基于图的异构数据集成方法研究
黄跃珍 1,2杨芬 1田丰 3张承业 1 李雨婵 1
(1. 广州广电运通信息科技有限公司,广东 广州 510663;2. 广州数字科技集团有限公司,广东 广州 510627;3. 广电运通集团股份有限公司,广东 广州 510663 )
DOI:10.11959/j.issn.2096-0271.2025002
引用格式:
黄跃珍,杨芬,田丰等.基于图的异构数据集成方法研究[J].大数据,2025,11(01):21-35.
HUANG Y Z,YANG F,TIAN F,et al.Research on graph-based heterogeneous data integration method[J].BIG DATA RESEARCH,2025,11(01):21-35.
摘 要 企业各部门对数据施行分散管理,烟囱式的系统建设使数据散落在异构数据库中,异构数据给当前数据集成工作带来了系列挑战。为解决企业异构系统数据汇聚融合的问题,提出一种基于图的端到端的数据集成框架。首先,根据关系型数据模型的主外键关系将表和字段的实体关系构建成网络图,将表名和字段名称分别看作图中不同类型的实体。然后,将构建的图输入图神经网络,经过图卷积得到图中各节点的向量表征,基于节点向量可计算任意所需匹配的两个图的节点映射关系。完成图中表和字段的对齐后,再将不同字段值标准化,即将每个单元格的值映射为标准值。最后,将以上结果工程化为数据库可执行的查询语句,从而实现异构数据融合。在企业内部的真实数据上进行验证,实验结果表明,文中所提框架能提高数据集成的开发效率,且该模型不受业务领域限制,具有较强的移植性。
关键词 数据集成;数据融合;异构数据;模式匹配;实体对齐;图神经网络
0 引言
随着企业信息化建设的不断发展,不同的业务系统中都积累了海量的数据,这些数据存储在不同类型的关系型数据库中。由于开发团队遵循的规范和标准不同,数据库的表结构、表名、字段名及字段名的含义均存在差异,甚至同厂商不同版本系统的数据库的表结构和字段命名方式也存在较大的差异,导致各业务系统之间的数据存在异构性,无法实现统一管理和共享,产生“数据孤岛”现象。为解决异构数据的问题,企业需要进行数据集成,将来自不同数据源、不同格式和不同结构的数据进行整合统一,这个过程需要对存量的异构数据进行清洗、转换、映射等处理,以获取标准化的、结构统一的数据。
数据集成的核心技术是数据融合。数据融合指将异构数据源的数据进行整合、合并的过程,是解决来自不同数据源的同一实体在集成过程中产生的冲突问题,从而保证数据的正确性与一致性。总体来看,数据融合分为两类场景:一是纵向的垂直领域的数据融合,也称数据合并,通过将多个异构系统的数据合并在同一张表中,得到数据全集,例如大型集团企业旗下存在多个下属子企业,集团需要汇聚采集各个子企业人力系统的员工信息数据进行数据合并来得到全集团的人员数据;二是横向的跨领域的数据融合,即将异构数据源中同一事物不同表示的实体进行识别消歧,获取该实体更多的有价值的信息,以打破“数据孤岛”,实现跨源数据之间的关联互通,例如将信用卡信息的关系型数据集和用户购买商品的支付记录数据集进行融合,以获取实体更多的扩展信息。本文重点研究的是第一种场景。
企业传统的数据融合主要包括以下步骤:





每对接一个系统都需要经过以上繁杂的梳理、采集、加工流程,数据链路非常长、对接工作量极大,极其耗费时间,这便是人们常说的数据分析80%的时间被用于数据整合清洗。此外,随着上游系统数据不断增加或进行系统改造,已编写的清洗规则可能会失效,会造成数据准确性降低,从而引发新的数据质量问题,导致下游应用数据出现异常情况。图1所示为不同人力资源管理系统的人员基本信息表、字段差异以及根据数据标准进行层层数据加工融合的传统的企业数据融合实例。
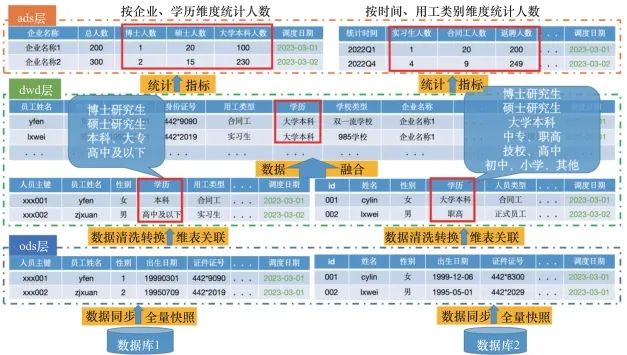
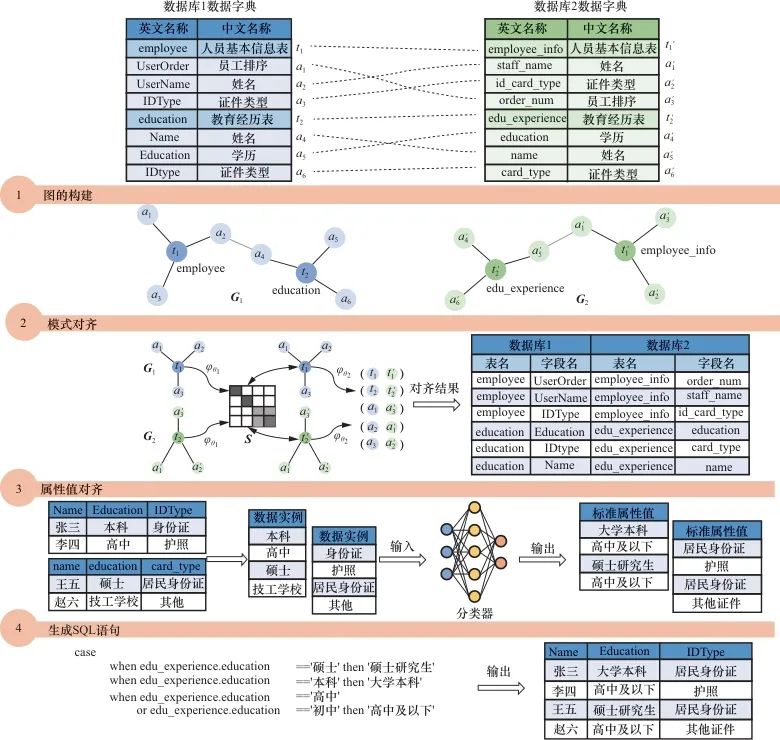
为解决传统的数据融合加工链路长、效率低的问题,本文提出了一种基于图神经网络的端到端的数据融合模型,将数据融合分成多个阶段,每个阶段负责不同的任务,通过多个模块的无缝连接构建数据融合一体化框架。具体来说,考虑到图结构能非常直观地表示出关系型数据集的结构信息和潜在的语义关系,笔者基于关系型数据集的结构内在属性将其编码为图结构,该结构形式包含表和字段两种节点类型。当表或字段中存在多个词时,其会被当作整体表示为一个节点,节点间通过关系型数据集中表结构的主外键和表与字段的包含关系进行连接。完成图结构的构建后,将图输入DGMC(deep graph matching consensus)网络中,进行表和字段实体的映射对齐,将任意两个构建好的图输入DGMC模型中,便可输出两个图中相似节点的匹配关系。图2第二步所示为将两个数据库表中的员工基本信息表和基本信息表对齐,同时将两个表中包含的字段也对齐。在表和字段实体映射对齐阶段,笔者还尝试用多种算法进行模式匹配效果对比。由于两个异构数据源中同一个字段的属性的值取值范围往往存在差异,因此在完成表和字段节点关系的匹配后,接下来需要对已对齐的属性值进行数据标准化转换,如考虑到预训练模型强大的语义表征,本文采用预训练模型Debertav3来实现数据项值与数据标准映射的对齐。找到表和字段的映射对齐关系后,再将字段对应的值与数据标准值进行映射转换,实现数据标准化。图2第三步所示为将数据表中证件类型字段值“身份证”映射为标准值“居民身份证”。最后,将前三步的结果通过工程化方法自动化输出为可执行的SQL语句,从而实现数据自动融合。
1 相关工作
数据集成包括数据清洗、关系解析、语义消歧、数据融合等技术。专家学者对以上技术的关注不断增强,其中数据融合已成为数据集成领域的关键研究方向。最早期的数据融合方法是基于规则的方法,依靠人工定义规则来确定记录是否指代同一实体,如编辑距离计算相似度、用Jaccard相似度等来计算记录间的相似度,该方法严重依赖领域专家来定义人工规则,处理异构数据时灵活性、扩展性不够强,因此学者开始引入机器学习的方法,如采用高斯混合模型、支持向量机(support vector machine,SVM)来解决实体对齐问题。FlexMatcher算法通过训练逻辑回归、KNN(k-nearest neighbor)等机器学习模型,将多个数据源的表结构映射到统一的表结构,当新数据源需要进行映射时,可用已训练好的机器学习模型将新数据源的每个字段分类到标准的字段名称。
考虑到数据本身包含一些特殊的内部结构信息,学者提出了基于图结构的向量表征方法,通过将数据转换为图结构来捕获不同属性之间与不同元组之间更丰富的语义关系,学习图节点和关系的特征向量,再基于向量相似度完成下游数据融合任务。其中,TransE将关系视为从头实体到尾实体的翻译,旨在将实体和关系映射到一个共享的向量空间中,以获取图结构中各节点和关系的低维特征向量。但该模型假设实体和关系在同一语义空间,难以捕捉复杂语义关系,例如复合关系和嵌套关系等。随后相继产生了TransH、TransR、TransD等改进模型。BootEA模型引入了自举策略和权重调整机制,通过迭代来提高对齐结果的准确性和鲁棒性,解决了初始对齐种子中存在的噪声和不完整性问题。该模型还利用翻译模型生成实体和关系嵌入,并借助一组对齐种子来协调嵌入空间,但该模型在处理复杂的多关系图和保持精确度方面存在一定的局限性。GCN-Align模型是一种基于图卷积网络(grah convolution network,GCN)的实体对齐模型,该模型首次提出利用图卷积网络生成结构和属性的特征向量,其利用图结构和对齐损失函数来提取实体的特征表示。RDGCN(reinforced dependency grah convolutional network)模型提出了一种新的关系感知双图卷积网络,通过知识图和它的对偶关系之间的密切交互来整合关系信息,通过聚合实体的邻居节点信息来更新实体的特征表示。DGMC(deep graph matching consensus)模型通过图信息传播和特征聚合来捕获图结构的信息,同时结合了局部区域特征和全局图结构特征,以更准确地进行图节点匹配。Zhao等将大规模知识库中已知实体的丰富同义名称作为训练数据,开发新型分层神经网络架构来预训练每种类型的实体匹配模型。Koutras等提出将数据库行、列和模式信息构建为图,再通过随机游走生成序列语料对模型进行训练,从而将图信息转换为可以揭示语义相似性的多维向量,并基于特征向量捕捉属性间的语义相似性来实现模式匹配。
虽然图结构能够表达关系型数据丰富的内在特征,但是图结构往往具有错误敏感性, 真实关系型数据集中的脏数据容易误导基于图结构的数据特征学习,从而导致匹配效果不佳。因此,本文提出了基于模式匹配和预训练词向量的端到端的数据融合模型,在图的构建阶段只采用了数据库表结构信息,不考虑将数据实例纳入图中,以降低数据质量低下带来的负面影响。
2 基于图结构的数据融合模型
本文设计了一套端到端的数据融合模型,通过表间主外键和表字段关系将关系型数据库结构构建成图结构,基于图神经网络将任意两个图结构的节点进行匹配,实现两个数据源间的模式匹配,再将已匹配上的字段进行数据值标准化转换,最后将每阶段输出的结构转为可执行的SQL语句,即实现了数据融合的核心步骤。本文提出的数据融合模型框架如图2所示,主要分为4步,每步形成流水线加工体系,各步的算法均可灵活替换,详细描述如下。
(1)图的构建
给定一个关系数据库字典(dictionary,D),D中包含

(2)模式对齐
数据库结构表级和属性级映射对齐,目的是将多个异构的数据源模式映射为标准模式,如图2第二步所示。将两个数据源中的人员基本信息表对齐,同时将两个表中包含的字段也对齐。通过将关系数据结构转为图输入DGMC模型,基于DGMC模型进行图模型训练,判断不同数据源表和字段属性实体之间的语义关联。DGMC模型本质上是通过学习图的向量表示,以及节点和关系的相似度,输出不同数据源表和字段属性的映射关系。
(3)属性值对齐
数据实例标准化是将不同数据源同一属性的不同属性值做标准化转换,实现数据实例值与数据标准值映射对齐,如图2第三步所示,将学历值“本科”映射为标准值“大学本科”。考虑到预训练语言模型强大的语义表征能力和数据值短文本特性,本文采用预训练模型对需要进行标准化转换的单元格值进行标准化分类,实现不同数据源属性值与数据标准值映射对齐。
(4)生成SQL语句
将第二、三步的输出结果串联起来,生成数据库可执行的SQL语句,从而实现数据融合,如图2第四步所示。
2.1 图的构建
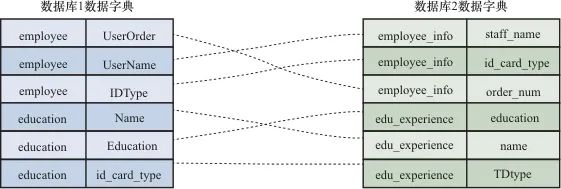
因缺乏统一的开发标准,不同业务系统的数据库模型各不相同,具体差异主要体现在事实表和维度表的设计、命名方式、数据字典的表现形式等方面。数据库字典通常以PDF、CHM、Excel等文件形式记录,预处理阶段需要将不同格式的数据库字典标准化为统一的图结构数据,通过图结构表示关系数据集中丰富的结构关系和语义信息。此步骤的输入数据为各业务系统的数据库字典,根据数据库字典中描述的表和字段的关系将其构建为网络图结构G(graph),数据库结构构建成图的实例如图3所示。其中表和字段均视为G的节点V(vertex),节点类型分为表和字段两种类型,基于数据模型主外键关系和表与字段间包含关系构成G的边E(edge),该步骤的输出为G(V,E),图G将作为模式对齐阶段的输入。
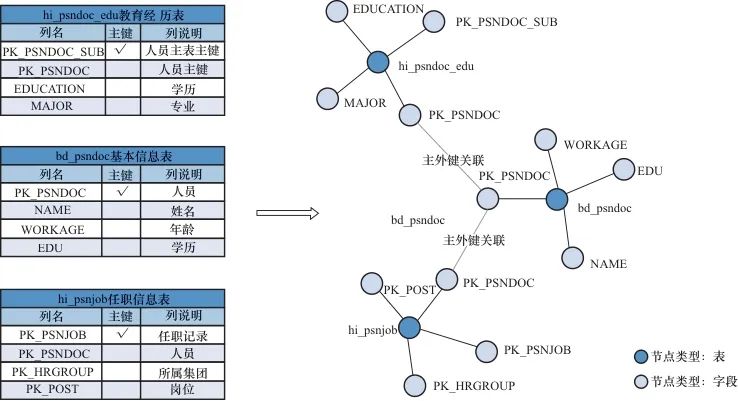
2.2 模式对齐
模式对齐是将两个系统的表、字段进行匹配对齐,本文将模式对齐问题转换为图对齐问题,即将两个图中的相关节点建立对齐关系。将需要进行对齐的图G1和图G2数据输入DGMC网络模型中,模型将输出两图节点的对齐结果。该模型的输入是待对齐的图G1=(V1,A1,X1,E1)、G2=(V2,A2,X2,E2),V表示节点集合,A表示邻接矩阵,X表示节点特征矩阵,E表示边的特征矩阵。其中,为充分利用图的特征信息,笔者采用表和字段中英文名称的预训练词向量Glove分别表示每个节点V的特征向量,使用机器翻译模型将中文名称翻译成英文,并将中英文词向量进行拼接来表示节点的特征,记为Xn×m,n为节点个数,m为拼接后的向量维度。模型主要分为以下两个阶段。第一阶段主要基于节点相似度得到初始对应关系矩阵S(0)。首先利用共享权重的图神经网络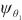
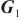
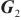
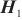
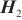
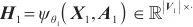 | (1) |
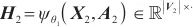 | (2) |
其中,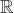
然后使用Sinkhorn算法进行熵正则化,得到初始的对应关系矩阵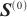
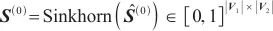 | (3) |
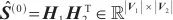 | (4) |
第二阶段主要对对应关系矩阵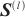
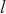
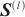
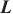
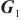
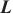
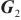
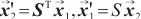 | (5) |
然后以单位矩阵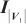
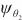
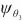
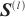
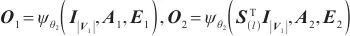 | (6) |
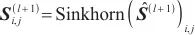 | (7) |
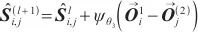 | (8) |
图4所示为两个不同人力系统的数据库表和字段的对齐结果。模型输出的映射关系字典可能并不是完全准确的,会存在映射置信度低、映射缺失和映射失败的数据项。为了提高指标对齐的准确率,在实际应用场景中,可对输出的对齐结果进行人工校正。在人工复核的过程中,仔细核查置信度低、映射缺失和映射失败的数据项的映射结果,并根据相关的业务知识和经验对未对齐的数据项进行必要的修正和调整,通过复核再次输出数据项的对齐结果,以提高映射的准确性,确保对所有数据项都进行了适当的映射。
2.3 属性值对齐
该阶段主要对数据值进行标准化的映射匹配,其主要目的是将各系统字段值的不同维度值统一为相同值,为下游数据分析统计等提供标准化的数据。考虑到实际场景中需要进行对齐的字段值通常是维度指标,维度值一般为较短的文本描述,因此,本文将数据实例中单元格对齐视为短文本分类任务,该任务基于预训练Debertav3模型来实现。Debertav3模型是一种基于BERT结构进行跨语言任务处理的模型,通过在大规模语料上进行预训练和微调,能够有效地理解和处理多语言的文本数据,因此,本文不用标注任何数据对Debertav3模型进行微调训练。
本文在采用Debertav3模型完成分类任务时,将待对齐系统对应字段的枚举值文本作为模型的输入、数据标准字段的枚举值集合作为分类的标签(label),该模型能够将不同字段枚举值映射为对应数据标准的枚举值。经过实验测试,基于Debertav3模型实现属性值对齐,能够获得较高的准确率。图5所示为属性值与数据标准映射对齐,各企业基本信息表中的学历需要根据数据标准中的学历值进行转换,如企业人员信息表中的“专科”需要映射为数据标准中的“大学专科”,“本科”需要映射为“大学本科”,“小学、初中、高中”需要映射为“高中及以下”,同理,证件类型字段需要进行同样的转换。
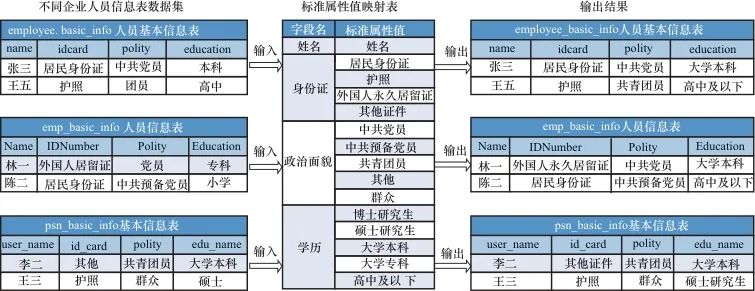
2.4 生成SQL语句
根据第二步和第三步的结果,自动生成完整的数据融合SQL语句,SQL语句的生成主要是经过以下两个步骤。
(1)条件语句的生成
首先根据数据值的对齐结果,对每个对齐的字段生成“case when then”条件语句,此时若待对齐的字段或表名为空,则将“null”作为字段值。
(2)完整语句的生成
通过获取待对齐表和字段的关系字典来获取表名,将“insert into”“from”添加到第一步的结果,最终输出数据库可执行的SQL语句。
下面用人力领域基本信息表实例来说明。经过模式对齐,可以将各个子企业系统中的基本信息表定位出来,同时通过属性值对齐找到待对齐基本信息表中各字段值与数据标准值映射关系,最终通过工程化规则生成SQL语句,数据融合SQL实例如图6所示。
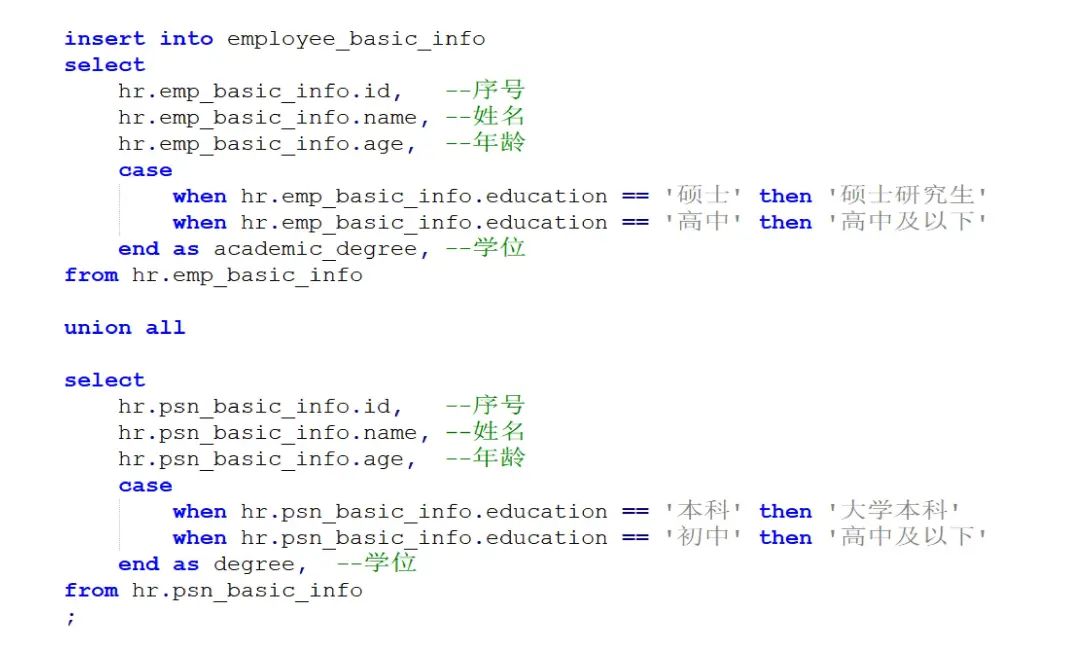
根据每个需要对齐的系统表名生成相应的数据融合SQL语句,以便后续进行数据处理和分析,自动生成SQL语句减少了手动处理的工作量,并提高了数据的一致性和规范性。此外,生成的SQL语句也为后续实现数据值对齐所需的系统间数据整合提供了方便。
3 实验结果及分析
3.1 数据集
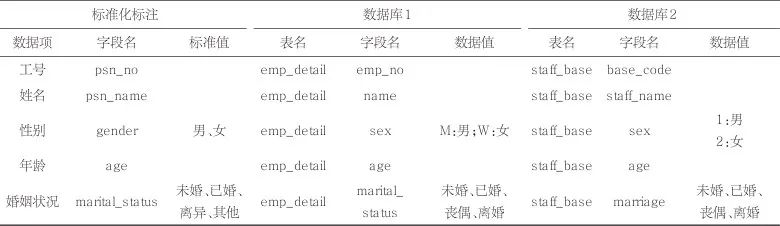
本文数据集来自企业数据融合项目的实际场景,实际场景中集团型企业需要采集多个成员企业的人力系统、财务系统、党务系统等系统数据。为了建立各成员企业同业务领域不同数据库系统中表和字段的自动匹配关系,本次实验主要抽取人力业务领域的系统进行数据标注,共涵盖了6个不同数据库系统的人力系统数据。为了测试模型的泛化能力,也抽取了其他类型的系统数据进行标注,如企业的填报系统数据。数据预处理过程中包括数据字典清洗整理、表逻辑关系梳理、数据值标准规范映射。在模式对齐阶段笔者共对76张事实表、维度表及字段进行标注,标注过程需要对不同数据库表和字段建立匹配关系,匹配关系包括表和字段的关联关系。对于每一个字段,在另外一个数据库表中找到与之对应的字段,形成对齐的实体对,将表和字段之间的包含关系表示为图的边关系。经过标注后,该数据集包含1 944个实体和1 886条边。在属性值对齐阶段,笔者为868个数据项制定数据标准,其中需要进行属性值对齐映射的有60个数据项,以便模型对属性值进行标准化处理,数据集实例见表1,各数据库表、字段、数据值均需要与标准化标注进行映射。
表1 数据集实例
3.2 评价指标
在模式对比阶段,本文采用3个评价指标对本文所提框架进行评测,分别是Hits@K(K≥1)、平均排名(mean rank,MR)和平均倒数排名(mean reciprocal rank,MRR),分别如式(9)、式(10)、式(11)所示。
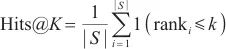 | (9) |
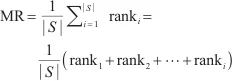 | (10) |
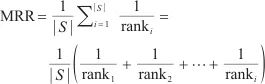 | (11) |
其中,
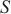
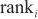
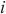
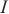

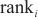
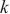
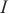

Hits@K(K≥1)表示排名前K的实体对中正确匹配的实体占真值(真正匹配的实体对的数量)的比例,Hits@K的值越高,则实体解析的精度越高。本文使用Hits@1、Hits@5和Hits@10指标来评估模型的性能。MR衡量了实体对齐结果中正确匹配的实体在排序列表中的平均位置,对于每一对实体对齐结果,记录其正确匹配的实体在排序列表中的位置,计算所有正确匹配的实体位置的平均值,MR值越小,表示实体对齐的结果较好。MRR计算所有正确匹配实体的倒数值的平均值,即将每个正确匹配的实体位置的倒数值取平均。MR和MRR都用于衡量实体对齐结果的准确性和排序性能,MRR值越大,表示实体对齐的结果较好。
3.3 实验结果和分析
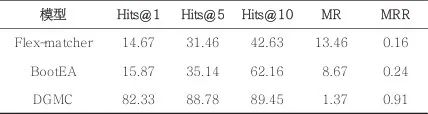
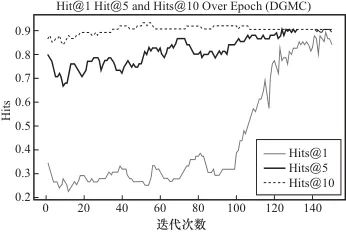
在模式对齐阶段分别对Flex-matcher、BootEA和DGMC模型进行了实验,并比较了3个模型在本文数据集上的实验效果,评测结果见表2。由表2可以看出,DGMC模型的Hits@1、Hits@5和Hits@10得分分别是82.33、88.78和89.45,均高于其他两个对比模型。MR和MRR得分分别为1.37和0.91,而Flex-matcher和BootEA模型对应的MR和MRR得分分别为13.46、0.16和8.67、0.24,可知DGMC模型的MR均小于其他两个对比模型,同时MRR值均大于其他两个对比模型。实验结果表明,DGMC模型在Hits@N、MR和MRR指标上均取得最优的效果。图7所示为DGMC模型评测结果,由图7可知,训练过程中模型的迭代次数(epoch)在140左右时,模型的性能趋于平缓,可终止迭代。
表2 评测结果
基于实验结果,本文对Flex-matcher、BootEA两个对比模型的实验效果进行简要分析。Flex-matcher模型是用于数据集成的工具,能够将多个数据源的表结构映射到统一的表结构中。然而,由于Flex-matcher模型采用传统的KNN、N-Gram等作为分类器,会存在数据不平衡、对异常值敏感等问题。此外,Flex-matcher模型仅适用于同表的多个数据源间的映射匹配,泛化能力较差,且预测效果较差。BootEA模型是基于嵌入的实体对齐方法,通过TransE来获取图结构属性,将不同系统的嵌入都统一到一个向量空间中,能在一定程度上捕捉到实体间的语义信息和图节点间相似性,但其建模能力较弱,并且基于TransE翻译假设的BootEA模型可能会将实体间的语义相似性视为结构相似性,导致模型给出不准确的对齐结果,预测效果也较差。
本文提出的数据融合框架集图构建、模式对齐和属性值对齐等为一体,在数据融合任务上具有一定的有效性,它能够根据不同系统的数据结构和数据字典自动实现表和字段的对齐,进一步生成相应的SQL语句,从而实现数据的一致性和统一性,对于处理异构数据具有重要意义。
4 结束语
本文提出的基于图的异构数据融合模型能有效地解决不同系统之间的数据集成问题,该模型将数据融合拆分为图的构建、模式对齐、属性值对齐和生成SQL语句4个组件,每个组件均可用不同的模型进行替换,灵活性较强,后续可尝试用更多的算法替换不同的组件。该模型引入了图神经网络,通过关联数据库中各表的字段来构建图数据,输入图神经网络模型来实现不同系统的表和字段的自动匹配,能够将各业务系统中指代同一实体的记录连接起来。基于预训练语言模型将不同系统中的属性值按照数据标准进行映射分类,能够消除不同系统中同一实体属性值的差异,最后输出数据合并的SQL语句。实验结果表明,该模型在处理异构系统数据融合问题上具有较高的准确性,相较传统的手工融合,该模型能够在一定程度上提高数据融合的效率,减少手工处理的工作量,对企业数据融合具有重要的借鉴意义,并且不受领域限制,具备广泛的适用性。
本文仅通过数据库模式关系构建了网络图数据进行训练,但现实场景中数据库表间的逻辑关系不完整,需要人工梳理数据库表间的逻辑关系,该任务需要具备一定的技术基础,数据获取存在一定的难度。下一步可将每个列的属性值引入图中,以丰富图数据的语义关系,减少对数据库模式的依赖,通过充分利用已有数据值,进一步提高数据融合模型的性能。
作者简介
黄跃珍(1973-),男,博士,广州数字科技集团有限公司党委书记、董事长,主要研究方向为多模态身份识别、公共数据运营、人工智能等。
杨芬(1991-),女,广州广电运通信息科技有限公司数据分析师,主要研究方向为数据治理运营、自然语言处理、知识图谱等。
田丰(1975-),男,广电运通集团股份有限公司研究总院院长,主要研究方向为数字底座技术、人工智能、大数据等。
张承业(1985-),男,博士,广州广电运通信息科技有限公司总经理助理,主要研究方向为数据底座技术、大数据平台技术、政企数字化转型研究等。
李雨婵(1998-),女,广州广电运通信息科技有限公司数据分析师,主要研究方向为数据治理、深度学习、可视化分析等。
联系我们:
Tel:010-53879208
010-53859533
E-mail:[email protected]
http://www.j-bigdataresearch.com.cn/
转载、合作:010-53878078
大数据期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的期刊,已成功入选中国科技核心期刊、中国计算机学会会刊、中国计算机学会推荐中文科技期刊,以及信息通信领域高质量科技期刊分级目录、计算领域高质量科技期刊分级目录,并多次被评为国家哲学社会科学文献中心学术期刊数据库“综合性人文社会科学”学科最受欢迎期刊。

关注《大数据》期刊微信公众号,获取更多内容