摘自知乎博主https://www.zhihu.com/question/362131975/answer/2182682685?utm_oi=78365163782144
作者:月来客栈
链接:https://www.zhihu.com/question/362131975/answer/2182682685
1. 多头注意力机制原理
1.1 动机
首先让我们先一起来看看作者当时为什么要提出Transformer这个模型?需要解决什么样的问题?现在的模型有什么样的缺陷?
1.1.1 面临问题
现在主流的序列模型都是基于复杂的循环神经网络或者是卷积神经网络构造而来的Encoder-Decoder模型,并且就算是目前性能最好的序列模型也都是基于注意力机制下的Encoder-Decoder架构。
由于传统的Encoder-Decoder架构在建模过程中,下一个时刻的计算过程会依赖于上一个时刻的输出,而这种固有的属性就限制了传统的Encoder-Decoder模型就不能以并行的方式进行计算。
所以作者会不停的提及这些传统的Encoder-Decoder模型
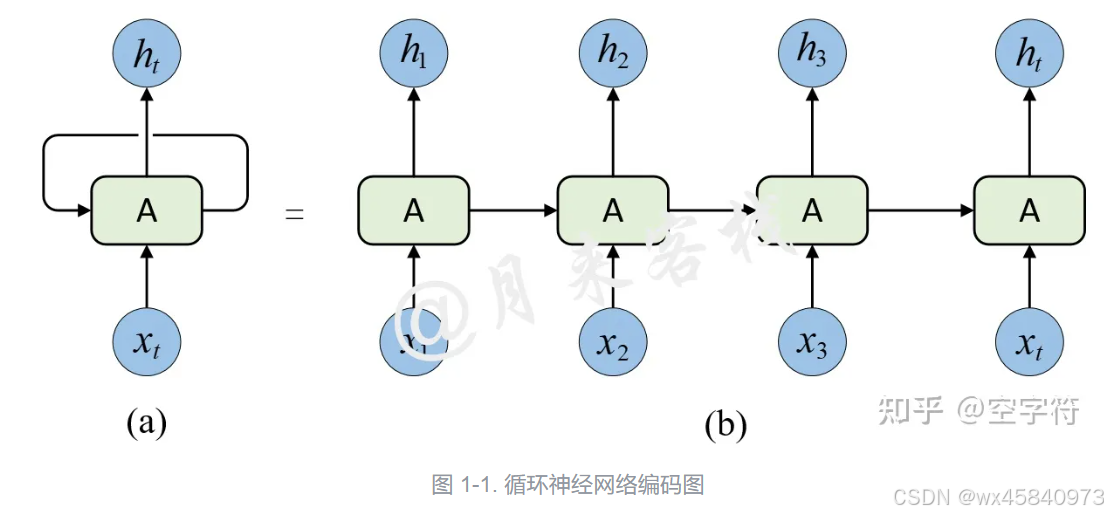
最近的工作通过因式分解技巧和条件计算显着提高了计算效率,同时还提高了后者的模型性能。然而,顺序计算的基本限制仍然存在。
1.1.2 解决思路
因此,作者首次提出了一种全新的Transformer架构来解决这一问题,如图1-2所示。当然,Transformer架构的优点在于它完全摈弃了传统的循环结构,取而代之的是只通过注意力机制来计算模型输入与输出的隐含表示,而这种注意力的名字就是大名鼎鼎的自注意力机制(self-attention),也就是图1-2中的Multi-Head Attention模块。
总体来说,所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。最终,Transformer架构就是基于这种的自注意力机制而构建的Encoder-Decoder模型。
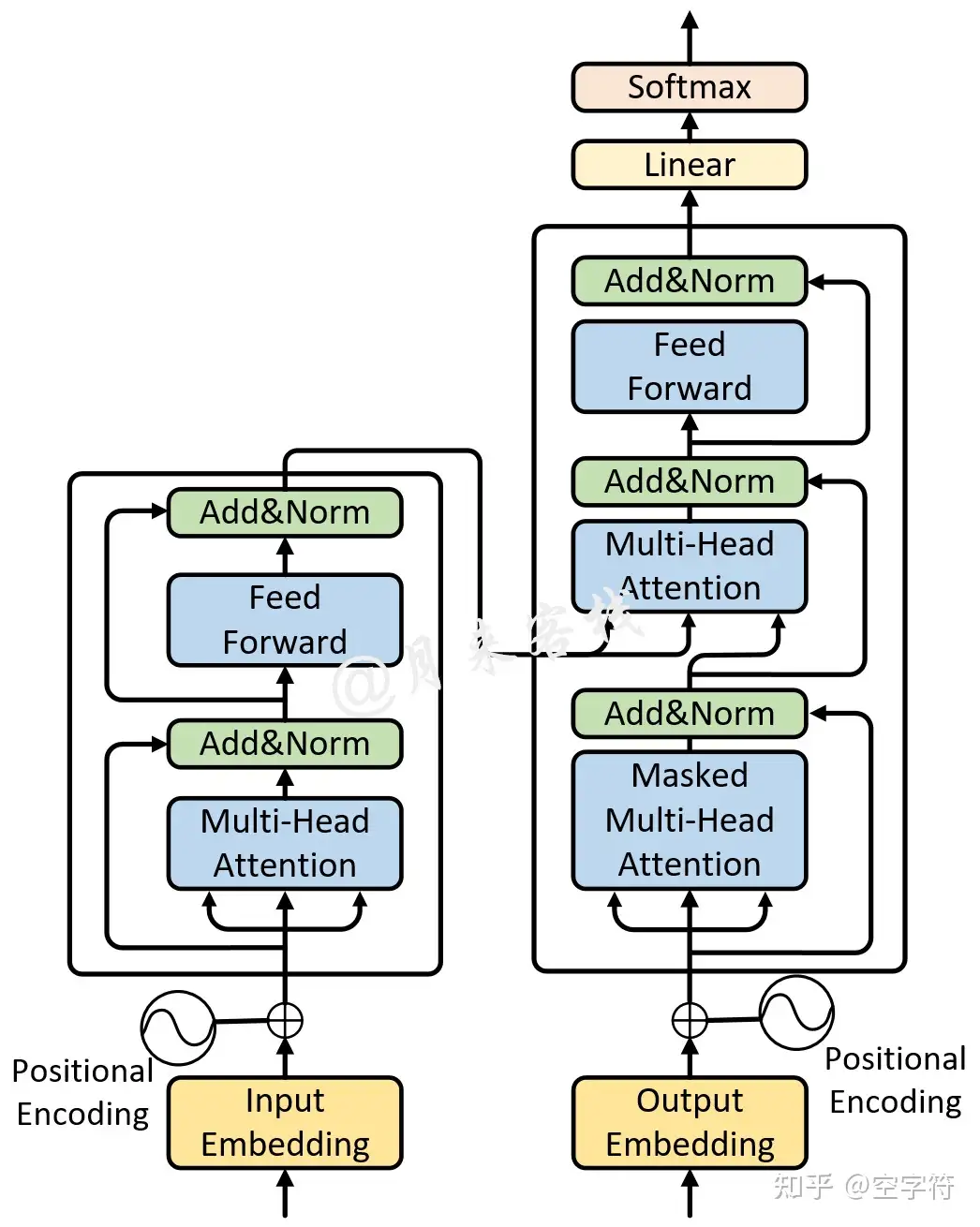
解释这句话
-
“所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重”:
- 自注意力机制是一种计算方法,用来判断句子中每个词在表示句子含义时的重要性。
- 在这个过程中,自注意力机制会计算句子中每个词对其他词的“关注度”(也就是注意力权重),这是一种通过数学运算(如点积、归一化等)来完成的。
-
“然后再以权重和的形式来计算得到整个句子的隐含向量表示”:
- 这些注意力权重会被用于计算每个词的隐含表示(也就是词向量),并通过加权求和的方式整合起来,得到整个句子的表示。
- 隐含向量是句子的数值化表示,用于之后的模型运算和预测。
-
“最终,Transformer架构就是基于这种的自注意力机制而构建的Encoder-Decoder模型”:
- Transformer是一种神经网络架构,它的核心部分就是自注意力机制。
- Transformer模型包括编码器(Encoder)和解码器(Decoder),通过自注意力机制来处理和理解输入数据(如句子)并生成输出(如翻译、文本生成等)。
总结来说,这句话的意思是:自注意力机制是通过计算句子中各个词的重要性来生成整个句子的表示,Transformer模型就是基于这种机制构建的用于处理语言任务的模型。
1.2 技术手段
自注意力机制 ,然后再来探究整体的网络架构。
1.2.1 什么是self-Attention
就是“Scaled Dot-Product Attention“。注意力机制可以描述为将query和一系列的key-value对映射到某个输出的过程,而这个输出的向量就是根据query和key计算得到的权重作用于value上的权重和(Value加权和)。 需要结合Transformer的解码过程,才能更好地理解。
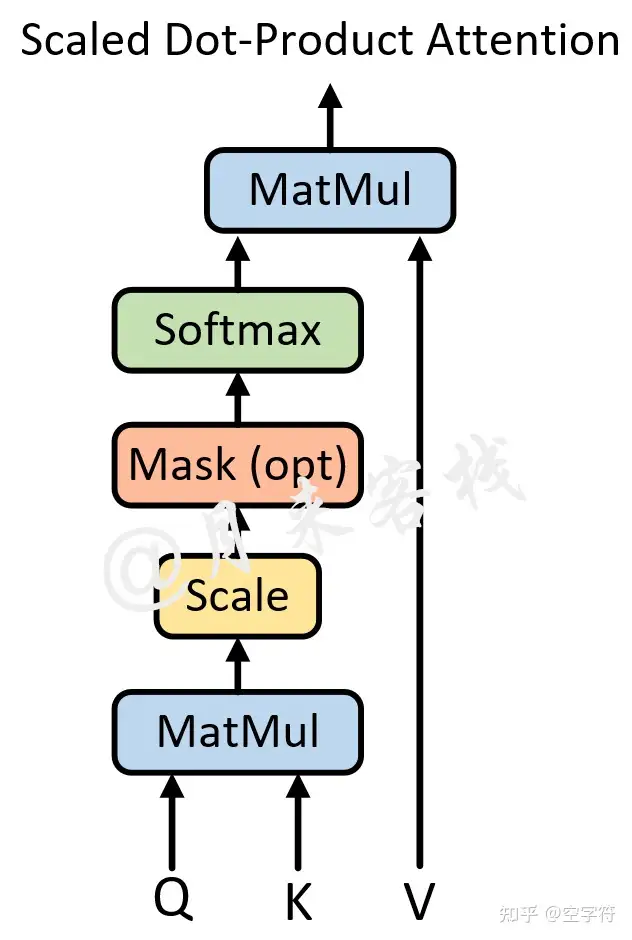
## 7. ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
## 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]
##首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
## 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
#一横行做softmax
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn从上图和代码可以看出,自注意力机制的核心过程就是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出。具体的,对于输入Q、K和V来说,其输出向量的计算公式为:

- Q(Query)的维度通常是
- K(Key)和 V(Value)维度类似
- 其中,
batch size是一次输入的数据批量大小,sequence length是输入序列的长度(即词的数量),是每个词的 Query 向量的维度。
是每个词的 Key 向量的维度。
是每个词的 Value 向量的维度.
- 多头之后,QKV 张量的维度 如下所示
- 代码解释
K.transpose(-1, -2)通过转置操作将K的最后两个维度对调,使得它的列数与Q的列数相同,从而能够进行点积计算。
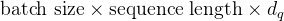



为什么要进行缩放? 去掉方差的影响
是因为通过实验作者发现,对于较大的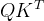

最后,文章中还通过随机变量的分析来解释为什么点积结果会变得很大:

借鉴了 (65 封私信 / 81 条消息) transformer的细节到底是怎么样的? - 知乎 (zhihu.com)
中的第二个回答
链接:https://www.zhihu.com/question/362131975/answer/3039107481
我们拿 Q 矩阵中的任意一列 q, K 矩阵中的任意一行 k 出来
翻译:

内积qk的期望
所以 根据计算公式可得 内积qk的期望:
内积qk的方差


https://www.cnblogs.com/yuyuanliu/p/15968716.html
