短信登录
Session实现登录流程
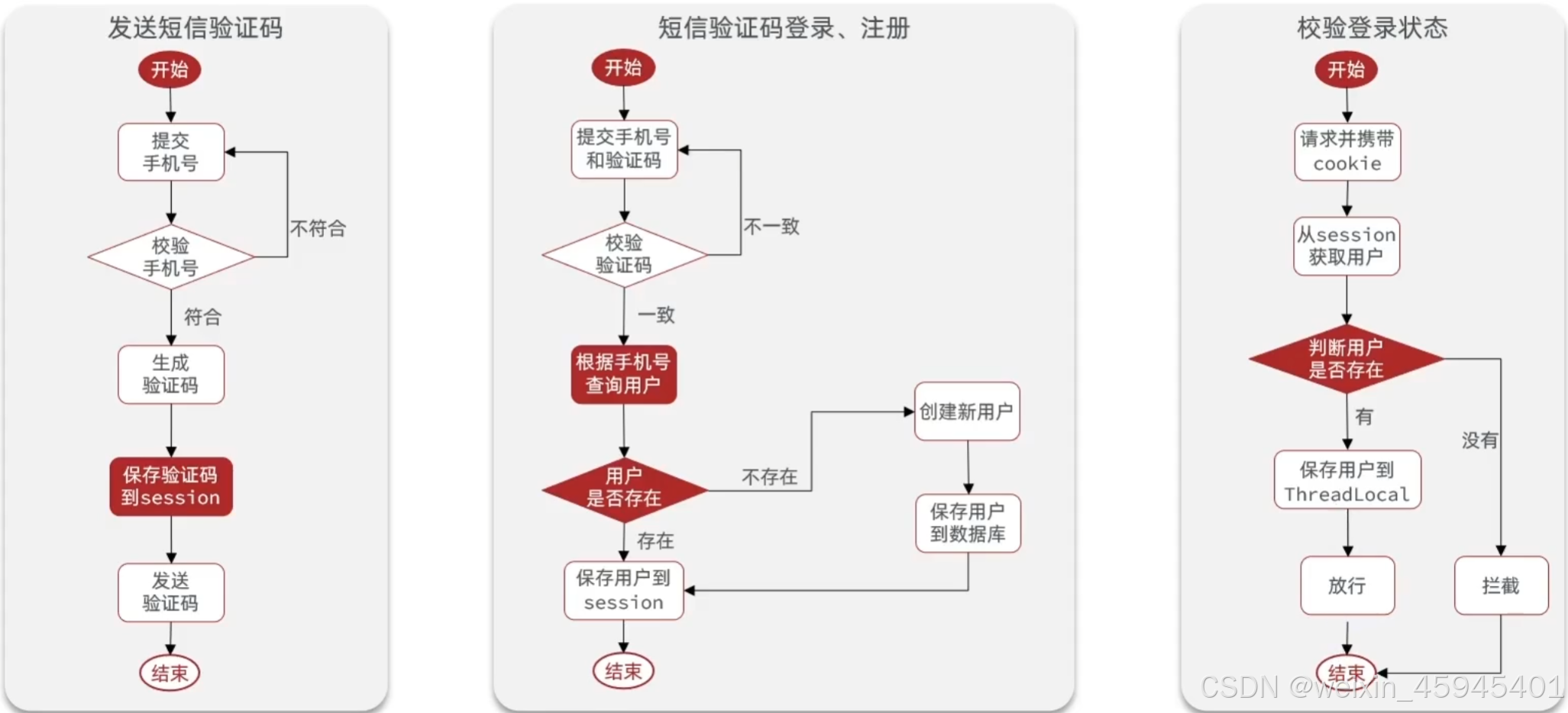
存在问题:session共享问题,多台Tomcat并不共享session存储空间,当请求切换到不同tomcat服务时导致数据丢失问题
解决问题:Redis代替session,数据共享、内存存储、key、value结构
Redis实现短信登录流程


public Result sendcode(string phone, HttpSession session){
//1.校验手机号
if(RegexUtils.isPhoneInvalid(phone)){
//2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
//3.符合,生成验证码
String code=RandomUtil.randomNumbers(length:6);
//4.保存验证码到 redisset key value ex 120
stringRedisTemplate.opsForValue().set( key: "login:code:" + phone, code, timeout: 2, TimeUnit.MINUTES);
//5.发送验证码
log.debug("发送短信验证码成功,验证码:",code);//返回ok
return Result.ok();
}public Result login(LoginFormDTo loginForm, HttpSession session){
//1.校验手机号
String phone =loginForm.getPhone();
if(RegexUtils.isPhoneInvalid(phone)){
//2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
//3.从redis获取验证码并校验
String cachecode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone);
String code=loginForm.getCode();
if(cacheCode ==null!cacheCode.equals(code)){
//不一致,报错
return Result.fail("验证码错误");
}
//4.一致,根据手机号查询用户
User user = query().eq(column:"phone",phone).one();
//5.判断用户是否存在
if(user == null){
//6.不存在,创建新用户并保存
user =createUserWithPhone(phone);
}
// 7、保存用户信息到 redis中
//7.1.随机生成token,作为登录令牌
String token=UUID.randomUuID().tostring(isSimple: true);
//7.2.将user对尔转为HashMap存储
UserDTo userDTo = BeanUtil.copyProperties(user, UserDTo.class);
Map<String,object>userMap= BeanUtil.beanToMap(userDTo);
//7.3.存储
String tokenKey = LOGIN_USER_KEY + token;
stringRedisTemplate.opsForHash().putAll(tokenKey, userMap);
//7.4.设置token有效期
stringRedisTemplate,expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES);
//8.返回token
return Result.ok(token);
}public boolean preHandle(HttpServletRequest request, HttpServletResponse response Obiect
handler) throws Exception{
//1.获取请求头中的token
String token=request.getHeader(s:"authorization");
if(strutil.isBlank(token)){
//不存在、拦截,返回401状态码
response.setStatus(401);
return false;
}
//2.基于TOKEN获取redis中的用户
String keyRedisConstants.LOGIN_USER_KEY + token:
Map<Obiect,obiect>userMap =stringRedisTemplate.opsForHash().entries(key);
//3.判断用户是否存在
if(userMap.isEmpty()){
//4.不存在,拦载、返回401状态码
response.setStatus(401):
return false;
}
//5.将查询到的Hash数据转为UserDTo对象
UserDTO userDTO = Beanutil,fillBeanWithMap(userMap, new UserDTO(), islguoreEror false);
//6.存在、保存用户信息到 ThreadLocal
UserHolder.saveUser(userDTO);
//7.刷新token有效期
stringRedisTemplate.expire(key, RedisConstants.LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}存在问题:状态登录刷新的问题
解决问题:拦截器的优化,添加拦截器,第一个拦截器作用拦截一切路径,主要刷新token有效期以及保存到ThreadLocal中,一切请求触发刷新的动作。第二个拦截器作用查询ThreadLocal的用户,主要是登录拦截。
public boolean preHandle(HttpServletRequest request, HttpServletResponse response Obiect
handler) throws Exception{
//1.获取请求头中的token
String token=request.getHeader(s:"authorization");
if(strutil.isBlank(token)){
return true;
}
//2.基于TOKEN获取redis中的用户
String keyRedisConstants.LOGIN_USER_KEY + token:
Map<Obiect,obiect>userMap = stringRedisTemplate.opsForHash().entries(key);
//3.判断用户是否存在
if(userMap.isEmpty()){
return true;
}
//5.将查询到的Hash数据转为UserDTo对象
UserDTO userDTO = Beanutil,fillBeanWithMap(userMap, new UserDTO(), islguoreEror false);
//6.存在、保存用户信息到 ThreadLocal
UserHolder.saveUser(userDTO);
//7.刷新token有效期
stringRedisTemplate.expire(key, RedisConstants.LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}public boolean preHandle(HttpServletRequest request, HttpServletResponse response,Obiect handler) throws Exception{
//1.判断是否需拦拦截(ThreadLocal中是否有用户)
if(UserHolder.getUser()==null){
//没有,需要拦载,设置状态码
response.setStatus(401);
//拦戳
return false;
}
//有用户,则放行
return true;
}
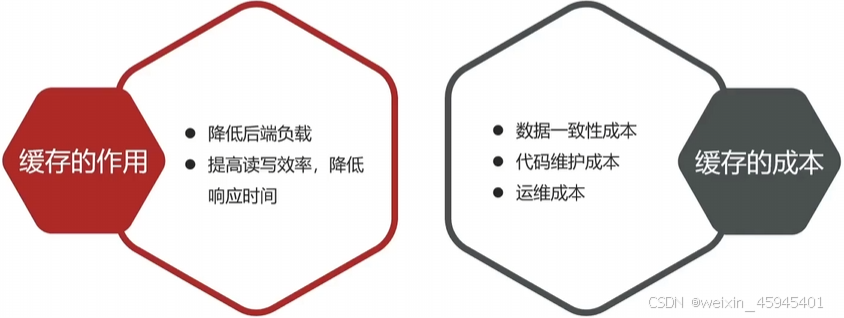
缓存
缓存:数据交换的缓冲区,存储数据的临时地方,一般读写性能比较高
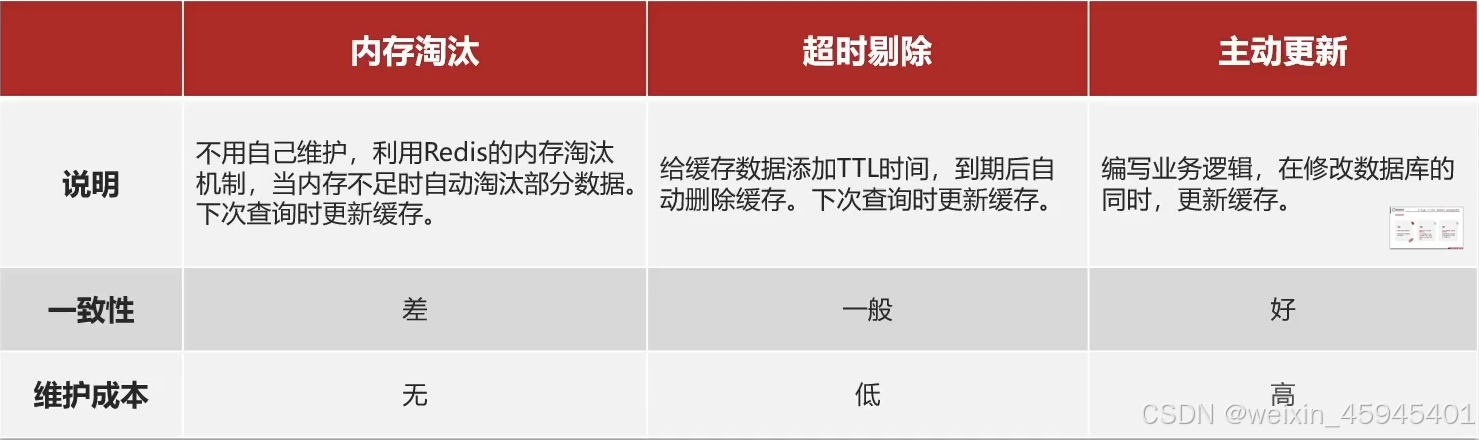
缓存更新策略:
业务场景:
低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存
高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存
主动更新策略:
操作缓存与数据库存在问题:
- 删除缓存还是更新缓存?
更新缓存:每次更新数据库都更新缓存,无效写操作较多
删除缓存:更新数据库时让缓存失效,查询时再更新缓存(优先)
- 如何保证缓存与数据库的操作的同时成功或失败?
单体系统,将缓存与数据库操作放在一个事务
分布式系统,利用TCC等分布式事务方案
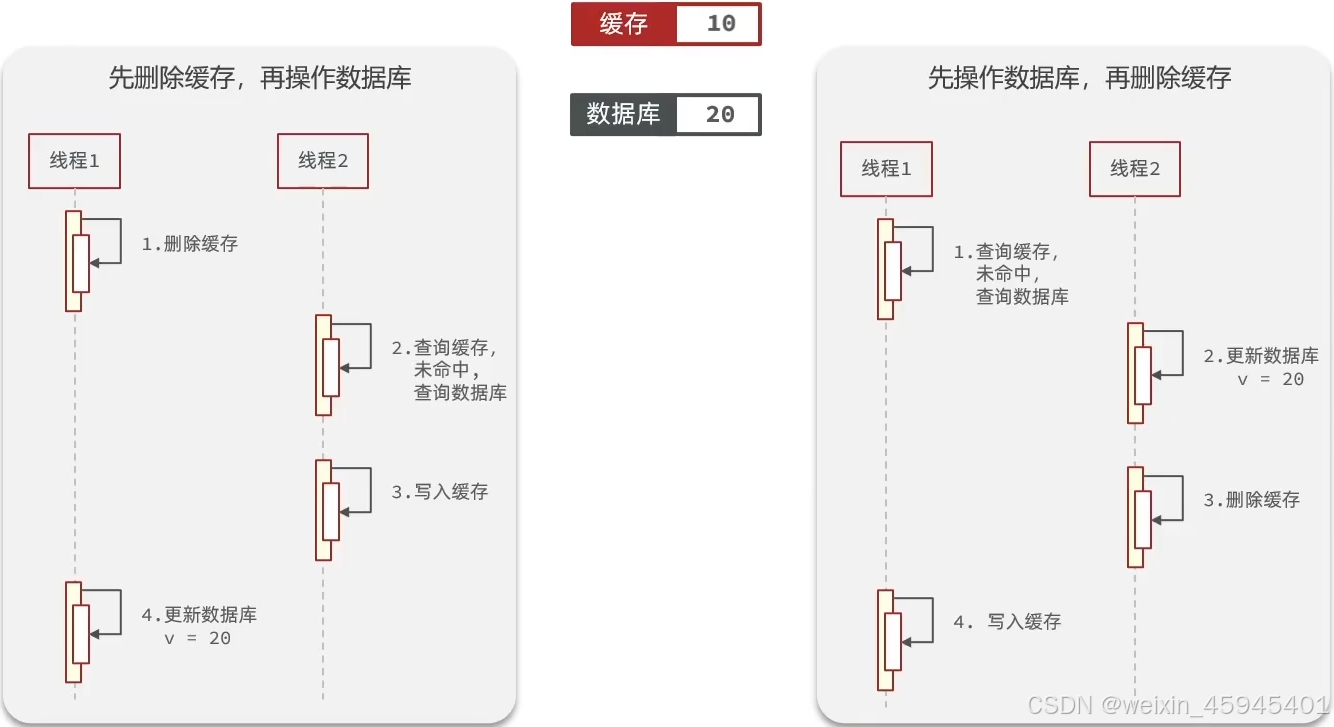
- 先操作缓存还是先操作数据库?
先删除缓存,再操作数据库
先操作数据库,再删除缓存(优先)
针对先操作缓存还是先操作数据库,正常情况:
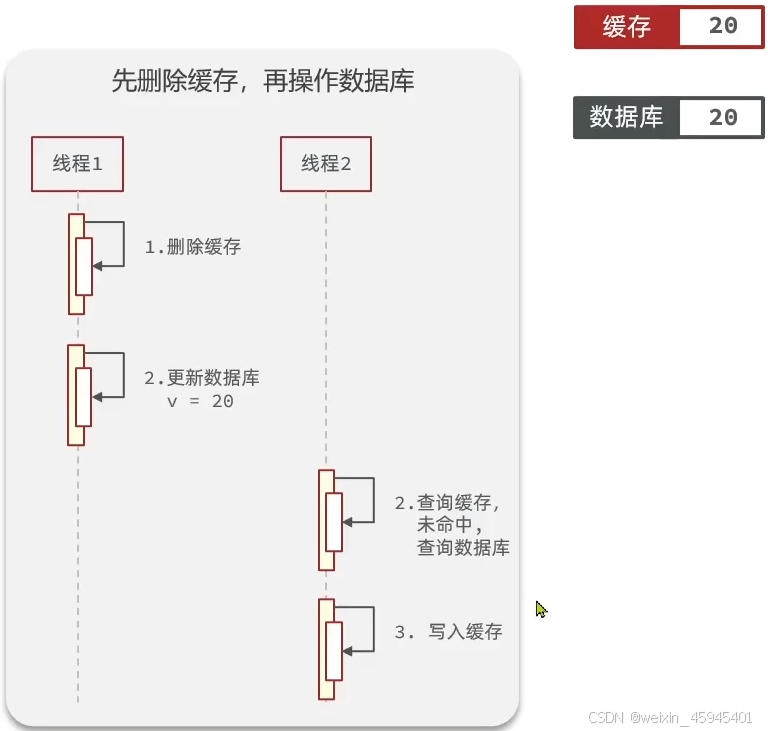

异常情况:
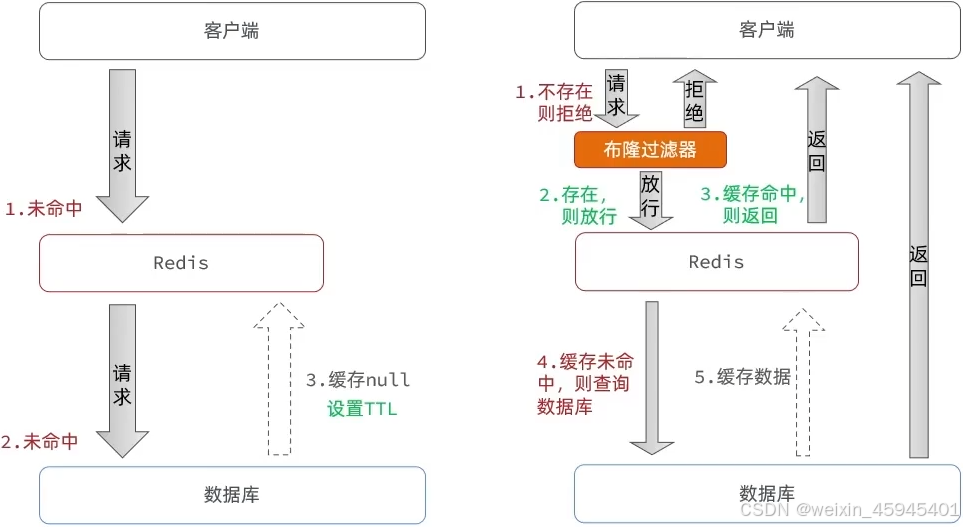
缓存穿透
问题:客户端请求的数据再缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
解决:
缓存空对象
- 优点:实现简单,维护方便
- 缺点:额外的内存消耗、可能造成短期的不一致
布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:实现复杂、存在误判可能
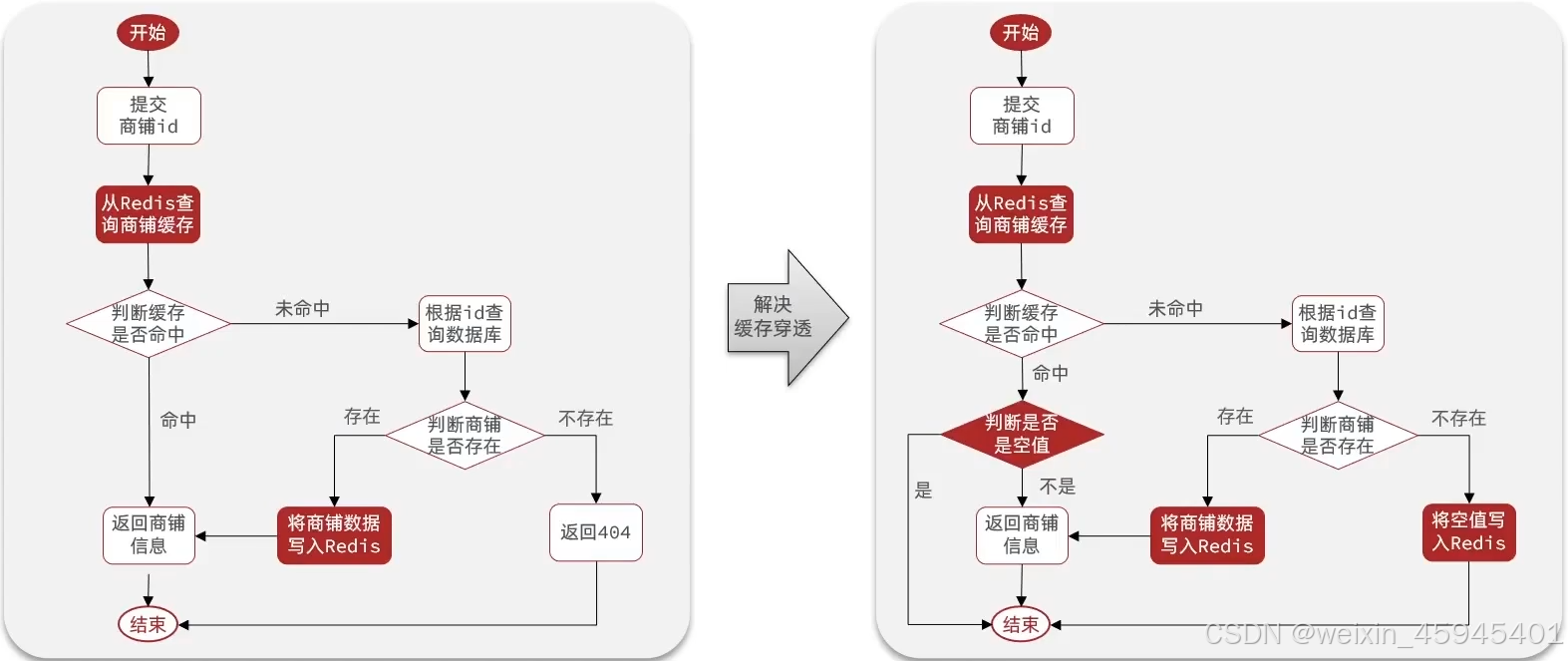
商铺查询的缓存穿透问题:
Redis缓存商铺查询代码实现
public Result queryById(Long id){
String key = CACHE_SHOP_KEY+id;
//1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存东
if(strutil.isNotBlank(shopJson)){
//3.存在,直接返回
Shop shop = IsoNutil.toBean(shopJson,Shop.class);
return Result.ok(shop);
}
//4.不存在,根据id查询数据库
Shop shop = getById(id);
//5.不存在,返回错误
if(shop == null){
return Restlt.fail("店铺不存在!");
}
//6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JsoNutil.toJsonstr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
//7.返回
return Result.ok(shop);
}
基于缓存空对象解决商铺查询缓存穿透代码实现
public Result queryById(Long id){
String key = CACHE_SHOP_KEY+id;
//1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存东
if(strutil.isNotBlank(shopJson)){
//3.存在,直接返回
Shop shop = IsoNutil.toBean(shopJson,Shop.class);
return Result.ok(shop);
}
判断命中的是否是空值
if(shopJson!= null){
//返回一个错误信息
return Result.fail("店铺信息不存在!");
}
//4.不存在,根据id查询数据库
Shop shop = getById(id);
//5.不存在,返回错误
if(shop == null){
// 将空值写入redis
stringRedisTemplate.opsForValue().set(key, vaue:"", CACHE_NULL_TTL, TimeUnit.MINUTES);
return Restlt.fail("店铺不存在!");
}
//6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JsoNutil.toJsonstr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
//7.返回
return Result.ok(shop);
}
布隆过滤器原理:
主要是用于检索⼀个元素是否在⼀个集合中。使用的是 redisson 实现的布隆过滤器。底层主要是先去初始化⼀个比较大数组,⾥⾯存放的⼆进制 0 或 1。 在⼀开始都是 0,当⼀个 key 来了之后经过 3 次 hash 计算,模于数组⻓度找到数据的下标然后把数组中原来的 0 改为 1,这样的话,三个数组的位置就能标明⼀个 key 的存在。查找的过程也是⼀样的。当然是有缺点的,布隆过滤器有可能会产生⼀定的误判,⼀般可以设置这个误判率,⼤概不会超过 5%,其实这个误判是必然存在的,要不就得增加数组的长度,其实已经算是很划分了,5%以内的误判 率⼀般的项目也能接受,不⾄于高并发下压倒数据库。
缓存雪崩
概念:指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压大
解决方法:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存