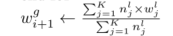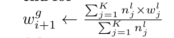第一篇是完全关于应用的,第二篇先使用FedSMB解决NON-IID的情形,发现通信轮数增加了,后又使用FedMMB,解决了上述问题
文献格式:
[1] Sheller M J , Reina G A , Edwards B , et al. Multi-institutional Deep Learning Modeling Without Sharing Patient Data: A Feasibility Study on Brain Tumor Segmentation[J]. Springer, Cham, 2018.
[2] Bakhtiari M , Nasirigerdeh R , Torkzadehmahani R , et al. Federated Multi-Mini-Batch: An Efficient Training Approach to Federated Learning in Non-IID Environments. 2020.
第一篇(不共享患者数据的多机构深度学习建模:脑肿瘤分割的可行性研究)
本文是将联邦学习应用到实际医学影像领域,联邦学习与IIL、CIIL相比,优势明显。IIL和CIIL不能很好地扩展到拥有少量数据的大量机构。
背景
深度模型需要大量的数据,标记医学图像数据需要专家知识,在医学成像领域,图像标注和机构数据的分离,是阻碍数据有效利用的鸿沟,机构之间的协作可以应对这一挑战。
数据预处理:尽管数据在丽联邦中没有集中共享,但需要考虑跨设备配置和采集协议的变化来源。不同采集环境数据在大规模分析研究中的用途和意义有限。预处理方法应该考虑异构数据的协调,允许集成和促进更容易的多机构协作进行大规模分析。
要点
1 在BraTS数据上应用联邦学习建立一个有效的分割模型,通过在中央服务器上迭代聚合本地训练的模型,在不共享任何患者数据的情况下,学习跨多个机构的差异(FedAvg)。
2. 参数 epoch per round(EPR) 影响收敛速度, 模型更新压缩/微调。
当数据分布式Non-iid时,随着参与数量的增加都可能会收敛减缓。
Institutional Incremental Learning (IIL)
IIL是一种简单的协作学习方式,各机构纷纷训练一种共享模式。
问题
1.数量增加,性能会下降
2.灾难性遗忘
Cyclic Institutional Incremental Learning (CIIL)
- CIIL是IIL的循环,在各个机构中循环,并通过在每个机构中固定epoch的数量来减少遗忘。
- 在CIIL循环中,每个机构在将更新后的模型传递给下一个参与者之前,对模型进行一系列的训练,以达到特定数量的epoch。
- CIIL需要额外的验证开销,这使得它比联邦更复杂,效率更低。
量化性能评估矩阵,用Dice 系数,范围是0~1,P,T是预测和实际的标签.
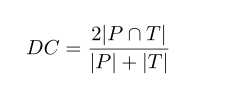
为了进一步提高数值稳定性,使用Adam优化,最小化DC, 增强数值的稳定性, 增加了L的拉普拉斯平滑,并对最终损失函数进行代数重排,用对数减法代替除法:
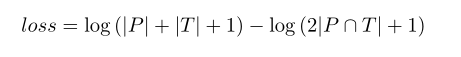
数据标签协议:对不同解剖区域的语义描述符的定义和记录对于允许跨机构的再现。
U-Net topology(不了解)
该模型以单通道图像为输入,输出大小相等的二进制掩码,其中每个像素都被分配一个类标签。该网络模仿了自动编码器的架构,具有捕获上下文的收缩路径(通过最大池)和支持本地化的扩展路径(通过上采样)。
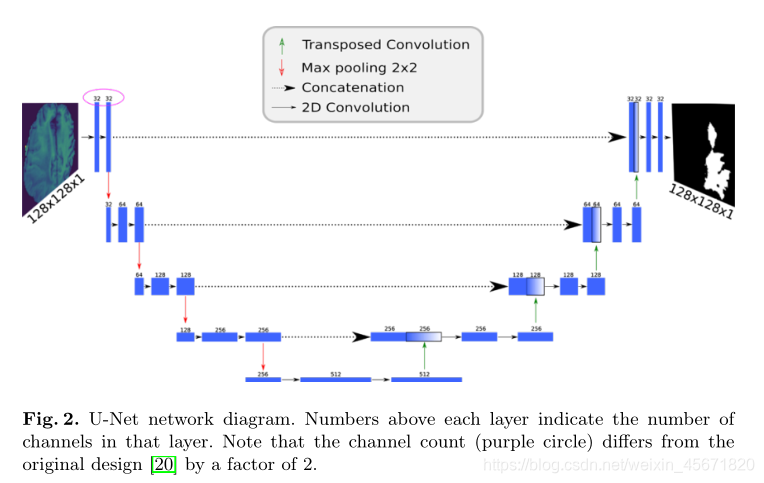
自2015年推出以来,U-Net已迅速成为图像分割的标准深度学习拓扑之一,并在创建用于分割超声图像中的神经、CT扫描中的肺、甚至射电望远镜干扰的预测模型方面发挥了作用。
联合多小批处理:非iid环境中联合学习的有效训练方法
最大精度和通信轮数依赖于客户端本地更新的数量。
问题
- 联邦平均(FedAvg)是一种著名的高效通信的联邦学习算法,如果跨客户机的数据分布是独立和相同分布的(IID),该算法的性能会很好。
- 在非iid环境下,FedAvg的精度较低,并且需要大量的通信回合实现目标精度。
解决方法
1.联邦单小批处理FedSMB,可以在NON-IID中实现集中训练的准确性,但是轮数变多了。
2. 处理轮数变多这一问题,引入了联邦多小批量(FedMMB ),批大小与批计数解耦,并在非iid设置中提供了准确性和通信效率之间的权衡。
过程
- FedSMB:客户端根据其本地数据训练模型的多个小批量,在每个通信轮中执行多个本地更新。
- FedMMB:将批大小从批计数中解耦出来,并允许在客户端指定本地更新的数量,而不受批大小的影响。
模型
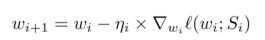
在全梯度下降(FGD)中,利用所有样本来计算损失函数的梯度;
随机梯度下降(SGD)使用单个随机选择的训练数据集样本计算梯度;
小批量梯度下降(MBGD)在随机小批量样本上优化损失函数
对于MBGD, epoch为 [ N B ] [\frac{N}{B}] [BN],其中B为批大小。(本地多计算,减少通信)
用户j有
n
j
n_j
nj个样本,更新本地模型参数
μ
j
=
E
∗
[
N
j
B
]
\mu_j=E*[\frac{N_j}{B}]
μj=E∗[BNj]次,E是本地的轮数,B是批大小,
N
j
N_j
Nj是样本数量,也就是执行MBGD算法E次。
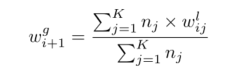
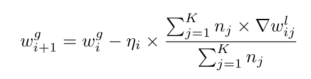
FedMMB算法

- I m a x I_{max} Imax:最大迭代, w j g w^g_j wjg和 η i \eta_i ηi是全局的权重和学习率, w j g w^g_j wjg和 n j l n^l_j njl是局部的权重和样本。 D j D_j Dj是j的本地数据集,包括 N j N_j Nj个样本。
- 本地更新
3.服务器聚合:
- 客户端 P j P_j Pj: 更新T和f,将数据 D j D_j Dj分为长度为B的很多份,计算p,q,n,u, w 0 w_0 w0, 计算 w u w_u wu,n。