原文链接:https://arxiv.org/abs/2406.10600
简介:本文引入自适应子采样方法和定制网络,利用稀疏性模式发掘雷达信号中的全局和局部依赖性。本文的子采样模块选择 RD谱中在下游任务贡献最大 像素 的子集。为提高子采样数据的特征提取,本文引入图神经网络,设计两分支主干分别提取局部和全局信息,并使用注意力融合模块组合两分支特征。实验表明,本文的SparseRadNet能在RADIal数据集上达到SotA分割和检测性能。
1. 引言
现有的基于原始雷达数据(如RAD张量、RD谱或ADC数据等)的方法多使用CNN,但大量像素仅含有噪声,CNN处理不够高效。
本文为每帧数据动态生成采样掩膜,对原始雷达数据进行子采样。同时,对子采样数据使用GNN,将子采样像素视为节点,根据特征空间中的距离建立动态边。此外,使用稀疏CNN作为主干的另一分支,与GNN分别提取局部和全局特征。
3. SparseRadNet结构
如图所示,SparseRadNet分为4部分:深度雷达子采样模块(从RD谱中选择重要部分);带有注意力融合模块的两分支主干(捕捉邻域信息);距离-角度解码器(将RD转化为RA视图);两个输出头(用于目标检测和空空间分割)。
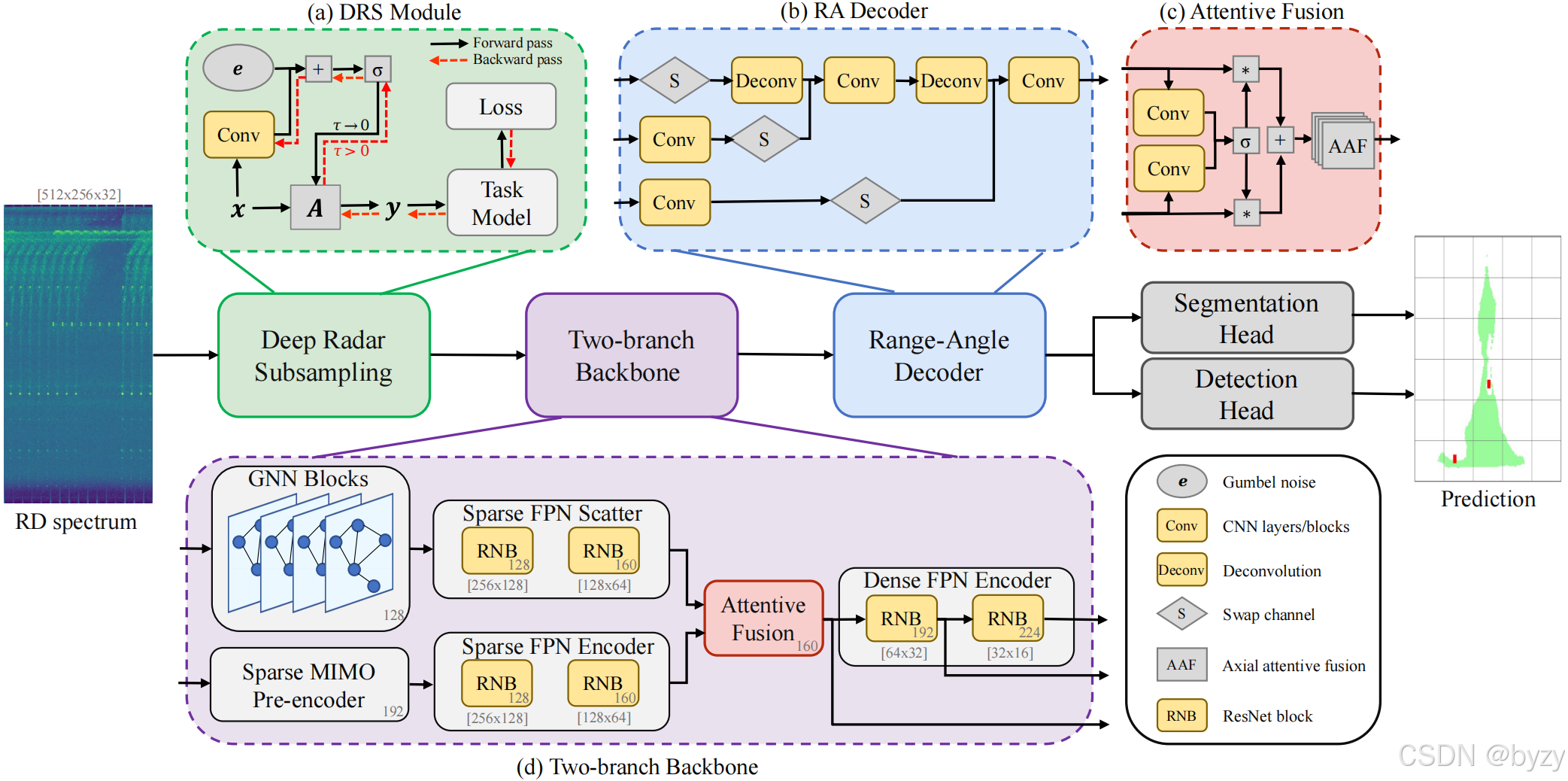
3.1 深度雷达子采样模块
本文提出深度雷达子采样(DRS)模块,以同时保留原始雷达数据的稀疏性和丰富的信息。
RD谱为 C H × W × N R x \mathbb C^{H\times W\times N_{Rx}} CH×W×NRx的复值向量,其中 N R x N_{Rx} NRx为接收天线的数量,复值被分为实部和虚部,作为本文方法的输入 x ∈ R H × W × 2 N R x x\in\mathbb R^{H\times W\times 2N_{Rx}} x∈RH×W×2NRx。令 A ∈ { 0 , 1 } H × W A\in\{0,1\}^{H\times W} A∈{0,1}H×W为\二值采样掩膜,可通过 y h , w , c = A h , w ⋅ x h , w , c y_{h,w,c}=A_{h,w}\cdot x_{h,w,c} yh,w,c=Ah,w⋅xh,w,c得 y ∈ R H × W × 2 N R x y\in\mathbb R^{H\times W\times 2N_{Rx}} y∈RH×W×2NRx。预定义的选择元素数 M ≪ N = H × W M\ll N=H\times W M≪N=H×W。本文使用CNN(参数为 θ \theta θ)处理输入,并将输出视为未归一化的logit Z θ ( x ) ∈ R H × W Z_{\theta}(x)\in\mathbb R^{H\times W} Zθ(x)∈RH×W。
本文将问题视为从分类分布的采样。使用Gumbel-Softmax方法直接从未归一化的logit中采样
M
M
M个像素,而非先将
Z
θ
(
x
)
Z_{\theta}(x)
Zθ(x)通过softmax达到概率分布
A
θ
(
x
)
A_\theta(x)
Aθ(x)。Gumbel-Max技巧能实现高效的分类采样,而Gumbel-Softmax将该方法视为重参数化技巧使得采样是可微的。
Z
θ
(
x
)
Z_{\theta}(x)
Zθ(x)中的每个元素
z
h
,
w
z_{h,w}
zh,w会先被Gumbel噪声
e
h
,
w
∼
Gumbel
(
0
,
1
)
e_{h,w}\sim \text{Gumbel}(0,1)
eh,w∼Gumbel(0,1)扰动,使得计算图中不可微的随机节点被移动到边上,从而梯度回传变得可行。然后,为扰动的logit使用argmax生成一个样本(等价于从类别分布
A
θ
(
x
)
A_\theta(x)
Aθ(x)中抽取一个类别)。使用argtopM操作同时采样
M
M
M个样本:
r
=
argtopM
1
≤
h
≤
H
1
≤
w
≤
W
{
z
h
,
w
+
e
h
,
w
}
r=\underset{1\leq w\leq W}{\underset{1\leq h\leq H}{\text{argtopM}}}\{z_{h,w}+e_{h,w}\}
r=1≤w≤W1≤h≤HargtopM{zh,w+eh,w}
其中 r = { r 1 , ⋯ , r m } ⊂ N 2 r=\{r_1,\cdots,r_m\}\subset\mathbb N^2 r={r1,⋯,rm}⊂N2为 M M M个采样的像素索引。根据 r r r可生成硬掩模 A h a r d A^{hard} Ahard。
由于argtopM不可微,Gumbel-Softmax方法使用softmax函数作为连续可微的近似,生成软掩膜
A
s
o
f
t
A^{soft}
Asoft:
A
s
o
f
t
=
∑
m
=
1
M
softmax
τ
{
w
m
+
Z
θ
(
x
)
+
e
}
A^{soft}=\sum_{m=1}^{M}\text{softmax}_\tau\{w^m+Z_\theta(x)+e\}
Asoft=m=1∑Msoftmaxτ{wm+Zθ(x)+e}
其中
w
h
,
w
m
∈
{
−
∞
,
0
}
w_{h,w}^m\in\{-\infin,0\}
wh,wm∈{−∞,0}通过设置为
−
∞
-\infin
−∞抑制过去抽取的样本,
τ
\tau
τ表示softmax的温度参数,控制Gumbel-Softmax的平滑程度。
τ
→
0
\tau\rightarrow0
τ→0时,软采样掩膜逼近硬掩膜。训练时,采样掩膜为
A
=
A
h
a
r
d
+
A
s
o
f
t
−
detach
(
A
s
o
f
t
)
A=A^{hard}+A^{soft}-\text{detach}(A^{soft})
A=Ahard+Asoft−detach(Asoft)
其中detach将张量从计算图中移除。前向传播过程 A A A作为二值采样掩膜生成下游感知模块的稀疏输入 y y y,而反向传播过程通过上式第二项将梯度回传到CNN。
DRS模块可被感知损失端到端训练,可选择对感知任务影响最大的像素,同时抑制噪声。
3.2 两分支主干
GNN分支。GNN分支包括GNN块和稀疏特征分散模块(FPN)。本文基于ViG的各向同性模式建立GNN,其中GNN层间的特征有相同的形状大小。
将子采样的像素通过线性层得到 C C C维向量 y ˉ ∈ R M × C \bar y\in\mathbb R^{M\times C} yˉ∈RM×C,作为初始节点特征。将节点记为 V \mathcal V V,对每个节点 v i v_i vi,寻找其特征空间中的 K K K近邻节点并连接两者形成边,得到边集 E \mathcal E E,进而形成图 G = ( V , E ) \mathcal G=(\mathcal V,\mathcal E) G=(V,E)。 K K K随着通过GNN块的增加而增大。由于节点特征会不断更新,其邻域会发生变化,因此称为动态图。
每个GNN块包括Grapher模块和前馈网络FFN。前者包含一个图卷积网络(GCN)层和前后的两个线性层。GCN包含两个步骤:聚合和更新。聚合前,根据当前节点特征生成图,然后节点的邻居被聚合操作
g
(
⋅
)
g(\cdot)
g(⋅)聚合,随后更新操作
h
(
⋅
)
h(\cdot)
h(⋅)通过线性层更新节点:
y
ˉ
i
′
=
G
C
N
(
y
ˉ
i
)
=
h
(
y
ˉ
i
,
g
(
y
ˉ
i
,
E
(
v
i
)
)
,
W
u
p
d
a
t
e
)
\bar y'_i=GCN(\bar y_i)=h(\bar y_i,g(\bar y_i,\mathcal E(v_i)),W_{update})
yˉi′=GCN(yˉi)=h(yˉi,g(yˉi,E(vi)),Wupdate)
其中
i
=
1
,
⋯
,
M
i=1,\cdots,M
i=1,⋯,M,
W
u
p
d
a
t
e
W_{update}
Wupdate为更新操作的参数,且
g
(
y
ˉ
i
)
=
concat
(
y
ˉ
i
,
max
{
y
ˉ
j
−
y
ˉ
i
∣
j
∈
E
(
v
i
)
}
)
h
(
y
ˉ
i
)
=
g
(
y
ˉ
i
)
W
u
p
d
a
t
e
g(\bar y_i)=\text{concat}(\bar y_i,\max\{\bar y_j-\bar y_i|j\in\mathcal E(v_i)\})\\ h(\bar y_i)=g(\bar y_i)W_{update}
g(yˉi)=concat(yˉi,max{yˉj−yˉi∣j∈E(vi)})h(yˉi)=g(yˉi)Wupdate
根据公式,这里的GCN类似于(特征空间下的)PointNet。
其中
h
(
⋅
)
h(\cdot)
h(⋅)为分组卷积。RD视图的特征包含角度信息,分组可视为划分象限。Grapher模块记为
Grapher
(
y
ˉ
)
=
σ
(
G
C
N
(
y
ˉ
W
i
n
)
)
W
o
u
t
+
y
ˉ
\text{Grapher}(\bar y)=\sigma(GCN(\bar yW_{in}))W_{out}+\bar y
Grapher(yˉ)=σ(GCN(yˉWin))Wout+yˉ
其中 σ \sigma σ为GeLU激活函数, W i n W_{in} Win和 W o u t W_{out} Wout为线性层参数(省略偏置项)。
稀疏FPN包括两个稀疏ResNet块,以将节点特征分散到RD图上并减小空间尺寸。
SCNN分支。稀疏CNN(SCNN)可以有效提取局部特征。该分支包括稀疏MIMO预编码器和稀疏FPN编码器。
MIMO预编码器在FFT-RadNet中引入,使用了针对雷达传感器定制的atrous卷积层。核大小为 1 × N T x 1\times N_{Tx} 1×NTx,膨胀 δ = Δ ⋅ W D max \delta=\frac{\Delta\cdot W}{D_{\max}} δ=DmaxΔ⋅W取决于发射器的多普勒偏移 Δ \Delta Δ、多普勒bin数 W W W和最大多普勒值 D max D_{\max} Dmax。这样,MIMO预编码器可解开目标相应的交错。本文应用稀疏atrous卷积。
稀疏FPN的结构和GNN中的一致,但包含更多的残差块以加强局部特征提取。
注意力融合。注意力融合包含空间注意力融合和轴向注意力融合。
首先,两个分支的特征分别通过卷积层得到 R H × W × 1 \mathbb R^{H\times W\times 1} RH×W×1的两个分数图,拼接后通过softmax,产生两组权重因子,用于特征图的加权求和。
然后,通过轴向注意力对齐局部和全局特征。GNN关注子采样像素的亲和度,保留了其位置;SCNN分支则在MIMO预编码器中交换了行的位置,使得两分支的输出特征在空间上不对齐。此外,本文期望在融合时考虑列的依赖性。因此,本文使用轴向注意力,将注意力分解为行向注意力和列向注意力,将注意力窗口限制在一行或一列中。
最后,使用密集FPN编码器进一步提取特征。
3.3 距离-角度解码器
距离-角度解码器用于将RD图转化到RA空间。组合不同尺度的特征可丰富信息。CNN用于匹配通道维度和角度bin的数量,并进行通道维度和多普勒维度的交换,得到RA视图。对于低分辨率的特征图,使用反卷积恢复空间分辨率。
3.4 多任务头
使用FFT-RadNet的多任务头,包含空空间分割头(预测每个像素的占用情况)和检测头(预测车辆的存在性以及距离、角度偏移量)。
4. 实验
4.1 实施细节
推断时,不添加Gumbel噪声,仅计算硬掩膜 A h a r d A^{hard} Ahard。此外,稀疏主干无法为softmax提供完整梯度信息,因此本文先将DRS插入密集基准方案FFT-RadNet训练,再加载到本文SparseRadNet中并冻结权重。
GNN分支关注全局信息提取,因此未加入位置编码。