开放集学习 Openset Learning
主动学习 Active Learning
例外检测 Out-of-Distribution
open-set recognition(OSR)开集识别
anomaly detection和outlier detection
文章目录
- OOD检测
- OSR开放集识别
- OSR开放集识别的特点
- OSR 和 OOD detection 的差异:
- 问题解决:
- 知识点
- Abstract
- 1. Introduction
- 2. Related Work
- 3. CORRELATION BETWEEN CLOSED-SET AND OPEN-SET PERFORMANCE
- 4 A GOOD CLOSED-SET CLASSIFIER IS ALL YOU NEED?
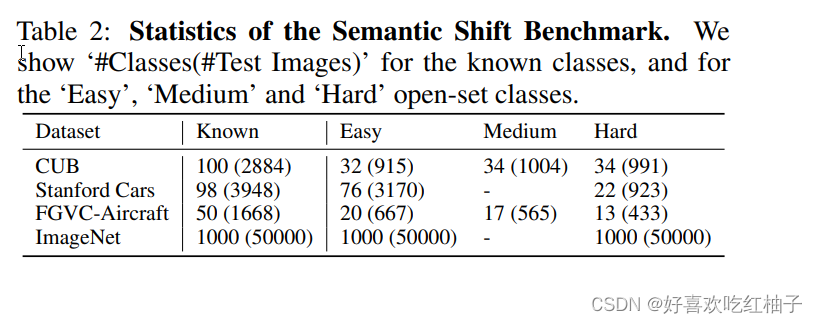
- 5 SEMANTIC SHIFT BENCHMARK
OOD检测
广义OOD detection:囊括了outlier detection (OD) 离群检测,anomaly detection (AD) 异常检测,novelty detection (ND)新颖检测,open set recognition (OSR)开放集识别 和 OOD detection(OOD)分布外检测;
OSR开放集识别
设计一个模型,这个模型不仅可以对已知的类别进行分类,还能够识别出属于未知类别的样本。这通常需要模型具有一定的异常检测能力。
OSR开放集识别的特点
【我的理解】
OSR识别是OOD的子集问题,OSR主要侧重于解决语义偏移的问题,而且可以识别出未来会出现的一些新类别,OOD会有语义偏移或者分布偏移等等
OSR还要求模型在已知类别中有好的分类
OSR 和 OOD detection 的差异:
-
不同的基准设置: OSR基准通常根据标签类别将一个多类分类数据集拆分为ID和OOD,而OOD检测将一个数据集作为ID,并找到其他几个数据集作为OOD,保证ID / OOD数据集之间的类别不重叠。然而,尽管这两个子任务的基准传统不同,但它们实际上都在处理相同的语义转换检测问题(y变化的检测,作者这里还是认为ood的重点是检测y的变化)。
-
OSR中没有额外的数据: 由于理论上开放风险约束保证的要求,OSR不鼓励在训练期间通过设计使用额外的数据。这种限制排除了更专注于有效性能改进(例如,异常值暴露)但可能违反OSR约束的方法。
-
OOD检测的广泛性: 与OSR相比,OOD检测包含更广泛的学习任务(例如,多标签分类)、更广泛的解决方案空间。
OSR与我们的通用OOD检测框架非常吻合,其中"已知的已知类别"和"未知的未知类别"分别对应于ID和OOD。形式上,OSR处理的是OOD样本发生语义偏移(Y变)的情况,即 P ( Y ) ≠ P ′ ( Y ) P(Y) \neq P'(Y) P(Y)=P′(Y)。OSR的目标与多类ND的目标在很大程度上是一致的,唯一的区别是OSR额外需要解决一个问题,就是对来自 P ( Y ) P(Y) P(Y) 的ID样本进行准确分类。
MNIST上的一个例子和多类ND类似,将前6类视为ID,其余4类视为OOD。此外,OSR还要求在6个ID类上有一个好的分类器。
问题解决:
转化为二元分类问题:已知类别 vs. 未知类别。在这个设置下,模型需要学习一个决策边界,能够区分已知类别的样本和未知类别的样本。
OpenMax算法:OpenMax首先会计算一个样本属于各个已知类别的概率,然后它会使用这些概率来估计这个样本属于未知类别的概率。
知识点
- semantic:语义,图片之间不同的语义表示图片代表不同的意思,下图横向为不同的semantic
- outlier images:离群图像,不在闭集中,fake images: 使用GAN网课生成的假图像

以下为论文解读
Abstract
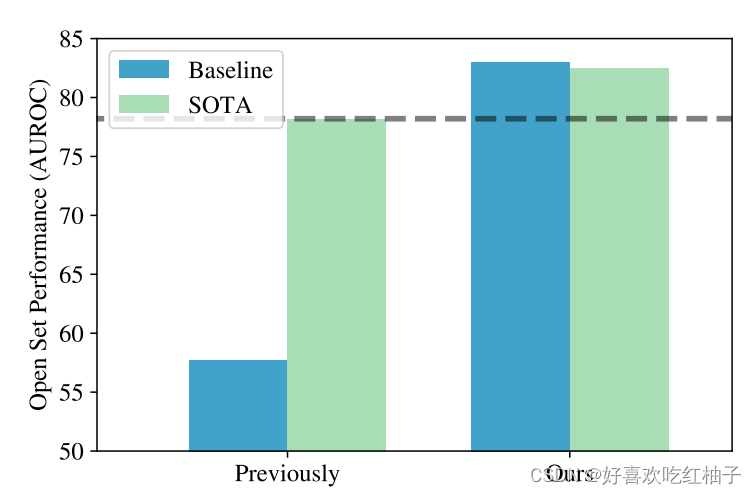
得到结论:模型做出“属于非以上类”决策的能力高度取决于在闭集分类中的准确性
使用方法:通过提高闭集精读来提高OSR性能
提出框架:SSB(Semantic Shift Benchmark)
1. Introduction
Question Defination:
In the more realistic open-set setting, a model must not only be able to distinguish between the training classes, but also indicate if an image comes from a class it has not yet encountered.
Baseline of OSR:
a model trained with the cross-entropy loss on the known classes
MSP baseline(define whether or not belongs to the known class)
the maximum value of the softmax probability vector is used to decide if an input belongs to the known classes or not (MSP baseline)
Contributions:
1.The relationship between Open and Closed[Sec 3]
Demonstrate the relationship between open-set and closed-set classification, and if the classifier is good at closed-set, it will also good at open-set, instead of not corelated.
2. How to improve the performance of open-set classifier[Sec 4]
Show that the open-set performance of a classifier can be improved by enhancing its closed-set accuracy.
- Strategies to improve the closed-set performance: more augmentation, better learning rate schedules and label smoothing……
- Open-set indicator:the maximum logit score (MLS) instead of normalized softmax probabilities;
- Performace: outperform the baseline and surpass state-of-the-art figures on four of the six OSR benchmark datasets;
3. The improved baseline and benchmark
Transfer these improvements to two previous OSR methods and does boost its performance.
4. SSB
- propose the ‘Semantic Shift Benchmark’ suite (SSB)
- the use of fine-grained dataset (CUB、Stanford Cars、FGVC-Aircraft……)
- propose a split to better separates from related machine learning sub-fields such as out-of-distribution (Hendrycks & Gimpel, 2017) and anomaly detection (Kwon et al., 2020)
2. Related Work
2.1 Open-set recognition
Methods for OSR
1. OpenMax
the first deep learning approach for OSR based on the Extreme Value Theory (EVT).
2. GANs
- OSRCI
generates images similar to those in the training set but that do not belong to any of the known classes, and uses the generated images to train an open-set classifier. [established the existing OSR benchmark suite]
核心思想是生成虚拟的对抗图像,这些图像与训练集中的样本类似,但不属于任何已知类别。这些虚拟图像被用于训练一个开放集分类器,使其能够更好地区分已知类别和未知类别。
该方法通过生成与训练集示例接近但不属于任何训练类别的虚拟示例,以便检测未知类别。通过将这些虚拟示例与训练集一起使用,可以将开放集识别重新定义为具有一个额外类别的分类问题,该类别包括新颖和未知示例的集合。
- OpenGAN
OpenGAN: Open-Set Recognition via Open Data Generation
using an adversarially trained discriminator to delineate closed from open-set images, leveraging real open-set images for model selection.
3. Reconstruction-based methods
use poor test-time reconstruction as an open-set indicator, and prototype-based methods
4. Prototype-based methods
represent known classes with learned prototypes, and identify open-set images based on distances to the prototypes.
2.2 State-of-the-art
2.2.1 Two methods achieved state-of-the-art in the controlled OSR setting
-
ARPL (Adversarial Reciprocal Point Learning) (Chen et al., 2020a; 2021)
sec 3.1 -
OpenHybrid (Zhang et al., 2020)
sec 4
2.2.2 Our achievements
The baseline in this work can be competitive with or outperform the more complex methods listed above.
2.3 Related subfields
- Out-of-distribution (OoD) detection
- Novelty detection
- Anomaly detection
- Novel category discovery
Distinguish OSR from OoD
- OoD is allowed to use additional data as examples of ‘OoD’ data during training while OSR don’t have access to additional data during training.
- While OoD encompasses all forms of distributional shift, including those based on low-level features, OSR specifically refers to semantic novelty.
3. CORRELATION BETWEEN CLOSED-SET AND OPEN-SET PERFORMANCE
Theme
the closed-set and open-set performance of classifiers are strongly correlated. The saying of “stronger closed-set classifiers have overfit their learned representations to the closed-set categories so it will perform poorly for OSR” is incorrect.
Formula
Consider a labelled training set for a classifier:
D t r a i n = { ( x i , y i ) } i = 1 N ⊂ X × C D_{train} = \{(x_i, y_i)\}^N _{i=1} ⊂ X × C Dtrain={(xi,yi)}i=1N⊂X×C
- X:输入空间
- C :已知类的集合
1 For closed-set
Testing: the test images also from the same set of classes.
D t e s t − c l o s e d = { ( x i , y i ) } i = 1 M ⊂ X × C D_{test-closed} = \{(x_i, y_i)\}^M _{i=1} ⊂ X × C Dtest−closed={(xi,yi)}i=1M⊂X×C
- return a distribution: p ( y ∣ x ) p(y|x) p(y∣x)
分类器为每个输入示例x返回一个关于已知类别的概率分布 p ( y ∣ x ) p(y|x) p(y∣x),意味着对于给定的输入示例x,分类器会生成一个概率分布,其中每个类别y都对应一个概率值。这个概率值表示分类器对于该输入示例属于每个已知类别的置信度或可能性。
具体而言,对于每个已知类别 c ∈ C c ∈ C c∈C,分类器会计算条件概率 p ( y = c ∣ x ) p(y=c|x) p(y=c∣x),表示在给定输入示例x的条件下,该示例属于类别c的概率。这样,对于每个输入示例x,分类器会为每个已知类别c生成一个概率值,形成一个概率分布 p ( y ∣ x ) p(y|x) p(y∣x),其中概率值的总和为1。
通过这个概率分布,我们可以了解分类器对于每个已知类别的相对置信度。通常情况下,预测类别会选择具有最高概率值的类别,因为它被认为是最有可能的类别。
这种概率分布的输出使我们能够获得更多关于分类器对于每个输入示例的不确定性和置信度的信息。它可以帮助我们进行后续的决策和分析,比如设置一个概率阈值来确定分类结果或者进行不确定性建模。
2 For open-set
Testing: test images may also come from unseen classes U U U
D t e s t − o p e n = { ( x i , y i ) } i = 1 M ′ ⊂ X × ( C ⋃ U ) D_{test-open} = \{(x_i, y_i)\}^{M'} _{i=1} ⊂ X × (C \bigcup U) Dtest−open={(xi,yi)}i=1M′⊂X×(C⋃U)
-
return a distribution: p ( y ∣ x , y ⊂ C ) p(y|x,y\subset C) p(y∣x,y⊂C) over known classes (理解:输入的图像为已知类的概率)
-
return a score: S ( y ∈ C ∣ x ) S(y\in C|x) S(y∈C∣x) indicate whether or not the test sample belongs to any of the known classes.(理解:输入的图像为已知类的得分)
在这种情况下,模型需要处理两种情况:已知类别和未见类别。
-
对于已知类别 C C C,模型会计算条件概率 p ( y ∈ C ∣ x ) p(y ∈ C|x) p(y∈C∣x),表示在给定输入示例x的条件下,该示例属于任何已知类别的概率。这样,模型可以返回一个关于已知类别的概率分布 p ( y ∣ x , y ∈ C ) p(y|x, y ∈ C) p(y∣x,y∈C),用于表示模型对于每个已知类别的置信度。
-
同时,模型还会返回一个分数 S ( y ∈ C ∣ x ) S(y ∈ C|x) S(y∈C∣x),该分数用于指示测试样本是否属于任何已知类别。这个分数可以是一个连续值或二进制值,表示测试样本属于已知类别的程度。较高的分数表明测试样本更有可能属于已知类别,而较低的分数则表明测试样本可能属于未见类别 U U U。
3 关于概率分布 p ( y ∣ x ) 和 p ( y ∣ x , y ∈ C ) p(y|x)和p(y|x, y ∈ C) p(y∣x)和p(y∣x,y∈C)
关系:
- p(y|x):表示在给定输入示例x的条件下,该示例属于类别y的概率。这是一个针对已知类别的条件概率分布,在封闭集合的情景下使用。
- p(y|x, y ∈ C):表示在给定输入示例x的条件下,该示例属于任何已知类别y的概率。这也是一个针对已知类别的条件概率分布,但在开放集合的情景下使用。
区别:
- 范围:概率分布p(y|x)仅考虑已知类别C,而概率分布p(y|x, y ∈ C)同时考虑已知类别C和未知类别U。
- 输出:概率分布p(y|x)仅给出关于已知类别的概率信息,而概率分布p(y|x, y ∈ C)还会给出关于已知类别的分数信息,用于指示测试样本是否属于已知类别。
- 用途:概率分布p(y|x)主要用于封闭集合的分类任务,而概率分布p(y|x, y ∈ C)主要用于开放集合的分类任务,可以处理未见过的类别U。
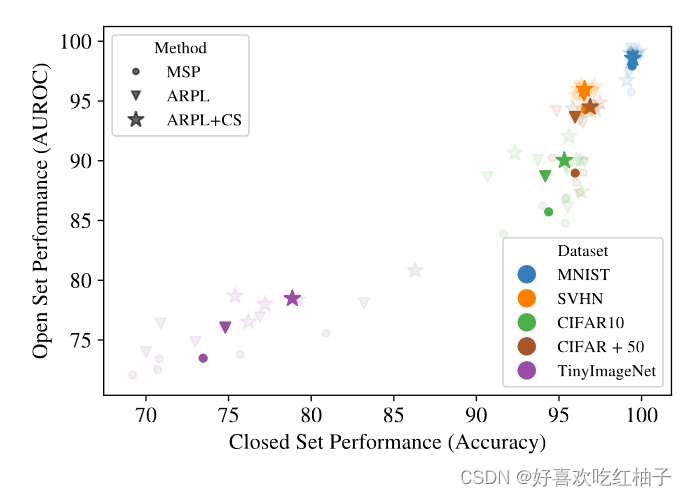
3.1 BASELINE AND STATE-OF-THE-ART ON STANDARD BENCHMARKS
Three representative open-set recognition methods across the standard benchmark datasets.
3.1.1 Three representative OSR methods
1. Maximum Softmax Probability (MSP, baseline)
Baseline: cross-entropy loss between a one-hot target vector and the softmax output p(y|x) of the classifier.
S ( y ∈ C ∣ x ) = m a x y ∈ C p ( y ∣ x ) S(y ∈ C|x) = max_{y∈C} p(y|x) S(y∈C∣x)=maxy∈Cp(y∣x)
2. ARPL
- RPL (Reciprocal Point Learning):the probability that a sample belongs to a class is proportional to its distance from a learned ‘reciprocal point’ in the feature space.
- reciprocal point: shows that open-set examples are different to all known classes.
样本属于某个类别的概率与其在特征空间中与一个学习到的“互补点”(reciprocal point)的距离成正比。互补点旨在表示相对于某个类别的“其他性”,其直观意义是开放集样本与所有已知类别都有所不同。
ARPL:extends RPL by computing feature distances as the sum of both the Euclidean and cosine distances.
S ( y ∈ C ∣ x ) = m a x y ∈ C ( d e ( x , y ) + d c ( x , y ) ) S(y ∈ C|x) = max_{y∈C} (d_e(x, y) + d_c(x, y)) S(y∈C∣x)=maxy∈C(de(x,y)+dc(x,y))
S ( y ∈ C ∣ x ) S(y ∈ C|x) S(y∈C∣x) is equals to the maximum distance in feature space between the image and any reciprocal point.
3. ARPL + CS
ARPL + confusing samples
The confusing samples are encouraged to be equidistant from all reciprocal points, with the same open-set scoring rule used as in ARPL.
3.1.2 Datasets
MNIST, SVHN, CIFAR10, CIFAR + N, TinyImageNet
- train : on a subset of classes, [known classes]
- evaluation : the rest of the classes are reserved as ‘unseen’, [unknown classes]
e.g. In CIFAR10, training on six classes, while using the other four classes for testing ( ∣ C ∣ = 6 ; ∣ U ∣ = 4 |C| = 6; |U| = 4 ∣C∣=6;∣U∣=4)
3.1.3 Experimental setup
Make : binary ‘known/unknown’ decision
Evaluation metric: AUROC
3.1.4 Results
OSR and CSR is highly corelated with a linear relationship. 皮尔森系数
ρ
=
0.9
ρ=0.9
ρ=0.9.
Pearson Product-Moment相关系数
Pearson Product-Moment相关系数(Pearson’s correlation coefficient)是一种用于衡量两个连续变量之间线性相关程度的统计量。它衡量了两个变量之间的线性关系的强度和方向。
Pearson相关系数的取值范围在-1到1之间。
- 当相关系数为1时,表示存在完全的正线性关系,即两个变量完全正相关。
- 当相关系数为-1时,表示存在完全的负线性关系,即两个变量完全负相关。
- 当相关系数为0时,表示两个变量之间不存在线性关系。
Pearson相关系数的计算基于变量之间的协方差和标准差。

Pearson相关系数具有以下特点:
- 当相关系数接近于1或-1时,表示存在较强的线性关系。
- 当相关系数接近于0时,表示两个变量之间的线性关系较弱或不存在。
- 当相关系数为正时,表示两个变量呈正相关关系;当相关系数为负时,表示两个变量呈负相关关系。
Pearson相关系数只衡量线性关系,对于非线性关系无法准确评估。
3.1.5 Discussion
Model calibration :quantify whether the model ‘knows when it doesn’t know’, in that low confidence predictions are correlated with high error rates.
模型校准是指预测模型在评估自身预测的置信度或不确定性时的准确程度。一个良好校准的模型在正确的预测上会给出高置信度,并且在错误的预测上给出低置信度。
为什么开集和闭集检测的准确率高度相关?
如果闭集检测可以对不认识的类给出低置信度,那么就完美符合了开集检测的目的:分类出认识的类同时检测出不认识的类。
3.2 EXPERIMENTS ON LARGE-SCALE DATASETS (ImageNet)
Methods
使用模型:【在Imagenet-21K上进行预训练】
- 卷积神经网络模型:VGG(2015), ResNet(2016) ,EfficientNet(2019),
- 非卷积方法:ViT(2019),MLP-Mixer(2021)
Dataset
闭集:ImageNet-1K中的1000个类
开放集:ImageNet-21K-P数据集中的两个不相交的子集,各1000个类,这两个子集根据与闭集的语义相关程度分为hard和easy两个难度,hard与已知类语义更相近,easy与已知类语义更不同。
Results
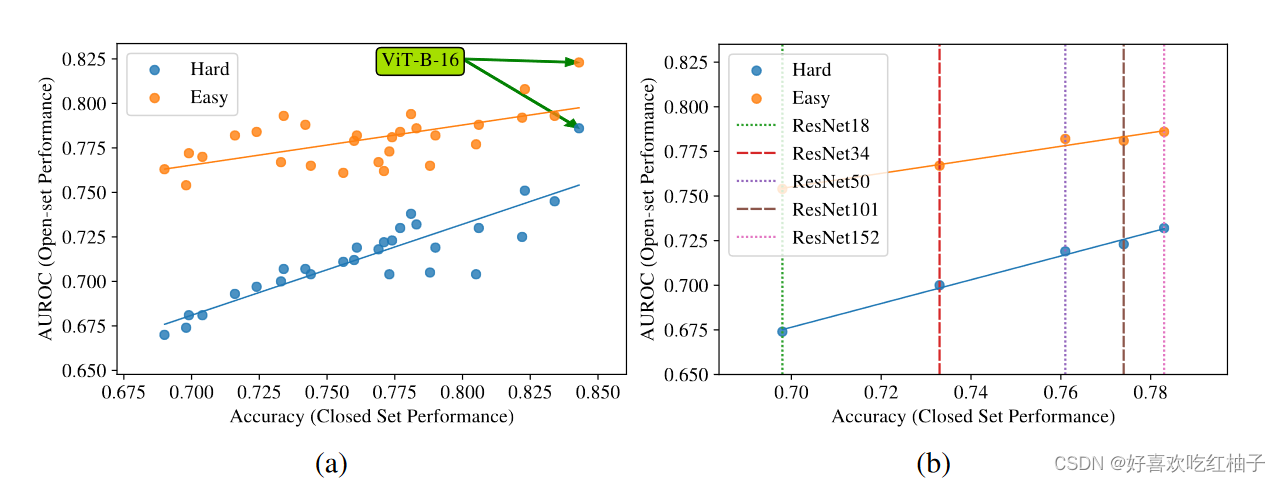
- 依旧呈线性关系,但是与小规模数据集相比,线性相关性降低了, ρ = 0.88 ρ = 0.88 ρ=0.88 for the ‘Hard’ evaluation and ρ = 0.63 ρ = 0.63 ρ=0.63 for the ‘Easy’;
4 A GOOD CLOSED-SET CLASSIFIER IS ALL YOU NEED?
使用一些方法提高闭集分类器的准确率就可以相应的提高开集检测的AUROC
For example: longer training (scatter point 7 - scatter point 8); better augmentations (3 - 5); and ensembling (8 - 9)
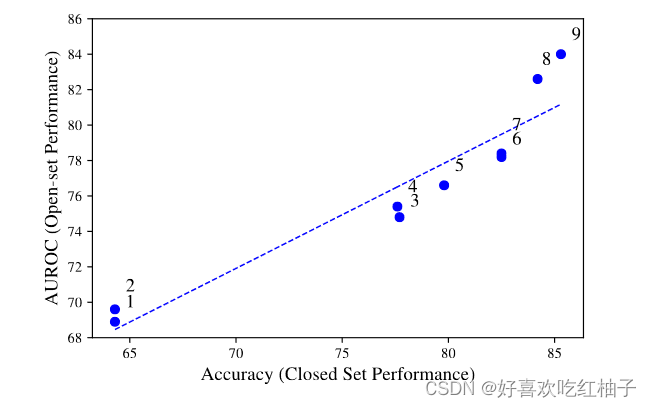
4.1 Logit scoring rule
Logits(对数几率) 是深度分类器中最后一个线性层的原始输出,在经过softmax操作之前,这些输出还没有被归一化,因此不能解释为概率向量,其值之和为一。
由于softmax操作会归一化logits,使其失去了很多特征的幅值信息,因此我们发现logits可以带来更好的开放集检测结果。
对于开放集检测,使用logits可以更直接地利用底层特征及其幅值,而不受softmax引入的归一化的影响。这有助于更有效地区分已知类别和未知类别,从而提高开放集检测的性能。
提出了一个名为maximum logit score (MLS)的新baseline
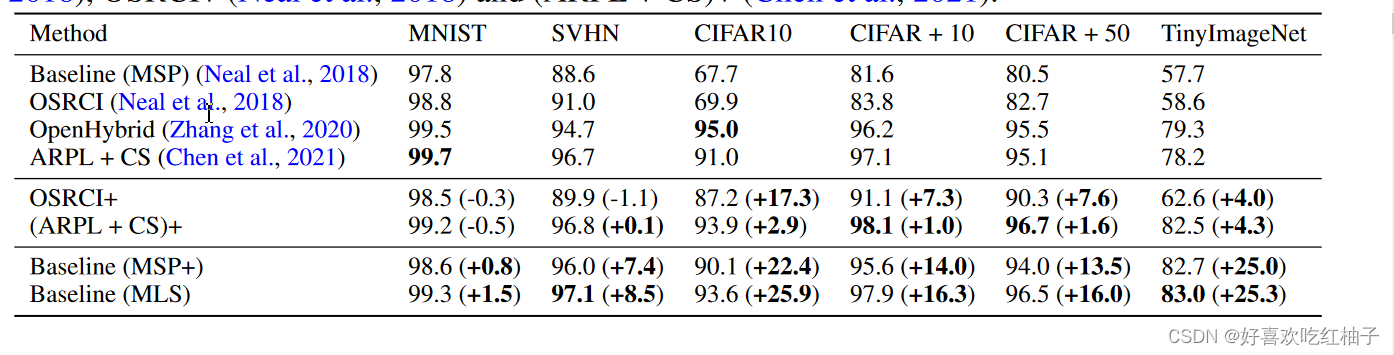
从图中可以看出本文中提出的新baseline(MLS)远远超出了原来的baseline(MSP和MSP+),MLS surpasses the existing state-of-the-art on the SVHN, CIFAR+10, CIFAR+50 and TinyImageNet benchmarks and is, on average, 0.7% better across the entire suite.
4.2 Discussion
Our findings in this section suggest that many of the gains could equally be realised through the standard baseline.
在开放集识别领域中,有许多新方法被提出并进行了改进,这些方法在训练策略、超参数和数据增强等方面进行了精心设计。然而,这些方法往往没有报告闭集准确率,因此很难确定开放集性能提升中有多少是由于闭集准确率的提高所导致的。
研究者通过提出新的评估协议和对比实验发现,在将闭集准确率进行比较后,基准方法的性能与改进方法之间的差异微乎其微,表明许多性能提升可以通过标准基准线实现。 这些发现对于开放集识别方法的评估和进一步改进具有重要意义。
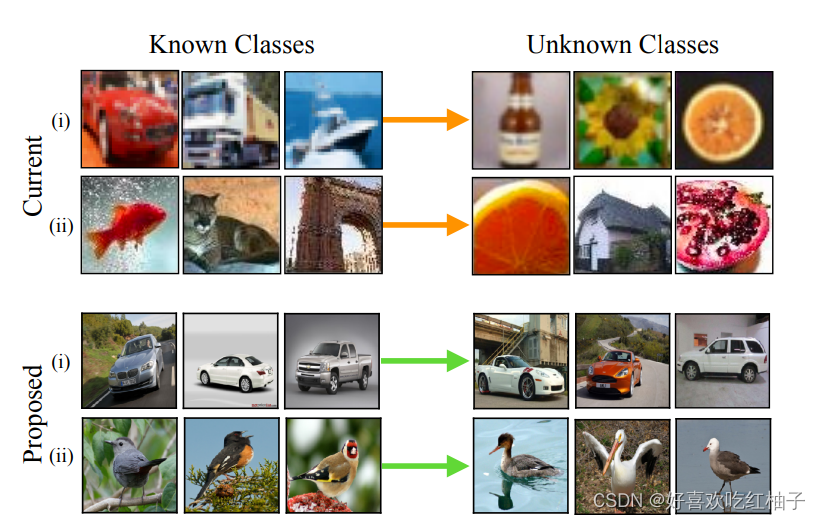
5 SEMANTIC SHIFT BENCHMARK
OSR benchmarks have two drawbacks:
(1) they all involve small scale datasets;
(2) they lack a clear definition of what constitutes a ‘semantic class’
OSR aims to identify whether a test image is semantically different to the training classes
Our evaluation settings all aim to explicitly capture the notion of semantic novelty.
5.1 ImageNet
提出了一种新的划分Hrad和Easy集的新方法:
-
使用ImageNet数据库中的两个子集:ImageNet-1K和ImageNet-21K-P。ImageNet-1K中的类别被视为闭集,即已知的类别。从ImageNet-21K-P的类别中选择开放集类别,这些类别与闭集类别不相交。
-
计算类别之间的语义距离:利用了ImageNet数据库中的类别之间的层次化语义结构。例如,对于类别"elephant",它可以在不同的层次上具有多个标签,如"elephant"、“placental”、“mammal”、“vertebrate"和"animal”。通过计算类别在语义树中的节点之间的路径距离,可以衡量它们之间的语义差异。
-
通过将ImageNet-1K中的类别与ImageNet-21K-P中的类别进行比较,可以确定它们之间的语义距离。根据总的语义距离,将开放集类别划分为"Easy"和"Hard"两组。根据语义距离矩阵中每个类别到闭集类别的距离进行排序,确定easy和hard集。
Easy集分类举例
假设我们有两个闭集类别:狗和猫。我们想要确定一个开放集类别,该类别与闭集中的狗和猫之间的语义距离较大。
在ImageNet-21K-P中,我们可以找到一个与闭集类别语义距离较大的类别,例如"海豚"。假设在ImageNet的语义树中,狗和猫位于较低级别的节点,而"海豚"位于较高级别的节点。这意味着在语义树中,从"海豚"到狗和猫之间存在较长的路径距离,即语义距离较大。
因此,我们可以将"海豚"作为一个语义距离较大的类别,将其纳入"Easy"开放集。
Hard集分类举例
假设我们有两个闭集类别:汽车和卡车。我们想要确定一个开放集类别,该类别与闭集中的汽车和卡车之间的语义距离较小。
在ImageNet-21K-P中,我们可以找到一个与闭集类别语义距离较小的类别,例如"公交车"。假设在ImageNet的语义树中,汽车、卡车和公交车位于相对较高级别的节点,并且它们之间的路径距离相对较短。
因此,我们可以将"公交车"作为一个语义距离较小的类别,将其纳入"Hrad"开放集。
5.2 Fine-grained classification datasets
这一部分分析了细粒度图像数据集和CIFAR+10数据集(OSR评估识别基准数据集)的区别。
5.2.1 Fine-grained classification datasets
细粒度图像数据集语义分类更明确更清晰,在数据集中,所有类别都是该单一类别的变体,定义了一个语义变化的单一轴。由于变化轴被明确定义,分类器就能学习到比较好的特征并且进行合理分类。
e.g. 假设有一个鸟类的FGVC数据集。在该数据集中,我们有许多鸟类的不同物种,比如鹦鹉、鸽子、鸵鸟等。每个类别都是鸟类这个 “入门级(entry level)” 类别的一个变种,定义了一个明确的语义变化轴,即鸟类的物种。在FGVC数据集中,由于明确定义了鸟类物种作为变化轴,我们可以期望分类器能够学习到鸟类物种的特征和区分方法。
5.2.2 Current OSR benchmarks such as CIFAR+10
如果模型使用CIFAR10数据集进行训练并且评估,模型首先在CIFAR10类别中进行训练,例如{airplane, automobile, ship, truck},所有这些类别都可以被视为“入门级”,然后需要将来自CIFAR100类别的图像(例如{bicycle, bee, porcupine, baby})识别为新类别。
在这种情况下,要识别的新类和训练的类关联度不大,变化轴不具体,无法确定OSR模型是在响应真实的语义信号还是仅仅对“未见过”的数据中的低级分布偏移作出反应。此外,由于当前基准设置中训练类别数量较少,对于分类器来学习这样的高级类别定义是不现实的。
举例分析
在CIFAR+10基准中,我们假设模型首先在CIFAR10的四个类别上进行训练:飞机、汽车、船和卡车。这些类别都可以被视为“入门级”类别,它们是相对常见和广泛的物体类别。假设模型要识别CIFAR100数据集的一些新类别,例如自行车、蜜蜂、猪和婴儿。这些类别在语义上与CIFAR10的类别没有明确的关联。
假设我们的模型在CIFAR10的训练中学习到了一些低级特征,例如边缘检测、纹理等。当我们将模型应用于CIFAR100数据集时,它可能仍然依赖于这些低级特征来进行分类。例如,当模型在CIFAR100中遇到一张自行车的图片时,它可能会依赖于低级特征,如轮廓、纹理或颜色来判断。这样,模型可能无法真正理解自行车是一种交通工具,而是仅仅根据低级特征进行分类。
PS: 什么是模型对数据进行低级特征的分布式转移
当我们说模型只是在对“未见过”的数据中进行低级特征的分布式转移时,意味着模型可能没有真正理解新类别的高级语义特征,而是依赖于在训练中学到的一些通用低级特征来进行分类。
在这种情况下,模型可能会将新类别的图像与训练数据中的某些低级特征进行关联,而不是基于真正的高级语义理解。例如,在前面提到的例子中,模型可能会根据自行车图像中的轮廓、纹理或颜色等低级特征来判断其属于自行车类别,而不是基于对自行车作为一种交通工具的理解。
这种低级特征的分布式转移指的是模型将在训练中学习到的低级特征应用于新类别的数据。尽管这种转移可能在某些情况下表现良好,但它并不能保证模型真正理解新类别的语义含义。模型可能会在新类别的数据中出现错误的分类或混淆,因为它没有学习到与新类别相关的高级特征。
因此,这种低级特征的分布式转移是指模型在处理“未见过”的数据时,主要依赖于低级特征而没有真正理解新类别的高级语义特征。这是与细粒度视觉分类(FGVC)数据集不同的一种情况,其中模型需要学习到更具体和高级的类别定义和区分方法。
OSR benchmarks存在问题:
由于训练类别和测试类别之间的语义关系不明确,模型可能无法准确地学习到高级的类别定义和语义特征。
如何解决: 使用细粒度数据图像来作为OSR问题的benchmark并且进行难易程度划分
Propose three FGVC datasets for OSR evaluation:
1. Caltech-UCSD-Birds (CUB) (Wah et al., 2011),
2. Stanford Cars (Krause et al., 2013)
3. FGVC-Aircraft (Maji et al., 2013).
这些数据集中的属性信息可以用于构建开放式的FGVC类别划分,将类别划分为“容易”、“中等”和“困难”三个级别,难度取决于标记的类别属性与训练类别之间的相似性,越相似难度越高,越难分类。
这样的划分可以帮助评估模型在处理具有不同语义转变程度的类别时的性能。
举例分析
在这个例子中,我们使用CUB(Caltech-UCSD Birds-200-2011)数据集进行鸟类分类任务。CUB数据集是一个广泛使用的鸟类细粒度视觉分类数据集,包含200个鸟类,共有约11,788张图像。每个鸟类都有对应的类别标签和标记属性描述。
1. 选择训练类别
在这个例子中,训练集是CUB数据集中的一部分,其中包含了多个鸟类的图像和它们的类别标签。我们可以从训练集中选择一部分鸟类作为我们的训练样本,例如选择红冠蓝尾鸲、红喉山雀、黄腹山雀和绿头鸭作为训练集中的类别。
属性类别如下所示:
- 红冠蓝尾鸲(Red-crowned Blue-tail):标记属性为"has_crest::yes"、“has_tail::blue”。
- 红喉山雀(Red-throated Sunbird):标记属性为"has_crest::yes"、“has_tail::red”。
- 黄腹山雀(Yellow-bellied Sunbird):标记属性为"has_crest::no"、“has_tail::yellow”。
- 绿头鸭(Mallard Duck):标记属性为"has_crest::no"、“has_tail::green”。
2. 选择评估类别
在CUB数据集中,除了红冠蓝尾鸲、红喉山雀、黄腹山雀和绿头鸭之外,还有其他鸟类类别可供选择。我们可以从这些其他类别中选择一部分作为测试集,以评估模型对于未见过的鸟类类别的分类性能。
例如,我们可以选择CUB数据集中的一些其他类别,如蓝喉山雀(Blue-throated Sunbird)、紫嘴鸟(Purple Finch)、白头鹤(White-necked Heron)等作为测试集中的类别。
属性类别如下所示:
- 蓝喉山雀(Blue-throated Sunbird):标记属性为"has_crest::yes"、“has_tail::blue”。
- 紫嘴鸟(Purple Finch):标记属性为"has_crest::no"、“has_tail::purple”。
- 白头鹤(White-necked Heron):标记属性为"has_crest::yes"、“has_tail::white”。
3. 划分难度等级
Hard
在这个例子中,红冠蓝尾鸲和红喉山雀具有冠羽(crest)和彩色尾巴(blue或red),而蓝喉山雀也具有相似的特征。因此,蓝喉山雀可能被归类为难分类的类别。
Easy
在这个例子中,黄腹山雀和绿头鸭的标记属性与训练集中的类别不相似,它们没有冠羽(no crest)并且尾巴的颜色也不同。因此,紫嘴鸟和白头鹤可能被归类为好分类的类别。
Medium
在这个例子中,白头鹤的标记属性与训练集中的类别有一些相似之处(具有冠羽),但尾巴的颜色不同。因此,白头鹤可能被归类为中等难度的类别。
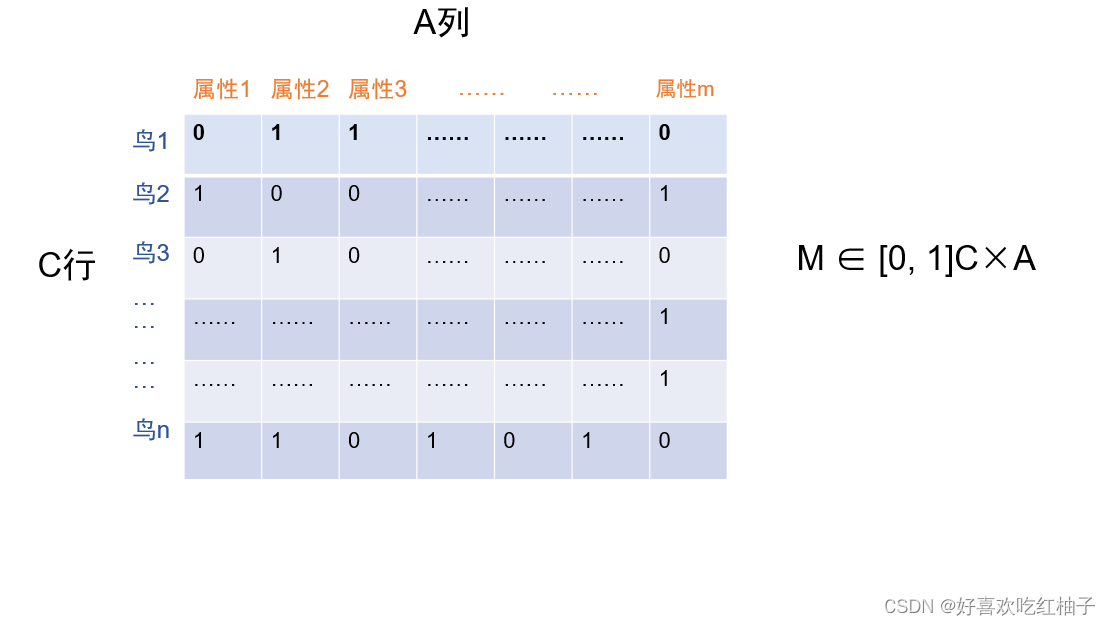
建模公式
使用一个矩阵来进行类别和标签的概括 : M ∈ [ 0 , 1 ] C × A M ∈ [0, 1]^{C×A} M∈[0,1]C×A
每一行就代表着该类具有的属性信息,然后可以把训练集和测试集的每一行进行比较,来进行难易程度划分:每一行越相似说明越难划分,每一行越不相似说明越好划分。
5.3 BENCHMARKING FOR OPEN-SET RECOGNITION
5.3.1 Evaluation Protocol
在细粒度分类中,通常会在ImageNet上进行预训练。然而,在提出的细粒度开放集设置中,这种做法不适用,因为ImageNet中的类别与提出的数据集存在重叠。因此,研究中使用了在Places数据集(Zhou等人,2017)上使用MoCoV2自监督权重(Chen等人,2020b;Zhao等人,2021)进行预训练的网络。对于ImageNet基准测试,可以使用ImageNet-1K数据集上的标签进行训练,并在未见过的类别上进行评估。
5.3.2 Results
Strong closed-set classifiers produce open-set results with good AUROC performance, and the MLS baseline performs comparably to the state-of-the-art method.
6. Conclusion
这项工作展示了在开放集识别任务中模型的闭集性能和开放集性能之间存在强相关性。利用这一发现,证明了在测试时使用最大logit分数(MLS)训练的闭集分类器可以与现有的OSR领域中最先进方法相竞争甚至超越其性能。