A u t o f o r m e r Autoformer Autoformer
摘要
我们设计了 A u t o f o r m e r Autoformer Autoformer作为一种新型分解架构,带有自相关机制。我们打破了序列分解的预处理惯例,并将其革新为深度模型的基本内部模块。这种设计使 A u t o f o r m e r Autoformer Autoformer具备了对复杂时间序列的渐进分解能力。进一步地,受随机过程理论的启发,我们基于序列周期性设计了自相关机制,它在子序列级别进行依赖关系的发现和表示聚合。在效率和准确性方面,自相关机制都优于自注意力机制。
1.简介
最近的深度预测模型已经取得了很大的进展,特别是基于变压器的模型。得益于自关注机制,变压器在对序列数据的长期依赖关系建模方面具有很大的优势,这使得更强大的大模型成为可能。我们尝试利用序列的周期性来更新自关注中的点向连接。观察到,周期之间处于相同相位位置的子序列往往呈现相似的时间过程。因此,尝试基于序列周期性导出的过程相似性构建一个序列级连接。
提出了一个原始的自耦器来代替变压器进行长期时间序列预测。自耦器仍然沿用残差和编解码器结构,但将变压器改造为分解预测结构。通过嵌入我们提出的分解块作为内部算子,自耦器器可以逐步从预测的隐藏变量中分离出长期趋势信息。这种设计允许我们的模型在预测过程中交替分解和细化中间结果。受随机过程理论的启发,自耦器引入了自相关机制来代替自关注,该机制基于序列的周期性发现子序列的相似性,并从底层周期中聚合相似的子序列。这种序列智能机制为长度为 L L L的序列实现了 O ( L l o g L ) O(L log L) O(LlogL)复杂度,并通过将逐点表示聚合扩展到子序列级别来打破信息利用瓶颈。自耦器在六个基准上达到了最先进的精度。贡献总结如下:
- 为了解决长期未来复杂的时间模式,我们提出了自耦器作为一个分解架构,并设计了内部分解块,以赋予深度预测模型具有内在的渐进分解能力。
- 我们提出了一种自相关机制,在序列级别上具有依赖性发现和信息聚合。我们的机制超越了以前的自关注家族,可以同时有利于计算效率和信息利用率。
- 在六个基准的长期设定下,自耦器实现了38%的相对改进,涵盖了五个实际应用:能源、交通、经济、天气和疾病。
2.相关工作
- 提出的自相关机制基于时间序列的固有周期性,可以提供序列明智的连接。
- 自耦器利用分解作为深度模型的内部块,可以在整个预测过程中逐步分解隐藏序列,包括过去的序列和预测的中间结果。
3.Autoformer
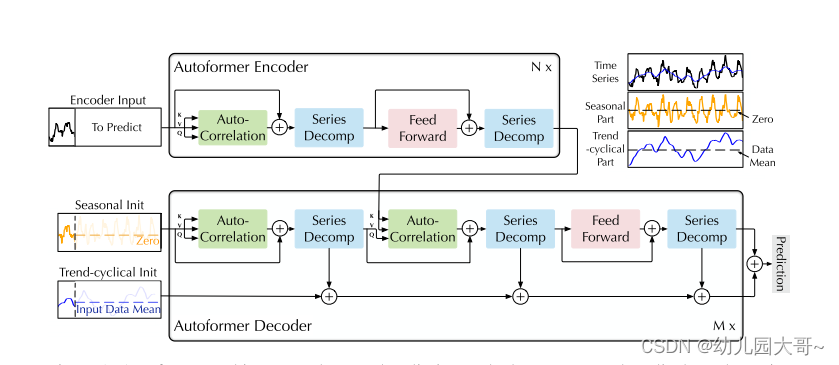
将 T r a n s f o r m e r Transformer Transformer改造为一个深度分解架构,包括内部的系列分解块、自相关机制以及相应的编码器和解码器。
序列分解模块:
该模块的目的是将输入的时间序列分解为趋势周期部分和季节性部分,以便更好地进行长期预测。由于未来是未知的,因此该模块通过对预测的中间隐藏变量进行处理来提取长期稳定的趋势。具体方法是使用移动平均法,通过填充操作保持序列长度不变。最终,该模块输出分解后的季节性部分和趋势周期部分。
采用移动平均法来平滑周期性波动,并突出长期趋势。对于长度为
L
L
L的输入序列
X
∈
R
L
×
d
X \in \mathbb{R}^{L \times d}
X∈RL×d,其过程如下:
X
t
=
AvgPool
(
Padding
(
X
)
)
X
s
=
X
−
X
t
方程一
X_t = \text{AvgPool}(\text{Padding}(X))\\ X_s = X - X_t\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\方程一
Xt=AvgPool(Padding(X))Xs=X−Xt 方程一
其中, X s X_s Xs和 X t ∈ R L × d X_t ∈ \mathbb{R}^{L \times d} Xt∈RL×d分别表示季节性和提取的趋势周期部分。我们采用带有填充操作的 A v g P o o l ( ⋅ ) AvgPool(·) AvgPool(⋅)进行移动平均,以保持序列长度不变。我们用 X s , X t = S e r i e s D e c o m p ( X ) Xs, Xt = SeriesDecomp(X) Xs,Xt=SeriesDecomp(X)来总结上述方程,这是一个模型内部模块。
详细解释:
上述描述讲述了一种时间序列分解方法,通过移动平均法来平滑周期性波动并突出长期趋势。为了更好地理解和实现该方法,我们可以将步骤细分如下:
-
填充操作 (Padding):在进行移动平均之前,我们需要对序列进行填充,以确保边缘数据也能被平滑处理。填充操作通常是对序列的前后添加额外的数据点,这些点可以是序列的首尾数据点的复制或者其他合适的填充方法。
-
移动平均 (AvgPool):移动平均法通过对一定窗口内的数据进行平均,从而平滑掉短期波动,突出长期趋势。在实现中,通常使用池化操作 (pooling),例如平均池化 (average pooling)。移动平均详解
-
分解时间序列:根据上述公式,通过移动平均得到的序列 X t X_t Xt代表提取的趋势部分,原序列 X X X减去趋势部分 X t X_t Xt得到季节性部分 X s X_s Xs。
具体的实现步骤如下:
import numpy as np
import pandas as pd
def padding(X, pad_width):
"""
对时间序列进行填充操作。
X: 输入的时间序列,形状为 (L, d)
pad_width: 填充的宽度
"""
return np.pad(X, ((pad_width, pad_width), (0, 0)), mode='edge')
def avg_pooling(X, window_size):
"""
进行移动平均操作。
X: 填充后的时间序列,形状为 (L + 2*pad_width, d)
window_size: 移动平均的窗口大小
"""
return pd.DataFrame(X).rolling(window=window_size, center=True).mean().values
def series_decomp(X, window_size):
"""
时间序列分解函数。
X: 输入的时间序列,形状为 (L, d)
window_size: 移动平均的窗口大小
"""
L, d = X.shape
pad_width = window_size // 2
# 步骤1:填充操作
X_padded = padding(X, pad_width)
# 步骤2:移动平均
X_t = avg_pooling(X_padded, window_size)[pad_width:-pad_width]
# 步骤3:分解时间序列
X_s = X - X_t
return X_s, X_t
# 示例输入
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6], [6, 7], [7, 8]])
window_size = 3
# 调用分解函数
X_s, X_t = series_decomp(X, window_size)
print("季节性部分:\n", X_s)
print("趋势周期部分:\n", X_t)
在这个示例中,我们对输入的时间序列 X X X进行填充,并使用平均池化方法来平滑数据,最后分解出季节性部分和趋势周期部分。这些步骤体现了上述方程的具体实现。
模型输入
编码器的输入是过去
I
I
I个时间步的
X
e
n
∈
R
I
×
d
Xen ∈ R^{I×d}
Xen∈RI×d。作为一个分解架构,
A
u
t
o
f
o
r
m
e
r
Autoformer
Autoformer解码器的输入包含两部分:季节性部分
X
d
e
s
∈
R
(
I
/
2
+
O
)
×
d
X_{des} ∈ R^{(I/2+O)×d}
Xdes∈R(I/2+O)×d和趋势周期部分
X
d
e
t
∈
R
(
I
/
2
+
O
)
×
d
X_{det} ∈ R^{(I/2+O)×d}
Xdet∈R(I/2+O)×d,这些部分需要被细化。每个初始化包含两部分:一部分是从编码器输入
X
e
n
X_{en}
Xen的后半部分(长度为
I
/
2
I/2
I/2)分解得到的组件以提供近期信息,另一部分是长度为
O
O
O的占位符,用标量填充。具体数学公式如下:
Xens
,
Xent
=
SeriesDecomp
(
Xen
I
2
:
I
)
Xdes
=
Concat
(
Xens
,
X
0
)
Xdet
=
Concat
(
Xent
,
XMean
)
方程二
\begin{align*} \text{Xens}, \text{Xent} &= \text{SeriesDecomp}(\text{Xen}_{\frac{I}{2}:I}) \\ \text{Xdes} &= \text{Concat}(\text{Xens}, \text{X}_0) \\ \text{Xdet} &= \text{Concat}(\text{Xent}, \text{XMean}) \end{align*}\ \ \ \ \ \ \ \ \ \ \ \ \ 方程二
Xens,XentXdesXdet=SeriesDecomp(Xen2I:I)=Concat(Xens,X0)=Concat(Xent,XMean) 方程二
其中, X e n s , X e n t ∈ R I / 2 × d X_{ens}, X_{ent} ∈ R^{I/2×d} Xens,Xent∈RI/2×d分别表示 X e n X_{en} Xen的季节性和趋势周期部分,而 X 0 , X M e a n ∈ R O × d X_0, X_{Mean} ∈ R^{O×d} X0,XMean∈RO×d分别表示用零填充的占位符和 X e n X_{en} Xen的均值。
详细解释:
具体操作步骤如下:
- 分解时间序列:
- 使用
SeriesDecomp函数对输入序列的后半部分进行分解,得到季节性部分 X e n s X_{ens} Xens和趋势周期部分 X e n t X_{ent} Xent。
- 使用
- 构建解码器的输入:
- 时间步长为I的 X e n X_{en} Xen,其维度是 I ∗ d I*d I∗d;
- 构建解码器的输入:
- 通过将分解得到的季节性部分 X e n s X_{ens} Xens与长度为 O O O的零占位符 X 0 X_0 X0进行拼接,得到 X d e s X_{des} Xdes。
- 通过将分解得到的趋势周期部分 X e n t X_{ent} Xent与长度为 O O O的均值占位符 X M e a n X_{Mean} XMean进行拼接,得到 X d e t X_{det} Xdet。
具体操作的Python代码实现如下:
import numpy as np
def series_decomp(X):
"""
对输入时间序列进行分解,提取季节性部分和趋势周期部分。
这里假设 SeriesDecomp 已经实现。
"""
# 示例实现:直接返回两个分量
# 实际实现需要根据具体算法进行
seasonal_part = ... # 分解得到的季节性部分
trend_part = ... # 分解得到的趋势周期部分
return seasonal_part, trend_part
def prepare_decoder_inputs(Xen, I, O):
"""
准备 Autoformer 解码器的输入。
Xen: 输入的时间序列,形状为 (I, d)
I: 过去时间步的数量
O: 占位符的长度
"""
# 分解输入序列的后半部分
Xen_half = Xen[I//2:I]
Xens, Xent = series_decomp(Xen_half)
# 构建零占位符和均值占位符
X0 = np.zeros((O, Xen.shape[1]))
XMean = np.full((O, Xen.shape[1]), Xen.mean(axis=0))
# 拼接得到解码器的输入
Xdes = np.concatenate((Xens, X0), axis=0)
Xdet = np.concatenate((Xent, XMean), axis=0)
return Xdes, Xdet
# 示例输入
I = 10
O = 5
Xen = np.random.randn(I, 3) # 假设输入序列形状为 (I, d)
# 准备解码器输入
Xdes, Xdet = prepare_decoder_inputs(Xen, I, O)
print("季节性部分解码器输入:\n", Xdes)
print("趋势周期部分解码器输入:\n", Xdet)
这个代码实现了将输入时间序列分解并准备解码器输入的过程。SeriesDecomp 函数需要根据具体的分解算法进行实现,示例中假设该函数已经实现。解码器输入的构建通过拼接分解得到的部分与占位符来完成。
编码器
编码器专注于季节性部分的建模。编码器的输出包含过去的季节性信息,并将作为交叉信息来帮助解码器细化预测结果。假设我们有
N
N
N个编码器层。第
l
l
l个编码器层的整体方程可以总结为
X
l
en
=
Encoder
(
X
l
−
1
en
)
X_l^{\text{en}} = \text{Encoder}(X_{l-1}^{\text{en}})
Xlen=Encoder(Xl−1en)。具体细节如下:
S
e
n
l
,
1
,
‾
=
S
e
r
i
e
s
D
e
c
o
m
p
(
A
u
t
o
−
C
o
r
r
e
l
a
t
i
o
n
(
X
e
n
l
−
1
)
+
X
e
n
l
−
1
)
S
e
n
l
,
2
,
‾
=
S
e
r
i
e
s
D
e
c
o
m
p
(
F
e
e
d
F
o
r
w
a
r
d
(
S
e
n
l
,
1
)
+
S
e
n
l
,
1
)
方程三
S_{en}^{l,1},\underline{}=SeriesDecomp(Auto-Correlation(X_{en}^{l-1})+X_{en}^{l-1})\\S_{en}^{l,2},\underline{}=SeriesDecomp(FeedForward(S_{en}^{l,1})+S_{en}^{l,1}) \ \ \ \ \ 方程三
Senl,1,=SeriesDecomp(Auto−Correlation(Xenl−1)+Xenl−1)Senl,2,=SeriesDecomp(FeedForward(Senl,1)+Senl,1) 方程三
其中,
′
‾
′
'\underline\ \ '
′ ′表示被消除的趋势部分。
X
e
n
l
X_{en}^l
Xenl是第
l
l
l个编码器层的输出,
X
e
n
0
X_{en}^0
Xen0是
X
e
n
X_{en}
Xen的嵌入表示。
S
e
n
l
,
i
,
i
∈
{
1
,
2
}
S_{en}^{l,i},i∈\{1,2\}
Senl,i,i∈{1,2},分别表示第
l
l
l层中第
i
i
i个序列分解块之后的季节性组件。我们将在下一节中详细描述
A
u
t
o
−
C
o
r
r
e
l
a
t
i
o
n
(
⋅
)
Auto-Correlation(·)
Auto−Correlation(⋅),它可以无缝地替代自注意力机制。
详细解释:
编码器主要关注于季节性部分的建模。它的输出包含过去的季节性信息,并将作为交叉信息来帮助解码器做出预测。假设我们有 N 个编码器层。第 l 个编码器层的整体方程可以总结为 X e n l = Encoder ( X e n l − 1 ) X^l_{en} = \text{Encoder}(X^{l-1}_{en}) Xenl=Encoder(Xenl−1)。具体细节如下:
-
第一步:使用
Auto-Correlation方法和之前的编码器输出 X e n l − 1 X^{l-1}_{en} Xenl−1对输入进行处理,得到第 l 层编码器的第一个分解结果 S e n l , 1 S^{l,1}_{en} Senl,1。公式: S e n l , 1 = SeriesDecomp ( Auto-Correlation ( X e n l − 1 ) + X e n l − 1 ) S^{l,1}_{en} = \text{SeriesDecomp}(\text{Auto-Correlation}(X^{l-1}_{en}) + X^{l-1}_{en}) Senl,1=SeriesDecomp(Auto-Correlation(Xenl−1)+Xenl−1)
-
第二步:将第一个分解结果 S e n l , 1 S^{l,1}_{en} Senl,1通过一个前馈网络 FeedForward ( ⋅ ) \text{FeedForward}(·) FeedForward(⋅)进行处理,并进行第二次分解,得到第 l 层编码器的第二个分解结果 S e n l , 2 S^{l,2}_{en} Senl,2。
公式: S e n l , 2 = SeriesDecomp ( FeedForward ( S e n l , 1 ) + S e n l , 1 ) S^{l,2}_{en} = \text{SeriesDecomp}(\text{FeedForward}(S^{l,1}_{en}) + S^{l,1}_{en}) Senl,2=SeriesDecomp(FeedForward(Senl,1)+Senl,1)
这里,SeriesDecomp 表示时间序列分解操作,Auto-Correlation(·) 是一个用来替代自注意力机制的运算。
具体操作实现
下面是一个具体操作的实现细节,使用Python代码实现上述两个步骤:
import numpy as np
def auto_correlation(X):
"""
Auto-Correlation方法的示例实现。
实际实现需要根据具体的算法进行。
"""
# 示例实现:直接返回输入
return X
def feed_forward(X):
"""
前馈网络的示例实现。
实际实现可以包括多个全连接层和激活函数。
"""
# 示例实现:直接返回输入
return X
def series_decomp(X):
"""
对输入时间序列进行分解,提取季节性部分和趋势周期部分。
这里假设 SeriesDecomp 已经实现。
"""
# 示例实现:直接返回两个分量
# 实际实现需要根据具体算法进行
seasonal_part = ... # 分解得到的季节性部分
trend_part = ... # 分解得到的趋势周期部分
return seasonal_part, trend_part
def encoder_layer(X_prev):
"""
单层编码器操作。
X_prev: 上一层编码器的输出
"""
# 第一步:Auto-Correlation 和分解
auto_corr_result = auto_correlation(X_prev) + X_prev
S_l1_en, _ = series_decomp(auto_corr_result)
# 第二步:前馈网络和分解
feed_forward_result = feed_forward(S_l1_en) + S_l1_en
S_l2_en, _ = series_decomp(feed_forward_result)
return S_l2_en
# 示例输入
I = 10
X_prev = np.random.randn(I, 3) # 假设输入序列形状为 (I, d)
# 调用编码器层操作
X_next = encoder_layer(X_prev)
print("编码器输出:\n", X_next)
这个代码展示了如何实现一个编码器层的具体操作。首先通过 Auto-Correlation 方法处理输入,然后进行第一次分解。接着通过前馈网络处理第一次分解结果,并进行第二次分解。最终得到编码器的输出。SeriesDecomp、Auto-Correlation 和 FeedForward 函数需要根据具体算法进行实现,这里提供了一个简单的示例实现。
解码器
解码器包含两个部分:用于趋势周期分量的累积结构,以及用于季节组分的堆叠自相关机制。每个解码器层都包含内部自相关和编码器-解码器自相关,这可以分别细化预测并利用过去的季节信息。模型在解码过程中从中间的隐藏变量中提取潜在趋势,允许
A
u
t
o
f
o
r
m
e
r
Autoformer
Autoformer逐步细化趋势预测,并消除在自相关中发现基于周期的依赖关系时的干扰信息。假设有
M
M
M个解码器层。利用来自编码器的潜变量
X
e
n
N
X_{en}^N
XenN,第
l
l
l个解码器层的方程可以总结为
X
d
e
l
=
D
e
c
o
d
e
r
(
X
d
e
l
−
1
,
X
e
n
N
)
X_{de}^l=Decoder(X_{de}^{l-1},X_{en}^N)
Xdel=Decoder(Xdel−1,XenN)。解码器可以形式化如下:
S
l
,
1
d
e
,
T
l
,
1
d
e
=
SeriesDecomp (Auto-Correlation
(
X
l
−
1
d
e
)
+
X
l
−
1
d
e
)
S
l
,
2
d
e
,
T
l
,
2
d
e
=
SeriesDecomp (Auto-Correlation
(
S
l
,
1
d
e
,
X
N
e
n
)
+
S
l
,
1
d
e
)
S
l
,
3
d
e
,
T
l
,
3
d
e
=
SeriesDecomp (FeedForward
(
S
l
,
2
d
e
)
+
S
l
,
2
d
e
)
T
l
d
e
=
T
l
−
1
d
e
+
W
l
,
1
∗
T
l
,
1
d
e
+
W
l
,
2
∗
T
l
,
2
d
e
+
W
l
,
3
∗
T
l
,
3
d
e
方程四
\begin{align*} S_{l,1}^{de}, T_{l,1}^{de} &= \text{SeriesDecomp (Auto-Correlation}(X_{l-1}^{de})+X_{l-1}^{de}) \\ S_{l,2}^{de}, T_{l,2}^{de} &= \text{SeriesDecomp (Auto-Correlation}(S_{l,1}^{de},X_N^{en})+S_{l,1}^{de}) \\ S_{l,3}^{de}, T_{l,3}^{de} &= \text{SeriesDecomp (FeedForward}(S_{l,2}^{de})+S_{l,2}^{de}) \\ T_{l}^{de} &= T_{l-1}^{de} + W_{l,1} \ast T_{l,1}^{de}+ W_{l,2} \ast T_{l,2}^{de}+W_{l,3} \ast T_{l,3}^{de} \\ \end{align*}\ \ \ \ \ \ \ \ \ 方程四
Sl,1de,Tl,1deSl,2de,Tl,2deSl,3de,Tl,3deTlde=SeriesDecomp (Auto-Correlation(Xl−1de)+Xl−1de)=SeriesDecomp (Auto-Correlation(Sl,1de,XNen)+Sl,1de)=SeriesDecomp (FeedForward(Sl,2de)+Sl,2de)=Tl−1de+Wl,1∗Tl,1de+Wl,2∗Tl,2de+Wl,3∗Tl,3de 方程四
其中,
X
d
e
l
=
S
d
e
l
,
3
,
l
∈
{
1
,
.
.
.
,
M
}
X_{de}^l=S_{de}^{l,3},l\in\{1,...,M\}
Xdel=Sdel,3,l∈{1,...,M}表示第
l
l
l层解码器的输出。
X
0
d
e
X_0^{de}
X0de 是从
X
d
e
s
X_{des}
Xdes 中嵌入的,用于深度变换,而
T
0
d
e
=
X
d
e
t
T_0^{de} = X_{det}
T0de=Xdet 用于累积。
S
l
,
i
d
e
S_{l,i}^{de}
Sl,ide 和
T
l
,
i
d
e
T_{l,i}^{de}
Tl,ide,其中
i
∈
{
1
,
2
,
3
}
i ∈ \{1, 2, 3\}
i∈{1,2,3},分别表示在第
l
l
l 层中经过第
i
i
i 个序列分解块后的季节组分和趋势-周期组分。
W
l
,
i
W_{l,i}
Wl,i,其中
i
∈
{
1
,
2
,
3
}
i ∈ \{1, 2, 3\}
i∈{1,2,3},表示第
i
i
i 个提取的趋势
T
l
,
i
d
e
T_{l,i}^{de}
Tl,ide 的投影器。
最终的预测是这两个细化后的分解组分的和,即 W S ∗ X M d e + T M d e W_S * X_M^{de} + T_M^{de} WS∗XMde+TMde,其中 W S W_S WS 是将深度变换后的季节组分 X M d e X_M^{de} XMde 投影到目标维度的投影器。
详细解释:
解码器包含两个部分:用于趋势周期分量的累积结构,以及用于季节性分量的堆叠自相关机制。每个解码器层都包含内部自相关和编码器-解码器自相关,这可以分别细化预测并利用过去的季节性信息。模型在解码过程中从中间的隐藏变量中提取潜在趋势,允许Autoformer逐步细化趋势预测,并消除在自相关中发现基于周期的依赖关系时的干扰信息。
假设有 M M M个解码器层。利用来自编码器的潜变量 X e n N X^N_{en} XenN,第 l l l个解码器层的方程可以总结为 X d e l = Decoder ( X d e l − 1 , X e n N ) X^l_{de} = \text{Decoder}(X^{l-1}_{de}, X^N_{en}) Xdel=Decoder(Xdel−1,XenN)。解码器可以形式化如下:
-
第一步:
S l , 1 d e , T l , 1 d e = SeriesDecomp ( Auto-Correlation ( X l − 1 d e ) + X l − 1 d e ) S^{de}_{l,1}, T^{de}_{l,1} = \text{SeriesDecomp}(\text{Auto-Correlation}(X^{de}_{l-1}) + X^{de}_{l-1}) Sl,1de,Tl,1de=SeriesDecomp(Auto-Correlation(Xl−1de)+Xl−1de)
使用Auto-Correlation方法和之前的解码器输出 X l − 1 d e X^{de}_{l-1} Xl−1de对输入进行处理,并进行第一次分解。 -
第二步:
S l , 2 d e , T l , 2 d e = SeriesDecomp ( Auto-Correlation ( S l , 1 d e , X e n N ) + S l , 1 d e ) S^{de}_{l,2}, T^{de}_{l,2} = \text{SeriesDecomp}(\text{Auto-Correlation}(S^{de}_{l,1}, X^N_{en}) + S^{de}_{l,1}) Sl,2de,Tl,2de=SeriesDecomp(Auto-Correlation(Sl,1de,XenN)+Sl,1de)
使用Auto-Correlation方法将第一个分解结果 S l , 1 d e S^{de}_{l,1} Sl,1de和编码器的输出 X e n N X^N_{en} XenN结合起来进行处理,并进行第二次分解。 -
第三步:
S l , 3 d e , T l , 3 d e = SeriesDecomp ( FeedForward ( S l , 2 d e ) + S l , 2 d e ) S^{de}_{l,3}, T^{de}_{l,3} = \text{SeriesDecomp}(\text{FeedForward}(S^{de}_{l,2}) + S^{de}_{l,2}) Sl,3de,Tl,3de=SeriesDecomp(FeedForward(Sl,2de)+Sl,2de)
将第二次分解结果 S l , 2 d e S^{de}_{l,2} Sl,2de通过一个前馈网络 FeedForward ( ⋅ ) \text{FeedForward}(·) FeedForward(⋅)进行处理,并进行第三次分解。 -
第四步:
T I l = T l − 1 d e + W l , 1 ∗ T l , 1 d e + W l , 2 ∗ T l , 2 d e + W l , 3 ∗ T l , 3 d e T^l_I = T^{de}_{l-1} + W_{l,1} * T^{de}_{l,1} + W_{l,2} * T^{de}_{l,2} + W_{l,3} * T^{de}_{l,3} TIl=Tl−1de+Wl,1∗Tl,1de+Wl,2∗Tl,2de+Wl,3∗Tl,3de
累积和加权组合趋势周期分量,得到最终的趋势部分 T I l T^l_I TIl。
最终的预测是这两个细化后的分解结果的和,即 W s ∗ X d e s + T I l W_s * X^s_{de} + T^l_I Ws∗Xdes+TIl,其中 W s W_s Ws是将深度变换后的季节部分 X d e s X^s_{de} Xdes投影到目标维度的投影器。
具体操作实现
下面是一个具体操作的实现细节,使用Python代码实现上述四个步骤:
import numpy as np
def auto_correlation(X, Y=None):
"""
Auto-Correlation方法的示例实现。
实际实现需要根据具体的算法进行。
"""
if Y is None:
Y = X
# 示例实现:直接返回输入
return X + Y
def feed_forward(X):
"""
前馈网络的示例实现。
实际实现可以包括多个全连接层和激活函数。
"""
# 示例实现:直接返回输入
return X
def series_decomp(X):
"""
对输入时间序列进行分解,提取季节性部分和趋势周期部分。
这里假设 SeriesDecomp 已经实现。
"""
# 示例实现:直接返回两个分量
seasonal_part = X * 0.5 # 分解得到的季节性部分
trend_part = X * 0.5 # 分解得到的趋势周期部分
return seasonal_part, trend_part
def decoder_layer(X_de_prev, X_en_N, W):
"""
单层解码器操作。
X_de_prev: 上一层解码器的输出
X_en_N: 来自编码器的潜变量
W: 加权参数列表
"""
# 第一步:Auto-Correlation 和第一次分解
S_de_l1, T_de_l1 = series_decomp(auto_correlation(X_de_prev))
# 第二步:Auto-Correlation 和第二次分解
S_de_l2, T_de_l2 = series_decomp(auto_correlation(S_de_l1, X_en_N))
# 第三步:前馈网络和第三次分解
S_de_l3, T_de_l3 = series_decomp(feed_forward(S_de_l2))
# 第四步:累积和加权组合趋势周期分量
T_l_I = T_de_l1 * W[0] + T_de_l2 * W[1] + T_de_l3 * W[2]
return S_de_l3, T_l_I
# 示例输入
I = 10
X_de_prev = np.random.randn(I, 3) # 假设上一层解码器输出形状为 (I, d)
X_en_N = np.random.randn(I, 3) # 假设编码器输出形状为 (I, d)
W = [0.3, 0.3, 0.4] # 假设加权参数
# 调用解码器层操作
S_de_l3, T_l_I = decoder_layer(X_de_prev, X_en_N, W)
print("解码器季节性部分:\n", S_de_l3)
print("解码器趋势周期部分:\n", T_l_I)
这个代码实现了一个解码器层的具体操作。首先通过 Auto-Correlation 方法处理输入,并进行第一次分解。接着再通过 Auto-Correlation 方法结合编码器输出进行第二次分解。然后通过前馈网络处理第二次分解结果,并进行第三次分解。最后累积和加权组合趋势周期分量,得到最终的趋势部分。SeriesDecomp、Auto-Correlation 和 FeedForward 函数需要根据具体算法进行实现,这里提供了一个简单的示例实现。
自相关机制
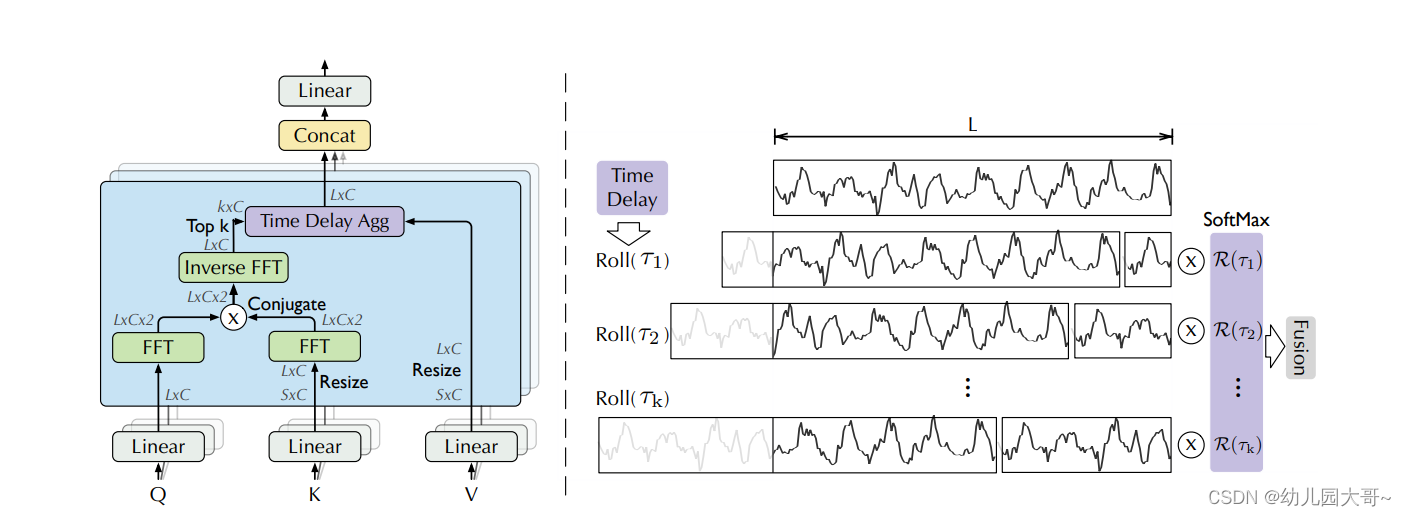
提出了具有序列间连接的自相关机制,以扩大信息利用率。自相关机制通过计算序列的自相关来发现基于周期的依赖关系,并通过时间延迟聚合来聚合相似的子序列。
具体介绍
图中的自相关机制涉及到的Q、K、V分别代表Query、Key和Value,它们分别经过线性变换后参与了一系列的傅里叶变换和逆傅里叶变换操作。以下是整体流程的详细说明:
-
线性变换:
- Q、K、V分别通过线性层进行线性变换。线性层的输出维度与输入维度一致。
-
傅里叶变换(FFT):
- Q和K分别进行傅里叶变换(FFT),将时域信号转换为频域信号。这个过程产生了频域表示的Q和K。
-
调整尺寸(Resize):
- 将Q的傅里叶变换结果调整尺寸,使其适应后续操作。K的傅里叶变换结果也同样进行调整尺寸操作。
-
共轭和乘法操作:
- 对K的傅里叶变换结果取共轭,然后与Q的傅里叶变换结果进行逐元素相乘。这个过程结合了频域中的Q和K信息。
-
逆傅里叶变换(Inverse FFT):
- 将乘积结果进行逆傅里叶变换,返回到时域。这一步产生了融合Q和K频域信息的时域结果。
-
Top K选择:
- 从逆傅里叶变换的结果中选择Top K个重要的时刻,保留重要信息。
-
时间延迟聚合(Time Delay Aggregation):
- 对Top K结果进行时间延迟聚合,这一步将多个延迟后的结果进行整合。
-
线性变换和Concat:
- 聚合后的结果经过线性层,并与原始的V向量进行连接操作(Concat)。
-
SoftMax和融合:
- 在时域上,对不同时间延迟后的结果进行SoftMax操作,以计算权重,然后将这些权重用于加权求和,最后融合得到最终结果。
整体流程通过傅里叶变换和逆傅里叶变换的操作,实现了Q和K在频域中的相关性计算,再通过时间延迟聚合和线性变换,结合V的信息,最终得到融合后的输出结果。这种自相关机制能够更有效地捕捉时序数据中的特征。
基于周期的依赖关系,观察到在周期中的相同相位位置自然提供了相似的子过程。受随机过程理论的启发,对于一个真实的离散时间过程
{
X
t
}
\{X_t\}
{Xt},我们可以通过以下方程得到自相关
R
X
X
(
τ
)
R_{XX}(τ)
RXX(τ):
R
X
X
(
τ
)
=
lim
L
→
∞
1
L
∑
t
=
1
L
X
t
X
t
−
τ
方程五
R_{XX}(\tau) = \lim_{L \to \infty} \frac{1}{L} \sum_{t=1}^{L} X_t X_{t-\tau}\\ 方程五
RXX(τ)=L→∞limL1t=1∑LXtXt−τ方程五
R X X ( τ ) R_{XX}(τ) RXX(τ)反映了 { X t } \{X_t\} {Xt}与其延迟 τ τ τ的序列 { X t − τ } \{X_{t−τ}\} {Xt−τ}之间的时间延迟相似性。如图所示,我们使用自相关 R ( τ ) R(τ) R(τ)作为估计周期长度 τ τ τ的非标准化置信度。然后,我们选择最可能的 k k k个周期长度 τ 1 , … , τ k τ_1,…,τ_k τ1,…,τk。基于上述估计的周期,可以推导出基于周期的依赖关系,并可以通过相应的自相关进行加权。
详细解释:
在时序数据分析中,我们常常会观察到数据在周期中的相同相位位置会呈现相似的子过程。基于这个启发,我们可以利用自相关函数来捕捉这种周期性的相似性。对于一个真实的离散时间过程 { X t } \{X_t\} {Xt},我们可以通过以下方程得到自相关函数 R X X ( τ ) R_{XX}(\tau) RXX(τ):
R X X ( τ ) = lim L → ∞ 1 L ∑ t = 1 L X t X t − τ R_{XX}(\tau) = \lim_{L \to \infty} \frac{1}{L} \sum_{t=1}^{L} X_t X_{t-\tau} RXX(τ)=limL→∞L1∑t=1LXtXt−τ
方程五解释了如何计算自相关函数 R X X ( τ ) R_{XX}(\tau) RXX(τ),其具体含义如下:
-
自相关函数 R X X ( τ ) R_{XX}(\tau) RXX(τ):
- 自相关函数 R X X ( τ ) R_{XX}(\tau) RXX(τ)反映了时间序列 { X t } \{X_t\} {Xt}与其延迟 { X t − τ } \{X_{t-\tau}\} {Xt−τ}之间的时间延迟相似性。
- 它通过计算序列中每个时间点 X t X_t Xt与其在时间上延迟 τ \tau τ个时间点的数值 X t − τ X_{t-\tau} Xt−τ的乘积,然后取平均值来得到。
- 当 τ = 0 \tau = 0 τ=0时,自相关函数反映了序列与自身的相关性,通常为最大值。
-
计算步骤:
- 对于给定的时间序列 { X t } \{X_t\} {Xt},选择一个时间窗口长度 L L L。
- 对于每个时间延迟 τ \tau τ,计算时间序列在每个时间点的值与其延迟 τ \tau τ个时间点的值的乘积。
- 将所有乘积的平均值作为该时间延迟 τ \tau τ下的自相关值。
-
周期长度的估计:
- 如图所示,我们使用自相关函数 R ( τ ) R(\tau) R(τ)作为估计周期长度的非标准化度量。
- 然后,选择 k k k个可能的周期长度 τ 1 , … , τ k \tau_1, \ldots, \tau_k τ1,…,τk。
- 基于上述估计的周期,可以推导出基于周期的依赖关系,并通过自相关进行加权。
通过这种方式,我们能够捕捉时间序列中的周期性模式和相似性,从而提高时间序列分析和预测的准确性。下面是Python代码示例,展示了如何计算自相关函数并选择可能的周期长度进行加权:
import numpy as np
def calculate_autocorrelation(X, max_lag):
"""
计算时间序列 X 的自相关函数 R(τ)
X: 输入时间序列
max_lag: 最大延迟(τ)的值
"""
L = len(X)
R = np.zeros(max_lag)
for tau in range(1, max_lag + 1):
sum_val = 0
for t in range(tau, L):
sum_val += X[t] * X[t - tau]
R[tau - 1] = sum_val / L
return R
def select_periods(R, num_periods):
"""
选择可能的周期长度 τ₁, ..., τₖ
R: 自相关函数值
num_periods: 选择的周期数量
"""
indices = np.argsort(R)[-num_periods:] # 选择自相关值最大的几个周期
return indices + 1 # 索引从0开始,需要加1以得到实际的τ值
# 示例输入
X = np.random.randn(100) # 假设输入时间序列长度为100
max_lag = 20 # 最大延迟
num_periods = 3 # 选择的周期数量
# 计算自相关函数
R = calculate_autocorrelation(X, max_lag)
# 选择可能的周期长度
periods = select_periods(R, num_periods)
print("自相关函数:\n", R)
print("可能的周期长度:", periods)
在这个示例中,我们首先计算输入时间序列的自相关函数 R ( τ ) R(\tau) R(τ),然后选择自相关值最大的几个周期长度作为可能的周期。这样可以帮助我们识别时间序列中的周期性依赖关系,并进一步进行时间序列分析和预测。
时间延迟聚合 基于周期的依赖关系连接了估计周期内的子序列。因此,我们提出了时间延迟聚合模块,该模块可以根据选定的时间延迟
τ
1
,
…
,
τ
k
τ_1,…,τ_k
τ1,…,τk滚动序列。这种操作可以将处于估计周期相同相位位置的相似子序列对齐,这与自注意力家族中的逐点点积聚合不同。最后,我们通过
s
o
f
t
m
a
x
softmax
softmax归一化的置信度聚合子序列。对于单头情况和长度为
L
L
L的时间序列
X
X
X,经过投影器后,我们得到查询
Q
Q
Q、键
K
K
K和值
V
V
V。因此,它可以无缝地替代自注意力。自相关机制如下:
τ
1
,
…
,
τ
k
=
arg Top
k
{
R
Q
,
K
(
τ
)
}
R
^
Q
,
K
(
τ
1
)
,
…
,
R
^
Q
,
K
(
τ
k
)
=
SoftMax
(
R
Q
,
K
(
τ
1
)
,
…
,
R
Q
,
K
(
τ
k
)
)
Auto-Correlation
(
Q
,
K
,
V
)
=
∑
i
=
1
k
Roll
(
V
,
τ
i
)
⋅
R
^
Q
,
K
(
τ
i
)
方程六
\tau_1, \ldots, \tau_k = \text{arg Top}_k \left\{ R_{Q, K}(\tau) \right\} \\ \widehat{R}_{Q, K}(\tau_1), \ldots, \widehat{R}_{Q, K}(\tau_k) = \text{SoftMax} \left( R_{Q, K}(\tau_1), \ldots, R_{Q, K}(\tau_k) \right) \\ \text{Auto-Correlation}(Q, K, V) = \sum_{i=1}^{k} \text{Roll}(V, \tau_i) \cdot \widehat{R}_{Q, K}(\tau_i)\\方程六
τ1,…,τk=arg Topk{RQ,K(τ)}R
Q,K(τ1),…,R
Q,K(τk)=SoftMax(RQ,K(τ1),…,RQ,K(τk))Auto-Correlation(Q,K,V)=i=1∑kRoll(V,τi)⋅R
Q,K(τi)方程六
其中
a
r
g
T
o
p
k
(
⋅
)
arg\ Topk(⋅)
arg Topk(⋅)是获取
T
o
p
k
Topk
Topk个自相关值的参数,并令
k
=
⌊
c
×
l
o
g
L
⌋
k=\lfloor c×logL \rfloor
k=⌊c×logL⌋,
c
c
c是一个超参数。
R
Q
,
K
R_{Q,K}
RQ,K是序列
Q
Q
Q和
K
K
K之间的自相关。
R
o
l
l
(
X
,
τ
)
Roll(X,τ)
Roll(X,τ)表示对X进行时间延迟
τ
τ
τ的操作,其中超出第一个位置的元素将被重新引入到最后的位置。对于编码器-解码器自相关,
K
K
K、
V
V
V来自编码器
X
e
n
N
X_{en}^N
XenN并会被调整为长度
O
O
O,而
Q
Q
Q来自解码器的前一个块。对于
A
u
t
o
f
o
r
m
e
r
Autoformer
Autoformer中使用的多头版本,具有
d
m
o
d
e
l
d_{model}
dmodel个通道和
h
h
h个头的隐藏变量,第
i
i
i个头的查询、键和值是
Q
i
,
K
i
,
V
i
∈
R
L
×
d
m
o
d
e
l
h
,
i
∈
{
1
,
.
.
.
,
h
}
Q_i,K_i,V_i\in \mathbb{R}^{L\times \frac{d_{model}}{h}},i\in\{1,...,h\}
Qi,Ki,Vi∈RL×hdmodel,i∈{1,...,h},。其过程如下:
MultiHead
(
Q
,
K
,
V
)
=
W
output
×
Concat
(
head
1
,
…
,
head
h
)
where
head
i
=
Auto-Correlation
(
Q
i
,
K
i
,
V
i
)
方程七
\text{MultiHead}(Q, K, V) = W_{\text{output}} \times \text{Concat}(\text{head}_1, \ldots, \text{head}_h) \\ \text{where } \text{head}_i = \text{Auto-Correlation}(Q_i, K_i, V_i)\\方程七
MultiHead(Q,K,V)=Woutput×Concat(head1,…,headh)where headi=Auto-Correlation(Qi,Ki,Vi)方程七
详细介绍:
时间延迟聚合基于周期的依赖关系连接了估计周期内的子序列。这种聚合方式可以根据选定的时间延迟 τ 1 , … , τ k \tau_1, \ldots, \tau_k τ1,…,τk滚动序列,从而估计周期相同相位位置的相似子序列对齐。这种方法可以将处于估计周期相同相位位置的相似子序列对齐,这与自注意力家族中的逐点积累不同。最终,通过softmax归一化的量信度聚合子序列。对于单头情况下长为 L L L的时间序列 X X X,经过投影器后,我们得到查询 Q Q Q、键 K K K和值 V V V。因此,它可以无缝地替代自注意力。自相关机制如下:
τ 1 , … , τ k = arg Top k { R Q , K ( τ ) } \tau_1, \ldots, \tau_k = \arg \text{Top}_k \{ R_{Q,K}(\tau) \} τ1,…,τk=argTopk{RQ,K(τ)}
R ^ Q , K ( τ 1 ) , … , R ^ Q , K ( τ k ) = SoftMax ( R Q , K ( τ 1 ) , … , R Q , K ( τ k ) ) \hat{R}_{Q,K}(\tau_1), \ldots, \hat{R}_{Q,K}(\tau_k) = \text{SoftMax}(R_{Q,K}(\tau_1), \ldots, R_{Q,K}(\tau_k)) R^Q,K(τ1),…,R^Q,K(τk)=SoftMax(RQ,K(τ1),…,RQ,K(τk))
Auto-Correlation ( Q , K , V ) = ∑ i = 1 k Roll ( V , τ i ) ⋅ R ^ Q , K ( τ i ) \text{Auto-Correlation}(Q, K, V) = \sum_{i=1}^k \text{Roll}(V, \tau_i) \cdot \hat{R}_{Q,K}(\tau_i) Auto-Correlation(Q,K,V)=∑i=1kRoll(V,τi)⋅R^Q,K(τi)
其中,
- arg Top k ( ⋅ ) \arg \text{Top}_k(\cdot) argTopk(⋅)是获取Top k k k个自相关值的参数,并令 k = ⌊ c × log L ⌋ k = \lfloor c \times \log L \rfloor k=⌊c×logL⌋, c c c是一个超参数。
- R Q , K R_{Q,K} RQ,K是序列 Q Q Q和 K K K之间的自相关。
- Roll ( X , τ ) \text{Roll}(X, \tau) Roll(X,τ)表示对 X X X进行时间延迟 τ \tau τ的操作,其中超出第一位的元素将被重新引入到最后的位置。
对于编码器-解码器组合中,键 K K K来自编码器 X e X^e Xe并会被调整为长度 O O O,而 Q Q Q来自解码器的前一个块。对于Autoformer中使用的多头版本,具有 d m o d e l d_{model} dmodel个通道和 h h h头的隐藏变量,第 i i i个头的查询、键和值是 Q i , K i , V i ∈ R L × d m o d e l h Q_i, K_i, V_i \in \mathbb{R}^{L \times \frac{d_{model}}{h}} Qi,Ki,Vi∈RL×hdmodel, i ∈ { 1 , … , h } i \in \{1, \ldots, h\} i∈{1,…,h}。其过程如下:
MultiHead ( Q , K , V ) = W output × Concat ( head 1 , … , head h ) \text{MultiHead}(Q, K, V) = W_{\text{output}} \times \text{Concat}(\text{head}_1, \ldots, \text{head}_h) MultiHead(Q,K,V)=Woutput×Concat(head1,…,headh)
where head i = Auto-Correlation ( Q i , K i , V i ) \text{where head}_i = \text{Auto-Correlation}(Q_i, K_i, V_i) where headi=Auto-Correlation(Qi,Ki,Vi)
上述方程展示了时间延迟聚合和多头自相关机制的具体实现方式及其在编码器-解码器结构中的应用。
高效计算:对于基于周期的依赖关系,这些依赖关系指向底层周期中相同相位位置的子过程,并且本质上是稀疏的。在这里,我们选择最可能的延迟来避免选择相反的相位。由于我们聚合了
O
(
l
o
g
L
)
O(log L)
O(logL)个长度为
L
L
L的序列,因此方程
6
6
6和
7
7
7的复杂度为
O
(
L
l
o
g
L
)
O(Llog L)
O(LlogL)。对于自相关计算(方程
5
5
5),给定时间序列
{
X
t
}
,
R
X
X
(
τ
)
\{X_t\},R_{X X} (τ)
{Xt},RXX(τ)可以通过基于维纳-辛钦定理的快速傅里叶变换(
F
F
T
FFT
FFT)来计算:
S
X
X
(
f
)
=
F
(
X
t
)
F
∗
(
X
t
)
=
∫
−
∞
∞
X
t
e
−
i
2
π
t
f
d
t
⋅
∫
−
∞
∞
X
t
e
−
i
2
π
t
f
d
t
‾
R
X
X
(
τ
)
=
F
−
1
(
S
X
X
(
f
)
)
=
∫
−
∞
∞
S
X
X
(
f
)
e
i
2
π
f
τ
,
d
f
方程八
\begin{align*} S_{XX}(f) &=F(X_t) F^*(X_t) = \int_{-\infty}^{\infty} X_t e^{-i2\pi tf} dt \cdot \overline{\int_{-\infty}^{\infty} X_t e^{-i2\pi tf} dt}^ \ \\R_{XX}(\tau) &= F^{-1}(S_{XX}(f)) = \int_{-\infty}^{\infty} S_{XX}(f) e^{i2\pi f\tau} , df \end{align*}方程八
SXX(f)RXX(τ)=F(Xt)F∗(Xt)=∫−∞∞Xte−i2πtfdt⋅∫−∞∞Xte−i2πtfdt =F−1(SXX(f))=∫−∞∞SXX(f)ei2πfτ,df方程八
其中 τ ∈ { 1 , . . . , L } τ ∈ \{1, ..., L\} τ∈{1,...,L}, F F F表示 F F T FFT FFT, F − 1 F^{-1} F−1是其逆变换。 ∗ * ∗表示共轭操作, S X X ( f ) S_{X X} (f) SXX(f)是频域中的。请注意,通过 F F T FFT FFT可以一次性计算 { 1 , . . . , L } \{1, ..., L\} {1,...,L}中所有延迟的序列自相关。因此,自相关计算达到了 O ( L l o g L ) O(Llog L) O(LlogL)的复杂度。
详细解释:
对于基于周期的依赖关系,这些依赖关系指向底层周期中相同相位位置的子过程,并且本质上是稀疏的。在这里,我们选择最可能的延迟来避免选择相反的相位。由于我们聚合了 O ( log L ) \mathcal{O}(\log L) O(logL)个长度为 L L L的序列,因此方程6和7的复杂度为 O ( L log L ) \mathcal{O}(L \log L) O(LlogL)。对于自相关计算(方程5),给定时间序列 { X t } \{X_t\} {Xt}, R X X ( τ ) R_{XX}(\tau) RXX(τ)可以通过基于维纳-辛辛那提变换的快速傅里叶变换(FFT)来计算:
S X X ( f ) = F ( X t ) F ∗ ( X t ) = ∫ − ∞ ∞ X t e − i 2 π t f d t ⋅ ∫ − ∞ ∞ X t e − i 2 π t f d t S_{XX}(f) = F(X_t) F^*(X_t) = \int_{-\infty}^{\infty} X_t e^{-i2\pi tf} dt \cdot \int_{-\infty}^{\infty} X_t e^{-i2\pi tf} dt SXX(f)=F(Xt)F∗(Xt)=∫−∞∞Xte−i2πtfdt⋅∫−∞∞Xte−i2πtfdt
R X X ( τ ) = F − 1 ( S X X ( f ) ) = ∫ − ∞ ∞ S X X ( f ) e i 2 π f τ d f R_{XX}(\tau) = F^{-1}(S_{XX}(f)) = \int_{-\infty}^{\infty} S_{XX}(f) e^{i2\pi f\tau} df RXX(τ)=F−1(SXX(f))=∫−∞∞SXX(f)ei2πfτdf
其中:
- τ ∈ { 1 , … , L } \tau \in \{1, \ldots, L\} τ∈{1,…,L}
- F F F表示FFT, F − 1 F^{-1} F−1是其逆变换
- ∗ * ∗表示共轭操作
- S X X ( f ) S_{XX}(f) SXX(f)是频域中的 θ \theta θ
请注意,通过FFT可以一次性计算 { 1 , … , L } \{1, \ldots, L\} {1,…,L}中所有延迟的序列自相关。因此,自相关计算达到了 O ( L log L ) \mathcal{O}(L \log L) O(LlogL)的复杂度。
这个方法利用了FFT的高效性来处理长序列的自相关计算,大大降低了计算复杂度,提升了计算效率。
自相关与自注意族
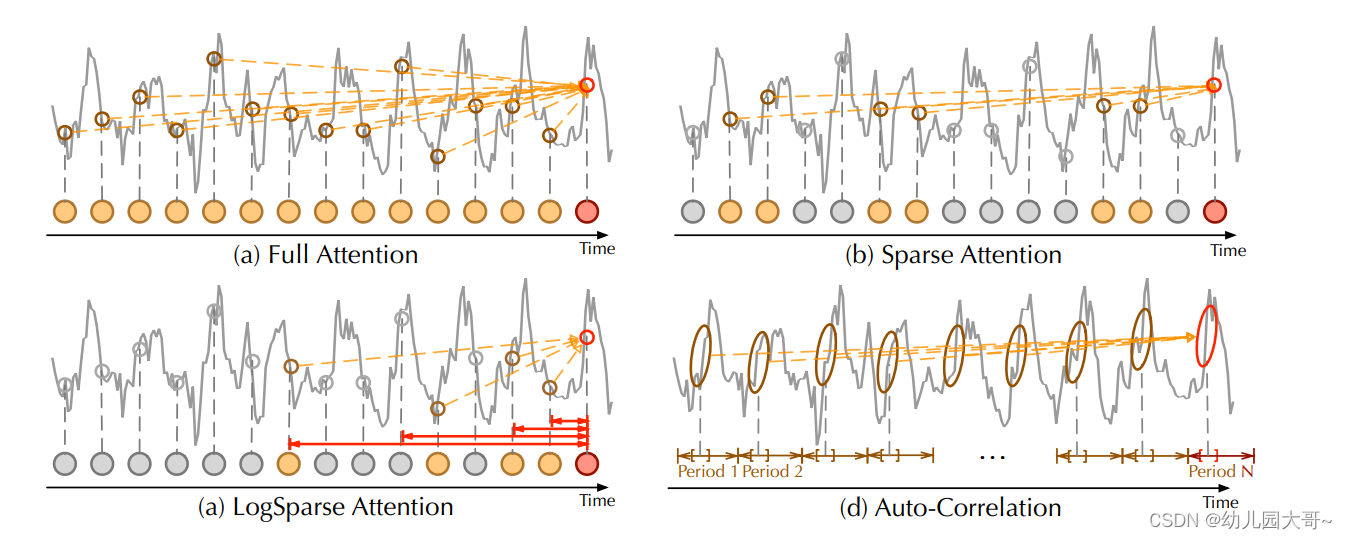
与逐点自注意力族不同,自相关展示了序列之间的连接(如图所示)。具体来说,对于时间依赖性,我们基于周期性来查找子序列之间的依赖关系。相比之下,自注意力族仅计算分散点之间的关系。尽管一些自注意力机制考虑了局部信息,但它们仅利用这些信息来帮助发现逐点依赖关系。对于信息聚合,我们采用时间延迟块来聚合来自底层周期中的相似子序列。相反,自注意力通过点积来聚合选定的点。得益于固有的稀疏性和子序列级别的表示聚合,自相关可以同时提高计算效率和信息利用率。
详细解释:
图片中的内容展示了自相关与自注意力机制的比较,并通过图示说明了各自的特点和应用。以下是详细介绍:
图3:自相关与自注意力家族的比较
-
全注意力(Full Attention):适用于所有时间点之间的完全连接。图(a)展示了全注意力机制,它对序列中的每个时间点(节点)都进行关注,因此计算复杂度较高。
-
稀疏注意力(Sparse Attention):基于提出的相似度指标选择。图(b)展示了稀疏注意力,它仅关注选择的一部分时间点,从而减少了计算复杂度。
-
LogSparse 注意力(LogSparse Attention):对数稀疏注意力,选择点遵循指数增加的间隔。图©展示了LogSparse注意力,它选择的点随着时间的推进,间隔逐渐增大,适用于处理长序列。
-
自相关(Auto-Correlation):关注底层周期中子序列之间的连接。图(d)展示了自相关机制,它通过时间延迟选择基于周期性依赖关系的子序列连接,从而高效地捕捉序列中不同周期的相似性。
与逐点自注意力家族不同,自相关展示了序列之间的连接(如图所示)。具体来说,对于时间依赖性,我们基于周期性来查找子序列之间的依赖关系。相比之下,自注意力家族计算分散点之间的关系。尽管一些自注意力机制考虑了局部信息,但它们仅利用这些信息来帮助发现远点依赖关系。对于信息聚合,我们采用时间延迟块来聚合来自底层周期中的相似位置子序列。相反,自注意力通过点对点聚合来选定的点。得益于固有的稀疏性和子序列级别的表示聚合,自相关可以同时提高计算效率和信息利用率。
图片通过图示(a, b, c, d)分别展示了全注意力、稀疏注意力、LogSparse 注意力和自相关机制的特点,并通过箭头和连接线展示了不同机制下节点之间的连接方式。