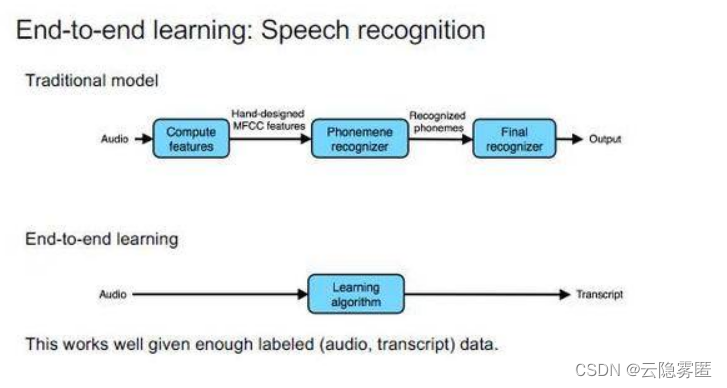
一、端到端(end to end)
从输入端到输出端会得到一个预测结果,将预测结果和真实结果进行比较得到误差,将误差反向传播到网络的各个层之中,调整网络的权重和参数直到模型收敛或者达到预期的效果为止,中间所有的操作都包含在神经网络内部,不再分成多个模块处理。由原始数据输入,到结果输出,从输入端到输出端,中间的神经网络自成一体(也可以当做黑盒子看待),这就是端到端的模型。
优势:
1.只要有足够多的数据,我们不需要知道输入到输出的映射是怎样的,不用引入人类知识,可以充分利用数据本身的信息。
2.所需人工设计的组件更少,能够简化设计工作流程。
二、非端到端(Pipeline)
非端到端是输入->模型A->输出A->模型B->输出B->...->输出。不同于端到端,非端到端可以看作是一个流水线工作,比如在一个典型的NLP问题中,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果。
三、序列到序列(seq2seq)
序列到序列是:输入是序列->模型->输出是序列。
序列到序列一种通用的端到端序列学习方法,它基于编码-解码(Encoder - Decoder)的架构。
应用:
示例一: 翻译。如果用英文的序列作为输入,用法语的作为标签,进行训练模型。即可得到一个英语到法语的翻译器。
示例二:文本摘要。如果使用一个新闻文章和对应的摘要数据进行训练。可得到一个文章内容摘要器。
示例三:QA问答机器人。使用问题和答案数据集进行训练,可得到一个问答机器人或聊天机器人。
reference:
https://blog.csdn.net/qq_38410428/article/details/91381151