一、IDEA操作
1、打断点
1.打断点的基本操作
开始 debug 之前,首先需要学会在代码中打断点,非常简单,直接在代码左侧单击鼠标左键即可。
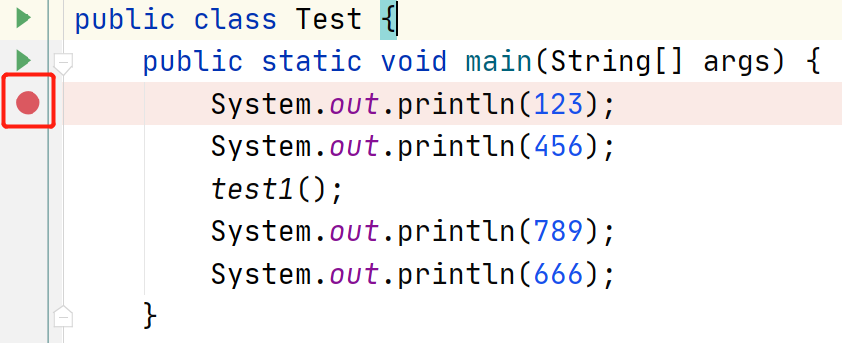
然后,启动程序不能使用 run 的方式,而是要点击 debug。
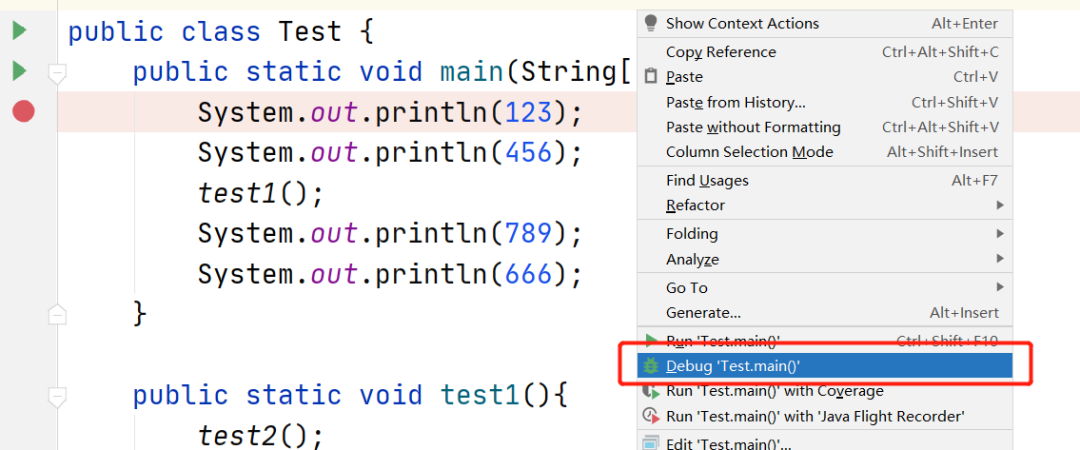
当看到如下状态的时候,说明已经进入了断点。
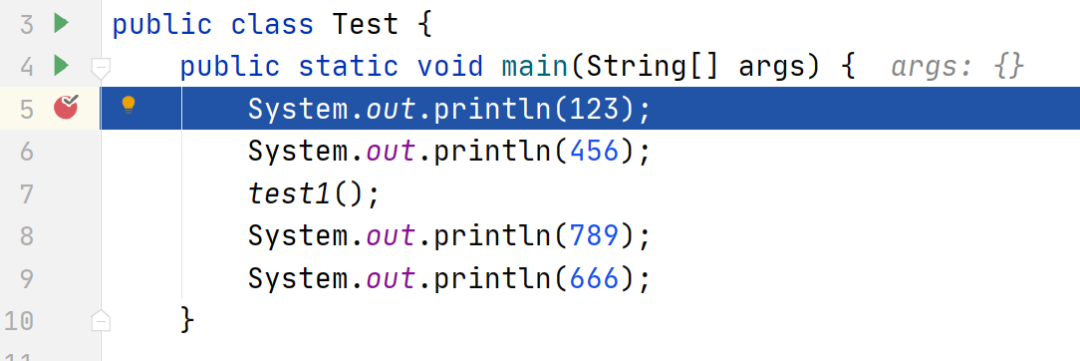
然后我们会在 IDEA 中看到这样一个界面,有很多按钮,接下来楠哥逐个给大家讲解每个按钮的作用。
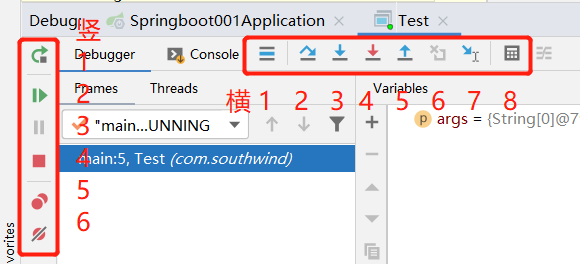
我们先说横排的 8 个按钮,我会按照横 1、横 2 这样的命名方式来介绍。
横 1:从其他界面回到当前断点界面光标处。
横 2:从断点处开始,逐行执行代码,如果遇到方法,直接跳过。
横 3:从断点处开始,逐行执行代码,如果遇到方法,会进入方法,但是只能进入自定义方法,不会进入官方类库的方法。
横 4:从断点处开始,逐行执行代码,如果遇到方法,会进入方法,适用于所有方法。
横 5:从当前断点处回退,回到方法的调用处。
横 6:回退断点,回到上一个断点处,与横 5 的区别在于,它会回到上一个方法的断点中,而横 5 只会回到上一个方法的调用处,并不会进入方法。
横 7:回到断点光标处,与横 1 的区别在于,它会继续往后执行一行代码。
横 8:计算表达式,在 debug 模式中,可以直接输入当前类中的任意一个方法,直接进行运算,输出结果,如下图所示。
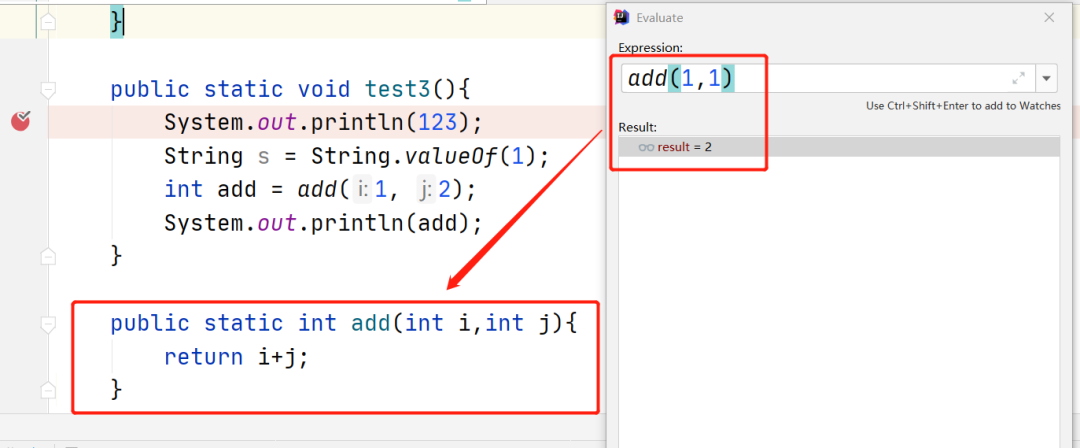
好了,介绍完横排按钮之后,接下来介绍竖排各个按钮的作用。
竖 1:重新运行程序,进入 debug 模式。
竖 2:执行程序,但不是逐行执行,而是跳转到下一个断点处。
竖 3:暂停断点,这个基本用不到。
竖 4:终止程序的运行。
竖 5:显示所有断点,如下图所示。
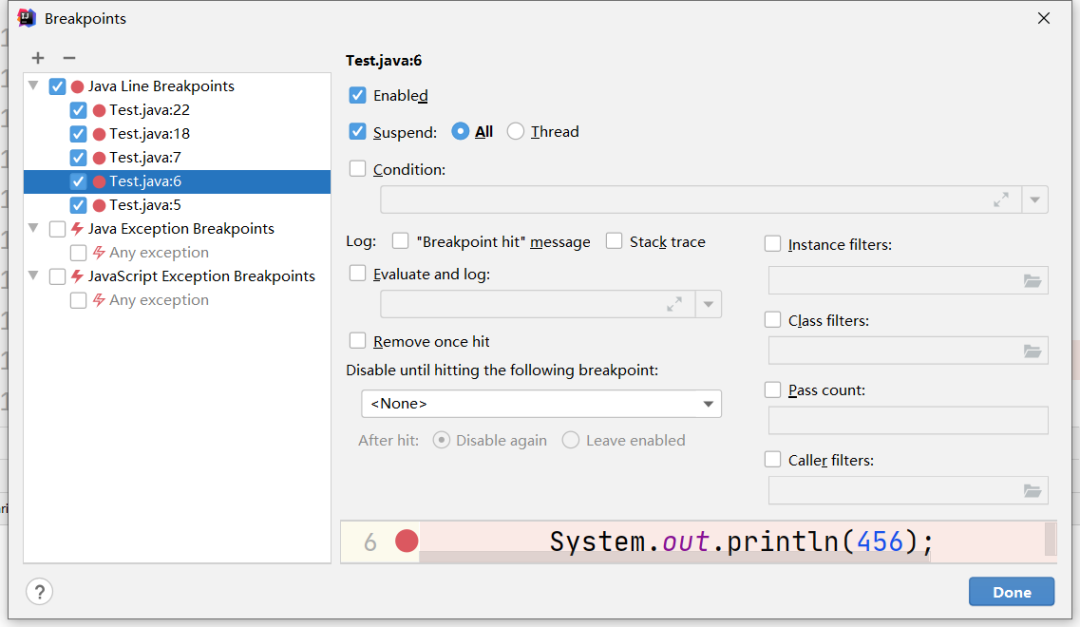
竖 6:让所有断点失效,debug 不再进入断点,要恢复断点,再次点击此按钮即可。
2、实际开发断点技巧
通过上面的步骤,想必大家已经学会了如何打断点,那么接下来楠哥再给大家介绍几种实际开发中常用的断点调试技巧,学会之后,写代码简直不要太香。
1、设置断点条件
可以手动设置进入断点的条件,比如代码如下所示。
for (int i = 0; i < 100; i++) {
System.out.println(i);
}
复制
如果我们在这个循环中打断点,那么每次执行循环都会进入断点,我们可以通过设置断点条件来控制是否进入断点,比如只需要在 i = 10 的时候进入断点,则可以在断点处右键,在弹出的对话框的 Condition 中输入条件,如下所示。
复制
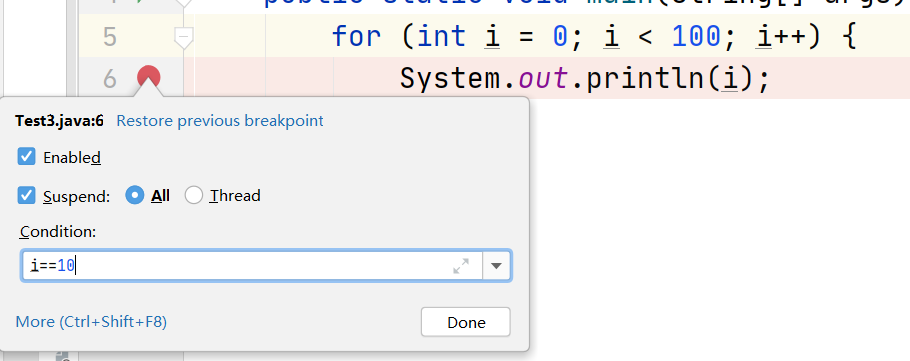
再次执行程序,可以看到 i == 10 的时候进入断点。

2.动态修改变量的值
在 debug 模式中,可以手动修改程序中变量的值,比如代码如下所示。
public static void test3(){
int add = add(1, 2);
System.out.println(add);
}
public static int add(int i,int j){
return i+j;
}
复制
变量 add 的值应该是 3,我们可以手动修改它的值,在控制台的 Variables 中选择 Set Value,具体操作如下所示。
复制
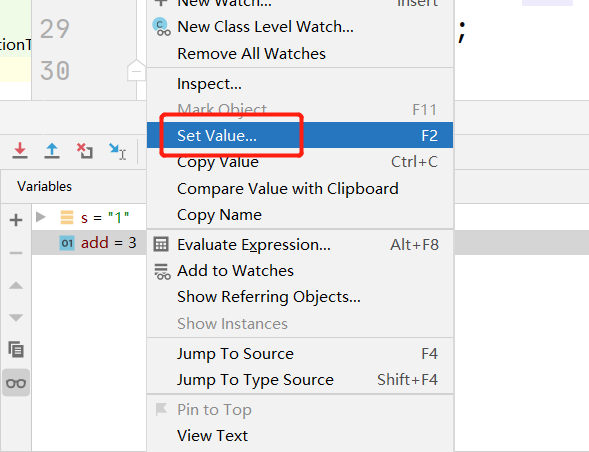
然后继续执行代码,可以看到控制台输出的就是 6。

当然,这只是临时的修改,下一次程序运行,结果仍然是 3。
3.多线程断点调试
在多线程的情况下,我们可以对线程的执行顺序进行控制,比如代码如下所示。
new Thread(()->{
System.out.println("线程1-1");
System.out.println("线程1-2");
System.out.println("线程1-3");
}).start();
new Thread(()->{
System.out.println("线程2-1");
System.out.println("线程2-2");
System.out.println("线程2-3");
}).start();
复制
运行结果如下图所示。
复制

如果我们希望按照 线程1-1,线程2-1,线程1-2,线程2-2,线程1-3,线程2-3 的顺序输出,可以通过设置断点执行顺序来实现,具体操作如下所示。
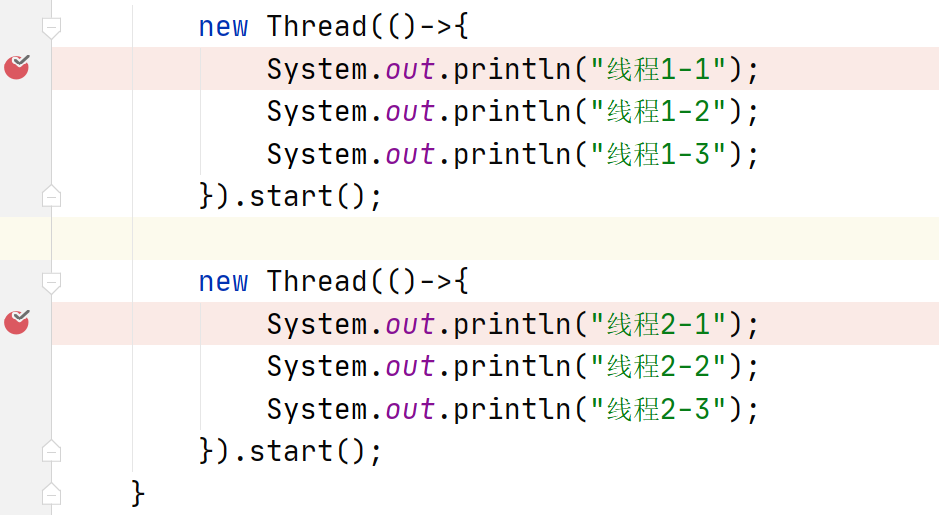
先在两个线程代码中打断点,然后在断点处右键,设置为 Thread,如下图所示。
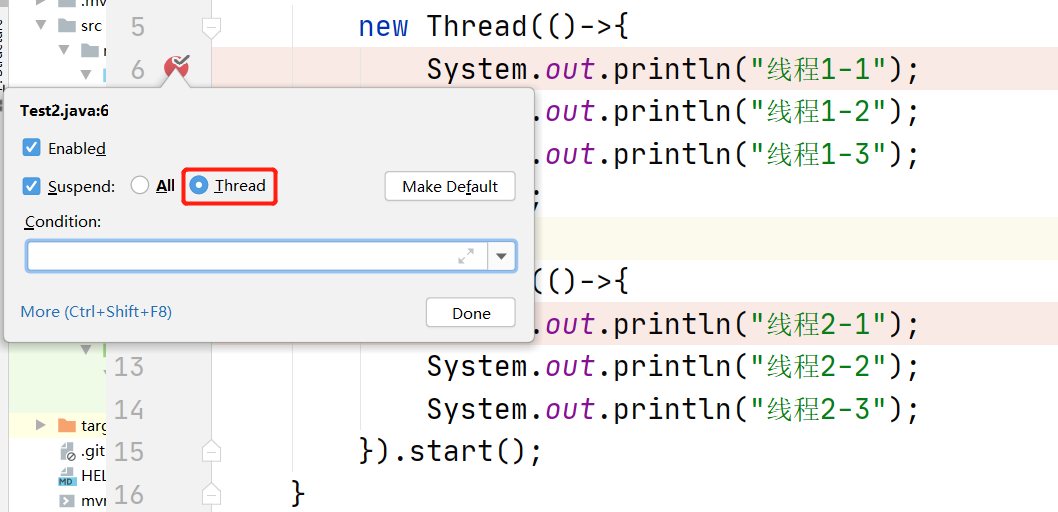
接下来执行程序,进入断点的时候,通过切换当前线程来实现交替执行,比如第一次执行为 Thread-0,那么接下来就切换到 Thread-1 执行,然后再切换到 Thread-0 来执行,如下图所示。
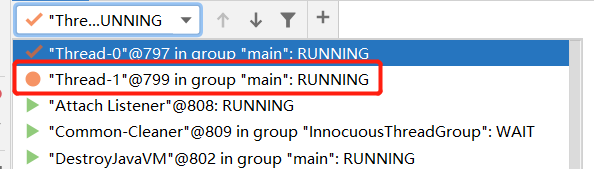
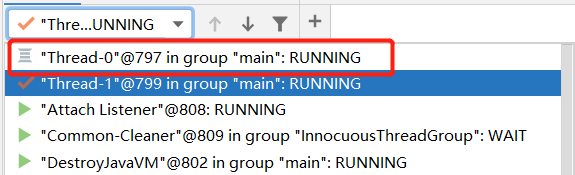
这样反复切换执行完毕之后,运行结果如下图所示。
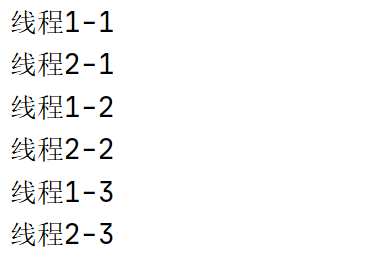
4.同时运行多个服务。
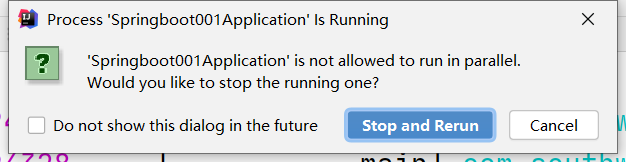
我们在做分布式开发的时候,同一个项目往往同时要启动调试多个服务实例,但是当我们第二次启动服务的时候,会弹出如下界面,意思是需要停止当前服务,才能重新启动第二个。
这个问题我们只需要做一个简单的配置就能解决,选择 Edit Configurations。
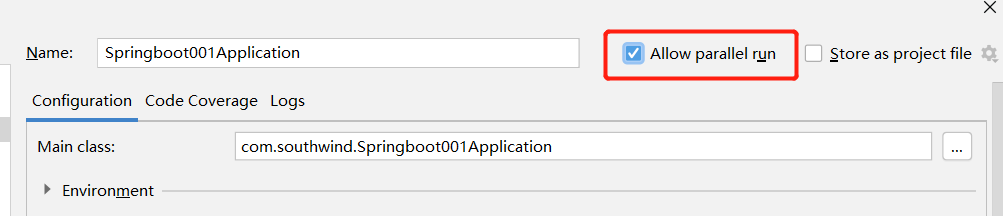
在弹出的窗口中勾选 Allow parallel run 即可,这样就可以同时启动多个服务了。
2.IDEA阅读源码技巧
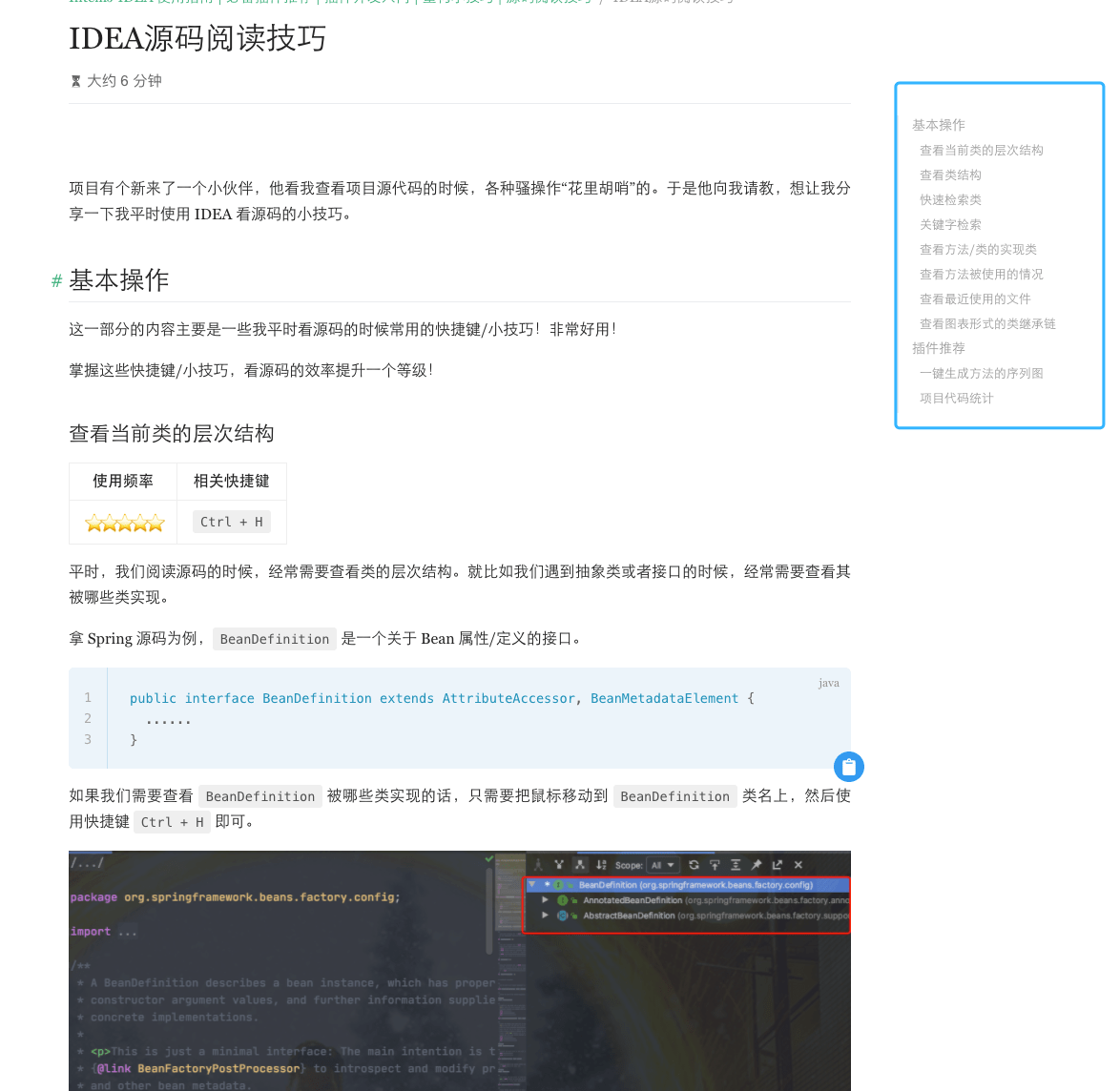
二、资源网站
1.linux在线速查手册
https://www.w3xue.com/manual/linux/
三、MySQL
1.基础操作
/* Windows服务 */
-- 启动MySQL
net start mysql
-- 创建Windows服务
sc create mysql binPath= mysqld_bin_path(注意:等号与值之间有空格)
/* 连接与断开服务器 */
mysql -h 地址 -P 端口 -u 用户名 -p 密码
SHOW PROCESSLIST -- 显示哪些线程正在运行 processlist
SHOW VARIABLES -- 显示系统变量信息 variables
2.数据库操作
/* 数据库操作 */
-- 查看当前数据库
SELECT DATABASE();
-- 显示当前时间、用户名、数据库版本
SELECT now(), user(), version();
-- 创建库
CREATE DATABASE[ IF NOT EXISTS] 数据库名 数据库选项
数据库选项:
CHARACTER SET charset_name
COLLATE collation_name
-- 查看已有库
SHOW DATABASES[ LIKE 'PATTERN']
-- 查看当前库信息
SHOW CREATE DATABASE 数据库名
-- 修改库的选项信息
ALTER DATABASE 库名 选项信息
-- 删除库
DROP DATABASE[ IF EXISTS] 数据库名
同时删除该数据库相关的目录及其目录内容
3.表的操作
-- 创建表
CREATE [TEMPORARY] TABLE[ IF NOT EXISTS] [库名.]表名 ( 表的结构定义 )[ 表选项]
每个字段必须有数据类型
最后一个字段后不能有逗号
TEMPORARY 临时表,会话结束时表自动消失
对于字段的定义:
字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
-- 表选项
-- 字符集
CHARSET = charset_name
如果表没有设定,则使用数据库字符集
-- 存储引擎
ENGINE = engine_name
表在管理数据时采用的不同的数据结构,结构不同会导致处理方式、提供的特性操作等不同
常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
不同的引擎在保存表的结构和数据时采用不同的方式
MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引
InnoDB表文件含义:.frm表定义,表空间数据和日志文件
SHOW ENGINES -- 显示存储引擎的状态信息
SHOW ENGINE 引擎名 {LOGS|STATUS} -- 显示存储引擎的日志或状态信息
-- 自增起始数
AUTO_INCREMENT = 行数
-- 数据文件目录
DATA DIRECTORY = '目录'
-- 索引文件目录
INDEX DIRECTORY = '目录'
-- 表注释
COMMENT = 'string'
-- 分区选项
PARTITION BY ... (详细见手册)
-- 查看所有表
SHOW TABLES[ LIKE 'pattern']
SHOW TABLES FROM 库名
-- 查看表结构
SHOW CREATE TABLE 表名 (信息更详细)
DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
-- 修改表
-- 修改表本身的选项
ALTER TABLE 表名 表的选项
eg: ALTER TABLE 表名 ENGINE=MYISAM;
-- 对表进行重命名
RENAME TABLE 原表名 TO 新表名
RENAME TABLE 原表名 TO 库名.表名 (可将表移动到另一个数据库)
-- RENAME可以交换两个表名
-- 修改表的字段机构(13.1.2. ALTER TABLE语法)
ALTER TABLE 表名 操作名
-- 操作名
ADD[ COLUMN] 字段定义 -- 增加字段
AFTER 字段名 -- 表示增加在该字段名后面
FIRST -- 表示增加在第一个
ADD PRIMARY KEY(字段名) -- 创建主键
ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
ADD INDEX [索引名] (字段名) -- 创建普通索引
DROP[ COLUMN] 字段名 -- 删除字段
MODIFY[ COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
CHANGE[ COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
DROP INDEX 索引名 -- 删除索引
DROP FOREIGN KEY 外键 -- 删除外键
-- 删除表
DROP TABLE[ IF EXISTS] 表名 ...
-- 清空表数据
TRUNCATE [TABLE] 表名
-- 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
-- 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
-- 检查表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
-- 优化表
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
-- 修复表
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
-- 分析表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
四、Spring&SpringBoot常用注解
1.SpringBootApplication
这个注解是 Spring Boot 项目的基石,创建 SpringBoot 项目之后会默认在主类加上
@SpringBootApplication
public class SpringSecurityJwtGuideApplication {
public static void main(java.lang.String[] args) {
SpringApplication.run(SpringSecurityJwtGuideApplication.class, args);
}
}
我们可以把 @SpringBootApplication看作是 @Configuration、@EnableAutoConfiguration、@ComponentScan 注解的集合。
package org.springframework.boot.autoconfigure;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
......
}
package org.springframework.boot;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
}
根据 SpringBoot 官网,这三个注解的作用分别是:
@EnableAutoConfiguration:启用 SpringBoot 的自动配置机制@ComponentScan: 扫描被@Component(@Repository,@Service,@Controller)注解的 bean,注解默认会扫描该类所在的包下所有的类。@Configuration:允许在 Spring 上下文中注册额外的 bean 或导入其他配置类
2.Spring Bean相关
2.1@Autowired
自动导入对