零、导包准备
import torch
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import numpy as np
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
一、建立数据集
animals-6
--train
|--dog
|--cat
...
--valid
|--dog
|--cat
...
--test
|--dog
|--cat
...
我的数据集中 train 中每个类别60张图片,valid 中每个类别 10 张图片,test 中每个类别几张到几十张不等,一共 6 个类别。
数据集路径
- 在项目根目录下创建一个 data 文件夹(名字可以任意),用来存放数据集。
- 在 data 文件夹下依次创建 train、valid、test 文件夹(test 文件夹可以没有,依据自己需求确定)
- 在 train 文件夹下创建类别文件夹,如 cat、dog 等
- 在类别文件夹如 cat 下,存放 cat 类别的图片。
- …
- 在 val 文件夹下创建类别文件夹,如 cat、dog 等
- 在类别文件夹如 cat 下,存放 cat 类别的图片。
- …
- …
- 在 train 文件夹下创建类别文件夹,如 cat、dog 等
- 在 data 文件夹下依次创建 train、valid、test 文件夹(test 文件夹可以没有,依据自己需求确定)
二、数据增强
建好的数据集在输入网络之前先进行数据增强,包括随机 resize 裁剪到 256 x 256,随机旋转,随机水平翻转,中心裁剪到 224 x 224,转化成 Tensor,正规化等。
image_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
三、加载数据
torchvision.transforms包DataLoader是 Pytorch 重要的特性,它们使得数据增加和加载数据变得非常简单。
使用 DataLoader 加载数据的时候就会将之前定义的数据 transform 就会应用的数据上了。
dataset = 'data'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'valid')
batch_size = 32
num_classes = 6
print(train_directory)
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid'])
}
train_data_size = len(data['train'])
valid_data_size = len(data['valid'])
train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8)
valid_data = DataLoader(data['valid'], batch_size=batch_size, shuffle=True, num_workers=8)
print(train_data_size, valid_data_size)
四、迁移学习
这里使用ResNet-50的预训练模型。
resnet50 = models.resnet50(pretrained=True)
在PyTorch中加载模型时,所有参数的‘requires_grad’字段默认设置为true。这意味着对参数值的每一次更改都将被存储,以便在用于训练的反向传播图中使用。这增加了内存需求。由于预训练的模型中的大多数参数已经训练好了,因此将requires_grad字段重置为false。
for param in resnet50.parameters():
param.requires_grad = False
为了适应自己的数据集,将ResNet-50的最后一层替换为,将原来最后一个全连接层的输入喂给一个有256个输出单元的线性层,接着再连接ReLU层和Dropout层,然后是256 x 6的线性层,输出为 6 通道的softmax层。
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 6),
nn.LogSoftmax(dim=1)
)
# 用GPU进行训练。
resnet50 = resnet50.to('cuda:1')
# 定义损失函数和优化器。
loss_func = nn.NLLLoss()
optimizer = optim.Adam(resnet50.parameters())
五、训练
def train_and_valid(model, loss_function, optimizer, epochs=25):
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
history = []
best_acc = 0.0
best_epoch = 0
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(tqdm(train_data)):
inputs = inputs.to(device)
labels = labels.to(device)
#因为这里梯度是累加的,所以每次记得清零
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(tqdm(valid_data)):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_function(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/train_data_size
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/valid_data_size
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if best_acc < avg_valid_acc:
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch+1, avg_valid_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start
))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
torch.save(model, 'models/'+dataset+'_model_'+str(epoch+1)+'.pt')
return model, history
num_epochs = 30
trained_model, history = train_and_valid(resnet50, loss_func, optimizer, num_epochs)
torch.save(history, 'models/'+dataset+'_history.pt')
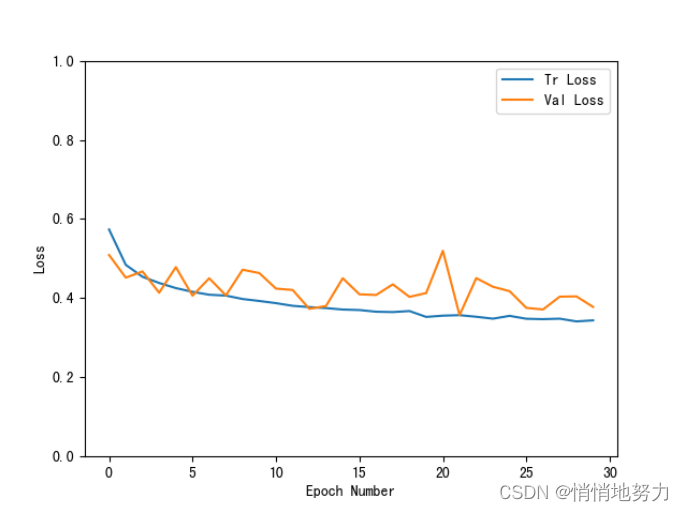
history = np.array(history)
plt.plot(history[:, 0:2])
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1)
plt.savefig(dataset+'_loss_curve.png')
plt.show()
plt.plot(history[:, 2:4])
plt.legend(['Tr Accuracy', 'Val Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig(dataset+'_accuracy_curve.png')
plt.show()
网络训练过程中添加进度条关键代码
for i, (inputs, labels) in enumerate(tqdm(train_data)):
完整代码
import torch
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import numpy as np
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
# 一、建立数据集
# animals-6
# --train
# |--dog
# |--cat
# ...
# --valid
# |--dog
# |--cat
# ...
# --test
# |--dog
# |--cat
# ...
# 我的数据集中 train 中每个类别60张图片,valid 中每个类别 10 张图片,test 中每个类别几张到几十张不等,一共 6 个类别。
# 二、数据增强
# 建好的数据集在输入网络之前先进行数据增强,包括随机 resize 裁剪到 256 x 256,随机旋转,随机水平翻转,中心裁剪到 224 x 224,转化成 Tensor,正规化等。
image_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
# 三、加载数据
# torchvision.transforms包DataLoader是 Pytorch 重要的特性,它们使得数据增加和加载数据变得非常简单。
# 使用 DataLoader 加载数据的时候就会将之前定义的数据 transform 就会应用的数据上了。
dataset = 'data'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'valid')
batch_size = 32
num_classes = 6
print(train_directory)
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid'])
}
train_data_size = len(data['train'])
valid_data_size = len(data['valid'])
train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8)
valid_data = DataLoader(data['valid'], batch_size=batch_size, shuffle=True, num_workers=8)
print(train_data_size, valid_data_size)
# 四、迁移学习
# 这里使用ResNet-50的预训练模型。
resnet50 = models.resnet50(pretrained=True)
# 在PyTorch中加载模型时,所有参数的‘requires_grad’字段默认设置为true。这意味着对参数值的每一次更改都将被存储,以便在用于训练的反向传播图中使用。
# 这增加了内存需求。由于预训练的模型中的大多数参数已经训练好了,因此将requires_grad字段重置为false。
for param in resnet50.parameters():
param.requires_grad = False
# 为了适应自己的数据集,将ResNet-50的最后一层替换为,将原来最后一个全连接层的输入喂给一个有256个输出单元的线性层,接着再连接ReLU层和Dropout层,然后是256 x 6的线性层,输出为6通道的softmax层。
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 6),
nn.LogSoftmax(dim=1)
)
# 用GPU进行训练。
resnet50 = resnet50.to('cuda:1')
# 定义损失函数和优化器。
loss_func = nn.NLLLoss()
optimizer = optim.Adam(resnet50.parameters())
# 五、训练
def train_and_valid(model, loss_function, optimizer, epochs=25):
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
history = []
best_acc = 0.0
best_epoch = 0
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(tqdm(train_data)):
inputs = inputs.to(device)
labels = labels.to(device)
#因为这里梯度是累加的,所以每次记得清零
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(tqdm(valid_data)):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_function(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/train_data_size
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/valid_data_size
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if best_acc < avg_valid_acc:
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch+1, avg_valid_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start
))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
torch.save(model, 'models/'+dataset+'_model_'+str(epoch+1)+'.pt')
return model, history
num_epochs = 30
trained_model, history = train_and_valid(resnet50, loss_func, optimizer, num_epochs)
torch.save(history, 'models/'+dataset+'_history.pt')
history = np.array(history)
plt.plot(history[:, 0:2])
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1)
plt.savefig(dataset+'_loss_curve.png')
plt.show()
plt.plot(history[:, 2:4])
plt.legend(['Tr Accuracy', 'Val Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig(dataset+'_accuracy_curve.png')
plt.show()
参考链接:https://cxyzjd.com/article/heiheiya/103028543