Faiss index
1.方法总结
| Method | Class name | index_factory | Main parameters | Bytes/vector | Exhaustive | Comments |
|---|---|---|---|---|---|---|
| Exact Search for L2(L2精确搜索) | IndexFlatL2 | "Flat" | d | 4*d | yes | brute-force |
| Exact Search for Inner Product(内积精确搜索) | IndexFlatIP | "Flat" | d | 4*d | yes | also for cosine (normalize vectors beforehand) |
| Hierarchical Navigable Small World graph exploration(分层可导航小世界图探索) | IndexHNSWFlat | "HNSW,Flat" | d, M | 4*d + x * M * 2 * 4 | no | |
| Inverted file with exact post-verification(倒排文件索引带精确后验证) | IndexIVFFlat | "IVFx,Flat" | quantizer, d, nlists, metric | 4*d + 8 | no | Takes another index to assign vectors to inverted lists. The 8 additional bytes are the vector id that needs to be stored. |
| Locality-Sensitive Hashing (binary flat index)(局部敏感哈希(二进制平面索引)) | IndexLSH | - | d, nbits | ceil(nbits/8) | yes | optimized by using random rotation instead of random projections |
| Scalar quantizer (SQ) in flat mode(平面模式下的标量量化器(SQ)) | IndexScalarQuantizer | "SQ8" | d | d | yes | 4 and 6 bits per component are also implemented. |
| Product quantizer (PQ) in flat mode(平面模式下的乘积量化器(PQ)) | IndexPQ | "PQx", "PQ"M"x"nbits | d, M, nbits | ceil(M * nbits / 8) | yes | |
| IVF and scalar quantizer(IVF与标量量化器结合) | IndexIVFScalarQuantizer | “IVFx,SQ4” “IVFx,SQ8” | quantizer, d, nlists, qtype | SQfp16: 2 * d + 8, SQ8: d + 8 or SQ4: d/2 + 8 | no | Same as the IndexScalarQuantizer |
| IVFADC (coarse quantizer+PQ on residuals)(IVFADC(粗略量化器+残差上的PQ) | IndexIVFPQ | "IVFx,PQ"y"x"nbits | quantizer, d, nlists, M, nbits | ceil(M * nbits/8)+8 | no | |
| IVFADC+R (same as IVFADC with re-ranking based on codes)(IVFADC+R(基于编码的重新排序)) | IndexIVFPQR | "IVFx,PQy+z" | quantizer, d, nlists, M, nbits, M_refine, nbits_refine | M+M_refine+8 | no |
- 索引可以使用类构造函数显式构造,或者使用
index_factory
1.Flat 索引
平面索引只是将向量编码为固定大小的代码,并将它们存储在 ntotal * code_size 字节的数组中。
在搜索时,所有索引向量都被顺序解码并与查询向量进行比较。
对于 IndexPQ,比较是在压缩域中完成的,速度更快
-
支持操作
平面索引类似于 C++ 向量。它们不存储向量 ID,因为在许多情况下顺序编号就足够了。所以:
- 它们不支持
add_with_id(但可以将它们包装在IndexIDMap中以添加该功能)。 - 它们确实支持高效的直接向量访问(使用
reconstruct和reconstruct_n) - 他们支持通过
remove来删除。请注意,这会缩小索引并更改编号。
- 它们不支持
-
向量编码
可用的编码是(压缩率由小到大):
- 完全不编码(
IndexFlat):向量不经压缩存储; - 16 位浮点编码(使用
QT_fp16的IndexScalarQuantizer):向量被压缩为 16 位浮点,这可能会导致精度下降; - 8/6/4 位整数编码(
IndexScalarQuantizer,带QT_8bit/QT_6bit/QT_4bit):向量量化为 256/64/16 级别; - PQ 编码(
IndexPQ):将向量分割成子向量,每个子向量量化为 几比特(通常为 8 比特)。参见下面的示例。 - 残差编码(
IndexResidual):对向量进行量化,并通过残差逐步细化。在每个量化阶段,都可以细化编码本的大小。
- 完全不编码(
2.单元探测法(IndexIVF* 索引)
一种典型的加速方法是采用 k-means 等分区技术,但代价是失去找到最近邻居的保证。相应的算法有时也被称为单元探测法。
我们使用基于多重探测的基于分区的方法。
- 特征空间被划分为
nlist单元(聚类中心)。 - 由于使用量化函数(在 k 均值的情况下,分配给最接近查询的质心),数据库向量被分配给这些单元格之一,并存储在由
nlist倒排列表形成的倒排文件结构中。 - 查询时,选择一组
nprobe倒排列表 - 将查询与分配给这些列表的每个数据库向量进行比较。
这样做时,仅将数据库的一小部分与查询进行比较:
作为第一个近似值,该部分是 nprobe/nlist,但该近似值通常被低估,因为倒排列表的长度不相等。
当未选择给定查询的最近邻居的单元格时,就会出现失败情况。
构造函数采用索引作为参数(量化器或粗量化器),用于对倒排列表进行赋值。
在此索引中搜索查询,返回的向量 id 是应该访问的倒排列表。
-
使用 flat 索引作为粗量化器的单元探测方法
通常,会使用平坦索引作为粗量化器。
IndexIVF的训练方法将质心添加到平坦索引中。nprobe在查询时指定(对于衡量速度和准确性之间的权衡很有用)。 -
其他类型的粗量化器
在某些情况下,使用其他类型的量化器(例如基于 GPU 的量化器、
MultiIndexQuantizer或基于HNSW的量化器)是有益的。 -
IndexIVF 的编码向量
倒排列表的元素是编码向量(+相应的向量id)。编码主要是为了让向量更加紧凑。这些元素只是按顺序扫描,搜索函数返回迄今为止看到的前 k 个最小距离。
支持的代码与 Flat 索引相同,只需通过插入 IVF 转换索引类的名称:
IndexFlat变为IndexIVFFlat。
3.HNSW 索引变体
IndexHNSW 使用平面索引作为底层存储来快速访问数据库向量并抽象向量的压缩/解压缩。 HNSW 取决于几个重要参数
M是图中使用的邻居数量。M越大,精度越高,但占用的内存也越多efConstruction是add时的探索深度efSearch是 search 的探索深度
-
支持的编码
IndexHNSW 支持以下 Flat 索引:
IndexHNSWFlat(无编码)、IndexHNSWSQ(标量量化器)、IndexHNSWPQ(乘积量化器)、IndexHNSW2Level(两级编码)。 -
支持的操作
除了 HNSW 使用的 Flat 索引的限制之外,HNSW 不支持从索引中删除向量。这会破坏图结构。
4.IndexLSH 及其与单元探测方法的关系
在 Faiss 中,IndedLSH 只是一个带有二进制代码的 Flat 索引。
数据库向量和查询向量被散列成二进制代码,并与汉明距离进行比较。
在Python中,(改进的)LSH索引的构建和搜索如下
n_bits = 2 * d
lsh = faiss.IndexLSH(d, n_bits)
lsh.train(x_train)
lsh.add(x_base)
D, I = lsh.search(x_query, k)
5.基于乘积量化 code 的索引
在 Python 中,乘积量化器定义为:
m = 16 # number of subquantizers
n_bits = 8 # bits allocated per subquantizer
pq = faiss.IndexPQ (d, m, n_bits) # Create the index
pq.train (x_train) # Training
pq.add (x_base) # Populate the index
D, I = pq.search (x_query, k) # Perform a search
位数 n_bits 必须等于 8、12 或 16。维度 d 应为 m 的倍数
-
使用 PQ 优化 倒排文件
IndexIVFPQ可能是大规模搜索最有用的索引结构。它的用法就像coarse_quantizer = faiss.IndexFlatL2(d) index = faiss.IndexIVFPQ(coarse_quantizer, d, ncentroids, code_size, 8) index.nprobe = 5
2.Faiss 索引(混合)
1.以 PQ 索引 作为粗量化器的单元探测方法
乘积量化器也可以用作粗量化器。这对应于中描述的多索引。对于具有 m 个段的 PQ,每个段编码为 c 个质心,倒排列表的数量为 c m c^m cm。因此,m=2 是唯一实用的选择。
在 FAISS 中,对应的粗量化器索引是 MultiIndexQuantizer。该索引很特殊,因为没有向其中添加向量。因此,必须在 IndexIVF 上设置特定标志 (quantizer_trains_alone)。
nbits_mi = 12 # c
M_mi = 2 # m
coarse_quantizer_mi = faiss.MultiIndexQuantizer(d, M_mi, nbits_mi)
ncentroids_mi = 2 ** (M_mi * nbits_mi)
index = faiss.IndexIVFFlat(coarse_quantizer_mi, d, ncentroids_mi)
index.nprobe = 2048
index.quantizer_trains_alone = True
与 IndexFlat 相比,MultiIndexQuantizer 在快速/低精度操作点方面通常具有竞争力。
3.index factory
index_factory 函数解释字符串以生成复合 Faiss 索引。
该字符串是一个以逗号分隔的组件列表。
它的目的是促进索引结构的构造,特别是当它们是嵌套的时。
index_factory 参数通常包括预处理组件、倒排文件和编码组件。
例如,
index = index_factory(128, “PCA80, Flat”) : 生成一个 128 维度的索引,并通过 PCA 把他降维到 80,然后进行穷举搜索。
index = index_factory(128, “OPQ16_64,IMI2x8,PQ8+16”) : 生成 128D 向量,对 64D 中的 16 个块进行 OPQ 变换,使用 2x8 位的反向多索引(= 65536 个反向列表),然后用大小为 8 的 PQ 进行细化,再用 16 字节进行细化。
1.Prefixes
| String | Class name | Comments |
|---|---|---|
| IDMap | IndexIDMap | 启用add_with_ids 用于在不支持他的索引上,主要是 Flat 索引。 |
| IDMap2 | IndexIDMap2 | Same, but in addition supports reconstruct. |
2.向量转换
这些字符串映射到 VectorTransform 对象,这些对象可以在索引化之前应用于向量
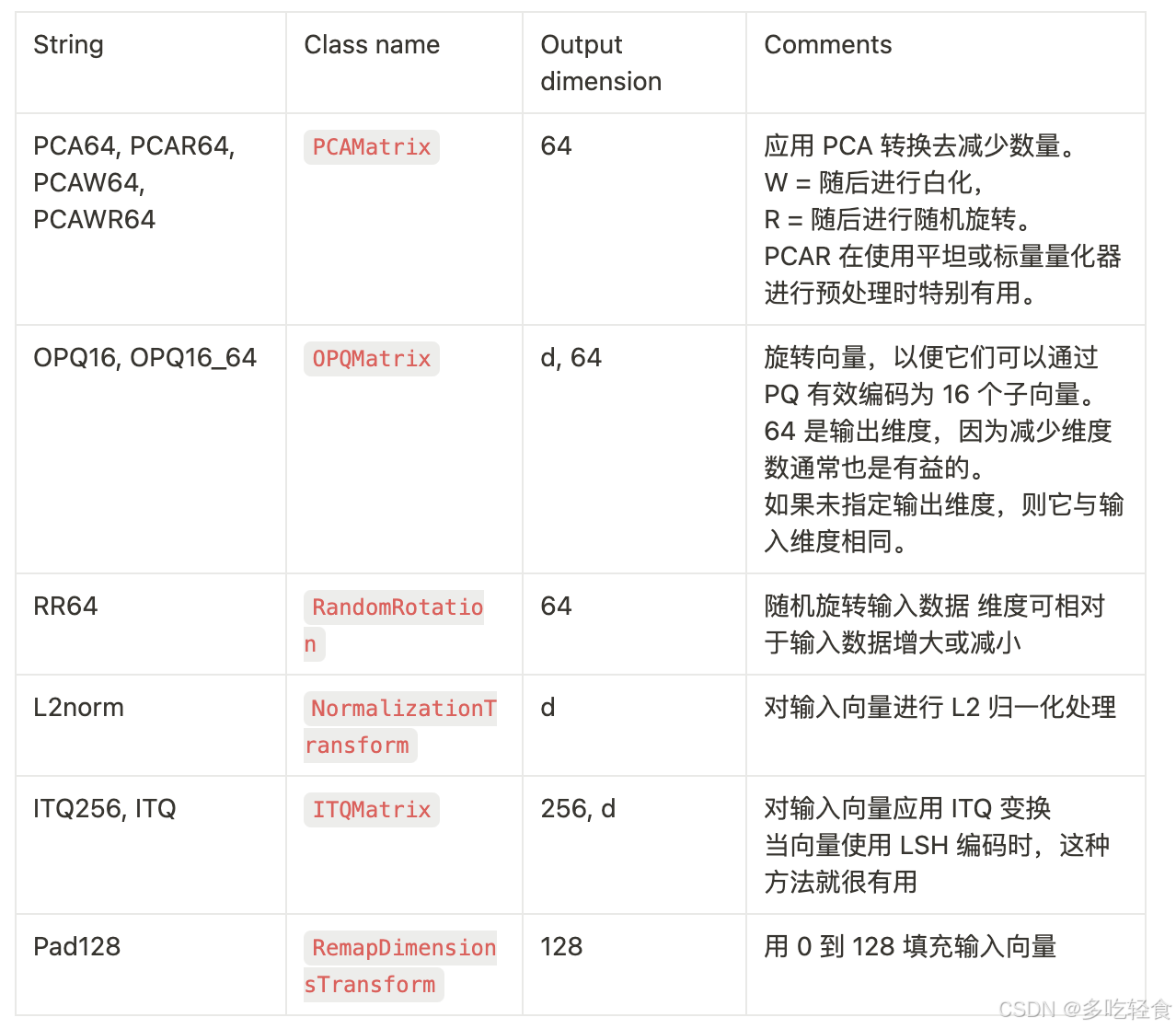
3.非穷尽搜索组件
-
倒排文件索引
倒排文件全部继承自
IndexIVF。非穷举组件指定粗略量化器(构造函数的第一个参数)应该是什么。
工厂字符串以
IVF或IMI开头,系统地后跟逗号和编码String Quantizer class Number of centroids Comments IVF4096 IndexFlatL2orIndexFlatIP4096 构造具有 Flat 量化器的 IndexIVF 变体之一。 IMI2x9 MultiIndexQuantizer2^(2 * 9) = 262144 构建具有更多质心的 IVF,可能不太平衡。 IVF65536_HNSW32 IndexHNSWFlat65536 量化器被训练为 Flat 索引,但使用 HNSW 进行索引。这使得量化速度更快 IVF65536(PQ16x4) arbitrary 65536 使用括号中的字符串构造粗量化器。 IVF1024(RCQ2x5) ResidualCoarseQuantizer1024 这是前一种情况的特例。粗量化器是残差量化器。 -
基于图的索引
HNSW 和 NSG 是基于图的索引。它们继承自
IndexHNSW和IndexNSG。两者都依赖于存储实际向量的平面存储IndexFlatCodes。String Storage class Comment HNSW32, HNSW IndexFlatL2可以说是最有用的 HNSW 变体,因为当存储链接时,压缩向量没有多大意义。 32(每个顶点的链接数)是默认值,可以省略。 HNSW32_SQ8 IndexScalarQuantizerSQ8 标量量化器 HNSW32_PQ12 IndexPQPQ12x8索引 HNSW32_16384+PQ12 Index2Layer第一层是 Flat 索引,PQ 对量化器的残差进行编码 HNSW32_2x10+PQ12 Index2Layer第一层是 IMI 索引,PQ 对量化器的残差进行编码 -
内存消耗
- 在
HNSW32中,32 编码链接数量,使用最多内存的最低级别有 32 * 2 个链接,即每个向量 32 * 2 * 4 = 256 字节。所以开销是相当大的。 - 在
NSG32中,32 直接编码每个顶点的链接数量,因此 32 意味着每个向量 32 * 4 = 128 字节。 - 对于
IVF和IMI索引,主要开销是每个向量的 64 位 id 也被存储(即每个向量 8 个字节的开销)
- 在
4. 编码
| String | Class name (Flat/IVF) | code size (bytes) | Comments |
|---|---|---|---|
| Flat | IndexFlat, IndexIVFFlat | 4 * d | 向量按原样存储,没有任何编码 |
| PQ16, PQ16x12 | IndexPQ, IndexIVFPQ | 16, ceil(16 * 12 / 8) | 使用乘积量化代码,每个代码有 16 个 12 位。当省略位数时,将其设置为 8。带有后缀“np”的情况下不会训练多义排列,这可能会很慢。 |
| PQ28x4fs, PQ28x4fsr, PQ28x4fs_64 | IndexPQFastScan, IndexIVFPQFastScan | 28 / 2 | 与上面的 PQ 相同,但使用 PQ 的“快速扫描”版本,该版本依赖 SIMD 指令进行距离计算。目前仅支持 nbits=4。后缀_64表示使用的 bbs 因子(必须是32的倍数)。后缀fsr(仅适用于IVF)表示向量应该由残差编码(更慢,更准确) |
| SQ4, SQ8, SQ6, SQfp16 | IndexScalar Quantizer, IndexIVF ScalarQuantizer | 4*d/8, d, 6*d/8, d*2 | 标量量化器编码 |
| Residual128, Residual3x10 | Index2Layer | ceil(log2(128) / 8), ceil(3*10 / 8) | 残差编码。将向量量化为 128 个中心点或 3x10 MI 中心点。之后应使用 PQ 或 SQ 对残差进行实际编码。只能用作编解码器。 |
| RQ1x16_6x8 | IndexResidualQuantizer | (16 + 6*8) / 8 | 残差量化编解码器。首先用 2^16 个中心点的量化器对矢量进行编码,然后分 6 个阶段对残差进行细化,每个阶段有 256 个中心点。 |
| RQ5x8_Nqint8 | IndexResidualQuantizer | 5+1 | 残余量化器索引,范数量化为 8 位(其他选项包括 Nqint4 和 Nfloat) |
| LSQ5x8_Nqint8 | IndexLocalSearchQuantizer | 5+1 | 相同,使用局部搜索量化器 |
| PRQ16x4x8 | IndexProductResidualQuantizer | 16*4 | 该向量被分割为 16 个子向量,每个子向量被编码为大小为 4x8 的残差量化器。 |
| PLSQ16x4x8 | IndexProductResidualQuantizer | 16*4 | 相同,使用 LSQ 量化器 |
| ZnLattice3x10_6 | IndexLattice | ceil((3*log2(C(d/3, 10)) + 6) / 8) | 格子编解码器。该向量首先分为 3 段,然后将每段编码为其范数(6 位)和维度 d/3 中单位球体上的方向,由半径^2 = 10 的 Zn 晶格量化。C(dim , r2) 是半径 sqrt(r2) 的球体上具有整数坐标的点数(有关更多详细信息,请参阅此处,以及有关如何设置半径的要点)。 |
| LSH, LSHrt, LSHr, LSHt | IndexLSH | ceil(d / 8) | 通过阈值对向量进行二值化处理。在搜索时,查询向量也会被二值化(对称搜索)。后缀 r = 在二值化之前旋转向量,t = 训练阈值以平衡 0 和 1。可与 ITQ 结合使用。 |
| ITQ90,SH2.5 | IndexIVFSpectralHash | ceil(90 / 8) | 只有 IVF 版本。将向量转换为使用 ITQ 进行编码(也支持 PCA 和 PCAR),降低至 90 维度。然后对每个分量进行编码,[0, 2.5] 给出位 0,[2.5, 5] 给出位 1,模 5。 |
5.后缀
| String | Storage class | Comment |
|---|---|---|
| RFlat | IndexRefineFlat | 通过精确的距离计算对搜索结果重新排序 |
| Refine(PQ25x12) | IndexRefine | 相同,但细化索引可以是任何索引。 |
6.例子
让我们看看最复杂的工厂字符串之一
OPQ16_64,IVF262144(IVF512,PQ32x4fs,RFlat),PQ16x4fsr,Refine(OPQ56_112,PQ56)
OPQ16_64: OPQ pre-processingIVF262144(IVF512,PQ32x4fs,RFlat): 具有 262k 质心的 IVF 索引。粗量化器是带有附加细化步骤的 IVFPQFastScan 索引。PQ16x4fsr: 向量使用 PQ 快速扫描进行编码(每个向量需要 16 * 4 / 8 = 8 字节)Refine(OPQ56_112,PQ56): 重排序索引是经过OPQ预处理的PQ,占用56字节。