导读:高可用架构 7 月 30 日在上海举办了『互联网架构的基石』专题沙龙,进行了闭门私董会研讨及对外开放的四个专题的演讲,期望能促进业界对互联网基础服务及工具的建设及发展,本文是姚捷分享唯品会全链路监控方案。
姚捷,唯品会平台架构部高级架构师,加入唯品会前有超过 10 年的金融/保险互联网技术架构和团队管理经验,擅长以产品思维设计和构建系统。现专注于互联网基础架构,负责唯品会全链路监控/分析平台的开发,管理,推广和运维落地工作。对大数据体系,实时计算,微服务体系,消息系统有深入研究和实践。
我来自唯品会平台架构部,非常感谢高可用架构在上海组织了这么一场高逼格的活动。唯品会平台架构部是长期致力于基础应用架构建设与推广的部门,我们承担非常多的基础应用架构研发。
唯品会有三大特点,特卖 + 闪购 + 正品,在唯品会,峰值访问量非常大,这样的流量,使得唯品会平台架构部承担非常大的挑战,包括我今天分享的全链路监控系统。
上面是我们的新广告,周杰伦代言,傲娇品牌,只卖呆萌的价格。
今天给大家带来的是我们一个比较重要的产品 Mercury,它是一个大型互联网应用全链路监控系统解决方案。
大家可能了解,500 错误场景可能是大家在线上经常遇到的问题,等待很长时间,然后系统给你 500,让大家很抓狂。在部署全链路监控之前,大家可能需要使用比较古老的方式,跑到生产机上面去查问题,这个过程可能耗费大量的时间。
之前在唯品会,我们做了一个叫 Logview 的产品,它是一款基于 nginx access log 的监控平台。唯品会大量系统前置了一个代理服务器,Logview 的机制是通过解析 nginx access log,构建一个日志监控平台。它跑了蛮长时间,迄今还在线上稳定运行,它曾经是唯品会最重要的一个监控平台。
但随着业务规模的不断增加,基于 nginx access log 的监控会遇到不少问题。
没有办法从代码级别进行监控,通过它只能看到粗粒度的监控信息;
随着服务化的改造,大部分的流量,已经不经过 nginx 了;
它支持告警,但是没有办法通过告警跟踪到问题的 root cause。比如说 500 通常是某一个异常导致的,但是这里是看不到异常的,你还得到主机上、到 ELK 上查日志。它没有办法通过告警很快速的定位到我们线上的 root cause,寻找问题的成本还是很高。
告警规则配置呆板,维护变更代价大。
没有办法跟踪业务之间的调用关系。唯品会在全网大概有上个业务域,主机现在接近几万台,这个体量是非常之大的,当一个系统一个域出了一个业务问题的时候,其实导致它产生问题的地方可能是很深层的。Logview 没有办法帮你跟踪到这些业务之间的关联关系,调用关系没有建立起来,出了问题你不知道最根本的原因在哪个域。
没有办法快速定位应用性能瓶颈。上面也提到,应用出了问题没有办法关联异常。
高峰值期间流量一上来就经常挂。
因为上面种种问题,我们痛定思痛,寻找新的方法。这个新的方向是什么?当时我们看了 Google Dapper (http://research.google.com/pubs/pub36356.html) 的文章之后,认为基本上就是全链路监控系统。
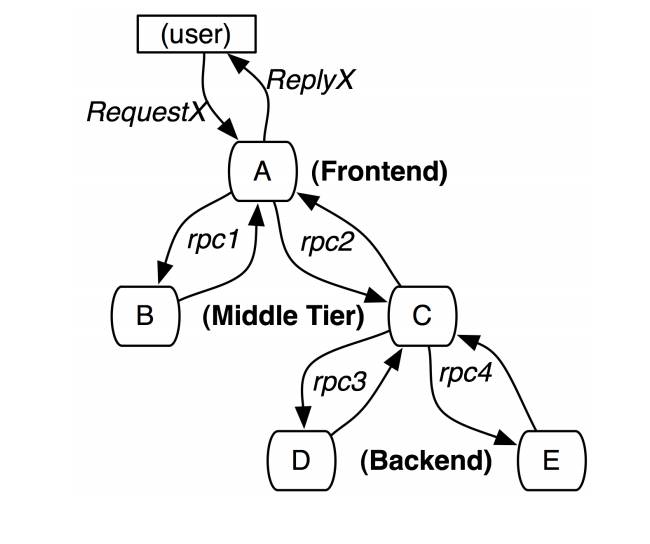
Dapper 是帮大家构建一套比较完整的端到端的全链路日志采集的规范,是大家可以跟随的一个原则或者准则。它最关键的概念就是 span。
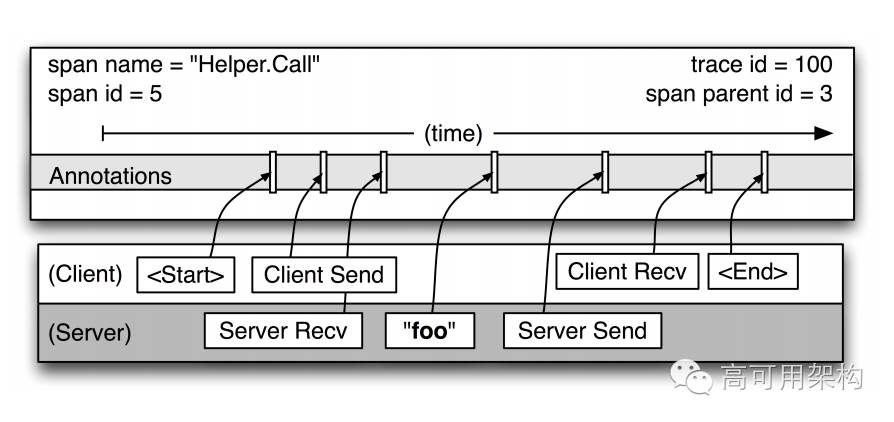
基于 Dapper 原理,有蛮多行业解决方案,比较有名的有淘宝 eagle eye,点评/携程的 CAT,微博的 Watchman,还有听云 Server 等。当时我们也对这些方案做了一些调研,但最终我们还是选择自建平台。
为什么呢?因为唯品会还算有钱,团队的能力也比较强,有蛮多资深的技术人员。除了有钱有之外,更多的是从业务上,从系统层面上去看我们为什么要自建平台。
第一,系统复杂。上千个业务域,同时又是异构系统,有很多系统还是 PHP。服务化体系内存在众多的异构系统的,我们要去监控这样的异构系统,显然不能直接用一些业界的方案。
第二,海量数据。唯品会峰值每分钟上亿日志量,一天达到上百亿的日志量,这是非常海量的数据。BAT 之外,对比其他公司,唯品会在这个数据量上面也是很高的。对这些海量日志,怎么样端到端对海量数据搜集、计算、存储、检索,这是一个很大的挑战。
第三,我们需要自建服务化体系的监控。我们有自建的服务化体系,这个服务化体系要怎么监控?我们的服务端其实需要一些定制的埋点和数据透传机制的,它没有办法说我直接打一个 log,这其实是每个公司有自己的服务化体系,它需要自己去埋点。
第四,高度可治理。这个非常重要,因为当你整个摊子铺大了之后,上千个域都接入后,怎么去管理?比如说大促的时候经常遇到我没数据了,为什么没有数据,整个体系是非常复杂的,我怎么样能够快速的知道这个业务为什么没有监控数据了,这就涉及到治理。
另外大促的时候我们要做一些动态的升降级,这些动态的升降级也是依赖比较强的治理能力,需要在生产环境去控制日志的产生。
第五,快速接入,升级便捷。因为我们的团队很大,开发人员很多,所以我们的产品要做到让业务用起来很方便,我们需要一些无侵入埋点,快速接入。
同时在我们很复杂的体系当中,需要考虑怎么快速的升级,我不知道大家有没有经历过在一个很庞大的体系当中升级客户端,不管是监控系统的客户端,还是其他的客户端都是很头疼的问题,特别是在业务线众多的大型公司。据说阿里的 dubbo/hsf 的升级其实是非常困难的,我们现在也遇到类似的问题,因此需要提前去考虑这些问题。
第六,灵活的告警策略和高效告警。我们需要一个多维度、多监督、多级别、多时效、同时支持告警收敛的告警引擎
第七,还有一个很重要的一点,监控体系要与公司的很多体系无缝对接,我需要满足不同角色的需求,同时要与唯品会的发布、监控、问题跟踪平台无缝对接。
所以正是因为以上种种原因,我们决定自建平台。
先快速给大家介绍一下 Mercury。
Mercury 是唯品会自主研发的应用性能监控和问题跟踪平台
基于客户端探针上报应用调用链相关日志
基于流式计算和大数据存储和检索技术
提供实时和准实时告警,并快速定位根源问题
分布式应用调用链路跟踪
提供快速有效的数据展现和分析平台
唯品会监控体系
我们的全链路应用监控体系在唯品会处于什么样的位置?

系统层监控我们主要还是 Zabbix,我们在上面做了一些封装,提供更好的交互。
业务层我们有一个产品叫 Telescope,所有的业务监控,包括 PV/UV、定单量、支付成功/失败率等重要业务数据&