一、爬虫
通过对比各个比较知名的招聘网站,发现有些网站反爬真的啥也爬不到,然后找到了前程无忧的手机端的网页。
分析网址(网址在爬虫代码中)
通过更新pageno的参数,进行分页爬取。
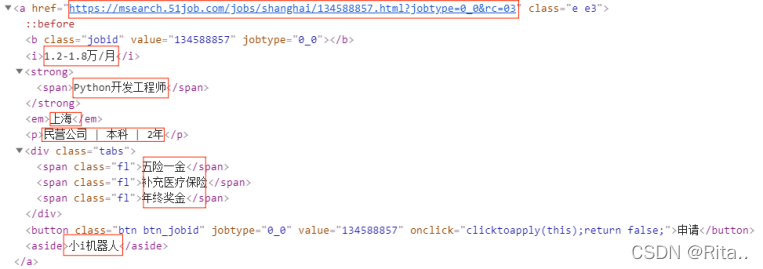
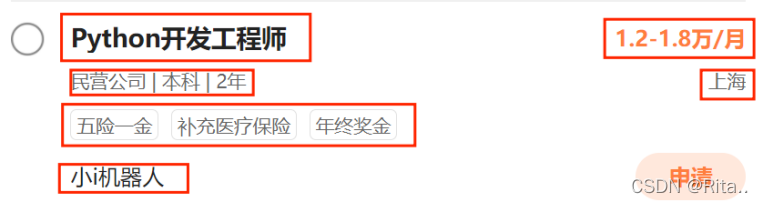
利用find_all函数找到一页中所有class值等于e e3的a标签
find_detail=bs.find_all(‘a’,class_=‘e e3’)
#提取 职称, 地区, 公司资质, 要求, 薪资, 福利, 公司名称, 详情链接
在find_detail对象中找到contents内容(.contents可以将标签下的子节点以列表形式输出)我们通过debug可以找到各数据的索引值。

import requests
from bs4 import BeautifulSoup
from openpyxl import workbook
import sqlite3
def askURL(url):
headers={
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36',
'Cookie': '#你的网页cookie值,需要频繁更新!',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive'
}
try:
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
response.encoding=response.apparent_encoding
except:
print("response error!")
return response.text
#爬取数据并保存到excel文件中
def getData():
try:
u = 'https://msearch.51job.com/job_list.php?keyword=Python&keywordtype=2&funtype=0000&indtype=00&jobarea=000000&workyear=99&jobterm=99&cotype=99&issuedate=9°ree=99&saltype=99&cosize=99&lonlat=&radius=&landmark=0&wxjobid=&filttertype=&pageno='
wb = workbook.Workbook()#创建excel
ws = wb.active #激活worksheet
ws.append(['职称', '地区', '公司资质', '要求', '薪资', '福利', '公司名称', '详情链接'])
for p in range(1, 28):#分页爬取,爬取27页的关于python的数据
url = u + str(p)
html = askURL(url)
bs = BeautifulSoup(html, 'html.parser')
find_detail = bs.find_all('a', class_='e e3')
for i in range(len(find_detail)):
welfare = str(find_detail[i].contents[11].text)
welfare = welfare.replace('\n', ' ')
company = find_detail[i].contents[9].string.split("|")[0]
company = str(company).replace(' ', '')
demands = find_detail[i].contents[9].string.split("|")[1:]
demands = ''.join(demands)
cname = find_detail[i].contents[-2].text
link = find_detail[i].get('href')
if welfare == '申请':
welfare = ''
ws.append([find_detail[i].contents[5].string, find_detail[i].contents[7].string, company,
demands, find_detail[i].contents[3].string, welfare, cname, link])
wb.save('data.xlsx')
print('爬取并保存成功!')
except IndexError:
print("error!")
#爬取数据并保存到Sqlite数据库中
def save2db(dbpath):
try:
u = 'https://msearch.51job.com/job_list.php?keyword=Python&keywordtype=2&funtype=0000&indtype=00&jobarea=000000&workyear=99&jobterm=99&cotype=99&issuedate=9°ree=99&saltype=99&cosize=99&lonlat=&radius=&landmark=0&wxjobid=&filttertype=&pageno='
conn = sqlite3.connect(dbpath)
sql_del='''delete from job_dis'''
conn.execute(sql_del)
conn.commit()
sql = '''insert into job_dis (职称,地区,公司资质,要求,薪资,福利,公司名称,详情链接)
values('%s','%s','%s','%s','%s','%s','%s','%s')'''
for p in range(1, 28):#分页爬取,爬取27页的关于python的数据
url = u + str(p)
html=askURL(url)
bs=BeautifulSoup(html, 'html.parser')
find_detail=bs.find_all('a', class_='e e3')
for i in range(len(find_detail)):#50
link=find_detail[i].get('href')
welfare = str(find_detail[i].contents[11].text)
welfare = welfare.replace('\n', ' ')
company = str(find_detail[i].contents[9].string.split("|")[0])
company = company.replace(' ', '')
demands = find_detail[i].contents[9].string.split("|")[1:] #, find_detail[i].contents[9].string.split("|")[2], '的工作经验']
demands = ''.join(demands)
cname= find_detail[i].contents[-2].text
if welfare == '申请':
welfare = ''
conn.execute(sql % (find_detail[i].contents[5].string, find_detail[i].contents[7].string, company,
str(demands), find_detail[i].contents[3].string, welfare, cname, link))
conn.commit()
conn.close()
print('成功保存到数据库!')
except IndexError:
print("error!")
if __name__ == '__main__':
getData()
save2db('data.db')
数据分别以excel和sqlite数据库的形式保存,两个函数的主要代码是一致的。
SQLite数据库建表
import sqlite3
def init_db(dbpath):
sql = '''
create table job_dis(
职称 varchar(255),
地区 varchar(255),
公司资质 varchar(255),
要求 message_text,
薪资 int,
福利 message_text,
公司名称 message_text,
详情链接 varchar(255)
);
'''
con = sqlite3.connect(dbpath)
cursor = con.cursor()
cursor.execute(sql)
con.commit()
con.close()
if __name__ == '__main__':
init_db('spider/data.db')
print('建表成功!')
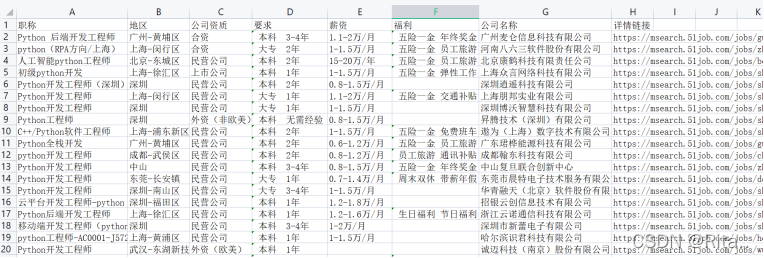
爬取到的数据如下:
二、数据处理
数据处理这块处理方法简单
import pandas as pd
import re
# 数据清洗:将所有薪资换算成月平均工资
def data_clear():
file_name = r'C:\Users\hp\PycharmProjects\期末大作业\spider\data.xlsx'
df = pd.read_excel(file_name)
for i in range(0, df.shape[0]):#0-1349 数据条数
s = df.loc[[i], ['薪资']].values.tolist()[0][0]
try:
if re.search('(.*)-(.*)', str(s)).string[-1] == '月':
a = re.search('(.*)-(.*)\/月', str(s))[1] # 处理月薪
b = re.search('(.*)-(.*)\/月', str(s))[2]
if b[-1] == '千':
x = eval(a[0:]) * 1000
y = eval(b[0:-1]) * 1000
elif b[-1] == '万':
x = eval(a[0:]) * 10000
y = eval(b[0:-1]) * 10000
value = round((x + y) / 2)
df.loc[[i], ['薪资']] = value
else:
a1 = re.search('(.*)-(.*)\/年', str(s))[1] # 处理年薪
b1 = re.search('(.*)-(.*)\/年', str(s))[2]
if b1[-1] == '万':
x1 = eval(a1[0:]) * 10000
y1 = eval(b1[0:-1]) * 10000
value1 = round((x1 + y1) / (2 * 12))
df.loc[[i], ['薪资']] = value1
except:
pass
df.to_excel('spider/test.xlsx')
if __name__ == '__main__':
data_clear()
print('薪资处理成功!')
三、生成词云
准备工作:安装相关库,找一个白底的背景图片
import jieba #分词
import matplotlib.pyplot as plt#绘图,数据可视化
from wordcloud import WordCloud
from PIL import Image #图片处理
import numpy as np #矩阵运算
import pandas as pd
#生成待遇的词云图片
#读入数据生成.txt文件
def readItem():
filename = r'C:\Users\hp\PycharmProjects\期末大作业\static\sentence.txt'
datafile = r'C:\Users\hp\PycharmProjects\期末大作业\spider\data.xlsx'
excel_file = pd.read_excel(datafile, usecols=[0, 1, 2, 3, 4, 5])
excel_file.to_csv(filename, sep=' ', index=False)
with open(r'static/sentence.txt', 'r', encoding='utf-8') as f:
text = str(f.read())
f.close()
text = text.replace('\n', '')#去换行符
text = text.replace('"', '')#去标点符号"
text = text.replace(' ', '')#去空格
text = text.replace('-', '')#-
text = text.replace('/', '每')#-
#print(text)
return text
if __name__ == '__main__':
text = readItem()
cut = jieba.cut(text)
string = ' '.join(cut)#分词
#print(string)
#print(len(string))
img=Image.open(r'./static/bg.jpg') #读取模板图
img_array = np.array(img)
wc = WordCloud(
width=800,
height=800,
background_color='white', #背景色
mask=img_array, #掩膜,产生词云背景的区域
font_path='STXINGKA.TTF', #字体所在位置:本机C:\Windows\Fonts
scale=5 #按比例放大
)
wc.generate_from_text(string)
#绘制图片
fig=plt.figure(1)
plt.imshow(wc)#显示
plt.axis('off')#设置不显示坐标轴
#plt.show()
plt.savefig('static/wordcloud.jpg', dpi=500)#设置清晰度
print('词云生成成功!')
词云图片如下:

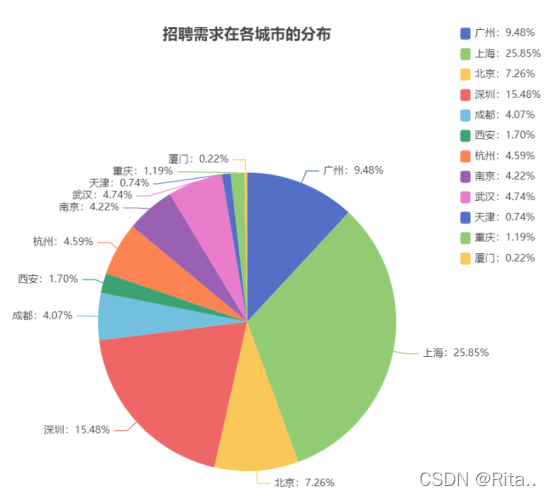
四、数据可视化
前端用echarts,简单易学,展示效果好,直接去官网
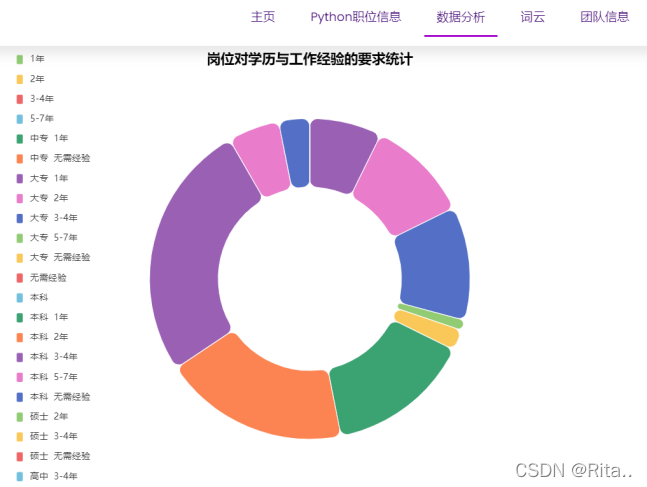
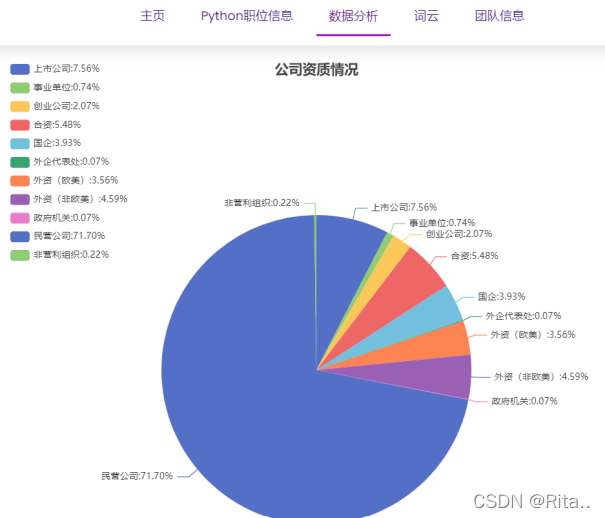
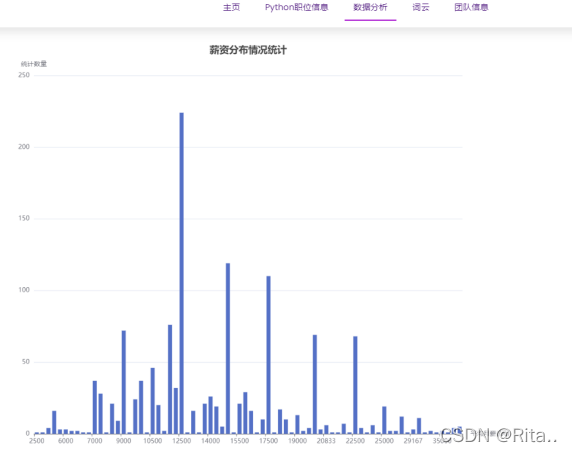
五、其他细节
项目框架:在PyCharm新建flask项目
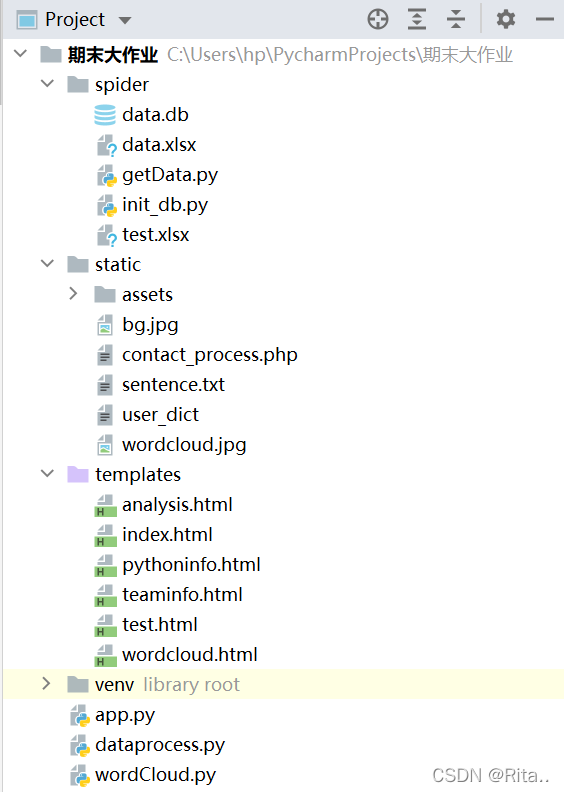
app.py部分源码,有些代码冗长,不方便全部码出
import sqlite3
import pandas as pd
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def main():
return render_template("index.html")
@app.route('/pythoninfo')
def pythoninfo():
datalist=[]
con=sqlite3.connect('spider/data.db')
cur=con.cursor()
sql="select * from job_dis"
data=cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
con.close()
return render_template('pythoninfo.html',pythoninfo=datalist)
@app.route('/wordcloud')
def wordcloud():
return render_template('wordcloud.html')
@app.route('/teaminfo')
def teaminfo():
return render_template('teaminfo.html')
echarts前端代码示例
<table border="1px" class="table-striped" >
<tr>
<td align="center">职称</td>
<td align="center" width="140px">地区</td>
<td align="center">公司资质</td>
<td align="center" width="150px">要求</td>
<td align="center">薪资</td>
<td align="center" width="150px">福利</td>
<td align="center">公司名称</td>
<td align="center">详情链接</td>
</tr>
{% for info in pythoninfo %}
<tr>
<td align="center">{{info[0]}}</td>
<td align="center">{{info[1] }}</td>
<td align="center">{{info[2]}}</td>
<td align="center">{{info[3]}}</td>
<td align="center">{{info[4]}}</td>
<td align="center">{{info[5]}}</td>
<td align="center">{{info[6]}}</td>
<td align="center">
<a href="{{ info[7] }}" target="_blank">
<font color="black">{{ info[7] }}</font>
</a>
</td>
</tr>
{% endfor %}
</table>
六、总结
网页展示有许多不足之处,数据处理也非常简单。花费2,3天时间+自学+应付课设。非常推荐B站IT私塾的课,再根据自己的需求查找相关的代码和知识点。爬虫的代码在2022年3月底是有效的。总的来说,入门还是很容易,精通需要花些功夫,学无止境~~~ python真香~~~