官方模型:YOLOv6/README_cn.md at main · meituan/YOLOv6
目录
1、模型和环境准备
1.1 模型下载
首先要做的是将yolov6模型克隆到本地,yolov6模型官网:YOLOv6,你可以点击里面进去下载到本地,也可以 通过git clone的方式下载到本地,如下:
git clone https://github.com/meituan/YOLOv6- 通过git clone的方式下载到本地:
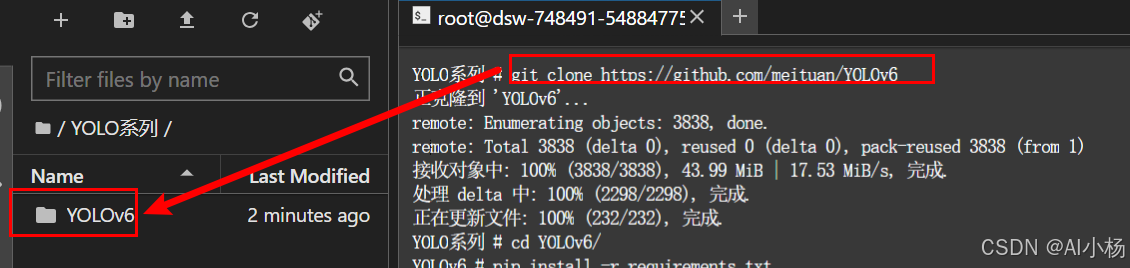
下载到本地后,有一个YOLOv6文件夹,如上。
1.2 依赖环境安装
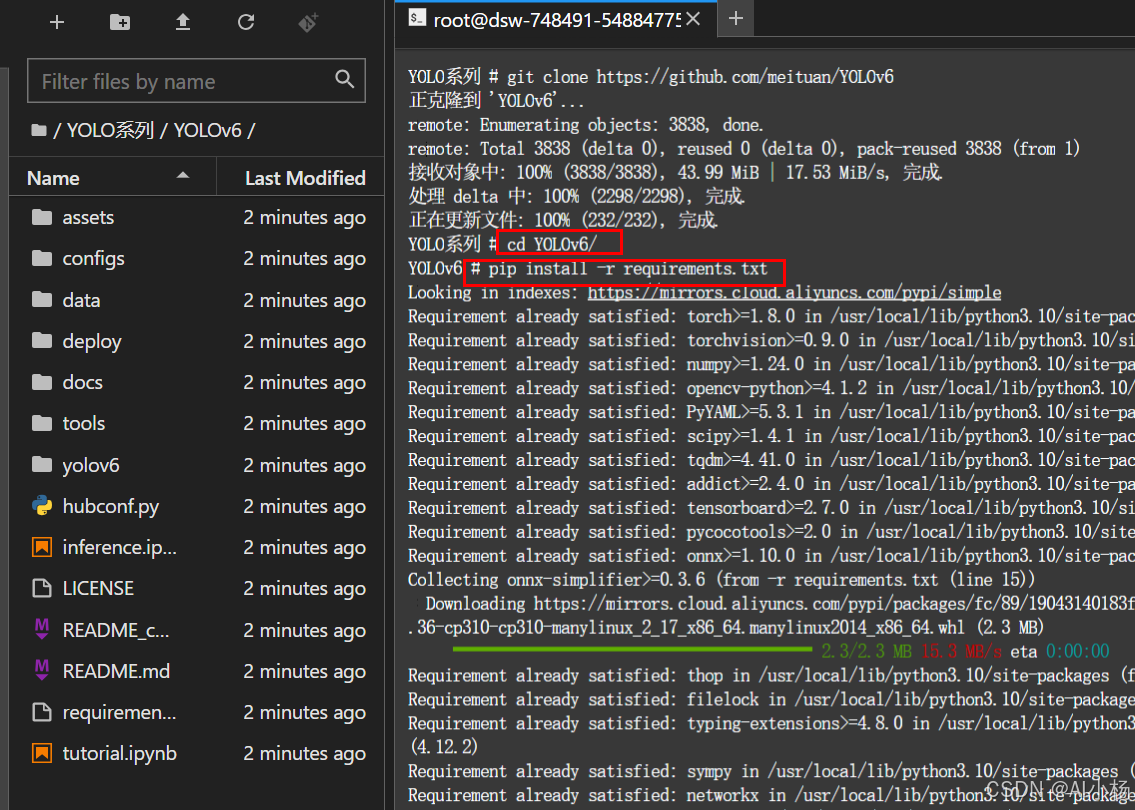
终端指令进入到YOLOv6文件夹下载,进行依赖包按,如下:
cd YOLOv6
pip install -r requirements.txt- 安装如下图:
1.3 权重文件下载
依赖环境安装完成后,进行模型权重文件下载,yolov6的权重文件有多个版本。
进入这个地址下载权重:YOLOv6,找到如下Benchmark模块,如下:
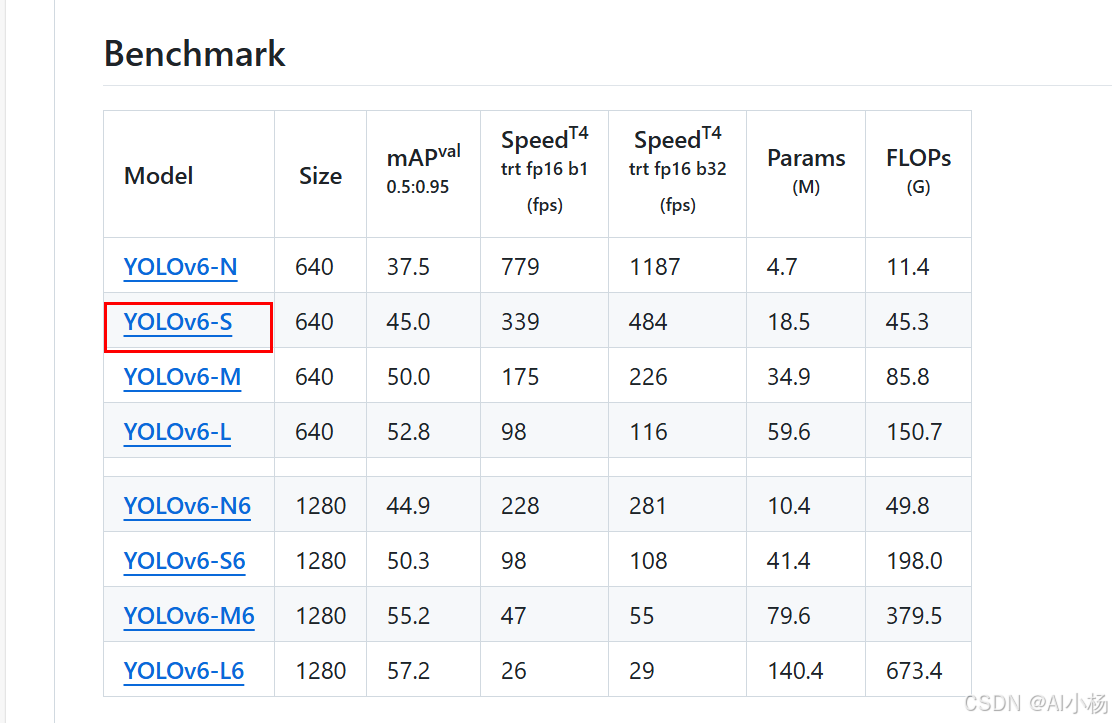
需要用什么模型,就点击对应的模型直接进行下载,例如我用的是yolov6s.pt,即我下载的YOLOv6-S,每一个模型都有自己的特点,详细介绍在下面。
YOLOv6 是一种高效的实时目标检测模型,提供了多种预训练权重模型,每个模型都有其特定的特点和应用场景。以下是 YOLOv6 提供的一些常见预训练权重模型及其主要区别:
模型特点和区别:
1.YOLOv6-N (Nano)
(1)特点:
- 推理速度极快,但在精度上有一定牺牲。
- 极其轻量级的模型,适合资源极度受限的设备。
(2)适用场景:物联网设备、低功耗嵌入式系统等。
(3)权重文件:yolov6n.pt
2.YOLOv6-S (Small)
(1) 特点:
- 较小的模型大小,适合资源受限的设备。
- 推理速度较快,精度较高。
(2) 适用场景:
- 移动设备、嵌入式系统等对模型大小和推理速度有较高要求的场景。
(3) 权重文件:yolov6s.pt
3.YOLOv6-M (Medium)
(1) 特点:
- 模型大小介于 Small 和 Large 之间。
- 精度和速度的平衡较好。
(2) 适用场景:
- 一般用途的目标检测任务,既需要一定的精度又需要较快的推理速度。
(3) 权重文件:yolov6m.pt
4.YOLOv6-L (Large)
(1) 特点:
- 较大的模型大小,具有更高的精度。
- 推理速度相对较慢。
(2) 适用场景:
- 高精度要求的任务,如安全监控、医学影像分析等。
(3) 权重文件:yolov6l.pt
5.YOLOv6-N6 (Nano with 1280x1280 input)
(1) 特点:
- 极轻量级模型,但输入分辨率提高到 1280x1280,提高了精度。
- 推理速度仍然较快。
(2) 适用场景:
- 需要在资源受限设备上获得更高精度的场景。
(3) 权重文件:yolov6n6.pt
6.YOLOv6-S6 (Small with 1280x1280 input)
(1) 特点:
- 较小的模型大小,输入分辨率提高到 1280x1280,提高了精度。
- 推理速度较快。
(2) 适用场景:
- 需要在移动设备上获得更高精度的场景。
(3) 权重文件:yolov6s6.pt
7.YOLOv6-M6 (Medium with 1280x1280 input)
(1) 特点:
- 模型大小介于 Small 和 Large 之间,输入分辨率提高到 1280x1280,提高了精度。
- 精度和速度的平衡较好。
(2) 适用场景:
- 一般用途的目标检测任务,需要更高的精度。
(3) 权重文件:yolov6m6.pt
8.YOLOv6-L6 (Large with 1280x1280 input)
(1) 特点:
- 较大的模型大小,输入分辨率提高到 1280x1280,具有最高的精度。
- 推理速度最慢。
(2) 适用场景:
- 需要最高精度的场景,如科学研究、高精度工业检测等。
(3) 权重文件:yolov6l6.pt
选择合适的模型
选择合适的 YOLOv6 模型取决于您的具体需求:
-
资源限制:如果设备资源有限,选择 Nano 或 Small。
-
精度要求:如果需要高精度,选择 Large 或 L6。
-
速度要求:如果需要快速推理,选择 Nano 或 Small。
-
通用用途:如果需要平衡精度和速度,选择 Medium 或 M6。
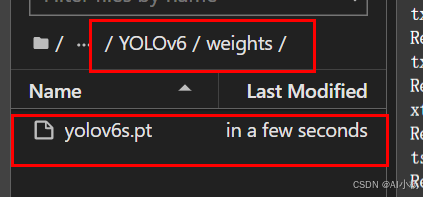
在YOLOv6目录下新建一个weights文件夹,把下载的权重模型放到该文件夹下:
1.4 环境测试
环境部署准备好之后,执行推理,测试环境是否部署成功。
在YOLOv6目录下运行如下代码:
python tools/infer.py - 运行截图:
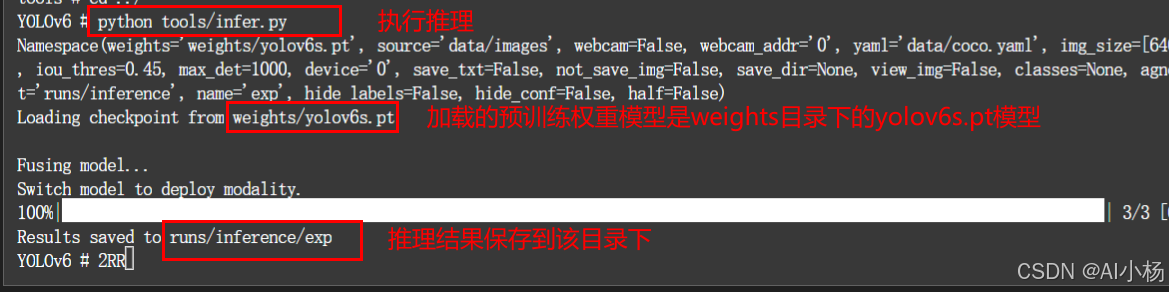
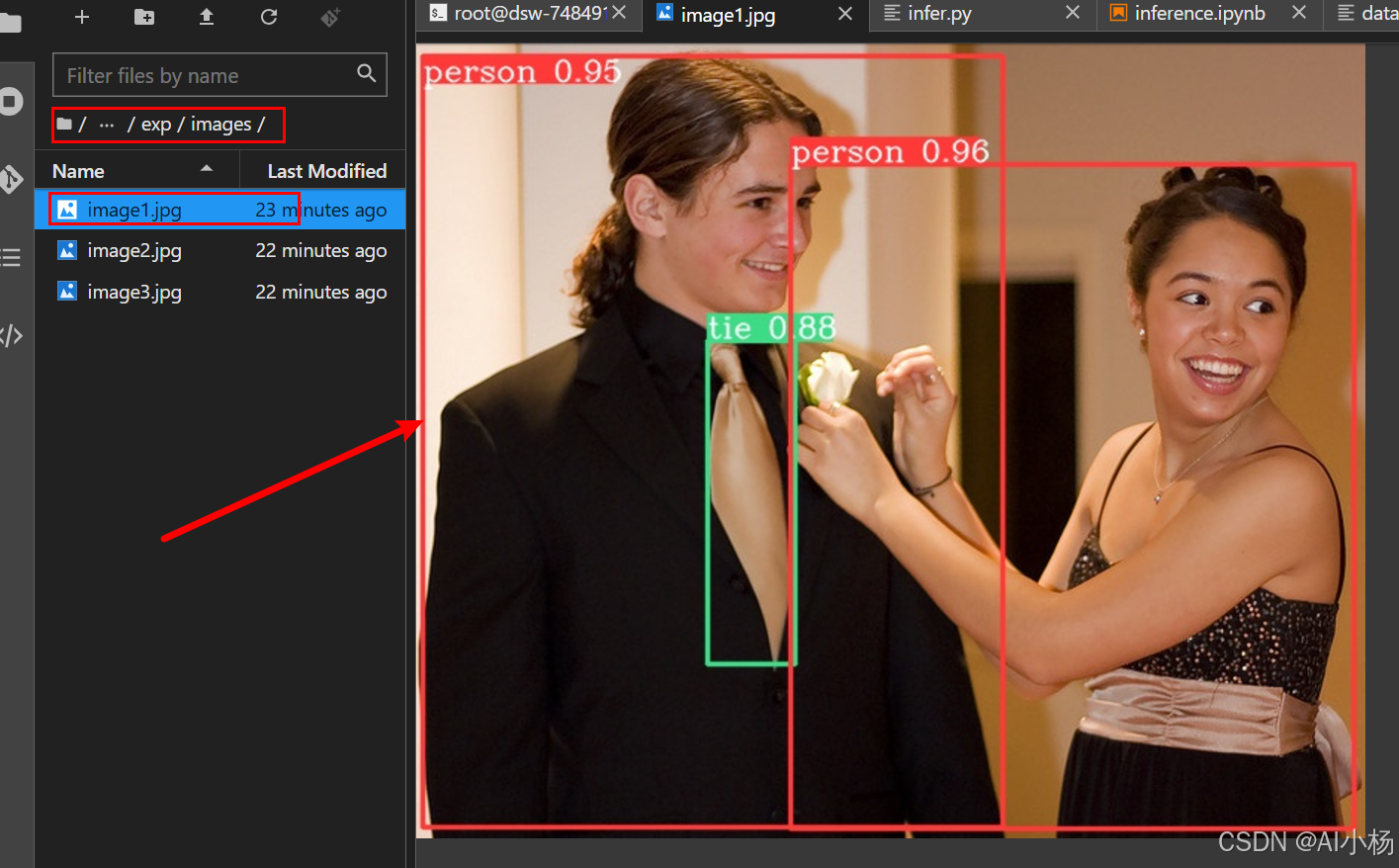
可以看到推理结果存放到runs/inference/exp文件夹下的,即进入该文件夹下(/YOLOv6/runs/inference/exp/images/),可以看到如下推理结果,表示环境准备成功,接下来就可以进行模型训练了。
2、配置文件和数据集准备
2.1 准备数据集
YOLOv6 支持多种格式的数据集,可以YOLO、COCO、VOC等格式的数据集,本次实验我采用的YOLO格式的数据集,YOLO数据集制作参考:数据标注,参考这篇文章的的“一、数据标注篇”下的“2、数据标注与处理”的“2.1 图像标注部分”,将图片和标注文件,按照如下结构进行放置:
datasets/
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ ├── val/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── test/
│ ├── image1.jpg
│ ├── image2.jpg
│ └── ...
├── labels/
│ ├── train/
│ │ ├── image1.txt
│ │ ├── image2.txt
│ │ └── ...
│ ├── val/
│ │ ├── image1.txt
│ │ ├── image2.txt
│ │ └── ...2.2 配置文件准备
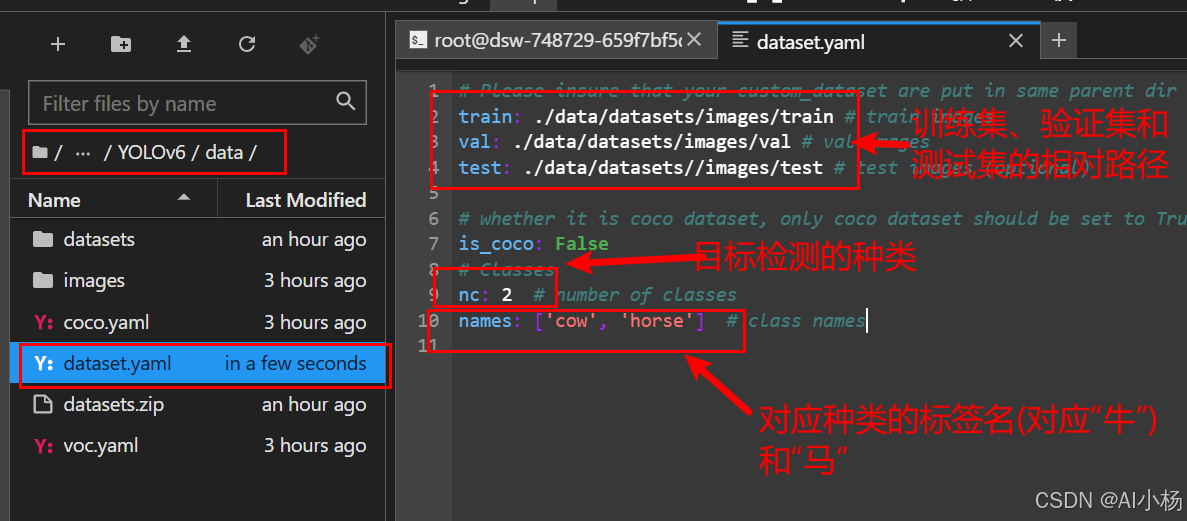
我的实验基于牛马的目标检测,故我的数据是牛和马的数据集,因此我的目标检测的类别是2,对应的标签名称为:cow(牛)、马(horse)。
在如下路径下配置文件:/YOLOv6/data/dataset.yaml,配置文件修改如下:
2.3 BUG修改
YOLOv6模型还是有一个BUG的,不知道是,什么时候可以修复,就是模型训练的时候找不到YOLOv6模型,实验的时候,这一步可以先跳过,直接去训练,如果训练不报这个错误的话就不用管。
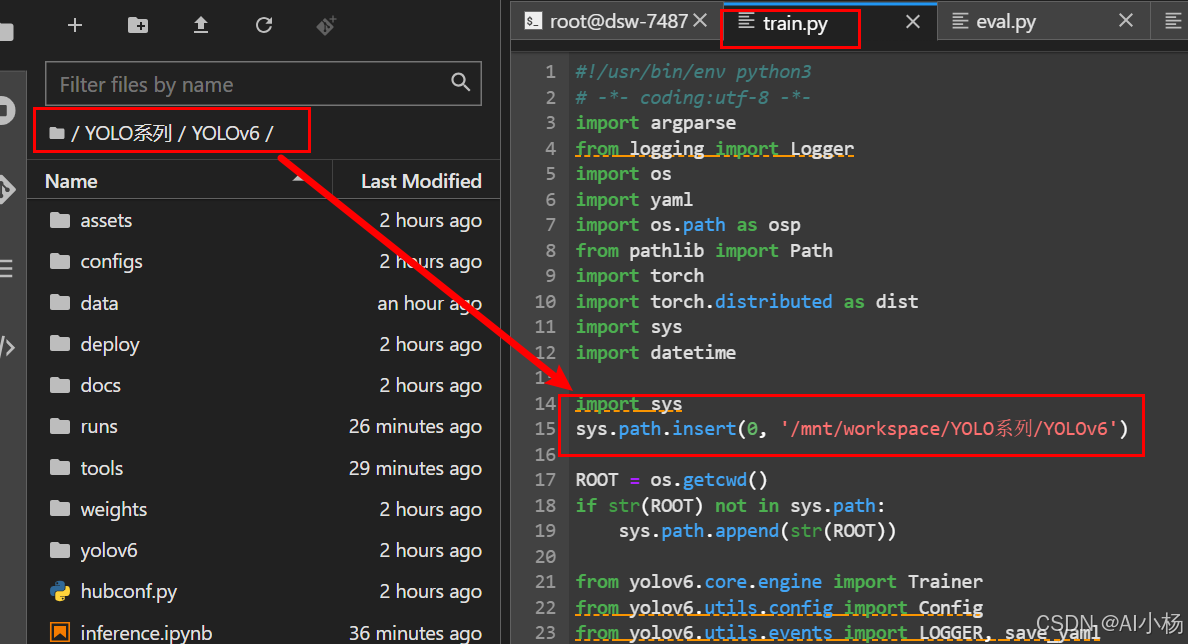
如果训练报错,说找不到什么文件的话,就将下列代码复制到YOLOv6/tools/目录下的train.py的文件里,目的是将YOLOv6 的路径添加到train.py文件中,如下图:
import sys
sys.path.insert(0, '/mnt/workspace/YOLO系列/YOLOv6')(注意“YOLOv6路径选择自己所放文件的绝对路径,例如我的YOLOv6文件是下载到/mnt/workspace/YOLO系列/路径下的,故我的路径是:/mnt/workspace/YOLO系列/YOLOv6”)
3、模型训练
3.1 模型训练
环境、依赖、数据集、配置文件等准备好后,接下来就是进行模型训练。
- 模型训练:
python tools/train.py --batch 32 --epochs 30 --conf configs/yolov6s_finetune.py --data data/dataset.yaml --fuse_ab - 参数详解:
1.--batch 32
- 说明:设置批量大小(batch size)。
- 作用:批量大小决定了每次前向传播和反向传播处理的样本数量。较大的批量大小可以利用 GPU 的并行计算能力,但会占用更多的内存。
- 默认值:通常默认值为 16 或 32,具体取决于硬件配置。
2.--epochs 30
- 说明:设置训练的轮数(epochs)。
- 作用:每个 epoch 表示整个训练数据集被遍历一次。增加 epochs 数量可以提高模型的训练效果,但也可能增加过拟合的风险。
- 默认值:通常默认值为 100 或更高,具体取决于任务的复杂性和数据集的大小。
3.--conf configs/yolov6s_finetune.py
- 说明:指定配置文件的路径。
- 作用:配置文件包含模型的架构、优化器设置、学习率调度等重要参数。
yolov6s_finetune.py是一个用于微调的配置文件。 - 默认值:没有默认值,必须指定。
4.--data data/dataset.yaml
- 说明:指定数据集配置文件的路径。
- 作用:数据集配置文件定义了训练、验证和测试数据集的路径以及类别信息。
dataset.yaml文件通常包含图像路径和标签路径。 - 默认值:没有默认值,必须指定。
5.--fuse_ab
- 说明:启用融合操作(fuse operation)。
- 作用:融合操作可以优化模型的性能,特别是在推理阶段。
--fuse_ab参数通常用于优化模型的卷积层。 - 默认值:通常默认情况下不启用,需要手动添加此参数。
模型训练过程如下:
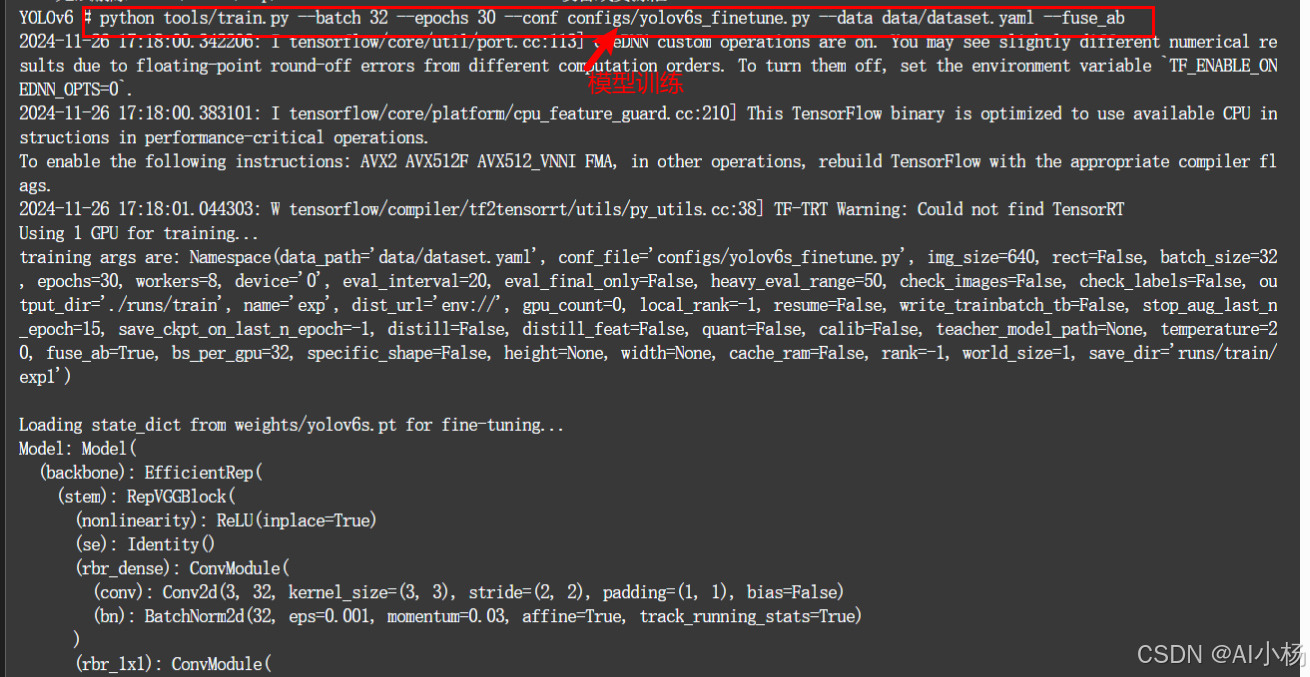
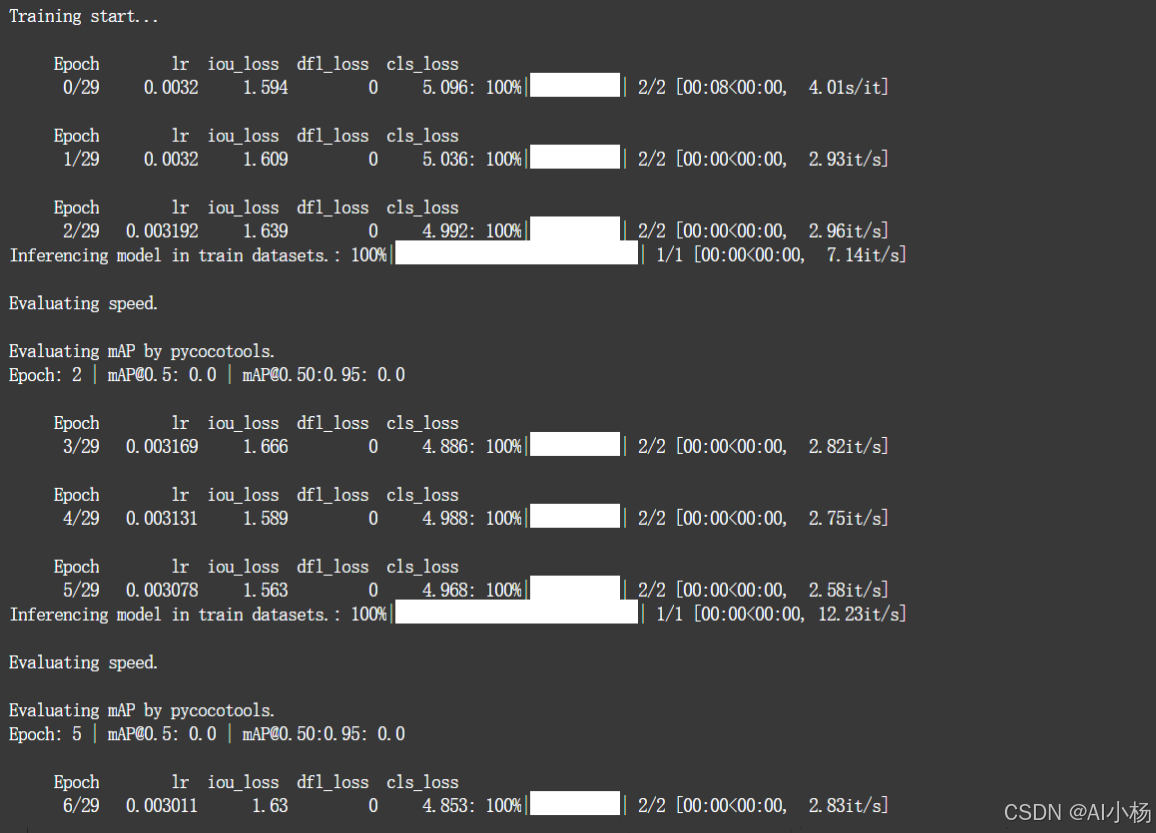
模型训练完成:
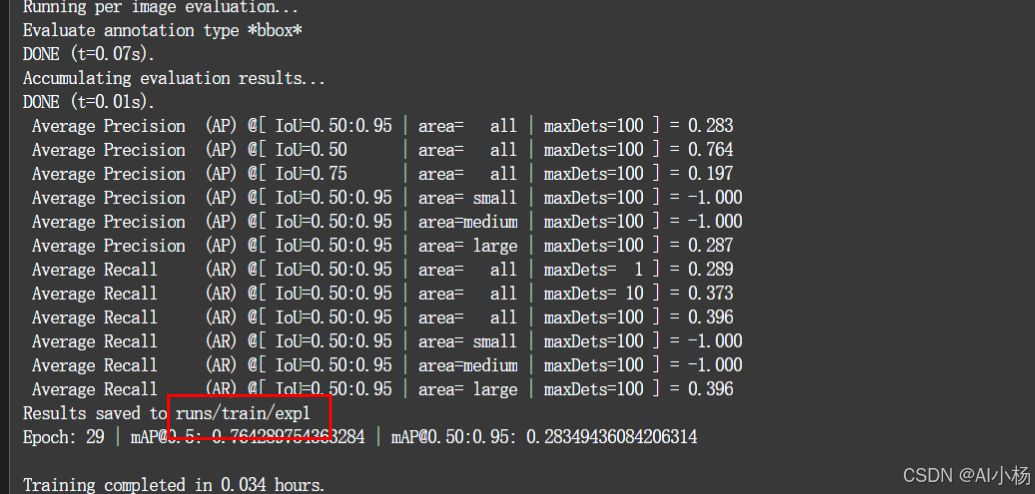
3.2 训练结果介绍
上图可以看出模型训练完成后,将训练的结果存放到runs/train/exp目录下,进入到该目录下,如下:
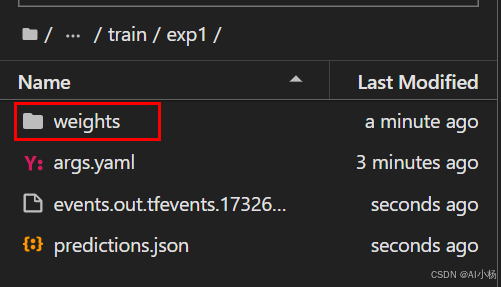
该目录下有一个weights权重文件,里面存放的训练好的模型权重:
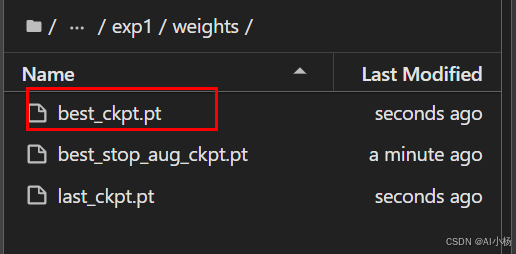
在 YOLOv6 模型训练过程中,通常会生成多个权重文件,其中最常见的两个是 best_ckpt.pt 和 last_ckpt.pt。这两个文件有不同的用途和含义:
(1). best_ckpt.pt
- 说明:这是在整个训练过程中表现最好的模型权重文件。
- 选择标准:通常根据验证集上的某个评估指标(如 mAP,即平均精度均值)来选择最佳模型。当某个 epoch 的验证集性能达到最优时,模型的权重会被保存为
best_ckpt.pt。 - 用途:用于最终的模型部署和测试。因为这是在验证集上表现最好的模型,所以通常会选择它作为最终模型。
(2). last_ckpt.pt
- 说明:这是训练结束时最后一个 epoch 的模型权重文件。
- 选择标准:无论最后一个 epoch 的验证集性能如何,都会保存这个模型的权重。
- 用途:用于继续训练或进行进一步的微调。如果训练过程中断,可以使用
last_ckpt.pt从最后一个 epoch 继续训练。
(3)区别总结
- 最佳性能 vs 最新状态:
best_ckpt.pt是在验证集上表现最好的模型,通常用于最终的模型部署和测试。last_ckpt.pt是训练结束时的最新模型,通常用于继续训练或微调。
综上所述,best_ckpt.pt是训练过程中表现最好的模型,故后续的模型评估和模型推理部署都用改模型。
4、模型评估与推理
4.1 模型评估
接下来是用训练好的最佳的权重模型best_ckpt.pt模型进行模型评估:
python tools/eval.py --data data/dataset.yaml --batch 32 --weights ./runs/train/exp1/weights/best_ckpt.pt --task val参数详解:
(1)--data data/dataset.yaml
- 说明:指定数据集配置文件的路径。
- 作用:数据集配置文件定义了训练、验证和测试数据集的路径以及类别信息。
dataset.yaml文件通常包含图像路径和标签路径。
(2)--batch 32
- 说明:设置批量大小(batch size)。
- 作用:批量大小决定了每次前向传播处理的样本数量。较大的批量大小可以利用 GPU 的并行计算能力,但会占用更多的内存。
(3)--weights runs/train/exp1/weights/best_ckpt.pt
- 说明:指定模型权重文件的路径。
- 作用:模型权重文件包含训练好的模型参数。在这里,您指定了
best_ckpt.pt文件,这是在验证集上表现最好的模型权重。
(4)--task val
- 说明:指定任务类型。
- 作用:
val表示在验证集上进行评估。其他可能的值包括test(在测试集上进行评估)。
(5)模型评估过程截图示例:
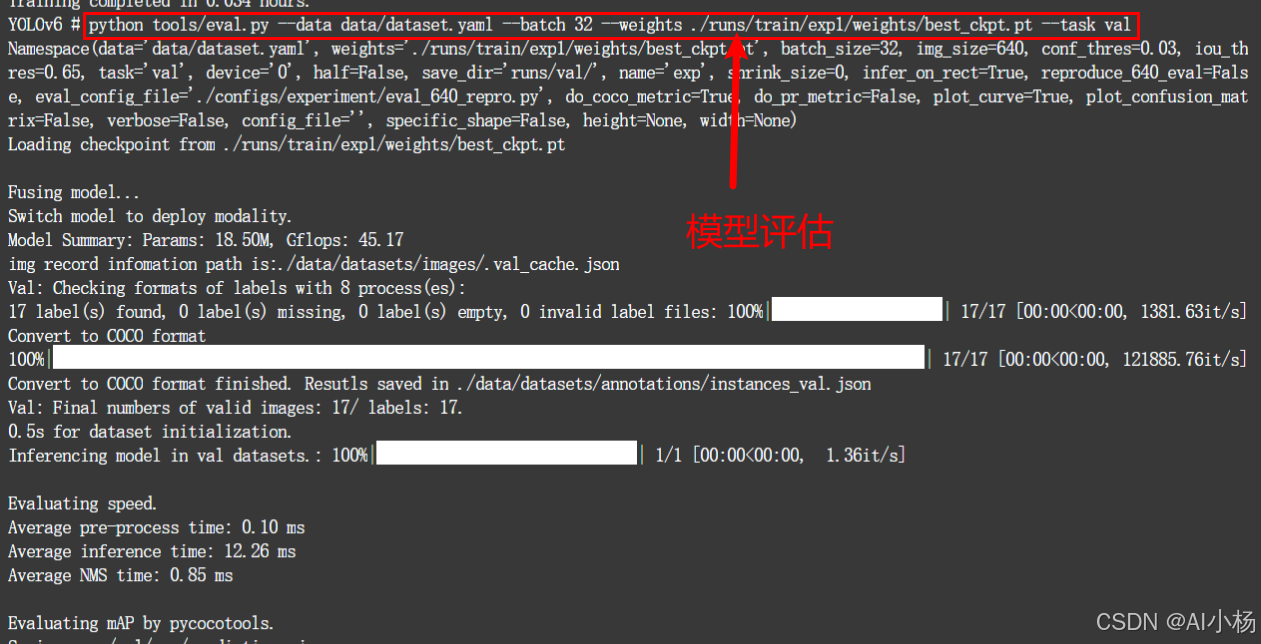
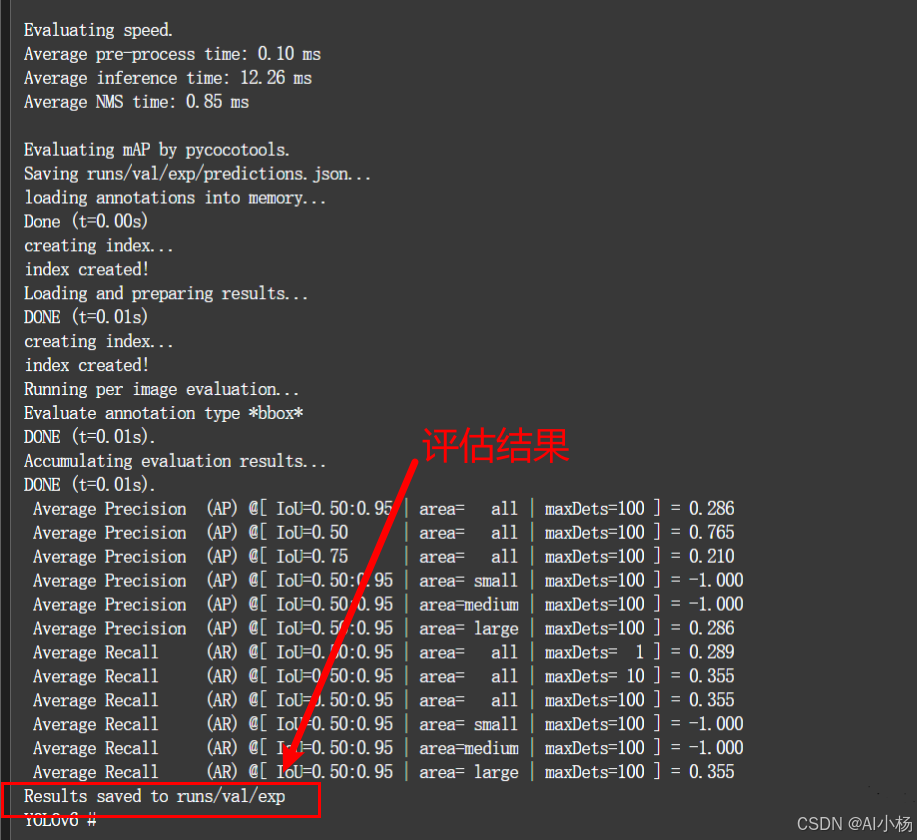
如上图,模型评估后结果存放到runs/val/exp目录下,进入到该目录就可以看到模型评估的结果了。
4.2 模型推理
接下来是模型推理,模型推理如下:
python tools/infer.py --weights ./runs/train/exp1/weights/best_ckpt.pt --source ./data/datasets/images/test参数详解
(1)--weights runs/train/exp1/weights/best_ckpt.pt
- 说明:指定模型权重文件的路径。
- 作用:模型权重文件包含训练好的模型参数。在这里,您指定了
best_ckpt.pt文件,这是在验证集上表现最好的模型权重。
(2)--source data/datasets/images/test
- 说明:指定输入数据的路径。
- 作用:输入数据可以是单个图像文件、目录中的多个图像文件或视频文件。在这里,您指定了一个包含测试图像的目录。
(3)模型推理过程如下:
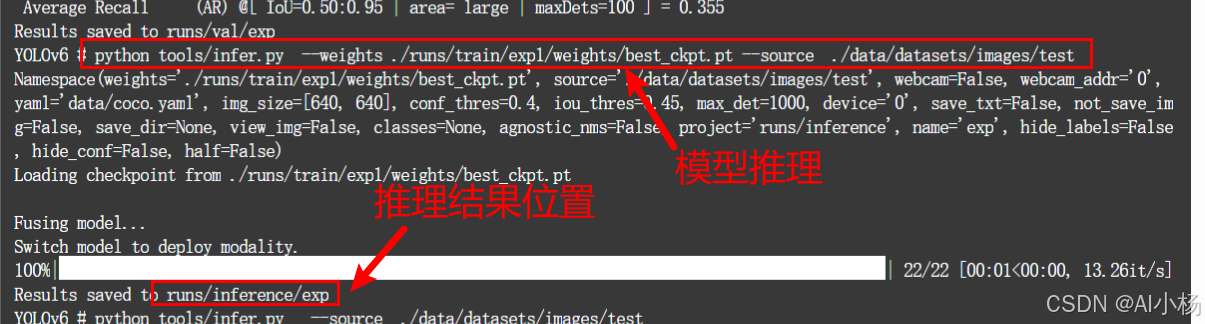
模型预测成功后,如上图,预测结果存放到runs/inference/exp目录下,进入该目录,就可以看到预测的结果,预测的结果部分示例如下:




