里,只需要记住这个文件的所属目录和文件名即可;
- 比如windows操作系统
- 数据:指存储的内容本身,比如文件、视频、图片等
- 元数据:又称之为解释性数据,记录数据的数据;一般指文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息。
2.HDFS简介
- Hadoop分布式文件系统。HDFS主要是解决大数据如何存储问题的。
- HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据 (比如 TB 和 PB)。
- HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。
3.HDFS重要特性
- 主从架构
- 分块存储
- 副本机制
- 元数据记录
- 抽象统一的目录树结构(namespace)
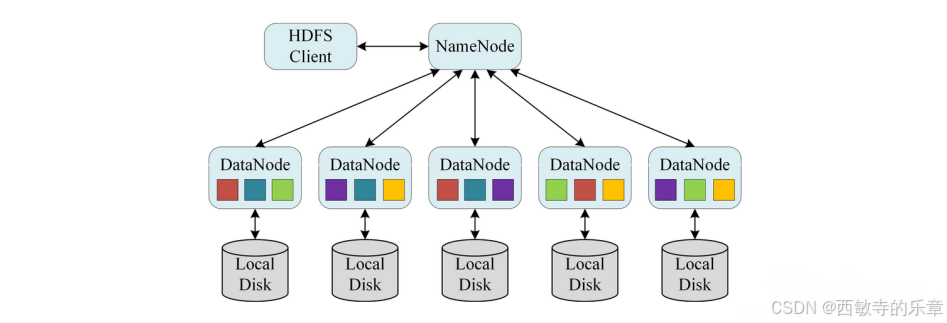
(1)主从架构
HDFS集群是标准的master/slave主从架构集群。
- 一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
- Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
(2)分块存储
- HDFS中的文件在物理上是分块存储(block)的,默认大小是128M(134217728),不足128M则本身就是一块。
- 块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。
(3)副本机制
- 文件的所有block都会有副本。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
- 副本数由参数dfs.replication控制,默认值是3,也就是会额外再复制2份,连同本身总共3份副本。
(4)元数据管理
在HDFS中,Namenode管理的元数据具有两种类型:
- 文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。 - 文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
(5)namespace
HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。
文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
- Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
- HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dira/dir-b/dir-c/file.data。
4.HDFS常用命令
(1)创建文件夹
hadoop fs -mkdir
(2)查看指定目录下内容
hadoop fs -ls
(3)上传文件到HDFS指定目录下
hadoop fs -put
(4)查看HDFS文件内容
hadoop fs -cat
(5)下载HDFS文件
hadoop fs -get
(6)追加数据到HDFS文件中
hadoop fs -appendToFile
(7)HDFS shell其他命令
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
5.namenode职责
- NameNode仅存储HDFS的元数据文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据。
- NameNode知道HDFS中任何给定文件的块列表及其位置,使用此信息NameNode知道如何从块中构建文件。
- NameNode不持久化存储每个文件中各个块所在的datanode的位置信息,这些信息会在系统启动时从DataNode重建。
- NameNode是Hadoop集群中的单点故障。
- NameNode所在机器通常会配置有大量内存(RAM)。
6.datanode职责
- DataNode负责最终数据块block的存储它是集群的从角色,也称为Slave。
- DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的块列表。
- 当某个DataNode关闭时,不会影响数据的可用性,NameNode将安排由其他DataNode管理的块进行副本复制。
- DataNode所在机器通常配置有大量的硬盘空间,因为实际数据存储在DataNode中。