引言:AI模型的"减肥革命"
在深度学习领域,模型参数量正以每年10倍的速度膨胀。GPT-3的1750亿参数震惊业界的同时,也暴露出算力消耗和部署成本的困境。当我们用4090显卡都难以流畅运行Stable Diffusion时,模型压缩技术便成为破局关键。本文将深入解析两大核心技术——蒸馏(Distillation)与量化(Quantization),揭开它们让模型"瘦身"却保持"智慧"的奥秘。
(图示:从2015年Hinton提出蒸馏到2023年FP8标准确立的技术演进)
一、知识蒸馏:让大模型"言传身教"的哲学
1.1 蒸馏技术的生物启发
就像酿酒师通过蒸馏提取精华,知识蒸馏(Knowledge Distillation)通过建立"师生模型"的知识传递机制,将庞大教师模型(Teacher Model)的决策智慧,浓缩到轻量学生模型(Student Model)中。
核心公式:
总损失函数 = α * 软目标损失 + (1-α) * 硬目标损失
其中软目标由教师模型输出经温度系数T软化:
q
i
=
e
x
p
(
z
i
/
T
)
∑
j
e
x
p
(
z
j
/
T
)
q_i = \frac{exp(z_i/T)}{\sum_j exp(z_j/T)}
qi=∑jexp(zj/T)exp(zi/T)
L
(
硬目标
)
=
−
∑
(
y
i
∗
l
o
g
(
p
i
)
)
L(硬目标) = -∑(y_i * log(p_i))
L(硬目标)=−∑(yi∗log(pi))
其中:
y_i 是真实标签的one-hot编码
p_i 是模型预测的概率分布
log是自然对数
1.2 蒸馏技术的三次进化
- 第一代:2015年Hinton经典蒸馏(NIPS论文)
- 第二代:2018年特征蒸馏(FitNets突破)
- 第三代:2021年动态蒸馏(DynaBERT实现结构自适应)
工业级实践:
- BERT蒸馏后模型缩小7倍,速度提升9倍(Google实践数据)
- 视觉Transformer蒸馏精度损失<1%,参数量减少60%(DeiT方案)
二、量化技术:模型参数的"数据压缩术"
2.1 量化的数学本质
将32位浮点数(FP32)用更低比特数表示,本质是在数值精度与存储效率间寻找帕累托最优解。
量化过程数学表达:
Q
(
x
)
=
r
o
u
n
d
(
x
/
Δ
)
+
Z
Δ
Q(x) = \frac{round(x/\Delta) + Z}{\Delta}
Q(x)=Δround(x/Δ)+Z
其中Δ为缩放因子,Z为零点偏移
2.2 主流量化格式解析
| 格式 | 位宽 | 动态范围 | 典型场景 | 硬件支持 |
|---|---|---|---|---|
| FP32 | 32 | 1e-38~1e38 | 训练 | 通用GPU |
| BF16 | 16 | 1e-5~1e38 | 混合精度训练 | Ampere架构 |
| FP16 | 16 | 5e-5~65504 | 推理 | Volta+架构 |
| FP8 | 8 | 自定义 | Transformer推理 | Hopper架构 |
| INT8 | 8 | -128~127 | 边缘设备部署 | 专用NPU |
关键突破点:
- BF16:保留指数位与FP32一致,避免梯度消失(NVIDIA A100首发支持)
- FP8:E5M2与E4M3两种格式的动态平衡(2022年NVIDIA H100实现)
- INT8:配合校准集进行动态量化(TensorRT典型方案)
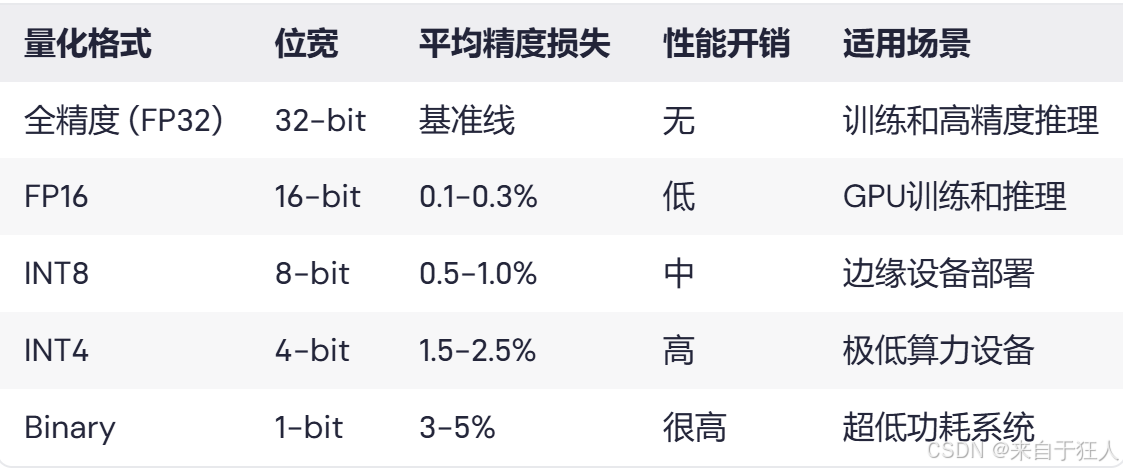
(表示:不同量化格式在MNIST数据集上的精度损失对比)
三、技术融合:蒸馏+量化的化学反应
3.1 联合优化策略
- 预蒸馏后量化:先压缩模型结构,再降低参数精度
- 量化感知蒸馏:在蒸馏过程中模拟量化噪声(QAT)
- 动态混合精度:不同层使用不同量化策略(Meta的LLM.int8())
案例研究:
- DistilBERT + INT8量化:模型体积缩小12倍,推理速度提升15倍
- ViT-Tiny + FP8:在Jetson Orin上实现实时4K图像处理
3.2 前沿技术突破
- 稀疏化蒸馏:2023年Google提出Block Movement Pruning
- 非对称量化:微软的ZeroQuant-V2实现4bit量化
- 神经架构搜索:AutoDistill自动寻找最优压缩路径
四、实战指南:如何选择优化方案
4.1 技术选型决策树
4.2 性能指标对照表
| 技术组合 | 压缩率 | 精度损失 | 硬件需求 | 开发成本 |
|---|---|---|---|---|
| 基础蒸馏+FP16 | 3-5x | <1% | 中 | 低 |
| 深度蒸馏+INT8 | 10-15x | 1-3% | 高 | 高 |
| 量化感知训练 | 8-12x | 0.5-2% | 极高 | 极高 |
五、未来展望:通向1bit量化的终极之路
-
2024趋势预测:
- FP6成为新训练标准
- 3D堆叠存储实现存内计算
- 光子芯片突破传统量化限制
-
量子化启示:
最新研究显示,通过量子纠缠原理进行参数编码,可能突破经典香农极限,这或许将引发下一场模型压缩革命。
结语:效率与智慧的平衡艺术
在算力军备竞赛的今天,模型优化技术已成为AI落地的胜负手。当我们用INT8在智能手表上运行BERT,用FP8在无人机实现实时语义分割时,这场静悄悄的效率革命正在重塑AI的应用边界。理解这些技术背后的数学之美,或许就是打开下一代智能系统的钥匙。
延伸阅读:
- [Hinton经典论文《Distilling the Knowledge in a Neural Network》]
- [NVIDIA白皮书《8-bit Floating Point: The Next AI Datatype》]
- [Google最新研究《The Era of 1-bit LLMs》]