古文字识别助手与众包平台——项目博客五
背景:
由于本项目算法部分为使用python编写,所以需要在springboot中调用外部的python程序进行计算本项目算法评分模块。
在登录功能和社区功能的搭建的基础上,完成了社区的获取帖子、发帖、点赞。
在搭建完em模型之后,基于minist数据集训练了300eporch,结果却显示分类的result正确率非常低,于是考虑引入cnn卷积神经网络提取图像特征再进行em算法迭代。
性能优化——点赞功能防抖函数实现。
调用外部的python程序进行计算评分:
业务流程:前端从后端获取推荐的图片,前端用户在进行描绘之后上传描绘后的灰度图片至后端,后端存储图片并调用python算法模块对该图片进行评分,并将评分返回给前端,并更新后端的中心图片。
由于项目本地开发和部署之后的服务器环境的配置和图片保存的地方也不相同,所以使用被两个property文件进行配置
# 本地
python.command=/Users/nyq/anaconda3/envs/pytorch/bin/python
python.code = /Users/nyq/Desktop/algorythm/code.py
# 服务器
python.command=/root/anaconda3/envs/guke/bin/python
python.code = /usr/local/src/spring/GuKe/algorythm/code.py
前端获取后端推荐图片代码:
@UserLoginToken
@PostMapping("/getRecommend")
public Result getRecommend(HttpServletRequest request)
{
String openid = openidUtils.getOpenidFromRequest(request);
try
{
Source source = sourceService.getRecommend(openid);
Map<String, Object> map = new HashMap<>();
map.put("source", source);
return ResultFactory.success().data(map);
} catch (Exception e)
{
throw new CustomException(exceptionUtils.getErrorInfoFromException(e) + "获取推荐图片失败");
}
}
这边调用了service中的方法,被推荐的图片共有1145张,所以需要在后端设置一个图片推荐的调度算法,本项目采用了一个简单的调用算法,雨露均沾式,哪些图片被描绘的少就推荐哪些,同时必须是用户没有描绘过的图片。
@Override
public Source getRecommend(String openid)
{
// 获取待推荐的图片,描绘次数少的图片在前面
List<Source> sourceList = sourceMapper.getAll();
// for(int i = 0; i < 10; i++){
// System.out.println(sourceList.get(i).getImageUrl() + " " +sourceList.get(i).getImageUrl());
// }
// 获取用户已上传的图片列表
List<Integer> upList = uploadMapper.getUploadByOpenid(openid);
// System.out.println("upList" + upList);
// 获取推荐图片的id
int count = 0;
boolean found = false;
while (!found)
{
// 如果用户没有描绘过该图片
if (!upList.contains(sourceList.get(count).getId()))
{
found = true;
break;
}
count++;
}
// 根据id获取源图片信息
return sourceList.get(count);
}
后端接口中,返回的图片地址为在线地址,在服务器端采用的是nginx静态资源存储。
存储完图片后调用服务器端的python程序:
部分代码如下:
@UserLoginToken
@ResponseBody
@PostMapping("/upload")
public Result uploadPicture(@RequestParam("file") MultipartFile file,
int id,
HttpServletRequest request) throws IOException, InterruptedException
{
if (file == null)
throw new CustomException("图片文件为空");
String openid = openidUtils.getOpenidFromRequest(request);
// 根据源图片类型创建响应的文件夹
String path = base_path;
path += Integer.toString(id);
path += "/";
//将文件保存到服务器指定位置
try
{
//获取文件在服务器的储存位置
File filePath = new File(path);
log.debug("文件的保存路径" + path);
if (!filePath.exists() && !filePath.isDirectory())
{
log.debug("目录不存在,创建目录" + filePath);
filePath.mkdir();
}
Upload uploadImage = new Upload();
//获取原始文件名称(包括格式)
String originalFileName = file.getOriginalFilename();
//获取文件类型,以最后一个‘.’为标识
String type = originalFileName.substring(originalFileName.lastIndexOf(".") + 1);
// 以用户的openid对图片进行命名
String name = openid;
// 设置文件新名称:用户的openid
Date d = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
String date = sdf.format(d);
String fileName = date + name + "." + type;
// 在指定路径下创建文件
File targetFile = new File(path, fileName);
file.transferTo(targetFile);
System.out.println("上传成功");
// 保存upload的信息到数据库
uploadImage.setName(id);
uploadImage.setAddress(path + fileName);
uploadImage.setTime(d);
uploadImage.setOpenid(openid);
// TODO: 这里还有一个需要做的工作是调用python脚本获取评分 (根据图片的本地地址) 最后将评分返回给前端,也得保存至数据库
// 由于获取到的数据为string类型,所以这边先转为double
// 然后得分 *100
// 然后再转化为整数
String result = this.getScore(path + fileName, id);
double res = Double.parseDouble(result) * 100;
int score = (int) res;
uploadImage.setScore(score);
// 更新source表相应图片的描绘次数
sourceService.updateCountById(id);
// 更新user表的总评分
userService.updateUserScore(uploadImage.getScore(), openid);
// 插入upload表信息
uploadService.insertUpload(uploadImage);
Map<String, Object> map = new HashMap<>();
map.put("score", score);
return ResultFactory.success().message("上传成功").data(map);
} catch (Exception e)
{
// System.out.println("上传失败");
// result.put("code",400);
log.error("保存图片失败");
e.printStackTrace();
return ResultFactory.error().message("上传失败");
}
String getScore(String file, int id) throws IOException, InterruptedException
{
String result = "";
try
{
//这个方法是类似隐形开启了命令执行器,输入指令执行python脚本
Process process = Runtime.getRuntime()
.exec(command + " " + code + " " + file + " " + id);
// 这种方式获取返回值的方式是需要用python打印输出,然后java去获取命令行的输出,在java返回
System.out.println(command + " " + code + " " + file + " " + id);
InputStreamReader ir = new InputStreamReader(process.getInputStream());
LineNumberReader input = new LineNumberReader(ir);
result = input.readLine();//中文的话这里可能会有乱码,可以尝试转一下不过问题不大
// result1 = new String(result.getBytes("iso8859-1"),"utf-8");
input.close();
ir.close();
int re = process.waitFor();
System.out.println("以下为结果");
System.out.println(result);
} catch (IOException | InterruptedException e)
{
System.out.println("调用python脚本并读取结果时出错:" + e.getMessage());
}
return result;
}
这边利用的是exec调用来执行外部程序【开启了命令执行器】,并使用输入输出流读取python程序打印到标准输出流的输出,然后再输入到java的变量中进行评分的获取。
到此,便完成了外部程序的调用。
小程序端社区获取帖子,发帖,点赞:
展示帖子:
首先,需要在community.js中封装获取所有帖子的方法:
在这里,为了方便链式调用,我采用了Promise格式,并且将在本次项目中的网络请求中全面使用Promise。根据接口,获得res.data,其中的数据需要做一些处理,主要是格式转换以及其他数据的获取。例如,time只需要显示年月日即可,而if_welcome是通过确定帖子的点赞列表中有没有当前用户的openid来设置true/false:
将处理好的结果保存在data的arr中即可。
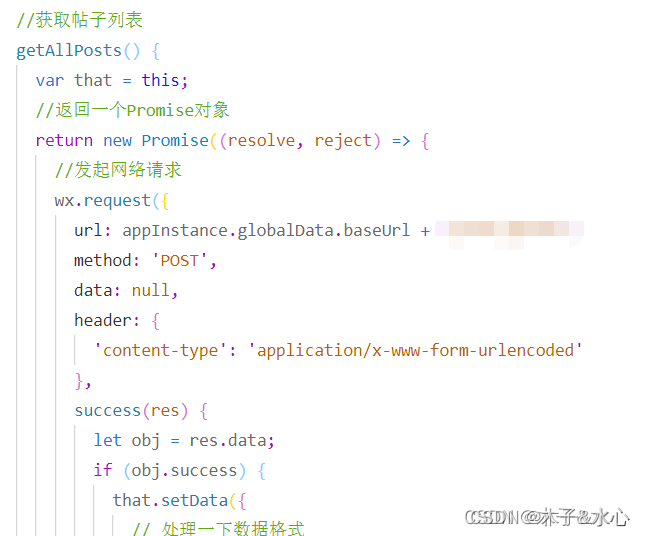
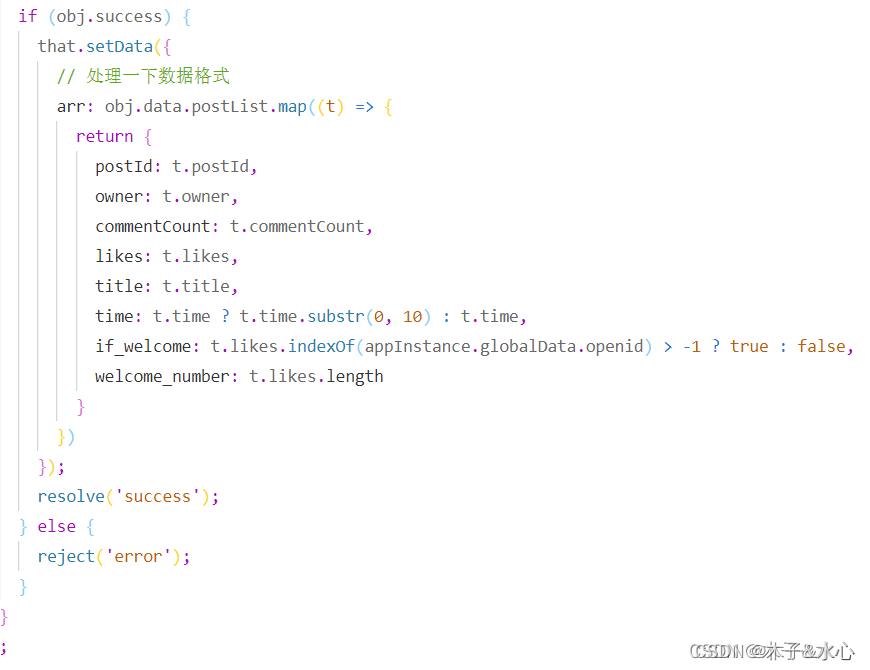
方法写好后,就要在community.wxml中修改调用Post的代码,将静态数据改为动态数据:
把整理好的数据字段分别传入Post中即可。这样,实现效果如下:
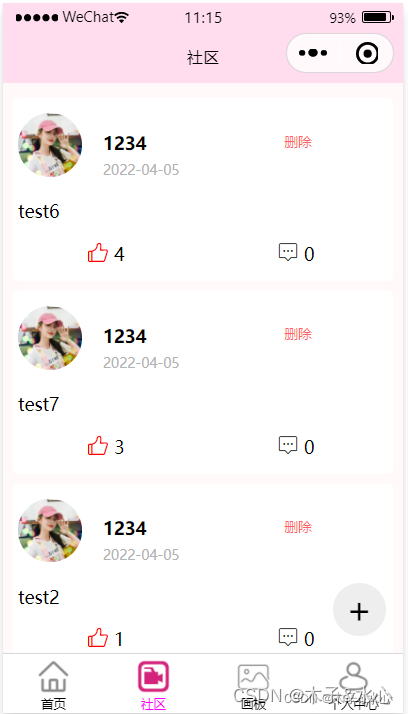
此外注意到,我在Post组件中增加了一个删除按钮,这个没有什么好说的。可以看到,基本页面搭建已经完成。

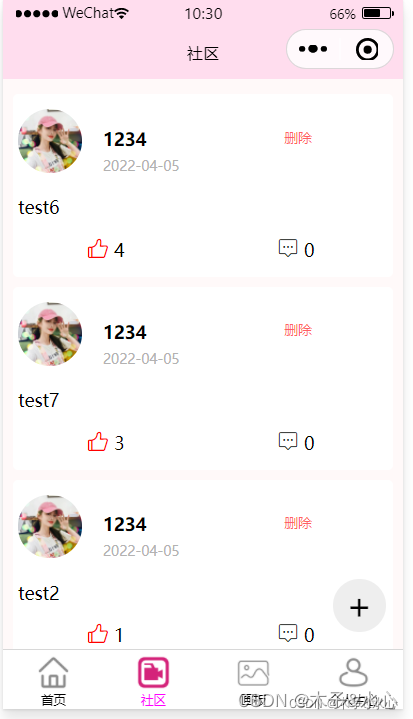
点赞帖子:
接下来,实现点赞功能。
在之前的文章中提到,点赞是通过点击Post组件的点赞按钮,然后由Post组件将事件传递给父组件并由父组件处理的。因此,同样是从Post组件出发:
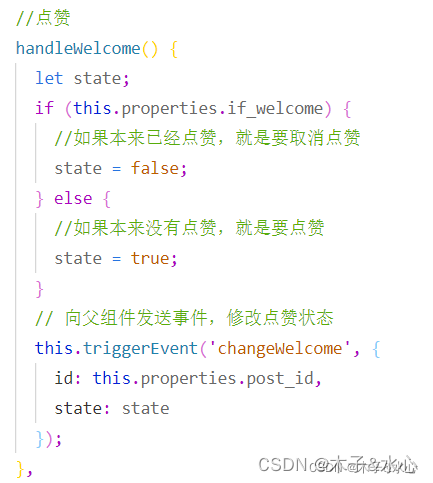
触发点赞的函数基本没有变化,仍然是将帖子的id和状态发送出去。然后,在community.wxml中接收并处理。在处理之前,先看点赞帖子的接口:
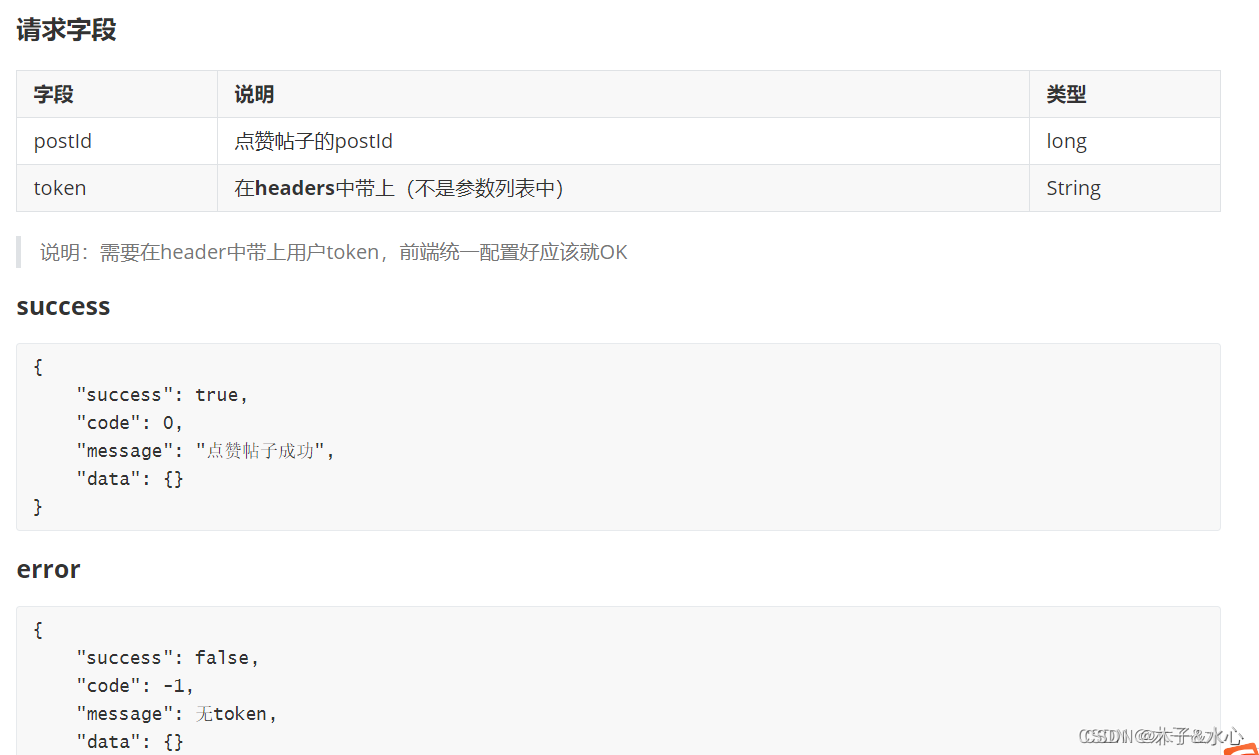
可见,要点赞帖子,必须有token,而要有token,就必须先登录。所以,community的页面结构必须变一下,在没有获取token时不能浏览页面:
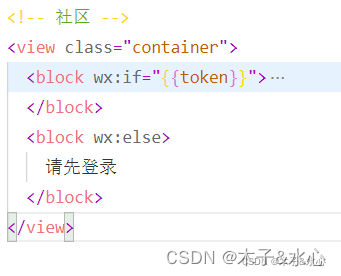
这样就保证,当用户点赞帖子时,已经登录了。然后可以处理changeWelcome事件了,但在这之前,必须封装一个点赞帖子的函数:
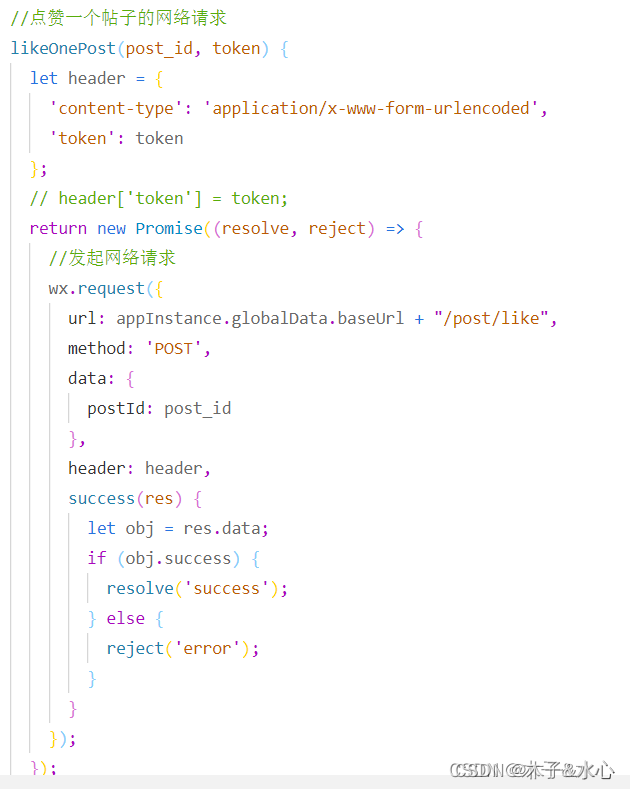
函数需要传入post_id和token,分别是要点赞的帖子的id和用户的token。注意,token是放在header里面的,不是放在data中。同样,函数返回Promise对象,以便进行下一次操作。
然后修改处理点赞事件的函数:

由于后端还没有给出取消点赞的接口,因此我现在只能实现点赞的功能。所以,获取state后,只处理state为true的情况。当state为true时,调用likeOnePost函数,传入post_id和token。如果Promise对象状态变为resolved,那么调用getAllPosts函数,重新获取帖子。否则,提示点赞失败。这样,实现效果:
点赞前:

点赞后:

至此,点赞功能实现。
发布帖子:
再接下来,要实现发帖功能。首先需要画一个发帖按钮,我使用固定定位,将按钮固定在视口右下角:
当然,这个按钮也是在只有token获取后才显示的。给这个按钮绑定一个点击事件函数:
我的计划是,新建一个发帖页面,点击发帖按钮将会前往这个页面,发帖成功后将会返回社区页面。于是,在pages中新建addNewPost页面:

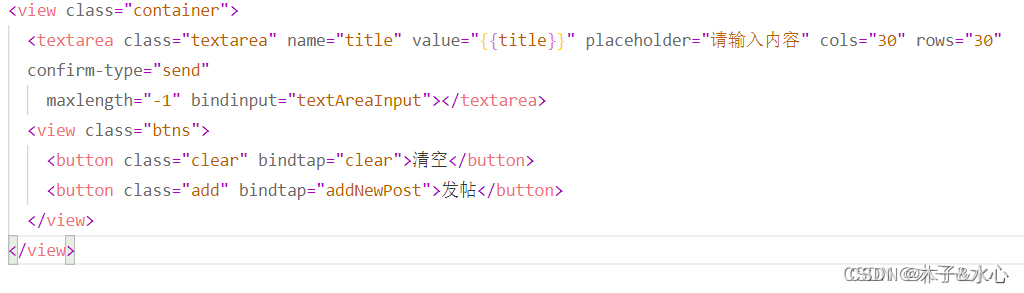
然后,先搭建addNewPost.wxml页面:
结构很简单,就是一个textarea加两个按钮即可。页面样式如下:
在data中建立数据:
title就是帖子内容,token是用户的token。按照惯例,需要在onShow生命周期函数中获取token:


,并清空title,保证上次输入的内容不会影响这次输入:

然后给textarea绑定输入监听函数和value值,并给两个按钮绑定函数。关于绑定输入函数和清空函数的具体实现:

当用户点击发帖按钮时,将会发布帖子:
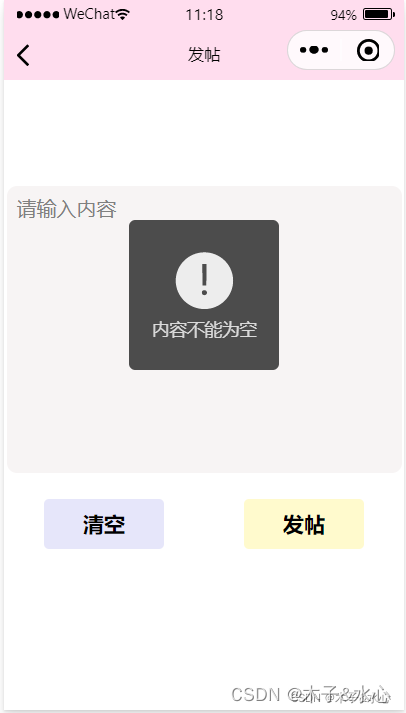
当用户没有输入内容时,会提示用户,不会发送网络请求:

否则,可以发送网络请求,同样使用Promise实现:
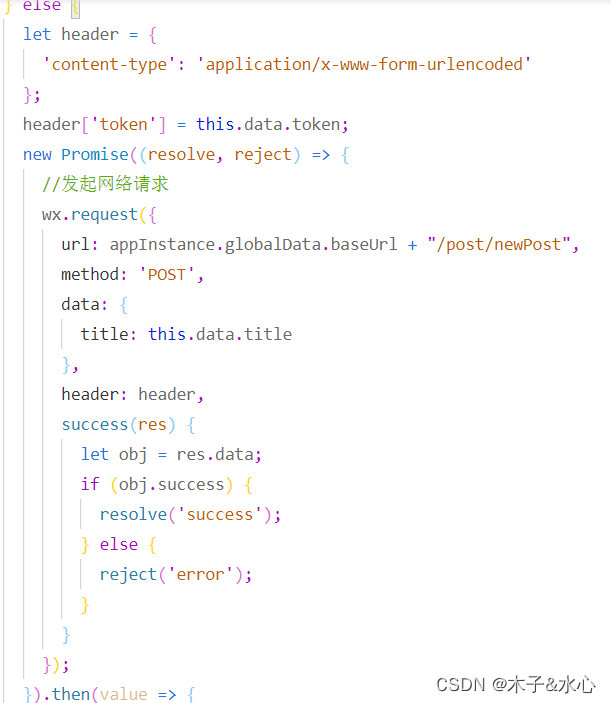
这次的then和catch我就直接写在函数内部了,因为应该不存在链式调用了:

如果发帖成功,将会提示用户,并且在1秒后退回上一层页面;发帖失败也会提示用户。
这样,发帖页面就完成了。然后需要在社区页面的发帖按钮中实现,点击就进入发帖页面,于是实现按钮的点击函数:

最终实现效果:

web端性能优化与自适应调整:
性能优化——防抖函数:
在项目中,点击点赞按钮,需要向服务器连续发送两次请求:一次是请求点赞一个帖子,一次是获取所有帖子信息以更新页面;
再次点击点赞按钮,视为取消点赞,同样需要向服务器发送两次请求:一次是请求取消点赞一个帖子,一次是获取所有帖子信息以更新页面;
这时就会发现有个问题,假如用户对点赞按钮进行暴力点击(非常频繁地点击),那么浏览器就需要非常频繁地向服务器发送请求,这样非常的消耗资源,甚至会造成卡死!
我们解决的办法是使用防抖函数。
防抖函数就是为了防止用户暴力点击而产生对服务器过度频繁的访问,使用防抖函数可以保证用户如果进行多次重复操作,只对服务器发送少量请求,以提高性能和减少卡顿。
防抖函数的核心是设置一个计时器,如果在计时内该函数再次被触发,就销毁原来的计时器,重新计时;若没有再次触发,则当时间到达时,就会执行相应动作。
我这里实现的属于延迟防抖,其他还有前缘防抖、可以设置是否立即执行的防抖等等…防抖函数的实现也有很多方式,网上资料还是挺多的,我这里写的是比较符合我们项目需求的,还未进行比较好的封装的防抖函数。
// 该函数用于根据用户点击操作修改前端变量,即点赞按钮的样式和点赞数量
function frontClickLike() {
let newAction, newLikes;
if (action === 'like') {
newAction = 'unlike';
newLikes = likes - 1;
} else {
newAction = 'like';
newLikes = likes + 1;
}
setAction(newAction)
setLikes(newLikes)
return newAction;
}
// 该函数用于根据最终的点赞状态,向后端发起请求
function clickLikeToBack(newAction) {
const url = (newAction === 'like' ? '/post/like' : '/post/unlike')
console.log(url)
// 请求服务器点赞或取消点赞
axios({
method: 'post',
url,
data: qs.stringify({
postId: props.postId,
}),
headers: {
token:sessionStorage.getItem('token')
}
})
.then((res) => {
console.log(res.data)
})
.catch((error) => console.log(error))
}
function antiShakeClickLike() {
console.log("func called")
// 打印一下当前计时器
console.log(`timeout: ${timeout}`)
// 调用frontClickLike,获得更新后的点赞状态
// 为什么要用返回的newAction而不是直接用action呢?
// 因为setAction是异步更新的,如果直接使用action,后面clickLikeToBack得到的是之前的action,而不是更新后的action
let newAction = frontClickLike();
// 如果timeout不为null,则说明之前已经有个计时器了,则清除计时器
if (timeout) {
console.log("timeout force cleared ")
clearTimeout(timeout)
}
// 重新计时,1秒后将当前like发送给后端
timeout = setTimeout(() => {
clickLikeToBack(newAction);
console.log(`将当前like发送给后端`)
}, 1000)
}
浏览器窗口缩放时内容调整:
主要关注一下wekitBox和@media的使用
在主页中,有一个介绍栏
文字部分使用了wekitBox,控制行数为10行,溢出部分用省略号表示

.wekitBox{
display: -webkit-box;
-webkit-line-clamp: 10;
text-overflow: ellipsis;
-webkit-box-orient:vertical;
overflow: hidden;
}
当浏览器窗口缩小时,会发现好像有点别扭
可不可以对文字部分进行自适应调整呢?我使用了@media去做了一个微小调整
在css中添加样式:

@media screen and (max-width: 600px) {
.wekitBox{
display: -webkit-box;
-webkit-line-clamp: 3;
text-overflow: ellipsis;
-webkit-box-orient:vertical;
overflow: hidden;
}
}
表示当窗口大小小于600px时,控制wekitBox显示的行数为3,效果如图:

骨刻文识别算法-cnn卷积神经网络:
1.简介
在搭建完em模型之后,基于minist数据集训练了300eporch,结果却显示分类的result正确率非常低,于是考虑引入cnn卷积神经网络提取图像特征再进行em算法迭代。
2.cnn
在初步尝试中采用别人训练好的cnn核(提取图像边缘特征)但是进行实验,发现结果也不是很理想,于是从新搭建cnn网络。如果用全连接神经网络处理大尺寸图像具有三个明显的缺点:
(1)首先将图像展开为向量会丢失空间信息;
(2)其次参数过多效率低下,训练困难;
(3)同时大量的参数也很快会导致网络过拟合。 而使用卷积神经网络可以很好地解决上面的三个问题。
3.pytorch
安装 pytorch,使用pytorch搭建cnn模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
# 输入[1,28,28]
nn.Conv2d(
in_channels=1, # 输入图片的高度
out_channels=16, # 输出图片的高度,
kernel_size=(4, 4), # 5x5的卷积核,相当于过滤器
padding=2, # 给图外边补上0
),
# 经过卷积层 输出[16,28,28] 传入池化层
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # 经过池化 输出[16,14,14] 传入下一个卷积
)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16, # 同上
out_channels=32,
kernel_size=(5, 5),
padding=2
),
# 经过卷积 输出[32, 14, 14] 传入池化层
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # 经过池化 输出[32,7,7] 传入输出层
)
# 输出层
self.output = nn.Linear(in_features=32 * 7 * 7, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x) # [batch, 32,7,7]
x = x.view(x.size(0), -1) # 保留batch, 将后面的乘到一起 [batch, 32*7*7]
output = self.output(x) # 输出[50,10]
return output
4.将cnn模型和em模型组合到新的模型中
class EM_model:
def __init__(self):
self.N = 60000
self.L = 10
self.groups = 10
self.w = np.random.rand(self.N, self.groups)
self.softMax()
self.u = np.random.rand(self.groups, self.L)
self.q = [np.identity(self.L) for _ in range(self.groups)]
self.q = np.array(self.q)
self.p = np.random.rand(self.groups)
self.p /= np.nansum(self.p)
# self.save(self.w, self.u, self.q, self.p)
self.load()
def _w(self, j): # 第j个类的概率之和
_sum = 0
for i in range(self.N):
_sum += self.w[i, j]
return _sum
def softMax(self):
for index, row in enumerate(self.w):
self.w[index] = row / np.nansum(row)
if np.nansum(row) == 0.0:
print(index, 'is 0')
def E_step(self):
for i in range(self.N):
for j in range(self.groups):
prob = scipy.stats.multivariate_normal.pdf(self.x[i, :], mean=self.u[j, :], cov=self.q[j, :])
result = self.p[j] * prob
self.w[i, j] = result * self.N
self.softMax()
def M_step(self):
# M步
for j in range(self.groups):
# 求p
self.p[j] = self._w(j) / self.N
# 求u
_sum = 0
for i in range(self.N):
_sum += self.w[i, j] * self.x[i]
_sum /= self._w(j)
self.u[j] = _sum
# 求q
_sum = np.zeros((self.L, self.L))
for i in range(self.N):
temp = self.w[i, j] * np.dot((self.x[i] - self.u[j]).reshape(self.L, 1), (self.x[i] - self.u[j]).reshape(1, self.L))
_sum += temp
# print(_sum.shape)
_sum /= self._w(j)
self.q[j] = _sum
def save(self, _w , _u, _q, _p):
np.savetxt('w.txt', _w)
np.savetxt('u.txt', _u)
np.savetxt('q.txt', _q.reshape(1, self.groups * self.L * self.L))
np.savetxt('p.txt', _p)
def load(self):
self.w = np.loadtxt('w.txt')
self.u = np.loadtxt('u.txt')
self.q = np.loadtxt('q.txt').reshape(self.groups, self.L, self.L)
self.p = np.loadtxt('p.txt')
def input(self, x):
self.x = x
self.N = x.shape[0]
print(x.shape)
def Eporch(self, EPORCH):
for i in range(EPORCH):
self.E_step()
self.M_step()
self.save(self.w, self.u, self.q, self.p)
def result(self):
return self.u, self.w