SQL常用函数
数学函数
ABS(x) --返回x的绝对值
BIN(x) --返回x的二进制(OCT返回八进制,HEX返回十六进制)
CEILING(x) --返回大于x的最小整数值
EXP(x) --返回值e(自然对数的底)的x次方
FLOOR(x) --返回小于x的最大整数值
GREATEST(x1,x2,...,xn) --返回集合中最大的值
LEAST(x1,x2,...,xn) --返回集合中最小的值
LN(x) --返回x的自然对数
LOG(x,y) --返回x的以y为底的对数
### MOD(x,y) -- 返回x/y的模(余数)
PI() --返回pi的值(圆周率)
RAND() --返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
ROUND(x,y) --返回参数x的四舍五入的有y位小数的值
SIGN(x) --返回代表数字x的符号的值
SQRT(x) --返回一个数的平方根
TRUNCATE(x,y) --返回数字x截短为y位小数的结果
两值比较大小
--取值小的
select least(11,22) --11
--取值大的
select greatest(33,44) --44
日期和时间函数
CURRENT_DATE() --返回当前的日期
CURRENT_TIME() --返回当前的时间
DATE_FORMAT(now(),'%Y-%m-%d') --依照指定的fmt格式格式化日期date值 mysql
DATE_FORMAT(now(),'yyyy-MM-dd') --依照指定的fmt格式格式化日期date值 hive
select next_day('2019-12-12','MO');--取当前天的下一个周一2019-12-16
DAYOFWEEK(date) --返回date所代表的一星期中的第几天(1~7)
DAYOFMONTH(date) --返回date是一个月的第几天(1~31)
DAYOFYEAR(date) --返回date是一年的第几天(1~366)
HOUR(time) --返回time的小时值(0~23)
MINUTE(time) --返回time的分钟值(0~59)
MONTH(date) --返回date的月份值(1~12)
QUARTER(date) --返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE);
WEEK(date) --返回日期date为一年中第几周(0~53)
YEAR(date) --返回日期date的年份(1000~9999)
--20171205转成2017-12-05
select from_unixtime(unix_timestamp('20220406','yyyymmdd'),'yyyy-mm-dd'); --hive函数
select str_to_date('20220406','%Y%m%d') ---starrocks函数
--2017-12-05转成20171205
select from_unixtime(unix_timestamp('2017-04-05','yyyy-mm-dd'),'yyyymmdd');
--时间
select timediff('18:00:00','16:30:30')
--日期
select datediff('2016-12-30','2016-12-29') --1
select date_add('2016-12-29',10); --2017-01-08
select date_sub('2021-05-15',10); --2021-05-05
--月份
select add_months(‘2020-09-04’,-1); --2020-08-04
--月报常用,每个月第一天
trunc(dt,"MM")=trunc(add_months(current_date(),-1),"MM")
--获取每个月最后一天
select last_day('2022-08-10') --2022-08-31
开窗函数
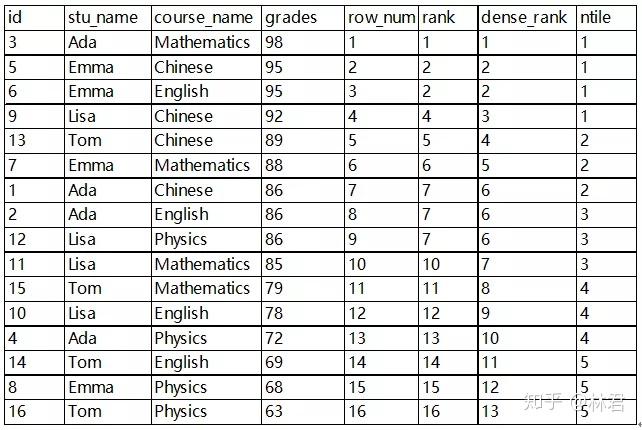
1:--排序()
row_number()over(partition by 分组字段 order by 排序字段 desc) as rn
--根据顺序计算:1,2,3,4,5
rank()over(partition by 分组字段 order by 排序字段 desc ) rk,
--排序相同时会重复,总数不会变: 1,2,2,4,5
dense_rank() over(partition by 分组字段 order by 排序字段 desc ) drk,
--排序相同时会重复,总数会减少:1,2,2,3,4
ntile( n ) over():
--可以看作是把有序的数据集合平均分配到指定的数量n的桶中,将桶号分配给每一行,排序对应的数字为桶号。如果不 能平均分配,则较小桶号的桶分配额外的行,并且各个桶中能放的数据条数最多相差1。
2--:取对应位置的值
--从当前行访问上一行的数据
lag(对比字段,偏移量,超出边界默认值) over(partition by 分组字段 order by 排序字段)
--从当前行访问下一行的数据
lead(对比字段,偏移量,超出边界默认值) over(partition by 分组字段 order by 排序字段)
--first_value()在结果的所有行记录中输出同一个满足条件的第一个记录;
--last_value()在结果的所有行记录中输出同一个满足条件的最后一个记录;
3:--聚合:sum(),count(),avg()...
--查询顾客的购买明细及月购买总额
select *,sum(cost) over(partition by substring(order_date,1,7)) from business;
--jack,2017-01-01,10,205
--jack,2017-01-02,55,205
举例说明:
开窗之累计到当前行
通常用between frame_start 和 frame_end语法来表示行的范围,frame_start和frame_end可支持:
- current row 边界是当前行,一般和其他范围关键字一起使用
- unbounded preceding 边界是分区中的第一行
- unbounded following 边界是分区中的最后一行
- expr preceding 边界是当前行减去expr的值
- expr following 边界是当前行加上expr的值
with start_sum as(
select '2022-01-31' as query_effdt,'2022' as query_year,'1月' as query_month,'10000228/10000109'deptid_path_all,'主动离职' as action_reason,1 as termination_emp_num union all
select '2022-02-28' as query_effdt,'2022' as query_year,'2月' as query_month,'10000228/10000109'deptid_path_all,'主动离职' as action_reason,2 as termination_emp_num union all
select '2022-03-31' as query_effdt,'2022' as query_year,'3月' as query_month,'10000228/10000109'deptid_path_all,'主动离职' as action_reason,3 as termination_emp_num union all
select '2022-04-30' as query_effdt,'2022' as query_year,'4月' as query_month,'10000228/10000109'deptid_path_all,'主动离职' as action_reason,4 as termination_emp_num union all
select '2022-01-31' as query_effdt,'2022' as query_year,'1月' as query_month,'10000228/10000109'deptid_path_all,'被动离职' as action_reason,10 as termination_emp_num union all
select '2022-05-31' as query_effdt,'2022' as query_year,'5月' as query_month,'10000228/10000109'deptid_path_all,'被动离职' as action_reason,5 as termination_emp_num union all
select '2022-06-30' as query_effdt,'2022' as query_year,'6月' as query_month,'10000228/10000109'deptid_path_all,'被动离职' as action_reason,5 as termination_emp_num union all
select '2022-09-01' as query_effdt,'2022' as query_year,'9月' as query_month,'10000228/10000109'deptid_path_all,'被动离职' as action_reason,5 as termination_emp_num
)
select
t1.query_effdt --查询日期
,t1.query_year --查询年
,t1.query_month --查询月
,t1.deptid_path_all --汇报链组织全路径ID
,t1.action_reason --离职类型:主动离职/被动离职
,sum(t1.termination_emp_num) over(partition by t1.query_year,t1.deptid_path_all,t1.action_reason order by t1.query_effdt rows between unbounded preceding and current row ) as termination_emp_num
from start_sum t1
trunc(A,B)
一、日期
TRUNC(date,'fmt')
:date 一个日期值
fmt 日期格式,该日期将由指定的元素格式所截去。忽略它则由最近的日期截去
如果当日日期是:2011-3-18
select trunc(sysdate) from dual --2011-3-18 今天的日期为2011-3-18
select trunc(sysdate, 'mm') from dual --2011-3-1 返回当月第一天.
select trunc(sysdate,'yy') from dual --2011-1-1 返回当年第一天
select trunc(sysdate,'yyyy') from dual --2011-1-1 返回当年第一天
select trunc(sysdate,'d') from dual --2011-3-13 (星期天)返回当前星期的第一天
二、数字
TRUNC(number,num_digits)
Number 需要截尾取整的数字。
Num_digits 用于指定取整精度的数字。Num_digits 的默认值为 0。
TRUNC()函数截取时不进行四舍五入
select trunc(123.458) from dual --123
select trunc(123.458,0) from dual --123
select trunc(123.458,1) from dual --123.4
select trunc(123.458,-1) from dual --120
select trunc(123.458,-4) from dual --0
select trunc(123.458,4) from dual --123.458
regexp_extract(字段,正则,2)
返回值: string
第一参数: 要处理的字段
第二参数: 需要匹配的正则表达式
第三个参数:
0是显示与之匹配的整个字符串
1 是显示第一个括号里面的
2 是显示第二个括号里面的
...
eg:
select regexp_extract('hitdecisiondlist','(i)(.*?)(e)',0) ; --结果:itde
select regexp_extract('hitdecisiondlist','(i)(.*?)(e)',1) ; --结果:i
select regexp_extract('hitdecisiondlist','(i)(.*?)(e)',2) ; --结果:td
regexp_replace( A, B,C)
A: 匹配的字段
B: 匹配的正则表达式
C: 符合B正则表达是的则替换成C
eg:
select regexp_replace('手机:13528923052,住址:广州市...','^1[3-9][0-9]{8}','加密#***#')
regexp(字段,‘匹配值’)
select regexp('football', 'ba'); --true
get_json_object(A, B)
---json_extract(json,'$.key')---mysql/presto 中使用--
data = {
"store":
{
"fruit":[{"weight":8,"type":"apple"}, {"weight":9,"type":"pear"}],
"bicycle":{"price":19.95,"color":"red"}
},
"email":"amy@only_for_json_udf_test.net",
"owner":"amy"
}
eg:
--单层
hive> select get_json_object(data, '$.owner') from test; --结果:amy
--多层
hive> select get_json_object(data, '$.store.bicycle.price') from test; --结果:19.95
--数组值
hive> select get_json_object(data, '$.store.fruit[0]') from test;
--结果:{"weight":8,"type":"apple"}
concat()、concat_ws()、group_concat()、string_agg()、concat_set()
1--y='2021',m='05',d='15'
select concat_ws('-',y,m,d) ---'2021-05-15'
select concat(y,'-',m,'-',d)---'2021-05-15'
select a,concat_set()[0] from table_name group by a
2--
select name,group_concat('_',d) as day,age from table group by name
--a,01_02_03_..,18
--b,04_05_06_..,20
3--
select deptno, string_agg(ename, ',') from employee group by deptno;
-- 20 | JONES
-- 30 | ALLEN,MARTIN
select deptno, string_agg(ename, ',' order by ename desc) from employee group by deptno;
--在基础上按ename倒序排序
4--把数组转为字符串
concat_ws(',',collect_set(deptid_path_all))
with rollup 分组汇总
select class,name,sum(socer) from students group by class,name with rollup
presto的日期加减
select
substr(day,1,10) as day
,(date(substr(day,1,10)) - interval '1' day) as sub_day
,(date(substr(day,1,10)) + interval '1' day) as add_day
from test_tb
lateral view explode(split(column,‘\\|’)) 一行转多行(列转行)
explode() 炸开
1.split(string,分割符)
2.lateral view
explode 将结构复杂的一行拆成多行,实现列转行
--Lateral View 是为了优化 UDTF
Lateral View用于和UDTF函数(explode、split)结合来使用。
首先通过UDTF函数拆分成多行,再将多行结果组合成一个支持别名的虚拟表。虚拟表相当于再和主表关联, 从而达到添加“UDTF生成的字段“以外字段的目的, 即主表里的字段或者主表运算后的字段。
--主要解决在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段、以及多个UDTF的问题
--语法
lateral view UDTF(expression) table_view as new_column;
--使用案列:
-----hive
select
query_effdt
,emplid
,manager_level_airbone
,deptid_path_all
from hdp_hr_dws.dws_hr_cadre_employee_info_1dfs
lateral view explode(split(manager_deptid_path_all,'\\,')) tmp_table as deptid_path_all
where manager_flag='leave'
and empl_rcd='0'
and empl_class='EMP'
----starrocks
select
t1.query_effdt
,t1.setid_dept
,t1.deptid
,t1.t_deptid_path_all
,tmp.unnest as deptids
,tmp1.unnest as deptid2
from hive_catalog.hdp_hr_dwd.dwd_hr_job_detail_info_1dfsp t1 ,
unnest(split(t_deptid_path_all,'/')) tmp ,
unnest(split(t_deptid_path_all,'/')) tmp1
-----
with t1 as (
select 1 as min_num, 6 as max_num union all
select 4 as min_num, 11 as max_num union all
select 9 as min_num, 17 as max_num union all
select 8 as min_num, 12 as max_num
)
select
t1.min_num,
t1.max_num,
array_sort(array_agg(t2.unnest)) as pro_lvl
from t1,
unnest([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]) as t2
where t2.unnest >= t1.min_num
and t2.unnest <= t1.max_num
group by
t1.min_num,
t1.max_num
order by min_num
说明
#1、UDF:进来一个出去一个,row mapping, 是row级别的操作 ,如upper,substr函数
#2、UDAF:进来多个出去一个,row mapping, 是row级别的操作 ,如sum,max等
#3、UDTF:进来一个出去多个,如explode、split
collect_set()、collect_list() 多行合成单行(行转列)
-- 说明:将group by中的某列转为一个数组返回 collect_list不去重而collect_set去重
select user_id,collect_set(article_id) from user_actions group by user_id;
-- user1 ["101","104"]
select user_id,collect_list(article_id) from user_actions group by user_id;
-- user1 ["101","104","101","101"]
按⽤户分组,取出每个⽤户每天看过的所有视频的名字:
select username, collect_list(video_name) from t_visit_video group by username
但是上⾯的查询结果有点问题,因为霸王别姬实在太好看了,所以李四这家伙看了两遍,这直接就导致得到的观看过
视频列表有重复的,所以应该增加去重,使⽤collect_set,其与collect_list的区别就是会去重:
select username, collect_set(video_name) from t_visit_video group by usernam
sort_array(): 对数组排序
select user_id,sort_array(collect_list(article_id)) as contents from user_actions group by user_id;
-- user1 ["101","104","101","101"]
-- 把数组的值按小到大进行排序
size, length, reverse,array_length
select size(split('gaga,abab,cdcd','\\,')) --3
select length('gaga,abab,cdcd') --14
select reverse(split(reverse('10000211/10012279/10012283'),'/')[0]); --10012283
select split('10000211/10012279/10012283','/')[size(split('10000211/10012279/10012283','/'))-1];
--10012283
--starrocks--
select array_length([1,2,3]); --3
translate
select translate()
instr()
# INSTR(C1,C2,I,J) 在一个字符串中搜索指定的字符,返回发现指定的字符的位置;
C1 被搜索的字符串
C2 希望搜索的字符串
I 搜索的开始位置,默认为1
J 出现的位置,默认为1
select instr('10001485/10000212/10000233','10001485')=1; --true
select instr('10001485/10000212/10000233','10000212')>=1; --true
# select instr("abcde",'b');--2,
--即在字符串“abcde”里面,字符串“b”出现在第2个位置。如果没有找到,则返回0;不可能返回负数
coalesce()
表修改操作
#修改表注释
alter table my_table set tblproperties('comment'='表注释')
#修改表字段注释
alter table my_table change column userid userid string comment '用户id'
#修改分区字段注释
alter table my_table partition column(dt string comment '日期分区')
#修改视图注释
alter view my_view set tblproperties('comment'='表注释')
#修改视图字段注释(需要重建视图)
#删除视图
drop view my_view;
#创建视图
create view my_view
(user_id comment '用户号'
session_id commeng '会话id'
) comment '我的视图' as
select user_id,session_id from my_table
#修改表名
alter table mysu rename to new_su;
#查看详细信息
desc formatted my_talbe;
-- 选择数据库
use db;
-- 增加一列
alter table xxx add columns (user_name string);
-- 将增加的列放到某一列后面
alter table xxx change column user_name user_name string after user_id;
-- 将增加的列放到第一列位置
alter table xxx change column user_name user_name string first;
--测试--
create table hdp_hr_dwd.ygh_students
(
name string comment '姓名'
,birth string comment '生日'
,sex string comment '性别'
,stu_no string comment '学生编号'
) comment '学生信息表';
alter table hdp_hr_dwd.ygh_students add columns (class string comment '班级');
alter table hdp_hr_dwd.ygh_students add columns (hight string comment '身高');
alter table hdp_hr_dwd.ygh_students change column class class string comment '班级' after birth;
insert overwrite table hdp_hr_dwd.ygh_students
select '小明' as name,'2001-01-01' as birth,'男' as sex,'1' as class,'123456' as stu_no union all
select '张三' as name,'1999-01-01' as birth,'男' as sex,'2' as class,'123321' as stu_no union all
select '李四' as name,'1998-01-01' as birth,'男' as sex,'3' as class,'111222' as stu_no;
alter table hdp_hr_dwd.ygh_students change column class class string comment '班级' after name;
alter table hdp_hr_dwd.ygh_students change column hight hight string comment '身高' after sex;
更好
-- 查看表是否数据倾斜
select table_skewness('b_st_yz_aj_cgajfj');
-- 在哪个节点分布
select
xc_node_id, count(1)
from tablename
group by xc_node_id
order by xc_node_id desc;
pg库查看建表
select * from information_schema.columns
where
table_catalog='esop_basic' and
table_name='belong_base';
starrocks导数指定分割符
datax的streamload加以下参数:
{
"column_separator": "\\x01",
"row_delimiter": "\\x02"
}
pg日期函数
select substring(cast(current_date - INTERVAL ‘1 day’ as character varying),1,10)
查两表间数据之差
with table1 as (
select 1 as id,'a' as tag,'2023-05-01' as dt union all
select 2 as id,'b' as tag,'2023-05-02' as dt union all
select 3 as id,'c' as tag,'2023-05-03' as dt
)
,table2 as(
select 1 as id,'a' as tag,'2023-05-01' as dt union all
select 2 as id,'b' as tag,'2023-05-02' as dt union all
select 3 as id,'c' as tag,'2023-05-03' as dt union all
select 4 as id,'d' as tag,'2023-05-04' as dt
)
SELECT * FROM table2
EXCEPT
SELECT * FROM table1
这条SQL语句将返回在table2中存在但在table中不1存在的所有行。如果想要查询在table1中存在但在table2中不存在的所有行,可以将语句中的table2和table1交换位置
starrocks 建分区表
--1、 月增分区--
drop table if exists sr_hr_cryptic_dwd.dwd_hr_cost_empl_related_1dfsp;
create table sr_hr_cryptic_dwd.dwd_hr_cost_empl_related_1dfsp(
...............
)ENGINE=OLAP
DUPLICATE KEY(t_dttm_ymd,add_ym,emplid)
COMMENT "员工成本相关信息表"
PARTITION BY RANGE(t_dttm_ymd)
( START ('2016-01-01') END ('2050-01-01') EVERY (INTERVAL 1 MONTH))
DISTRIBUTED BY HASH(emplid) BUCKETS 24;
--2、ds 一个分区(保持每天最新)
) ENGINE=OLAP
DUPLICATE KEY(`ds`, `query_effdt`, `login_emplid`, `emplid`)
COMMENT "人与人汇报链权限表"
PARTITION BY RANGE(`ds`)
(PARTITION formal VALUES [('1970-01-01'), ('9999-12-31')))
DISTRIBUTED BY HASH(`ds`, `query_effdt`, `login_emplid`, `emplid`) BUCKETS 24;
--3、
mysql 系统表
--1.查看表的注释
SHOW TABLE STATUS FROM `数据库名` WHERE Name='表名';
--2.查看字段的注释
SHOW FULL COLUMNS FROM `表名`;
--3.修改表的注释
ALTER TABLE `表名` COMMENT '新注释';
--4.查看脚本语句
show create table db_labor_cost_dev.cost_labor_indirect
--5.查看某一个表的KEY
SHOW KEYS FROM db_labor_cost_dev.cost_labor_indirect WHERE Key_name = 'unique_key_name';
----字段名,字段类型,字段注释
select
concat(',',column_name) as column_name
,case when data_type in ('text','varchar') then 'string'
when data_type = 'float' then 'double'
when data_type = 'smallint' then 'int'
else data_type end as data_type
,concat('comment',' \'',column_comment,'\'' ) as comment
from information_schema.columns
where table_schema = 'db_labor_cost_dev'
and table_name = 'cost_labor_indirect'