autoware.universe源码略读3.13--perception:multi_object_tracker
Overview
官方对这个包的描述是利用时间序列处理目标检测结果,主要目的是提供目标ID与预测的速度,流程图如下
里面由Data association和EKF Tracker两部分组成
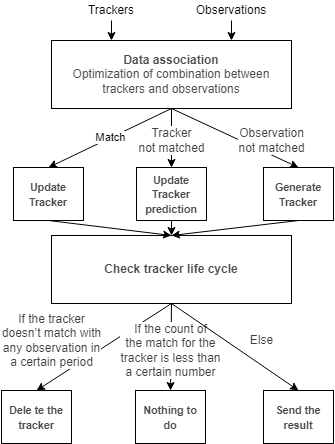
Data association
The data association performs maximum score matching, called min cost max flow problem. In this package, mussp[1] is used as solver. In addition, when associating observations to tracers, data association have gates such as the area of the object from the BEV, Mahalanobis distance, and maximum distance, depending on the class label.
看完了这段介绍也有点云里雾里的。。不过大概意思应该是把跟踪数据和观测数据根据BEV、马氏距离等指标给关联起来了
EKF Tracker
Models for pedestrians, bicycles (motorcycles), cars and unknown are available. The pedestrian or bicycle tracker is running at the same time as the respective EKF model in order to enable the transition between pedestrian and bicycle tracking. For big vehicles such as trucks and buses, we have separate models for passenger cars and large vehicles because they are difficult to distinguish from passenger cars and are not stable. Therefore, separate models are prepared for passenger cars and big vehicles, and these models are run at the same time as the respective EKF models to ensure stability.
这里看意思是为不同类别的跟踪准备了不同的EKF模型,接下来我们结合代码分开来看一下这几个部分
data_association
数据部分可以分为两个小块,一个是solver块,里面包含SSP算法(没用到)和muSSP算法(直接调用了第三方库),另一个就是主要的类,这里涉及到的问题是网络流问题,对这部分的概念也是简单了解了一下
[网络流]学习笔记:一次理解网络流!
一篇网络流 基本模型超全总结(最大流 费用流 多源汇最大流 上下界可行流) 思路+代码模板
gnn_solver
这里率先使用到的是gnn_solver这样一个东西,关于gnn_solver,指的应该是图神经网络,参考使用GNN求解组合优化问题大致先了解了一下这个东西是干嘛的。当然在接口中,其实只定义了一个虚函数,就是maximizeLinearAssignment,这个函数在后续子类中肯定是要被重新实现的。
后来又学习了下这个类,感觉这里指地又像是global nearest neighbor,因为这里其实没实现什么具体地东西,所以也分不清到底要指什么
(Class)successive_shortest_path
这是data_association的一种方法,直译过来是连续最短路径,继承自GnnSolverInterface类。里面首先定义了残差边ResidualEdge这样一个结构体,为后边的优化问题做准备
struct ResidualEdge
{
// Destination node
const int dst; // 残差边指向的目标节点
int capacity; // 残差边的容量
const double cost; // 残差边的成本(cost)
int flow; // 通过当前边的流量(flow)
// Access to the reverse edge by adjacency_list.at(dst).at(reverse)
const int reverse; // 反向边的索引
// ResidualEdge()
// : dst(0), capacity(0), cost(0), flow(0), reverse(0) {}
ResidualEdge(int dst, int capacity, double cost, int flow, int reverse)
: dst(dst), capacity(capacity), cost(cost), flow(flow), reverse(reverse)
{
}
};
之后,就是有300多行长的maximizeLinearAssignment函数,这里实现了最大线性分配问题的求解,用到的方法就是这个文件所对应的SSP方法,这里的cost是输入的成本矩阵,最后要重新分配的结果就是direct_assignment和reverse_assignment,这里我的理解就是重新分配了节点之间的连接关系,也不知道这样理解对不对。
函数首先设置了一些变量值并对cost进行了大小的检查,之后构建了残差网络,其中涉及到了n_dummies虚拟节点,这个应该是处理稀疏矩阵的时候用到的技巧。然后还涉及到了几个节点类型
int source = 0; // 源节点
int sink = n_agents + n_tasks + 1; // 汇节点
int n_nodes = n_agents + n_tasks + n_dummies + 2; // 节点总数
这里我让GPT为我生成了一张图解释各个节点之间的关系,也不知道对不对,我感觉这个图应该是有点问题。。不过因为也不是特别懂,所以说不上来具体的错误
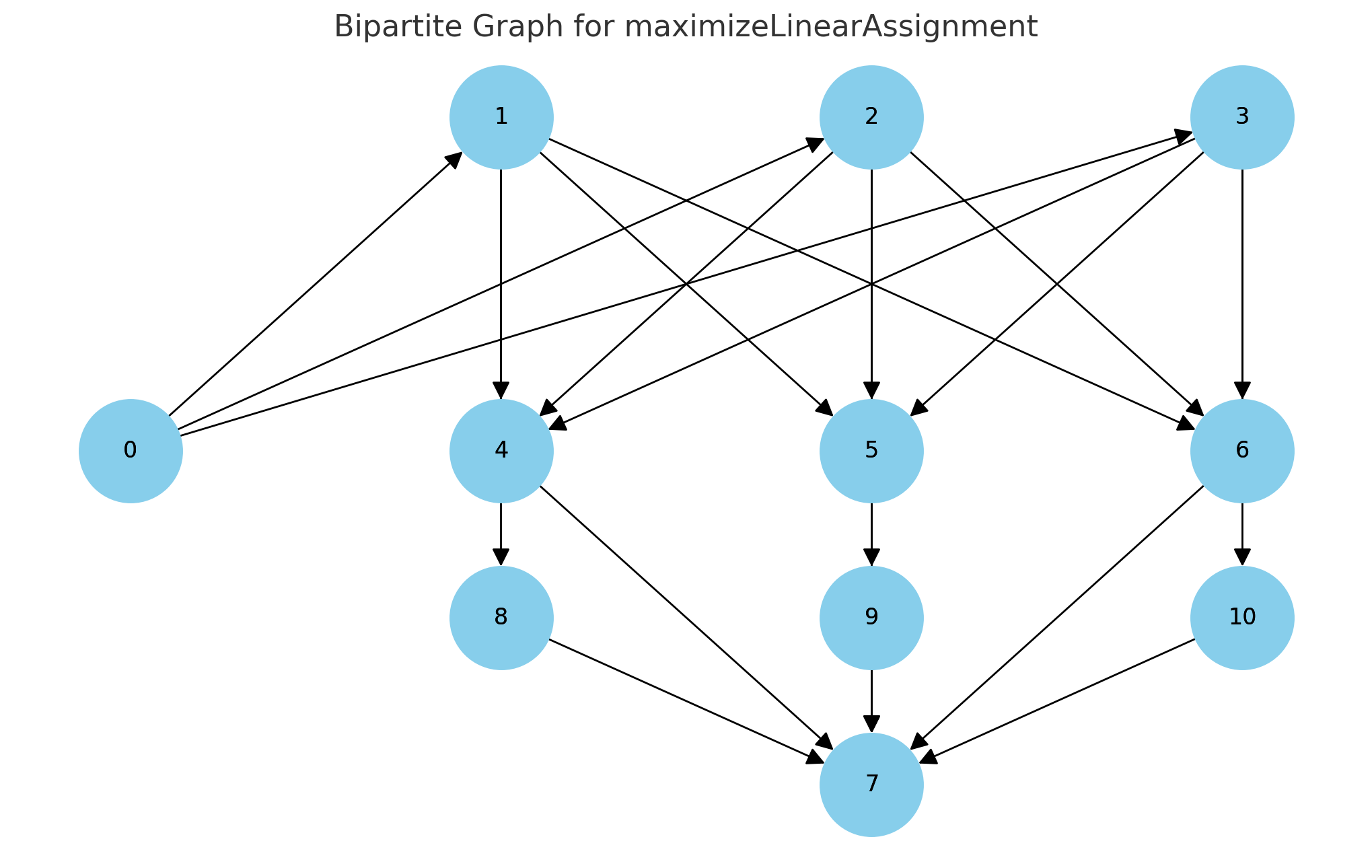
- 源节点 (0) 与每个代理节点 (1, 2, 3) 相连。
- 每个代理节点与每个任务节点 (4, 5, 6) 相连。
- 每个任务节点与汇节点 (7) 相连。
- 由于使用了稀疏代价 (sparse_cost),每个代理节点还与对应的虚拟节点 (8, 9, 10) 相连,并且这些虚拟节点也与汇节点 (7) 相连。
所以,这里的残差网络就是
std::vector<std::vector<ResidualEdge>> adjacency_list(n_nodes);
之后就分别添加残差边了,首先添加的是代理节点与源节点的边
// Add edges form source
for (int agent = 0; agent < n_agents; ++agent) {
// From source to agent
adjacency_list.at(source).emplace_back(agent + 1, 1, 0, 0, adjacency_list.at(agent + 1).size());
// From agent to source
adjacency_list.at(agent + 1).emplace_back(
source, 0, 0, 0, adjacency_list.at(source).size() - 1);
}
然后再添依次添加:任务节点、汇节点以及可能用到的虚拟节点 这几种节点对应的残差边,可以看到在最开始的网络构建的过程中,容量成本和流量三个变量都是设成0的。之后先定义了几个变量
// Maximum flow value
// 最大流量,其值为n_agents(代理节点数量)和n_tasks(任务节点数量)中的较小值。
// 在流网络中,最大流量是指从源节点到汇节点可以通过的最大流量。
const int max_flow = std::min(n_agents, n_tasks);
// Feasible potentials
// 用于存储每个节点的势能。在最小成本流问题中,势能是一种用于调整边的成本的技巧
// 可以保证所有的边的调整后的成本都是非负的
std::vector<double> potentials(n_nodes, 0);
// Shortest path lengths
// 用于存储从源节点到每个节点的最短路径长度
// 初始时,所有节点的最短路径长度都设置为无穷大(INF_DIST)
std::vector<double> distances(n_nodes, INF_DIST);
// Whether previously visited the node or not
// 用于存储每个节点是否已经被访问过
// 初始时,所有节点都没有被访问过
std::vector<bool> is_visited(n_nodes, false);
// Parent node (<prev_node, edge_index>)
// 用于存储每个节点的父节点和到达该节点的边的索引
// 在计算最短路径时,父节点是用于记录路径的重要信息,可以用于在找到最短路径后回溯路径
std::vector<std::pair<int, int>> prev_values(n_nodes);
接下来一大段的目的其实都是为了搜索最短路径,核心部分是对这个节点的遍历
// Loop over the incident nodes(/edges)
for (auto it_incident_edge = adjacency_list.at(cur_node).cbegin();
it_incident_edge != adjacency_list.at(cur_node).cend(); it_incident_edge++) {
// If the node is not visited and have capacity to increase flow, visit.
if (!is_visited.at(it_incident_edge->dst) && it_incident_edge->capacity > 0) {
// Calculate reduced cost
double reduced_cost =
it_incident_edge->cost + potentials.at(cur_node) - potentials.at(it_incident_edge->dst);
assert(reduced_cost >= 0);
if (distances.at(it_incident_edge->dst) > reduced_cost) {
distances.at(it_incident_edge->dst) = reduced_cost;
prev_values.at(it_incident_edge->dst) =
std::make_pair(cur_node, it_incident_edge - adjacency_list.at(cur_node).cbegin());
// std::cout << "[push]: (" << reduced_cost << ", " << next_v << ")" << std::endl;
p_queue.push(std::make_pair(reduced_cost, it_incident_edge->dst));
}
}
}
然后是增加/减少从源到汇的最短路径上的流量和容量,这里是分别拿出来了一个向前的残差边和一个向后的残差边,然后通过流量,判断具体哪些值应该被加加减减
int v = sink;
int prev_v;
while (v != source) {
ResidualEdge & e_forward =
adjacency_list.at(prev_values.at(v).first).at(prev_values.at(v).second);
assert(e_forward.dst == v);
ResidualEdge & e_backward = adjacency_list.at(v).at(e_forward.reverse);
prev_v = e_backward.dst;
if (e_backward.flow == 0) {
e_forward.capacity -= 1;
e_forward.flow += 1;
e_backward.capacity += 1;
} else {
e_forward.capacity -= 1;
e_backward.capacity += 1;
e_backward.flow -= 1;
}
v = prev_v;
}
之后是设置输出,这里的输出其实就是设置了代理节点和映射节点之间的映射关系,核心就是对匹配关系的提取
// Output
for (int agent = 0; agent < n_agents; ++agent) {
for (auto it_incident_edge = adjacency_list.at(agent + 1).cbegin();
it_incident_edge != adjacency_list.at(agent + 1).cend(); ++it_incident_edge) {
int task = it_incident_edge->dst - (n_agents + 1);
// If the flow value is 1 and task is not dummy, assign the task to the agent.
if (it_incident_edge->flow == 1 && 0 <= task && task < n_tasks) {
(*direct_assignment)[agent] = task;
(*reverse_assignment)[task] = agent;
break;
}
}
}
这部分感觉就是把所有的节点之间构建连接,然后它的思路是每次寻找单位费用最小的增广路进行增广,直到图上不存在增广路为止。如果图上存在单位费用为负的圈,SSP 算法无法正确求出该网络的最小费用最大流。此时需要先使用消圈算法消去图上的负圈。 其实这里自己也没有完全搞懂到底是怎么样的一个算法,只是大概知道是干什么的了而已
(Class)mu_successive_shortest_path
这个部分应该是涉及到的另一个算法,来自文章[1] C. Wang, Y. Wang, Y. Wang, C.-t. Wu, and G. Yu, “muSSP: Efficient Min-cost Flow Algorithm for Multi-object Tracking,” NeurIPS, 2019
| Name | License | Original Repository |
|---|---|---|
| muSSP | Apache-2.0 | https://github.com/yu-lab-vt/muSSP |
这里其实直接用到了上边的这个第三方库,这样直接调用solve_muSSP函数就好了。这里具体的原理就没太看了
(Class)data_association
这里是执行整个数据关联的部分,关于数据关联,之前没听说过所以可能想的不太明白,其实主要的目的就是进行帧与帧之间的多个目标的匹配。涉及到了很多算法,像Autoware.universe里面(当前galatic版本)下,使用到了SSP以及muSSP这两种方法,然后像我听说过的Apollo应该用的是匈牙利算法,具体的每一种算法的原理确实没有去深入研究,这里还是以知道这部分在干什么为学习目标。
(Func)getMahalanobisDistance
计算测量点与跟踪点之间的马氏距离,这里的测量应该指的就是观测,然后跟踪指的就是预测吧。至于马氏距离的计算就没什么好说的了,只需要先把数据类型统一了就好
(Func)getXYCovariance
在给定位置信息的情况下,计算x和y之间的协方差,所以这里对应的索引就分别是xx,yy,xy和yx
covariance << pose_covariance.covariance[0], pose_covariance.covariance[1],
pose_covariance.covariance[6], pose_covariance.covariance[7];
(Func)getFormedYawAngle
这个就是计算观测和跟踪的Yaw角差的,当然对角度的处理就不可避免地涉及到PI
const double angle_range = distinguish_front_or_back ? M_PI : M_PI_2;
const double angle_step = distinguish_front_or_back ? 2.0 * M_PI : M_PI;
// Fixed measurement_yaw to be in the range of +-90 or 180 degrees of X_t(IDX::YAW)
double measurement_fixed_yaw = measurement_yaw;
while (angle_range <= tracker_yaw - measurement_fixed_yaw) {
measurement_fixed_yaw = measurement_fixed_yaw + angle_step;
}
while (angle_range <= measurement_fixed_yaw - tracker_yaw) {
measurement_fixed_yaw = measurement_fixed_yaw - angle_step;
}
(Class Constructor)DataAssociation::DataAssociation
这个构造函数其实就是为成员变量赋值,这里把输入向量转成了Eigen::Map<Eigen::MatrixXd>这样的格式然后再赋值给成员变量
const int assign_label_num = static_cast<int>(std::sqrt(can_assign_vector.size()));
Eigen::Map<Eigen::MatrixXi> can_assign_matrix_tmp(
can_assign_vector.data(), assign_label_num, assign_label_num);
can_assign_matrix_ = can_assign_matrix_tmp.transpose();
最后我们看到,实例化的是gnn_solver::MuSSP,所以这里其实还是只用到了muSSP数据关联方法
(mFunc)DataAssociation::assign
执行数据关联步骤的函数,可以看到首先把数据准备好
std::vector<std::vector<double>> score(src.rows());
for (int row = 0; row < src.rows(); ++row) {
score.at(row).resize(src.cols());
for (int col = 0; col < src.cols(); ++col) {
score.at(row).at(col) = src(row, col);
}
}
然后直接调用maximizeLinearAssignment函数就好
// Solve
gnn_solver_ptr_->maximizeLinearAssignment(score, &direct_assignment, &reverse_assignment);
最后回根据分数进行一下筛选,把小于分数阈值的删除掉
(mFunc)DataAssociation::calcScoreMatrix
这个函数的主要目的是计算跟踪器(tracker)和检测到的物体(measurement)之间的得分矩阵(score matrix),用于后续的目标跟踪和数据关联。(先踩猜一下,数据关联的输入不会就是这个吧)
这里会对所有跟踪的物体和所有观测到的物体进行遍历,之后判断是否匹配
if (can_assign_matrix_(tracker_label, measurement_label)) {
匹配的话,会调用具体的模型得到当前时间下的TrackedObject
autoware_auto_perception_msgs::msg::TrackedObject tracked_object;
(*tracker_itr)->getTrackedObject(measurements.header.stamp, tracked_object);
接下来进行了一堆判定,这里的要求是,所有的判定都需要通过,具体包括距离、面积、角度、马氏距离和IoU,之后会算一个得分,并且放在对应的索引上(不匹配直接0)
// all gate is passed
if (passed_gate) {
score = (max_dist - std::min(dist, max_dist)) / max_dist;
if (score < score_threshold_) score = 0.0;
}
}
score_matrix(tracker_idx, measurement_idx) = score;
tracker
这里应该就是针对不同的对象写的不同的跟踪模型了,这里会用到common中的Kalman模块,这个在autoware.universe源码略读(1)–common中有简单提到过
bicycle_tracker
针对自行车的跟踪模型
(Struct)EkfParams
EKF所会用到的一些参数,首先这里涉及到了五维的变量,对应的就是enum IDX里面的五个成员
enum IDX {
X = 0,
Y = 1,
YAW = 2,
VX = 3,
WZ = 4,
};
然后在EkfParams中包含的是几个变量之间的协方差,然后p0对应的是初始协方差吧?至于r对应的就是几个变量的噪声了
(Struct)BoundingBox
每个检测框对应的三个变量,就是长宽高
(Class Constructor)BicycleTracker
构造函数里首先对刚才提到的EKF参数结构体进行了初始化,这里先对状态变量X进行了初始化
// initialize X matrix
Eigen::MatrixXd X(ekf_params_.dim_x, 1);
X(IDX::X) = object.kinematics.pose_with_covariance.pose.position.x;
X(IDX::Y) = object.kinematics.pose_with_covariance.pose.position.y;
X(IDX::YAW) = tf2::getYaw(object.kinematics.pose_with_covariance.pose.orientation);
if (object.kinematics.has_twist) {
X(IDX::VX) = object.kinematics.twist_with_covariance.twist.linear.x;
X(IDX::WZ) = object.kinematics.twist_with_covariance.twist.angular.z;
} else {
X(IDX::VX) = 0.0;
X(IDX::WZ) = 0.0;
}
然后初始化的还有P阵,这里需要注意的是,在object自身不包含协方差信息的时候,对XY变量的协方差计算进行了一定的处理,代码中给的解释是because p0_cov_x and y are in the vehicle coordinate system. 所以这里就是相当于做了一个2D的旋转
P(IDX::X, IDX::X) =
ekf_params_.p0_cov_x * cos_yaw * cos_yaw + ekf_params_.p0_cov_y * sin_yaw * sin_yaw;
P(IDX::X, IDX::Y) = 0.5f * (ekf_params_.p0_cov_x - ekf_params_.p0_cov_y) * sin_2yaw;
P(IDX::Y, IDX::Y) =
ekf_params_.p0_cov_x * sin_yaw * sin_yaw + ekf_params_.p0_cov_y * cos_yaw * cos_yaw;
P(IDX::Y, IDX::X) = P(IDX::X, IDX::Y);
当然如果object自己就带协方差的话,就用对象带的信息。然后线速度以及角速度的协方差也是也同样的道理,最后是对ekf进行了初始化
ekf_.init(X, P);
(mFunc)BicycleTracker::predict
这个函数有两种参数的输入形式,其中第一种predict(const rclcpp::Time & time)只输入一个时间的这里相当于一个接口,计算出来dt后里面具体调用的还是第二种形式,首先我们看针对自行车的这个非线性模型的形式
/* == Nonlinear model ==
*
* x_{k+1} = x_k + vx_k * cos(yaw_k) * dt
* y_{k+1} = y_k + vx_k * sin(yaw_k) * dt
* yaw_{k+1} = yaw_k + (wz_k) * dt
* vx_{k+1} = vx_k
* wz_{k+1} = wz_k
*
*/
OK这个形式非常简单,所以对应的线性化的模型也非常简单
/* == Linearized model ==
*
* A = [ 1, 0, -vx*sin(yaw)*dt, cos(yaw)*dt, 0]
* [ 0, 1, vx*cos(yaw)*dt, sin(yaw)*dt, 0]
* [ 0, 0, 1, 0, dt]
* [ 0, 0, 0, 1, 0]
* [ 0, 0, 0, 0, 1]
*/
这里A的计算没什么好说的,Q矩阵的计算和之前一样,还是要把XY的协方差进行一下旋转
Q(IDX::X, IDX::X) =
(ekf_params_.q_cov_x * cos_yaw * cos_yaw + ekf_params_.q_cov_y * sin_yaw * sin_yaw) * dt * dt;
Q(IDX::X, IDX::Y) = (0.5f * (ekf_params_.q_cov_x - ekf_params_.q_cov_y) * sin_2yaw) * dt * dt;
Q(IDX::Y, IDX::Y) =
(ekf_params_.q_cov_x * sin_yaw * sin_yaw + ekf_params_.q_cov_y * cos_yaw * cos_yaw) * dt * dt;
Q(IDX::Y, IDX::X) = Q(IDX::X, IDX::Y);
Q(IDX::YAW, IDX::YAW) = ekf_params_.q_cov_yaw * dt * dt;
Q(IDX::VX, IDX::VX) = ekf_params_.q_cov_vx * dt * dt;
Q(IDX::WZ, IDX::WZ) = ekf_params_.q_cov_wz * dt * dt;
然后直接调用EKF类中的预测函数就完成了预测的步骤
if (!ekf.predict(X_next_t, A, Q)) {
RCLCPP_WARN(logger_, "Cannot predict");
}
(mFunc)BicycleTracker::measureWithPose
执行接收到object消息后的量测更新,这里首先根据角度信息是否有效,决定了观测向量的维度
bool use_orientation_information = false;
if (
object.kinematics.orientation_availability ==
autoware_auto_perception_msgs::msg::DetectedObjectKinematics::SIGN_UNKNOWN) { // has 180 degree
// uncertainty
// fix orientation
while (M_PI_2 <= X_t(IDX::YAW) - measurement_yaw) {
measurement_yaw = measurement_yaw + M_PI;
}
while (M_PI_2 <= measurement_yaw - X_t(IDX::YAW)) {
measurement_yaw = measurement_yaw - M_PI;
}
use_orientation_information = true;
} else if (
object.kinematics.orientation_availability ==
autoware_auto_perception_msgs::msg::DetectedObjectKinematics::AVAILABLE) { // know full angle
use_orientation_information = true;
}
const int dim_y =
use_orientation_information ? 3 : 2; // pos x, pos y, (pos yaw) depending on Pose output
之后就是设置量测更新中需要的Y、C和R矩阵。这里的R矩阵也是会根据object是否自带协方差来定,自带协方差信息的话直接把对应的设置为R阵,然后执行更新过程的话,也是调用EKF类的函数就好
// update with ekf
if (!ekf_.update(Y, C, R)) {
RCLCPP_WARN(logger_, "Cannot update");
}
这里最后还对Z也处理了一下,对Z的话可以简单看作是一个一维的滤波器了
// position z
constexpr float gain = 0.9;
z_ = gain * z_ + (1.0 - gain) * object.kinematics.pose_with_covariance.pose.position.z;
(mFunc)BicycleTracker::measureWithShape
对物体的长宽高都执行了一个一维滤波,和对Z的处理是相同的
bounding_box_.width = gain * bounding_box_.width + (1.0 - gain) * object.shape.dimensions.x;
bounding_box_.length = gain * bounding_box_.length + (1.0 - gain) * object.shape.dimensions.y;
bounding_box_.height = gain * bounding_box_.height + (1.0 - gain) * object.shape.dimensions.z;
(mFunc)BicycleTracker::measure
进行量测更新的接口,这里提到预测和量测之间的时间差最好小于10ms
(mFunc)BicycleTracker::getTrackedObject
这个是获取跟踪物体的函数接口,输入的就是物体和你想要的时间,函数一上来就把物体先转成了TrackedObject这个类型。之后先调用预测函数,这里其实主要执行的就是预测步骤,感觉可以理解为对现有的object_变量进行了预测
// predict kinematics
KalmanFilter tmp_ekf_for_no_update = ekf_;
const double dt = (time - last_update_time_).seconds();
if (0.001 /*1msec*/ < dt) {
predict(dt, tmp_ekf_for_no_update);
}
接下来就是把预测得到的状态变量赋值给对应的变量了,这里协方差的地方有一点不同,因为目前的EKF模型是只考虑了五个维度,所以没考虑的维度之间的协方差就单纯利用经验值(代码里是0.1*0.1)了。当然最后针对形状shape也进行了一下处理,不过这里形状的大小是不会变的,只是根据角度对footprint进行了更新
// set shape
object.shape.dimensions.x = bounding_box_.width;
object.shape.dimensions.y = bounding_box_.length;
object.shape.dimensions.z = bounding_box_.height;
const auto origin_yaw = tf2::getYaw(object_.kinematics.pose_with_covariance.pose.orientation);
const auto ekf_pose_yaw = tf2::getYaw(pose_with_cov.pose.orientation);
object.shape.footprint =
tier4_autoware_utils::rotatePolygon(object.shape.footprint, origin_yaw - ekf_pose_yaw);
big_vehicle_tracker
这个只是单纯针对不同的车型重新实现了下EKF,所以其实大部分东西是相同的,可能会有一些细节不同。首先因为车型不同了,所以这里把对应的噪声也放大了。但是啊,这里的模型似乎也没变
/* == Nonlinear model ==
*
* x_{k+1} = x_k + vx_k * cos(yaw_k) * dt
* y_{k+1} = y_k + vx_k * sin(yaw_k) * dt
* yaw_{k+1} = yaw_k + (wz_k) * dt
* vx_{k+1} = vx_k
* wz_{k+1} = wz_k
*
*/
/* == Linearized model ==
*
* A = [ 1, 0, -vx*sin(yaw)*dt, cos(yaw)*dt, 0]
* [ 0, 1, vx*cos(yaw)*dt, sin(yaw)*dt, 0]
* [ 0, 0, 1, 0, dt]
* [ 0, 0, 0, 1, 0]
* [ 0, 0, 0, 0, 1]
*/
其他就没什么不一样的了
normal_vehicle_tracker
依旧没什么不一样的,但这个NormalVehicle不知道最后会指具体哪种车辆
pedestrian_tracker
针对行人的EKF模型,这里当然就把噪声适当降低了,然后模型还是没什么不一样的。。这里有一点不一样的东西是在量测更新的时候,观测维度就固定是2了
constexpr int dim_y = 2; // pos x, pos y depending on Pose output
/* Set measurement matrix */
Eigen::MatrixXd Y(dim_y, 1);
Y << object.kinematics.pose_with_covariance.pose.position.x,
object.kinematics.pose_with_covariance.pose.position.y;
然后这里的形状分成了BOUNDING_BOX``和CYLINDER两种
if (object.shape.type == autoware_auto_perception_msgs::msg::Shape::BOUNDING_BOX) {
bounding_box_.width = gain * bounding_box_.width + (1.0 - gain) * object.shape.dimensions.x;
bounding_box_.length = gain * bounding_box_.length + (1.0 - gain) * object.shape.dimensions.y;
bounding_box_.height = gain * bounding_box_.height + (1.0 - gain) * object.shape.dimensions.z;
} else if (object.shape.type == autoware_auto_perception_msgs::msg::Shape::CYLINDER) {
cylinder_.width = gain * cylinder_.width + (1.0 - gain) * object.shape.dimensions.x;
cylinder_.height = gain * cylinder_.height + (1.0 - gain) * object.shape.dimensions.z;
} else {
return false;
}
剩下的思路就一样了
unknown_tracker
针对未知的物体,之前在map_based_prediction中也提到过,autoware只认为这类物体在进行直线运动,所以我们可以看到这个类里的运动模型非常简单
/* == Nonlinear model ==
*
* x_{k+1} = x_k + vx_k * dt
* y_{k+1} = y_k + vx_k * dt
* vx_{k+1} = vx_k
* vy_{k+1} = vy_k
*
*/
/* == Linearized model ==
*
* A = [ 1, 0, dt, 0]
* [ 0, 1, 0, dt]
* [ 0, 0, 1, 0]
* [ 0, 0, 0, 1]
*/
剩下的就也差不多了,无非是一些细节上有些区别,就没什么好说的了
multiple_vehicle_tracker
这个看名字还以为是多个车辆的预测,结果看代码的意思是多种车辆的一个EKF接口(也就是把normal_vehicle和big_vehicle放在了一起),里面分别定义了predict预测、measure量测更新以及getTrackedObject的接口函数,当然这些函数的实现只要调用之前的那个库就好了,然后这里也非常智障。。在预测和更新的过程中,依我看两个模型只有噪声的设置有些区别,但是这里还是都分别执行了一次,不过因为每次输入的object都可能不一样,所以似乎除此之外确实没什么办法了
pass_through_tracker
这里似乎是针对那些不需要进行EKF的类型的物体准备的,因为可以看到里面其实没有任何的EKF过程,只是单纯对object_和``last_update_time_这种变量进行了更新。不知道这个类又是面向什么类型的,后边用到了再看吧
pedestrian_and_bicycle_tracker
和multiple_vehicle_tracker类似,不过这里就是把行人和自行车的接口写在一起了
tracker_base
整个跟踪类的一个基类,这里的构造函数用到了一些没见过的C++用法,搜了下主要是生成随机数的
std::mt19937 gen(std::random_device{}()); // std::random_device{}是一种随机数生成设备,通常用于生成高质量的随机数种子
// std::mt19937(Mersenne Twister) 是一种常用的伪随机数生成器
// 因其较长的周期(2^19937-1)和较好的统计性质而广泛使用。
std::independent_bits_engine<std::mt19937, 8, uint8_t> bit_eng(gen); // 用来生成固定位宽度的随机数
std::generate(uuid_.uuid.begin(), uuid_.uuid.end(), bit_eng); // 用于用生成器函数填充范围内的所有元素
然后这里定义的一个总接口是measure,针对predict反而没有总接口,是通过getPoseWithCovariance函数中调用getTrackedObject来执行到最终具体的不同类型的predict的
multi_object_tracker_core
(Class Constructor)MultiObjectTracker::MultiObjectTracker
这里就没什么好说的了,这个文件是整个包的一个核心节点实现,整个节点的参数有
| Name | Type | Description |
|---|---|---|
can_assign_matrix | double | Assignment table for data association |
max_dist_matrix | double | Maximum distance table for data association |
max_area_matrix | double | Maximum area table for data association |
min_area_matrix | double | Minimum area table for data association |
max_rad_matrix | double | Maximum angle table for data association |
world_frame_id | double | tracking frame |
enable_delay_compensation | bool | Estimate obstacles at current time considering detection delay |
publish_rate | double | if enable_delay_compensation is true, how many hertz to output |
| 然后构造函数里实例化了数据关联的类 |
data_association_ = std::make_unique<DataAssociation>(
can_assign_matrix, max_dist_matrix, max_area_matrix, min_area_matrix, max_rad_matrix,
min_iou_matrix);
(mFunc)MultiObjectTracker::onMeasurement
这个是在输入object时执行的回调函数,在坐标转换完成之后,先进行预测
rclcpp::Time measurement_time = input_objects_msg->header.stamp;
for (auto itr = list_tracker_.begin(); itr != list_tracker_.end(); ++itr) {
(*itr)->predict(measurement_time);
}
然后执行数据关联的过程
/* global nearest neighbor */
std::unordered_map<int, int> direct_assignment, reverse_assignment;
Eigen::MatrixXd score_matrix = data_association_->calcScoreMatrix(
transformed_objects, list_tracker_); // row : tracker, col : measurement
data_association_->assign(score_matrix, direct_assignment, reverse_assignment);
接下来根据数据关联地结果,可以找到匹配的对象的话执行量测更新,不然就直接更新
for (auto tracker_itr = list_tracker_.begin(); tracker_itr != list_tracker_.end();
++tracker_itr, ++tracker_idx) {
if (direct_assignment.find(tracker_idx) != direct_assignment.end()) { // found
(*(tracker_itr))
->updateWithMeasurement(
transformed_objects.objects.at(direct_assignment.find(tracker_idx)->second),
measurement_time);
} else { // not found
(*(tracker_itr))->updateWithoutMeasurement();
}
}
接下来对跟踪器的有效性进行了处理,然后发布最终的消息
(mFunc)MultiObjectTracker::createNewTracker
这里是根据Object的类型生成了新的跟踪器,在有新的object类型的时候调用
(mFunc)MultiObjectTracker::checkTrackerLifeCycle
这个看起来是判断跟踪器的时间间隔的,如果is_old,就把当前这个跟踪器删除掉
(mFunc)MultiObjectTracker::sanitizeTracker
这里主要是对跟踪器之间的关系进行了处理,目的是为了避免对很少种类的物体执行了很多种的跟踪器
// If at least one of them is UNKNOWN, delete the one with lower IOU. Because the UNKNOWN
// objects are not reliable.
if (label1 == Label::UNKNOWN || label2 == Label::UNKNOWN) {
if (min_iou_for_unknown_object < iou) {
if (label1 == Label::UNKNOWN && label2 == Label::UNKNOWN) {
if ((*itr1)->getTotalMeasurementCount() < (*itr2)->getTotalMeasurementCount()) {
should_delete_tracker1 = true;
} else {
should_delete_tracker2 = true;
}
} else if (label1 == Label::UNKNOWN) {
should_delete_tracker1 = true;
} else if (label2 == Label::UNKNOWN) {
should_delete_tracker2 = true;
}
}
} else { // If neither is UNKNOWN, delete the one with lower IOU.
if (min_iou < iou) {
if ((*itr1)->getTotalMeasurementCount() < (*itr2)->getTotalMeasurementCount()) {
should_delete_tracker1 = true;
} else {
should_delete_tracker2 = true;
}
}
}