【论文阅读笔记】Deep Learning Workload Scheduling in GPU Datacenters:Taxonomy, Challenges and Vision
论文链接
GPU数据中心的DL工作负载调度:分类、挑战、展望
Abstract
Deep learning (DL) shows its prosperity in a wide variety of fields. The development of a DL model is a time-consuming and resource-intensive procedure. Hence, dedicated GPU accelerators have been collectively constructed into a GPU datacenter. An efficient scheduler design for such GPU datacenter is crucially important to reduce the operational cost and improve resource utilization. However, traditional approaches designed for big data or high performance computing workloads can not support DL workloads to fully utilize the GPU resources. Recently, substantial schedulers are proposed to tailor for DL workloads in GPU datacenters. This paper surveys existing research efforts for both training and inference workloads. We primarily present how existing schedulers facilitate the respective workloads from the scheduling objectives and resource consumption features. Finally, we prospect several promising future research directions.
深度学习在很多领域取得成功。DL模型的发展是一个费时和资源密集的过程。因此,专用GPU已经被共同建造到数据中心。一个高效的调度器对于数据中心来说在减少操作开销和提高资源利用方面非常重要。然而,针对大数据中心和高性能计算设计的传统方法不能支持DL工作负载来有效利用GPU资源。最近,大量的调度器被设计来适应GPU数据中心的DL工作负载。本文调查了现有的针对训练和推理工作负载的研究。我们主要说明现有调度器如何从调度目标和资源消耗特性来促进各自的工作负载。最后,我们展望了几个有前景的研究方向。
1.Introduction
Recent decades have witnessed a dramatic increase in deep learning (DL) research, development, and application in many fields, including Go [130], medical analysis [125], robotics [48], etc. A standard DL development pipeline consists of model training and model inference. Each stage requires high-grade hardware resources (GPU and other compute systems) to produce and serve production-level DL models [62, 71, 106, 149]. Therefore it becomes prevalent for IT industries [62, 149] and research institutes [18, 19, 71] to set up GPU datacenters to meet their ever-growing DL development demands. A GPU datacenter possesses large amounts of heterogeneous compute resources to host large amounts of DL workloads. An effective scheduler system is urgently required to orchestrate these resources and workloads to guarantee the efficiency of DL workload execution, hardware utilization, and other scheduling objectives.
近几十年DL研究,发展和在各领域的应用取得了重大进步,包括 Go[130]、医学分析[125]、机器学[48]等等,一个标准的DL开发路线包括模型训练和模型推理。每个阶段需要大量硬件资源(GPU和其他计算系统)来生成和提供工业级的DL模型[62,71,106,149]。因此,it行业 [62, 149]和研究机构[18, 19, 71]建造GPU数据中心来满足不断增长的DL开发需求变得普遍。GPU数据中心拥有大量的异构计算资源来承载大量的DL工作负载。急需一个高效的调度器来协调这些资源和工作负载,以保证DL工作负载的执行效率、硬件利用率和其他调度目标。
The scheduler is responsible for determining the resource utilization of the entire datacenter and the performance of each job, which further affects the operation cost and user experience [42]. Specifically, (1) for model training, the scheduler allocates resources requested by the users to support the long-running offline training workloads. The scheduler needs to achieve high performance for each individual workload, high resource utilization for the entire datacenter, and high fairness among different users. Due to the unique and complicated features of DL training jobs, conventional scheduling algorithms for high performance computing (HPC) and big data workloads could cause unbalanced resource utilization and exorbitant infrastructure expense [157], and new solutions tailored for GPU datacenters are required. (2) For model inference, DL applications often serve as online services to answer users’ requests. They often have a higher expectation on the response latency and inference accuracy [25, 172]. Applications that fail to be completed within the specified time (Service Level Agreement) or have lower accuracy than expected may have little or no commercial values. Therefore, it is critical for the scheduler to balance the inference latency, accuracy and cost.
调度器负责决定整个数据中心的资源调度和每个任务的执行,这进一步影响运行开销和用户体验。具体来说,(1)对于模型训练,调度器分配用于请求的资源来支持长期运行的离线训练工作负载。调度器需要为每个单独的工作负载实现高性能,为这个数据中心实现高资源利用率,为每个用户实现高协调性。由于DL训练工作的独特性和负载性,用于高性能计算(HPC)和大数据工作负载的传统调度算法可能会导致不平衡的资源利用率和高昂的基础设施费用,所以GPU数据中心需要合适的新方法。(2)对于模型推理,DL应用通常作为线上服务来回答用户的请求,他们通常被期望有低响应延迟和高的推理准确率[25,172],那些不能在规定时间内做出响应或者精度低于预期的应用可能几乎或根本没有商业价值。因此,调度器需要平衡推理延迟、准确率和开销。
Over the years a variety of DL schedulers have been proposed for GPU datacenters [25, 46,
106, 117, 121, 152, 172]. However, most of these systems are designed in an ad-hoc way for some specific objectives. There is still a lack of comprehensive exploration towards efficient scheduling of DL workloads. We are interested in the following questions: (1) what are the main challenges for designing a satisfactory scheduler to manage DL workloads and resources? (2) Do existing solutions share common strategies to achieve their scheduling objectives? (3) How do we need to refine the schedulers to adapt to the rapid development of DL technology? Those questions are important for system researchers and practitioners to understand the fundamental principles of DL workload scheduling and management, and design innovative schedulers for more complex scenarios and objectives. Unfortunately, there are currently no such works to summarize and answer these questions from a systematic point of view.
多年来,大量的针对GPU数据中心的DL调度器已经被设计。然而,这些系统中的大多数都是以特定的方式为某些特定的任务设计。仍缺少对高效调度器的全面探索。我们关注以下几个问题:(1)设计一个令人满意的调度器来管理DL工作负载和资源的主要挑战是什么?(2)现有的方法是否在实现他们的调度目标方面是否存在共同策略?(3)我们如何改进调度器来适应急速发展的DL技术?这些问题对于系统研究这从业者理解DL工作负载调度和管理,并为更负载场景和目标设计新的调度器来说至关重要。不幸的是,目前还没有工作从系统的角度来总结和回答这些问题。
To the best of our knowledge, this paper presents the first survey for scheduling both DL training and inference workloads in research and production GPU datacenters. We make the following contributions. First, we perform an in-depth analysis about the characteristics of DL workloads and identify the inherent challenges to manage various DL workloads in GPU datacenters. Second, we comprehensively review and summarize existing DL scheduling works. We categorize these solutions based on the scheduling objectives and resource consumption features. We also analyze their mechanisms to address the scheduling challenges. Such summary can disclose the common and important considerations for existing DL scheduler designs. Third, we conclude the limitations and implications from existing designs, which can shed new light on possible directions of scheduler designs in GPU datacenters. We expect this survey can help the community understand the development of DL schedulers and facilitate future designs.
据我们所知,本文首次对研究和工业GPU数据中心的DL训练和推理工作负载进行了调研。我们做出了如下贡献。首先,我们对DL工作负载进行深入分析,并确定GPU数据中心中管理不同DL工作负载的挑战。其次,我们全面回顾和总结了现有的DL调度工作,我们根据调度目标和资源消耗特征对这些方法进行分类。我们也分析了他们解决调度挑战的原理。这样的总结可以说明现有DL调度设计常见和重要的考虑因素。第三,我们总结了现有设计的局限性和联系,这可以为GPU数据中心调度器设计你的可能方向提供新的线索。我们希望这项工作可以帮助大家了解DL调度器的发展并为未来设计提供思路。
Existing surveys. Past works also presented some surveys, which are relevant to but distinct
from ours. (1) Some works summarized the optimization techniques for DL applications, such as distributed training acceleration [112, 139], efficient model inference [44, 90], etc. These surveys primarily focused on the acceleration of individual jobs, while we consider the global optimization of the entire datacenter with plenty of workloads for various objectives. (2) Some works surveyed the scheduler designs for conventional cloud big data [128, 171] and HPC [109, 120] workloads. As discussed in Sec. 2.1, DL workloads have significantly distinct characteristics from these traditional jobs, and their scheduling mechanisms are not quite adaptable for DL training or inference. (3) Very few surveys conducted investigations on DL workload scheduling. Mayer and Jacobsen [98] summarized early designs of DL training job schedulers before 2019. This summary is outdated due to the emerging scheduling algorithms in recent years. Yu et al. [164] proposed a taxonomy for DL inference system optimization based on the computing paradigm. However, it mainly investigated the single node scenario instead of the datacenter scale. A recent work [163] considered the inference scheduling by colocating multiple workloads on the same GPU from both the cluster level and workload level. Different from those works, we provide a very comprehensive and up-to-date survey for scheduling techniques of both DL training and inference in the entire GPU datacenters
现有研究。 过去的工作也进行了一些调查,他们和我们的研究相关但不同。(1)一些工作总结了DL应用的优化技术,比如分布式训练加速[112,39],高效模型推理等等。这些调查主要关注当个工作的加速,而我们考虑具有各种工作负载的数据中心的全局优化。(2)一些工作研究为传统云大数据和HPC工作负载设计的调度器。如2.1节所示,DL工作负载和这些任务具有显著的区别,他们的调度原理不适用于DL训练和推理。(3)很少研究关注DL工作负载调度。[98]总结2019年之前的DL训练任务调度,由于今年来产生的大量调度器,这个工作已经过时了。[164]提出了一种基于计算范式的DL推理系统优化分类法,然而,它主要研究的是单节点场景,而不是数据中心规模。[163]考虑了通过从集群级别和工作负载级别将多个工作负载集中在同一GPU上进行推理调度。与这些工作不同的是,我们提供了一个对于整个GPU数据中心的DL训练和推理的调度全面和最新的研究。
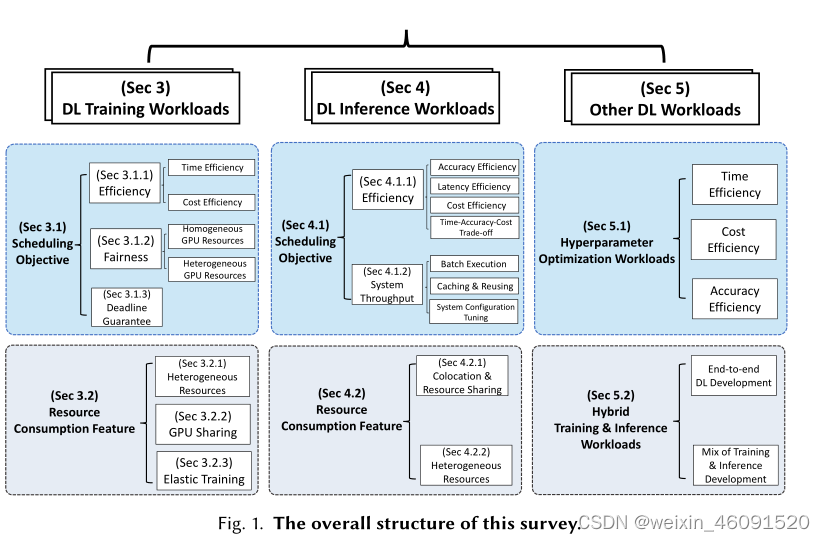
Paper organization. The paper is organized as follows: Sec. 2 describes the unique characteristics of DL workloads and challenges for scheduling in GPU datacenters. It also illustrates the scope of this survey. The main body of this survey is presented in Fig 1.Concretely, Sec. 3 and Sec.4 present detailed categorizations of training and inference workloads based on the scheduling objectives and resource consumption features, respectively. Sec. 5 discusses the other workloads, e.g., hyperparameter optimization, mixed training and inference workloads. Implications from these works are also given at the end of each section. Sec. 6 concludes this survey paper and identifies the future directions of scheduler designs.
**论文结构。**本文组织如下:第二节描述了DL工作负载独特的特征和GPU数据中心调度的挑战。他也说明了本次调查的范围。本次调查的主体结构在图1中展现。具体而言,第三节和第四节基于调度目标和资源消耗特征对训练和推理工作负载进行了详细的分类。第五节讨论了其他工作,诸如超参数优化,混合训练和推理工作负载。这些工作的实现也在每个部分的最后给出。第六节总结了本次调查并指出未来的研究方向。
2.Background
2.1 DL工作负载及他们的特征
A DL development pipeline typically consists of three stages: data processing, model training and model inference. In this survey, we narrow down our focus to training and inference workloads which account for the most computation and consume the majority of resources in the datacenter.
一个DL开发流程通常有三个阶段组成:数据处理、模型训练和模型推理。在这个调查中,我们将关注点缩小到训练和推理工作负载,它们占用了数据中心的大部分计算并消耗大部分资源。
2.1.1 DL Traning
A DL training workload builds models by extracting features from existing data. A DL framework (e.g., PyTorch [114], TensorFlow [6]) is commonly adopted to fully utilize heterogeneous compute resources to accelerate the training process. To further reduce the training time, the workload is deployed across multiple GPUs with a data-parallel training scheme, which is implemented via distributed training libraries (e.g., Horovod [124], DistributedDataParallel in Pytorch, MultiWorkerMirroredStrategy in Tensorflow).
DL训练工作负载从现有数据中提取特征来建立模型。DL框架通常充分利用异构计算资源来加快训练过程。为了进一步缩短训练时间,工作负载通过数据并行训练方案部署在多个GPU上,该方案通过分布式训练库实现。
DL training workloads exhibit some unique features compared to traditional big data or HPC
jobs, which need to be particularly considered for GPU datacenter scheduling. A series of studies have characterized training workloads from the production GPU datacenters, including Microsoft[71], SenseTime [62] and Alibaba [144, 149]. The characteristics are summarized as below.
DL训练工作负载具有和传统大数据或HPC不同的独特的特征,GPU数据中心调度需要特别关注这些特征。很多工作总结了工业GPU数据中心的训练负载工作的特征征,包括微软、SenseTime和阿里巴巴,这些特征总结如下:
T1: Inherent heterogeneity [71, 152]. GPU resources play a dominant role in DL training.
However, CPUs and memory might interfere with the input processing and then delay the training execution. A GPU datacenter generally offers an ample pool of CPU and memory resources compared to GPUs. Arbitrary selection of heterogeneous resource combinations by users may lead to imperfect training progress. Figure 2 (f) shows the training performance speedups of common DL models with various generations of GPUs. Different models have diverse affinities to GPU types.
T1:Inherent heterogeneity(内在异质性):GPU资源在DL训练中发挥着主要作用,然而GPUs和内存可能会干扰输入处理,进而推迟训练执行,和GPU相比,GPU数据中心通常提供充足的GPU和内存资源池。用户任意选择异构资源组合可能导致训练进度不完美。图2(f)显示了具有不同代GPU的常见DL模型的训练性能加速。不同的模型对GPU类型具有不同的偏向。
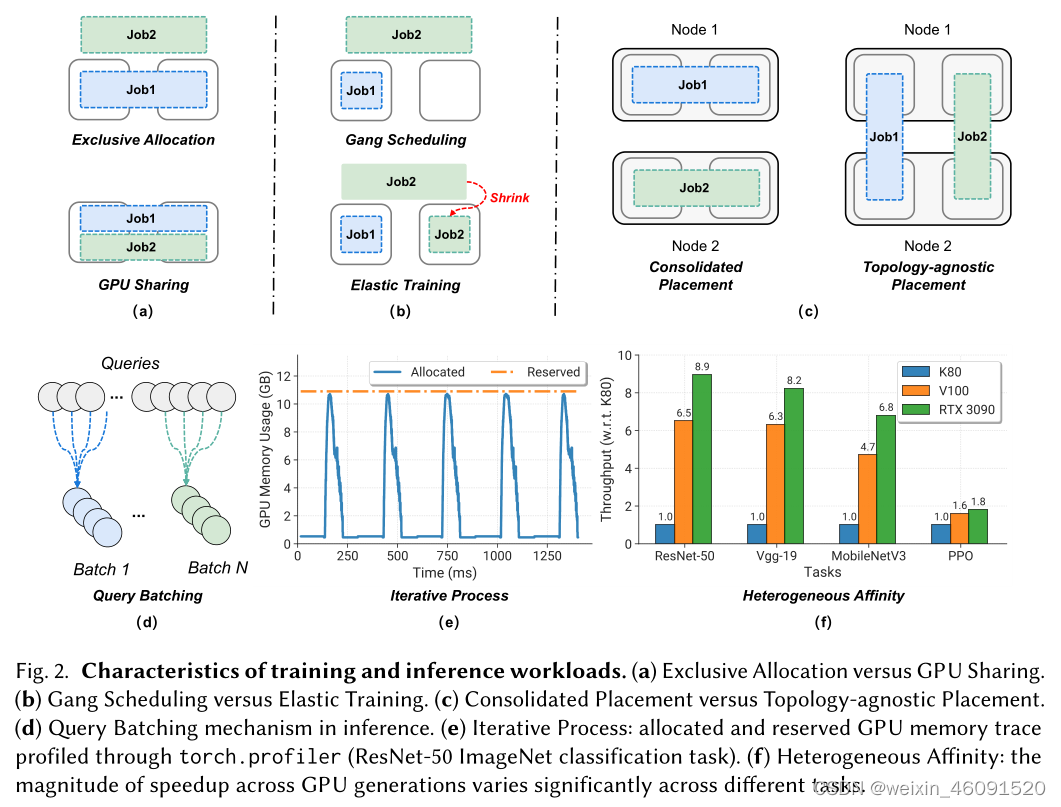
(a):独占分配和GPU共享
(b):集体调度和弹性训练
(c) : 合并布局和拓扑不可知布局
(e): 迭代过程:使用torch.profiler分析分配和保留的GPU内存跟踪
(f):异构亲和性:各代GPU的加速幅度在不同任务中差异很大。
T2: Placement sensitivity [97, 152]. Distributed DL jobs are sensitive to the locality of allocated GPU resources. Specifically, the runtime speed of some distributed DL jobs are bounded by device-to-device communication. Figure 2 © shows two types of placement, where a consolidated placement can efficiently reduce the communication overhead compared with topology-agnostic placement. The communication sensitivity of training jobs depends on the inherent property of the model structure. Advanced interconnect link (e.g., NVlink) can offer an order of magnitude higher bandwidth than PCIe. Therefore, distributed training jobs tend to request advanced interconnect to further obtain communication time reduction. Besides, jobs colocated in one server may suffer from PCIe bandwidth contention.
T2:放置位置敏感:分布式DL任务对分配的GPU资源的位置敏感。具体而言,一些DL分布式任务的运行速度受到设备之间通信的限制。图2(c)表示两种放置方式,与拓扑不可知的布局相比,合并布局可以有效减少通信开销。训练任务的通信敏感性取决于模型结构的固有特性。高级互连链路可以提供比PCIe高一个数量级的带宽。因此,分布式训练任务倾向于请求高级互连,以进一步减少通信时间。此外,位于一台服务器的作业可能会受到PCIe带宽争用的影响。
T3: Iterative process [42, 115]. DL training repeats a similar iterative pattern for up to thousands of times, as shown in Figure 2 (e). Each iteration consists of forward propagation, backward propagation and parameter update. It motivates that profiling a small number of iterations suffices to predict the pattern of future GPU memory usage and job completion time.
T3:迭代过程: 如图2(e)所示,DL训练任务重复一个类似的迭代模式多达上千次,每次的迭代包括前向传播、后向传播和参数更新。这促使分析少量迭代就可以预测未来GPU内存使用模式和作业完成时间。
T4: Feedback-driven exploration [152, 183]. Training a DL model is a typical trial-and-error process. Users may explore a number of trial configurations and terminate unpromising trials by the early feedback. Such early feedback can further motivate to launch new trial configurations. Hence, a GPU datacenter hosts abundant repetitive training trials and short duration trials.
**T4:反馈驱动的探索。**训练一个DL模型是一个典型的试错过程。用户可以探索很多种配置并在早期反馈终止。这种早期反馈可以进一步激励出新的使用配置。因此,GPU数据中心拥有大量重复训练试验和短时间试验。
**T5: Exclusive allocation [62] versus GPU sharing [149]. **Figure 2 (a) depicts the difference between exclusive allocation and GPU. Exclusive allocation refers to that a DL job exclusively has the resource usage ownership. On the contray, GPU sharing allows multiple jobs to co-locate in the same GPU device and take advantage of resources in a time-/space- sharing manner. Unlike CPUs, GPUs basically do not have the intrinsic hardware-level support for fine-grained sharing across users and thus they are allocated to DL training jobs exclusively. Due to the increasing hardware compute capability, plenty of DL training jobs can not fully utilize recent generations of GPU chips. To address this issue, datacenters enable GPU sharing through various technologies, e.g., NVIDIA Multi-Instance GPU (MIG) [3], Multi-Process Service (MPS) [4], GPU virtualization [61].
**T5:独占分配与GPU共享:**图2(a)描述了独占分配和GPU之间的区别。独占分配是指一个DL任务拥有资源使用所有权。相反,GPU共享运行多个作业共同加载到同一GPU上,并且以时间/空间共享的方式利用GPU资源。不像CPUs,GPUs基本上没有内在硬件级别支持跨用户的细粒度共享,因此它们被专门分配到DL训练任务上,由于硬件计算能力的逐步提升,大量的DL训练工作可以无法充分利用近几代GPU芯片。为了解决这个问题,数据中心通过各种技术实现GPU共享,比如NVIDA 多实例GPU,多进程服务,GPU虚拟化。
T6: Gang scheduling [62] versus elastic training [117]. Figure 2 (b) illustrates two scheduling mechanisms for data-parallel DL jobs. In particular, gang scheduling is that DL training requires all the GPUs to be allocated simultaneously in an all-or-nothing manner [35]. The requirement of gang scheduling results from the native support of DL frameworks and runtime speed performance guarantee. In contrast, elastic training removes the strict GPU request constraint, and allows a dynamic number of GPUs to run training jobs. Many scheduling systems support elastic training in order to improve GPU utilization and accelerate the training process. They take advantage of the elasticity of DL training workloads: a DL training job can adapt to a wide range of GPU counts
and the training processes can be suspended and resumed via checkpoints [62].
T6:集体调度和弹性训练。 图2(b)说明了数据并行DL作业的两种调度机制。特别地,集体调度是指DL训练任务以要么全有要么全无的方式分配所有GPU。集体调度的需求源于DL框架的本地支持和运行时速度性能保证。相反,弹性训练移除了严格的GPU请求限制,允许动态数量的GPUs运行训练任务。许多调度系统支持弹性训练以提高GPU利用率和加快训练过程。他们充分利用DL训练工作负载的灵活性;一个DL训练任务可以适应于广泛的GPU数量,并且训练过程可以通过检查点暂停和恢复。
2.1.2 DL inference
Model inference is the process of making predictions to users’ inputs. It is commonly applied as online services (e.g., personalized recommendations, face recognition, language translation). DL frameworks also make efforts to support inference workloads, like TensorFlow Serving [111], MXNet Model Server [1], etc. The inference jobs must be performed in a real-time manner, facing dynamic queries with strict latency requirements [172]. They may process each inference request individually, or batch multiple requests concurrently to balance the resource usage and latency. Since many inference systems are deployed in the public cloud alternative to on-premise clusters, there exist many works emphasizing how to exploit cloud resources at scale to handle inference requests. According to the report from A WS [63], the cost of DL inference has already taken up the majority (more than 90%) of the total infrastructure cost for machine learning as a service. A DL inference workload also gives unique characteristics that can affect the scheduling system designs. They are summarized as follows.
模型推理是根据用于输入进行预测的过程,通常作为在线服务(例如个性化推荐、人脸识别、语言翻译) DL框架也努力支持推理工作负载,如TensorFlow Serving,MXNet Model Server等,推理作业以实时的方式进行,具有严格的延迟要求的动态请求。他们可以一次处理一个请求,也可以同时批处理多个请求,来平衡资源使用和延迟。由于许多推理系统部署在公共云中,而不是部署在本地集群中,因此存在许多工作强调如何大规模利用云资源来处理推理请求。根据A WS[63]的报告,DL推理的成本已经占据了机器学习服务基础设施总成本的大部分(超过90%)。DL推理工作负载还提供了可以影响调度系统设计的特征。总结如下:
I1: Deterministic online execution [28, 51]. Different from offline training which could be resource-intensive and last for days or weeks, the inference for each query is often completed with sub-second response time and consumes much less resources. Moreover, many inference jobs reveal deterministic execution flows and duration under fixed-size query input. This gives predictable resource usage and execution speed, offering the opportunities of fine-grained optimization.
I1:确定性在线执行: 与资源密集且可以持续数天或数周的离线训练不同,每个请求的推理通常在几秒内完成并且消耗的资源要少的多。此外,在固定大小的查询输入下,很多推理作业表现出确定性的执行流和持续时间,这使得资源使用率和执行时间可预测,提供了细粒度优化的机会。
**I2: High demands on latency and accuracy [25, 172]. ** First, the inference service is expected to respond to the incoming queries promptly. Delays of inference responses can cause bad user experience. For example, an online recommend service is required to provide recommendations at interactive latencies (<100ms) to prevent user losses [25]. Other kinds of inference services also have strong latency requirements (e.g., <200ms [172]). Second, the prediction accuracy is also critical for building a reliable inference service. Inference workloads in some critical domains, e.g., healthcare and finance, may have stronger accuracy requirements [55]. The tight latency and accuracy demands pose great difficulty in managing inference jobs on GPUs, and there exist a trade-off between high accuracy and low latency. The datacenter managers need to carefully balance the latency overhead and prediction performance of the inference workloads.
I2:对延迟和准确率的高要求: 首先,推理任务需要迅速响应输入的请求,推理响应的延迟可能会导致用户糟糕的体验。例如,一个在线推荐服务需要在交互延迟(<100ms)内提供推荐,来防止用户流失。其他推理服务对延迟要求也很高。第二,准确率对建立可靠的推理服务也至关重要。一些关键领域的推理工作负载,例如医疗保健和金融可能具有更强的准确性要求。严格的延迟和准确性要求给在GPU上管理推理任务带来很大困难,并且在高精度和低延迟之间存在权衡。数据中心的管理者需要仔细平衡推理工作的延迟和准确性。
2.2 Scheduler in GPU Datacenters and Design Challenges
Scheduling has continuously drawn public attention for several decades [34, 36, 37]. Similar to scheduling at the level of the operating system, networking system or applications, parallel job scheduling at the datacenter level makes decisions about the allocation of computing resources to competing jobs for specific scheduling objectives [36], which forms an NP-hard problem. In
particular, it matches available resources with pending jobs and decides the optimal moment and amount of resources to be allocated to each job. Modern datacenters have introduced a number of schedulers to manage conventional workloads. For instance, HPC schedulers (e.g., Slurm [162], OpenPBS [5]) are used to support HPC applications and scientific computing; cloud schedulers (e.g., Mesos [59], Kubernetes [14], Yarn [138]) help allocate heterogeneous compute resources for big data applications at scale.
过去几十年调度受到大众的持续关注。类似在操作系统、网络系统或者应用级别的调度,数据中心级别的并行任务调度决定计算资源的分配给具有竞争关系的任务,来达到特定的调度目标,这是一个NP难问题。特别地,它将可用资源和未决任务进行匹配,并决定分配给每个作业的最佳时机和资源量。现代数据中心已经引入了许多调度器来管理传统的工作负载。例如,HPC调度器(例如,Slurm[162]、OpenPBS[5])用于支持HPC应用和科学计算;云调度器(例如,Mesos[59]、Kubernetes[14]、Yarn[138])有助于大规模为大数据应用程序分配异构计算资源。
As a special case, DL workload scheduling in GPU datacenters shares many similar features as conventional parallel job scheduling. Figure 3 shows the general workflow of DL schedulers in a GPU datacenter. The scheduler works on top of the DN frameworks, and assigns appropriate resources to satisfy a variety of DL workloads. It receives different types of workloads from the users. By monitoring the usages of existing compute resources in the datacenter, it delivers an efficient scheduling solution for these workloads to optimize the predetermined scheduling objective, e.g, JCT, fairness. Then it allocates the jobs to a set of hardware resources for execution. The schedulers for model training and model inference share similar logic flows but have totally different scheduling objectives, workload types, and target users. So our survey will investigate them separately (Sec. 3
and 4), and consider the mix of them in Sec. 5.
作为一种特殊情况,GPU数据中心中的DL工作负载调度与传统的并行作业调度具有许多相似的特性。图3显示了GPU数据中心中DL调度器的一般工作流程。调度器在DN框架之上工作,并分配适当的资源来满足各种DL工作负载。它接收来自用户的不同类型的工作负载。通过监控数据中心中现有计算资源的使用情况,它为这些工作负载提供了一个高效的调度解决方案,以优化预定的调度目标,例如JCT、公平性。然后,它将作业分配给一组硬件资源以供执行。用于模型训练和模型推理的调度器具有相似的逻辑流,但具有完全不同的调度目标、工作负载类型和目标用户。因此,我们将分别对它们进行调查(第3节和第4节),并在第5节中考虑它们的组合。
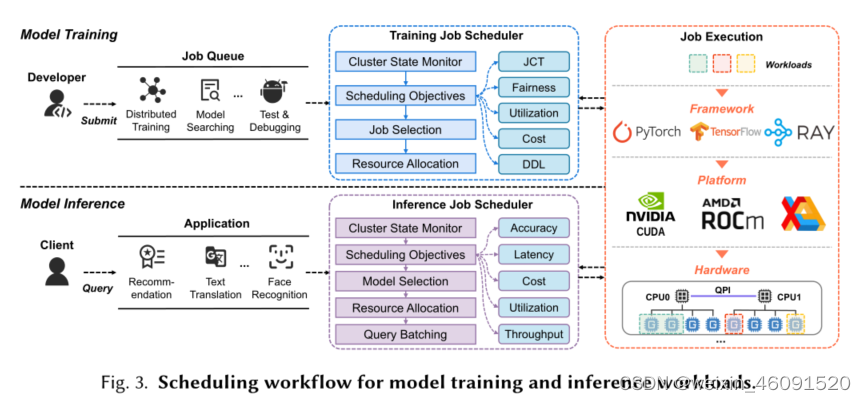
2.2.1 Scheduling Techniques 调度技术
Some techniques and mechanisms of conventional parallel job scheduling may also apply to DL workloads scheduling in GPU datacenters. For example, to manage computing resources more efficiently and provide guaranteed service for users, it is common to divide computing resources into separate partitions and set up different queues for different users or jobs with different characteristics [38, 46, 157]. Queues may also have different priorities and be equipped with different queuing policies, e.g., First-Come-First-Served and Shortest-Remaining- Time-First. Schedulers also pursue a better comprehension of affinities between workloads and resources to make wiser decisions. Therefore, mechanisms like performance modeling of workloads (e.g., online profiling [42] and performance prediction [46]) and trace analysis for characterizing the cluster-level workload distribution [62, 149] are widely adopted. Other traditional scheduling techniques (e.g., backfilling [46, 103]) and mechanisms (e.g., time-slicing [152], checkpointing [157], and migration [16, 152]) are also adopted for more flexible job arrangements and better resource utilization in DL workloads scheduling.
传统并行作业调度的一些技术和机制也可以应用于GPU数据中心中的DL工作负载调度。例如,为了更有效地管理计算资源并为用户提供有保障的服务,通常将计算资源划分为单独的分区,并为具有不同特征的不同用户或作业设置不同的队列[38,46157]。队列也可能具有不同的优先级,并配备有不同的排队策略,例如,先到先得和最短剩余时间优先。调度器还追求更好地理解工作负载和资源之间的相关性,以做出更明智的决策。因此,工作负载的性能建模(例如,在线评测[42]和性能预测[46])和用于表征集群级工作负载分布的跟踪分析[62149]等机制被广泛采用。其他传统的调度技术(例如,回填[46103])和机制(例如,时间切片[152]、检查点[157]和迁移[16152])也被采用,以在DL工作负载调度中实现更灵活的作业安排和更好的资源利用率。
However, due to the distinct characteristics of DL jobs (Sec. 2.1), simply adopting these techniques can cause a series of issues, e.g., serving job blocking, resource under-utilization, high operation cost. Below we summarize the challenges of scheduler designs caused by DL workload features.
然而,由于DL作业分布式的特点,简单地采用这些技术可能会导致一系列的问题,比如,服务作业阻塞、资源利用不足、运营成本高。下面我们总结了DL工作负载特性对调度器设计带来的挑战。
2.2.2 Challenge for Scheduling Training Jobs
As discussed in Sec. 2.1.1, DL training workloads have some unique requirements compared to HPC or cloud jobs, which raises some challenges for scheduling them. We discuss these challenges with a workload trace analysis from four private clusters (Venus, Earth, Saturn and Uranus) in SenseTime GPU datacenter Helios [62]. These clusters contain over 6000 GPUs and 1.5 million GPU jobs in total, spanning 6 months in 2020.
如第2.1.1节所述,与HPC或云作业相比,DL培训工作负载有一些独特的要求,这给调度它们带来了一些挑战。我们通过对SenseTime GPU数据中心Helios[62]中四个私人集群(金星、地球、土星和天王星)的工作负载跟踪分析来讨论这些挑战。这些集群总共包含6000多个GPU和150万个GPU作业,在2020年占据了6个月。
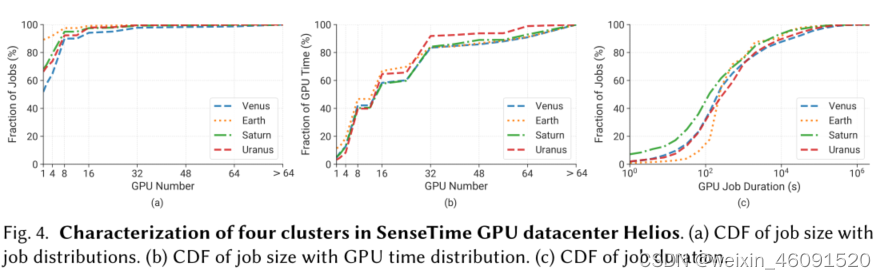
C1: Intensive resource consumption. The adoption of distributed training aims to reduce the training time yet prompts users to overclaim GPU resources for their jobs. Figures 4 (a) and (b) depict the distributions of requested GPUs pertaining to job and GPU resource occupation respectively. We observe that large-size jobs (≤8 GPUs) account for 10% of the entire trace, and they consume over half of computing resources. Such intensive resource requests can aggravate the job pending issue due to the shortage of GPU resources. If the scheduler prioritizes those large-scale jobs, the situation becomes worse as subsequent jobs have to compete for much less resources. Existing solutions often favor small jobs or treat large and small jobs equally. How to balance the trade-off between intensive and light-weight resource consumption remains a challenging problem.
C1:资源消耗密集。 分布式训练的采用旨在减少训练时间,但也会促使用户为自己的工作过度索取GPU资源。图4(a)和(b)分别描述了与作业和GPU资源占用有关的请求的GPU的分布。我们观察到,大型作业(≤8个GPU)占整个跟踪的10%,它们消耗了一半以上的计算资源。由于GPU资源短缺,这种密集的资源请求可能会加剧作业未决问题。如果调度器优先考虑那些大规模作业,情况会变得更糟,因为后续作业必须争夺更少的资源。现有的解决方案往往有利于小型工作,或者平等对待大型和小型工作。如何平衡大型和轻量级资源消耗之间的权衡仍然是一个具有挑战性的问题。
**C2: Unbalanced runtime distribution. **Recent trace analysis works [62, 71, 144, 149] presented the long-tail runtime distribution of DL training workloads in production GPU datacenters. Figure 4 © compares the GPU job duration distribution of each cluster. We observe it is common that job runtime varies from seconds to weeks even months among different production-level GPU clusters. The majority of workloads only finish within a short period of time, while the minority part consume many orders magnitudes of GPU time. Prioritizing short jobs is an effective way to reduce average job completion time but incurs low GPU utilization. More research efforts should be devoted to balance between short jobs and time-consuming jobs.
C2:运行时分布不平衡。最近的跟踪分析工作[62,71,144,149]介绍了工业GPU数据中心中DL训练工作负载的长尾运行时分布。图4(c)比较了每个集群的GPU作业持续时间分布。我们观察到,在不同的工业级GPU集群中,作业运行时间从几秒到几周甚至几个月不等,这是很常见的。大多数工作负载只在短时间内完成,而少数工作负载消耗许多数量级的GPU时间。优先考虑短作业是减少平均作业完成时间的有效方法,但GPU利用率较低。应该投入更多的研究工作来平衡短期工作和耗时工作。
C3: Heterogeneous resource affinity. The runtime speed of a DL training job is affected by a variety of hardware factors, among which GPU heterogeneity and network link heterogeneity are the most important ones. For the impact of GPUs, DL training can benefit from newer generations of GPUs. However, the marginal benefit brought by new GPU versions varies significantly (Figure
2 (f)). Also, the speedup ratio is unpredictable, which complicates the heterogeneous GPU resource allocation. For the impact of network links, the recently released high-end GPU interconnect including NVlink and NVswitch can significantly reduce the communication overhead across GPUs in the same sever. Along with PCI Express, InfiniBand, Ethernet and QPI, distributed training has several alternatives for cross-GPU communications. As these links differ considerably in bandwidths, and different jobs have different data sizes for exchange, it is non-trivial to allocate these network resources to the jobs to maximize the benefits and minimize the bandwidth contention.
C3:异构资源亲和性。 DL训练作业的运行速度受多种硬件因素的影响,其中GPU异构性和网络链路异构性是最重要的因素。对于GPU的影响,DL训练可以从新一代GPU中受益。然而,新GPU版本带来的边际效益差异很大(图2(f))。此外,加速比是不可预测的,这使异构GPU资源分配变得复杂。对于网络链路的影响,最近发布的包括NVlink和NVswitch在内的高端GPU互连可以显著降低同一服务器中GPU之间的通信开销。除了PCI Express、InfiniBand、以太网和QPI之外,分布式训练还有多种跨GPU通信的替代方案。由于这些链路的带宽差异很大,而且不同的作业有不同的数据大小可供交换,因此将这些网络资源分配给作业以最大化效益和最小化带宽争用是非常重要的。
**C4: Preemption overhead. ** DL frameworks usually provide functions to pause/resume the training jobs at any time for better fault-tolerance. The overhead of such processes primarily depends upon the job scale, which ranges from seconds to minutes. In this paper, the preemption overhead is considered as the addition of the costs of pausing and resuming the job. For time consuming jobs, the preemption overhead is relatively small with the benefit of higher scheduling flexibility. But for short jobs, the preemption overhead is non-negligible, and frequent preemption will delay their progress. Designing an appropriate preemptive mechanism requires meticulous considerations of both short and time-consuming jobs as well as their preemption overheads.
C4:抢占开销。 DL框架通常提供在任何时候暂停/恢复训练工作的功能,以获得更好的容错性。这些过程的开销主要取决于作业规模,从几秒钟到几分钟不等。在本文中,抢占开销被认为是暂停和恢复作业成本的增加。对于耗时的作业,抢占开销相对于更高的调度灵活性带来的收益来说较小。但对于短作业,抢占开销是不可忽略的,并且频繁抢占将推迟他们的进度。设计适当的先发制人机制需要一丝不苟考虑到短期和耗时的工作以及它们的抢占性管理费用。
2.2.3 调度推理任务的挑战
The online execution fashion and high latency requirement of inference workloads also give the following challenges for designing a scheduler.
推理工作负载的在线执行方式和高延迟要求也给设计调度器带来了以下挑战。
**C5: Low GPU utilization for each request. **Compared to training jobs, the inference service mainly involves small convolutional operations (e.g., 1x1, 3x3), and consumes small amounts of GPU resources. Besides, the peak performance of new GPUs are increasing rapidly [32]. This often leads to low GPU utilization for inference workloads [83, 173]. A common practice to improve the GPU utilization is to batch multiple inference requests and execute them at the same time [25].
**C5:每个请求的GPU利用率低。**与训练作业相比,推理服务主要涉及小的卷积运算(例如,1x1、3x3),并且消耗少量的GPU资源。此外,新GPU的峰值性能正在迅速提高[32]。这通常会导致推理工作负载的GPU利用率较低[83173]。提高GPU利用率的一种常见做法是批量处理多个推理请求并同时执行它们[25]。
**C6: Latency-accuracy-cost tradeoff. **The inference jobs are relatively malleable in terms of latency, accuracy and cost. To improve the resource utilization and cluster-wide job throughput, we can colocate multiple inference jobs or increase the batch size. However, this can increase the inference latency. To increase the accuracy, effective ways include model ensemble or augmentation evaluation, which can also incur latency delay [52]. The adoption of high-class hardware resources can accelerate the inference execution, but charges more for online services. Different users or inference jobs may have different demands towards latency, accuracy and cost. The scheduler needs to figure out a sweet spot for each job over an assortment of algorithms and hardware units.
C6:延迟精度成本权衡。 推理作业在延迟、准确性和成本方面具有相对的可塑性。为了提高资源利用率和集群范围内的作业吞吐量,我们可以将多个推理作业并置或增加批处理大小。然而,这会增加推理延迟。为了提高准确性,有效的方法包括模型集成或增强评估,这也可能导致延迟[52]。采用高级硬件资源可以加速推理执行,但在线服务的费用更高。不同的用户或推理作业可能对延迟、准确性和成本有不同的要求。调度器需要通过各种算法和硬件单元为每个作业找出一个最佳点。
C7: Bursty and fluctuating requests. As an online service, it is common for the inference application to receive bursty and fluctuating requests, which are unpredictable. This must be considered when determining the resources for the workload. How to guarantee the latency with the minimal operational cost even in extremely overloading scenarios raises a new challenge. In
practice, resources are often over-provisioned for inference workloads to guarantee their latency during the rush hours. Then an efficient scheduler needs to consider how to exploit the unused resources of these workloads when there are less queries.
**C7:突发性和波动性请求。**作为一种在线服务,推理应用程序通常会接收突发和波动的请求,这些请求是不可预测的。在确定工作负载的资源时,必须考虑到这一点。即使在极端过载的情况下,如何以最小的操作成本保证延迟也提出了新的挑战。在实践中,通常会为推理工作负载过度提供资源,以保证其在高峰时段的延迟。然后,一个高效的调度器需要考虑如何在查询较少的情况下利用这些工作负载的未使用资源。
2.3 Relevant Studies Not Included in This Survey 本次调查未包括的相关研究
This survey mainly focuses on the scheduling of DL training and inference workloads in GPU datacenters. Other relevant works beyond the scope of this paper will not be summarized in the following sections. Here we briefly discuss these directions. Readers who are interested in these works can refer to relevant surveys [44, 90, 109, 112, 120, 128, 139, 171].
本调查主要关注GPU数据中心中DL训练和推理工作负载的调度。本文范围之外的其他相关工作将不会在以下章节中进行总结。在这里,我们简要讨论一下这些方向。对这些作品感兴趣的读者可以参考相关调查[44、90、109、112、120、128、139、171]。
First, we do not consider the optimization solutions for individual training or inference jobs. Training job optimization mainly contains distributed training acceleration [17, 74, 175] and job placement optimization [84, 94, 161]. Inference job optimization techniques include workload characterization [15], pipeline execution [75], etc. Their objectives are to achieve high performance
for a single job instead of an entire datacenter. It is worth noting that scheduling hyperparameter optimization jobs will not be considered as single job optimization, because it involves a collection of training tasks (e.g., RubberBand [101], HyperSched [91]). They will be summarized in Sec. 5.
首先,我们不考虑单个训练或推理作业的优化解决方案。训练作业优化主要包括分布式训练加速[17,74175]和作业布局优化[84,94161]。推理作业优化技术包括工作负载表征[15]、流水线执行[75]等。它们的目标是为单个作业而不是整个数据中心实现高性能。值得注意的是,调度超参数优化作业不会被视为单作业优化,因为它涉及训练任务的集合(例如,RubberBand[101]、HyperSched[91])。它们将在第5节中进行总结。
Second, we consider the scheduling at the job level, and do not cover the scheduling approaches at the hardware resource level (e.g., network I/O, power). For instance, HIRE [13] proposed a novel in- network computing scheduling algorithm for datacenter switches. A number of works [49, 99, 145] utilized the DVFS mechanism on CPU and GPU chips to achieve cluster energy conservation. These works are not included in this survey.
其次,我们考虑了作业级别的调度,而没有涵盖硬件资源级别的调度方法(例如,网络I/O、电源)。例如,HIRE[13]提出了一种用于数据中心交换机的新型网络内计算调度算法。许多工作[4919145]利用CPU和GPU芯片上的DVFS机制来实现集群节能。这些工作不包括在本次调查中。
Third, we focus on the GPU datacenters where GPUs are the primary resources for the DL workloads. Those datacenters can also exploit other resources (e.g., CPU, FPGA, ASIC) as subsidiary. This can reflect the current status of mainstream DL infrastructures. Some scheduling systems mainly utilize the CPU [11, 53, 66, 156], FPGA [65, 72], or hybrid resources [73] where GPUs are not dominant. Some papers consider the DL services on mobile devices [110] or edge computing [123,177] other than datacenters. Those works are also out of the scope of this survey.
第三,我们关注GPU数据中心,其中GPU是DL工作负载的主要资源。这些数据中心还可以利用其他资源(例如CPU、FPGA、ASIC)作为辅助资源。这可以反映主流DL基础设施的现状。一些调度系统主要利用CPU[11,53,66156]、FPGA[65,72]或GPU不占主导地位的混合资源[73]。一些论文考虑了移动设备[110]或边缘计算[123,177],而不是数据中心。这些工作也不在本次调查的范围内。
Fourth, we target the scheduling of general DL training and inference workloads. Some works studied other types of DL jobs, e.g., data processing, model re-training, model validation. Some papers considered the optimization of specific DL applications based on their unique behaviors, including RNN-based service [41, 60], recommendation systems [54, 72, 73, 93] and video analytics [126, 174]. These works are not summarized in this paper. Besides, our aim is to enhance the system and workloads in terms of performance, efficiency and user experience. Other objectives like privacy protection [81, 96] is not considered either.
第四,我们针对一般DL训练和推理工作负载的调度。一些工作研究了其他类型的DL任务,例如数据处理、模型再训练、模型验证。一些论文考虑了基于特定DL应用程序的特定行为的优化,包括基于RNN的服务[41,60]、推荐系统[54,72,73,93]和视频分析[126174]。本文未对这些工作进行总结。此外,我们的目标是在性能、效率和用户体验方面增强系统和工作负载。其他目标,如隐私保护[81,96]也没有考虑在内。
3.SCHEDULING DL TRAINING WORKLOADS DL训练工作负载调度
DL training jobs consume a majority of compute resources in GPU datacenters. Therefore an effective and efficient scheduler for training workloads is of critical importance. Existing scheduling systems can be generally categorized from two dimensions: scheduling objective and resource consumption feature. Table 1 summarizes the past works for DL training scheduling. We detail them in the rest of this section.
DL训练作业消耗GPU数据中心中的大部分计算资源。因此,一个有效和高效的调度程序对训练工作量至关重要。现有的调度系统通常可以从两个维度进行分类:调度目标和资源消耗特征。表1总结了DL训练调度的过去工作。我们将在本节的其余部分详细介绍它们。
3.1 Scheduling Objectives
Different schedulers are designed to achieve different objectives, including efficiency, fairness and deadline guarantee. We first review past works from this perspective.
不同的调度器被设计来实现不同的目标,包括效率、公平性和最后期限保证。我们首先从这个角度来回顾过去的工作。
3.1.1 Efficiency.
Efficiency is a main objective to pursue when designing the workload schedulers. The GPU datacenter manager can consider different types of efficiency. We classify the efficiency- aware schedulers into three categories, as discussed below.
效率是设计工作负载调度器时要追求的主要目标。GPU数据中心管理器可以考虑不同类型的效率。我们将效率感知调度器分为三类,如下所述。
- Timing efficiency. This scheduling goal is to reduce the average queuing and execution time of training workloads in a datacenter. Some advanced strategies with special training configurations (e.g., sharing training, elastic training, heterogeneous training) can help improve the timing efficiency [64, 79, 85, 117, 151–154], which will be elaborated in Sec. 3.2. Here we mainly discuss the techniques over common training configurations that support gang scheduling, resource exclusive usage and preemptive operations.
1) 定时效率。此调度目标是减少数据中心中训练工作负载的平均排队和执行时间。一些具有特殊训练配置的高级策略(例如,共享训练、弹性训练、异构训练)可以帮助提高计时效率[64,79,851117151–154],这将在第3.2节中详细阐述。在这里,我们主要讨论支持集群调度、资源独占使用和抢先操作的常见训练配置上的技术。
One of the most common and effective ways for guaranteeing timing efficiency is to adopt some heuristic functions to determine the job scheduling priority . For instance, Tiresias [46] designs the Least Attained Service (LAS) algorithm to prioritize jobs based on their service, a metric defined as the multiplication of requested GPU resources and execution time. It devises the priority discretization to mitigate the frequent preemption issue , which is inspired by the classic Multi-Level Feedback Queue (MLFQ) algorithm [8, 22, 23]. These techniques enable Tiresias to beat the classical YARN-CS [138] significantly. E-LAS [132] improves over Tiresias by prioritizing jobs with the real-time epoch progress rate, which is computed as the proportion of the current training epoch over the total number of training epochs. With such improvement, E-LAS outperforms Tiresias in terms of average job timing efficiency. FfDL [70] is an open-sourced scheduler platform developed by IBM. It uses the operating lessons from the industry practice to guide the management of DL training workloads in the cloud.
保证定时效率的最常见和最有效的方法之一是采用一些启发式函数来确定作业调度优先级。例如,Tiresias[46]设计了最小可达服务(LAS)算法,以根据作业的服务对作业进行优先级排序,该度量定义为请求的GPU资源和执行时间的乘积。它设计了优先级离散化来缓解频繁抢占问题,这受到了经典的多级反馈队列(MLFQ)算法[8,22,23]的启发。这些技术使Tiresias能够击败经典的YARN-CS[138]。E-LAS[132]通过使用实时epoch进度率对作业进行优先级排序来改进Tiresias,该进度率计算为当前训练epoch占训练epoch总数的比例。有了这样的改进,E-LAS在平均工作时间效率方面优于Tiresias。FfDL[70]是由IBM开发的一个开源调度器平台。它使用行业实践中的操作经验教训来指导云中DL训练工作负载的管理。
An alternative strategy is to use machine learning techniques for job scheduling. [95] is a scheduler based on reinforcement learning (RL). It utilizes a Q-network which takes the job state and GPU datacenter state as input, and outputs the optimal job to be scheduled. MLFS [141] also leverages RL to determine the job priority and resource allocation. The RL model takes as input the job time information, resource demand, and accuracy requirements. It can effectively improve the average latency of a mix of data-parallel and model-parallel training jobs. Helios [62] characterizes the production training jobs from a shared GPU datacenter in SenseTime, and then adopts a variety of machine learning algorithms to predict the job priority from the history job information. The prediction result suffices to minimize the cluster-wide job latency. JPAS [183] is a scheduler based on the accuracy curve fitting technique to expedite the feedback-driven exploration of general training workloads. The feedback-driven exploration readily expects the scheduler to allocate more resources for more accurate models. JPAS leverages the accuracy curve fitting to predict the potential maximal accuracy improvement of each job, and then prioritize the jobs in a time interval. With this technique, JPAS can facilitate the early-stage progress of the training workloads and satisfy the needs for the feedback-driven exploration.
另一种策略是使用机器学习技术进行作业调度。[95]是一种基于强化学习(RL)的调度器。它利用Q-network,以作业状态和GPU数据中心状态为输入,并输出要调度的最佳作业。MLFS[141]还利用RL来确定作业优先级和资源分配。RL模型将工作时间信息、资源需求和准确性要求作为输入。它可以有效地提高数据并行和模型并行训练作业的平均延迟。Helios[62]在SenseTime中对来自共享GPU数据中心的生产训练作业进行表征,然后采用各种机器学习算法从历史作业信息中预测作业优先级。预测结果足以最小化集群范围内的作业延迟。JPAS[183]是一种基于精度曲线拟合技术的调度器,用于加快一般训练工作的反馈驱动探索。反馈驱动的探索很容易期望调度器为更准确的模型分配更多的资源。JPAS利用精度曲线拟合来预测每个作业潜在的最大精度改进,然后在一个时间间隔内对作业进行优先级排序。有了这项技术,JPAS可以促进训练工作的早期进展,并满足反馈驱动探索的需求。
The timing efficiency of DL training jobs is highly dependent on the job placement C3, where different placement policies can lead to different communication overheads. Users prefer the strict placement locality to maintain the DL training speed T2. Amaral et al. [7] found that packing jobs on the same CPU socket could bring up to 1.3× speedup compared to spreading jobs across different sockets. Then they designed the Topology-Aware scheduler, which uses a profiler to measure the placement sensitivity of each job, and thus performs a best-effort approach to schedule locality-sensitive jobs in a packing manner. Similarly, Tiresias [46] and E-LAS [132] also adopt the profiling strategy to identify the optimal job placement solutions. SMD [167] is a scheduler for parameter-server (PS) training jobs, which allows multiple jobs to contend the communication bandwidth. It models the scheduling problem as a non-convex integer non-linear program with the bin-packing constraints, and then develops an 휖-approximation algorithm called sum-of-ratio multi-dimensional-knapsack decomposition to solve it. The effectiveness of the SMD scheduler is validated both theoretically and empirically. Philly [71] investigates a production workload trace from Microsoft and conducts a thorough analysis about the impact of gang scheduling and locality constraints on the queuing delay and job runtime. Motivated by this, it proposes to relax locality constraints to improve the job timing efficiency.
DL训练作业的定时效率高度依赖于作业布置C3,因为不同的布置策略可能导致不同的通信开销。用户更喜欢紧密的放置位置以保持DL训练速度T2。Amaral等人[7]发现,与在不同socket中分配作业相比,在同一CPUsocket上打包作业可以带来1.3倍的加速。然后,他们设计了拓扑感知调度器,该调度器使用探查器来测量每个作业的位置敏感度,从而以打包的方式执行对位置敏感作业的最佳调度方法。同样,Tiresias[46]和E-LAS[132]也采用了分析策略来确定最佳的作业放置解决方案。SMD[167]是一种用于参数服务器(PS)训练作业的调度器,它允许多个作业竞争通信带宽。它将调度问题建模为具有装箱约束的非凸整数非线性规划,然后开发了一个采用比例和多维背包分解的近似算法进行求解,从理论和实验两方面验证了SMD调度器的有效性。Philly[71]调查了微软的生产工作负载跟踪,并对集群调度和位置约束对排队延迟和作业运行时间的影响进行了深入分析。基于此,提出放宽局部约束,提高作业时间效率。
Sometimes the scheduler can satisfy the GPU capacity request but fail to meet the placement locality. This will lead to the cluster fragmentation issue, which is often caused by the scattered GPU resource allocation. HiveD [181] emphasizes that sharing the GPU datacenter without the consideration of cluster fragmentation will cause significant job queuing delay. Therefore it develops
a buddy cell allocation mechanism to ensure sharing safety. HiveD can be easily incorporated with Tiresias [46] to reduce the queuing delay and further improve the job latency. [95] addresses the cluster fragmentation problem with an RL model, which is able to satisfy the locality constraint as much as possible. SPIN [57] observes that delay scheduling [170] can bring reward to the GPU datacenter in the long term for satisfying the placement locality in the near future. It requires the job runtime information to determine the delay scheduling policy. SPIN proposes a rounding-based randomized approximation method to achieve this goal, which has strong robustness even with inaccurate job runtime estimation.
有时调度器可以满足GPU容量请求,但不能满足放置位置。这将导致集群碎片化问题,这通常是由分散的GPU资源分配引起。HiveD[181]强调,在不考虑集群碎片的情况下共享GPU数据中心将导致显著的作业排队延迟。因此,它开发了一种分区分配机制来确保共享安全。HiveD可以很容易地与Tiresias[46]结合,以减少排队延迟并进一步减少作业延迟。[95]用RL模型解决了集群碎片化问题,该模型能够尽可能地满足局部性约束。SPIN[57]观察到,从长远来看,延迟调度[170]可以为GPU数据中心带来回报,因为它在不久的将来满足放置位置。它需要作业运行时信息来确定延迟调度策略。SPIN提出了一种基于舍入的随机逼近方法来实现这一目标,即使在作业运行时间估计不准确的情况下,该方法也具有较强的鲁棒性。
- Cost efficiency. This refers to the reduction of power consumption or financial cost for renting cloud services. This is another significant objective for training workload scheduling.
**2) 成本效益。**这是指降低租用云服务的功耗或财务成本。这是训练工作量调度的另一个重要目标。
Existing GPU datacenters have considerable power waste as not all the GPUs are actively used all the time, while the datacenter managers prefer to keep all the devices on. To reduce the energy cost, ANDREAS [39] considers a scenario where the execution of each job can be postponed within a certain period. Then it judiciously schedules jobs at appropriate moments to keep all the GPUs busy in the datacenter. It formulates the power consumption as a Mixed Integer Non-Linear Programming problem, and proposes an effective greedy heuristic algorithm to achieve a significant cost reduction. Different from ANDREAS, the Cluster Saving Service (CES) in Helios [62] has no assumption about postponing the execution of DL training jobs. It leverages a prediction model to estimate the future resource utilization from the history logs. Then the scheduler can decide how many GPU nodes should be turned on/off. CES can save the electricity by up to 1.65 million kilowatt-hours per year in four production clusters from SenseTime. Additionally, recent energy optimization frameworks such as GPOEO [140] can significantly save the power consumption of training workloads. Although they are not tailored for GPU datacenters, they can be easily transplanted into the GPU datacenter with a customized scheduler to orchestrate between datacenters and jobs.
现有的GPU数据中心存在相当大的功率浪费,因为并非所有GPU都一直在使用,而数据中心管理者更喜欢保持所有设备都处于开启状态。为了降低能源成本,ANDREAS[39]考虑了一种情况,即每个作业的执行可以在一定时间内推迟。然后,它明智地在适当的时刻安排作业,以保持数据中心中所有GPU的繁忙。它将功耗公式化为一个混合整数非线性规划问题,并提出了一种有效的贪婪启发式算法来实现显著的成本降低。与ANDREAS不同,Helios[62]中的集群保存服务(CES)没有推迟DL训练作业执行的假设。它利用预测模型从历史日志中估计未来的资源利用率。然后调度器可以决定应该打开/关闭多少GPU节点。在SenseTime的四个生产集群中,CES每年可节省高达165万千瓦时的电力。此外,最近的能量优化框架,如GPOEO[140],可以显著节省训练工作负载的功耗。尽管它们不是为GPU数据中心量身定制的,但它们可以通过定制的调度器轻松移植到GPU数据中心,以在数据中心和作业之间进行协调。
Cloud GPU resources are billed based on the amount and duration of usage. Training a model can be very time-consuming and resource-intensive C1. As such, the cost of a training workload could be considerably expensive. It is critical to reduce such financial cost to produce the model with the same quality. Particularly, PS training is a common method for distributed data-parallel model training in the cloud. Cynthia [182] is a scheduler to guarantee the cost-effectiveness of cloud resource provision for PS training. It introduces an analytical performance model to characterize the relationship between throughput and resource provision.
云GPU资源根据使用量和持续时间计费。训练一个模型可能非常耗时且资源密集C1。因此,培训工作量的成本可能相当昂贵。降低这样的财务成本以生产具有相同质量的模型是至关重要的。特别地,PS训练是在云中进行分布式数据并行模型训练的常用方法。Cynthia[182]是一个调度器,用于保证为PS训练提供云资源的成本效益。它引入了一个分析性能模型来表征吞吐量和资源供应之间的关系。
Through this performance model, this scheduler can identify an optimal resource type and PS configurations to maintain the training throughput while minimizing the monetary cost. Analogously, [134] is a scheduler, which recommends cost-effective and high-performing cloud resource configurations for PS training jobs.It selects the instances with the largest network bandwidth within the budget for the parameter server in order to avoid the communication bottleneck. It also proposes a heuristic method named Scala-Opt to decide the work instances which can guarantee the job throughput while maximizing the cost savings. Jahani [67] treats the compute node with different numbers of GPUs as different virtual machines (VMs). The renting cost and job throughput vary with different VM types. Then it models the scheduling process as a Mixed Integer Linear Programming (MILP) problem, and reduces the renting cost in a global manner while maintaining the job latency. MLCloudPrice [105] makes a quantitative analysis on the price difference among different GPU specifications and dynamic prices of the public cloud. It moves the workloads between spot and on-demand instances, which opportunistically utilizes the low-pricing spot instance to push forward the training progress
通过该性能模型,该调度器可以确定最佳的资源类型和PS配置,以保持训练吞吐量,同时最小化货币成本。类似地,[134]是一个调度器,它为PS训练作业推荐经济高效的云资源配置。它为参数服务器选择预算内网络带宽最大的实例,以避免通信瓶颈。它还提出了一种名为Scala-Opt的启发式方法来确定工作实例,该方法可以保证作业吞吐量,同时最大限度地节省成本。Jahani[67]将具有不同数量GPU的计算节点视为不同的虚拟机(VM)。租用成本和作业吞吐量因不同的VM类型而异。然后将调度过程建模为混合整数线性规划(MILP)问题,并在保持作业延迟的同时,全局降低租赁成本。MLCloudPrice[105]对公共云不同GPU规格和动态价格之间的价格差异进行了定量分析。它在现场实例和按需实例之间移动工作负载,从而机会主义地利用低价现场实例来推进训练进度。
3.1.2 Fairness.
Fairness indicates how fairly the compute resources are allocated among different entities, including user groups (i.e., tenants) and workloads. Fairness schedulers aim to guarantee that each entity can achieve better performance with the resource sharing mechanism than exclusively using the same portion of resources. For conventional workloads, the design of fairness schedulers follows some typical fairness principles, such as sharing incentive, strategy-proofness, envy-freeness and pareto efficiency [43]. It is more challenging to maintain fairness for DL training workloads for two reasons: (1) A GPU is an indivisible resource in common settings (gang scheduling) T6; (2) DL training exhibits resource heterogeneity preference T1 C3. Below we discuss the new works that can address these two challenges for fairness scheduling of training workloads.
公平性表示计算资源在不同实体之间分配的公平程度,包括用户组(即租户)和工作负载。公平调度器旨在保证每个实体通过资源共享机制可以获得比专门使用相同部分资源更好的性能。对于传统的工作负载,公平调度器的设计遵循一些典型的公平原则,如共享激励、策略验证、无嫉妒和帕累托效率[43]。由于两个原因,维持DL训练工作负载的公平性更具挑战性:(1)GPU在公共设置(集群调度)T6中是不可分割的资源;(2) DL训练表现出资源异质性偏好T1 C3。下面,我们将讨论可以解决训练工作负载公平调度这两个挑战的新工作。
1) Homogeneous GPU resources. A datacenter with only one generation of GPU devices can be considered as a homogeneous GPU environment. The scheduler in this system achieves fairness sharing of indivisible GPU resources from the timing dimension. For instance, Themis [97] maintains the job-level fairness by introducing a new metric called finish-time fairness. This metric inspires the scheduler to allocate more resources to the jobs whose attained service is less than the deserved amount. Moreover, in existing fairness schedulers (e.g., DRF [43]), the placement preferences of DL training workloads can result in severe fairness sharing loss. To address this problem, Themis builds a two-level scheduling architecture for biding resource allocation among jobs and uses the game theory to guarantee the performance. Astraea [157] concentrates on the fairness across workloads and tenants. It introduces the Long-Term GPU-time Fairness (LTGF) metric to measure the sharing benefit of each tenant and job, and proposes a two-level max-min scheduling discipline to enforce job-level and tenant-level LTGF in a shared GPU datacenter.
1) 同质GPU资源。 只有一代GPU设备的数据中心可以被视为同质GPU环境。该系统中的调度器从时序维度实现了不可分割GPU资源的公平共享。例如,Themis[97]通过引入一种称为完成时间公平性的新指标来保持工作级别的公平性。该度量激励调度器将更多的资源分配给所获得的服务少于应得数量的作业。此外,在现有的公平调度器(例如,DRF[43])中,DL训练工作负载的放置偏好可能导致严重的公平共享损失。为了解决这一问题,Themis建立了一个两级调度架构,用于在作业之间竞标资源分配,并使用博弈论来保证性能。Astrea[157]专注于工作负载和租户之间的公平性。它引入了长期GPU时间公平(LTGF)度量来衡量每个租户和作业的共享效益,并提出了一种两级最大-最小调度规则来在共享GPU数据中心中实施作业级和租户级LTGF。
**2) Heterogeneous compute resources. ** It is relatively easy to maintain fairness over one type of GPUs. However, the existence of multiple generations of GPUs and other compute resources (e.g., CPUs, network links) can also exacerbate the fairness of workloads or user groups T1 C3. A couple of works have introduced solutions to achieve fairness in the heterogeneous environment.
2) 异构计算资源。 在一种类型的GPU上保持公平性相对容易。然而,多代GPU和其他计算资源(例如,CPU、网络链路)的存在也会加剧工作负载或用户组T1 C3的公平性。一些工作介绍了在异构环境中实现公平的解决方案。
To achieve the fairness over GPUs and other compute resources, Allox [80] is a fairness scheduler, which assumes that both GPUs and CPUs are interchangeable resources, and takes into account the affinity of workloads towards different compute resources. It models the resource allocation as a min-cost bipartite matching problem with a theoretically optimal property. Then it proposes a greedy heuristic solution to solve this problem in an effective and scalable way. Dorm [133] is another fairness scheduler for the fair sharing of GPUs, CPUs and memory resources. It assumes that GPUs, CPUs and memory are complementary resources and the capacity of each one can influence the training job throughput. It dynamically partitions different types of compute resources for each DL training job. It formulates the resource allocation as an MILP problem with the resource utilization fairness as the optimization objective. The scheduling decision in each round is made by calling the MILP solver to optimize the utilization fairness.
为了实现GPU和其他计算资源的公平性,Allox[80]是一个公平调度器,它假设GPU和CPU都是可互换的资源,并考虑到工作负载对不同计算资源的亲和力。它将资源分配建模为具有理论最优性质的最小代价二分匹配问题。然后提出了一种贪婪启发式解决方案,以一种有效且可扩展的方式来解决这个问题。Dorm[133]是用于公平共享GPU、CPU和内存资源的另一个公平调度器。它假设GPU、CPU和内存是互补的资源,每一个的容量都会影响训练作业的吞吐量。它为每个DL训练作业动态地划分不同类型的计算资源。它将资源分配公式化为MILP问题,以资源利用公平性为优化目标。每轮的调度决策是通过调用MILP求解器来优化选择公平性。
It is also challenging to achieve fairness over different generations of GPUs. Datacenter users prefer to request the most powerful GPU resources for their training jobs. However, many jobs can not saturate the peak performance of these high-end GPUs. Besides, different DL training jobs have different sensitivities of runtime speed to the compute capability of GPUs.[16] is an early fairness scheduler dedicated for the heterogeneous GPU resource environment. It targets the inter-user fairness in the GPU heterogeneity. To maintain such fairness while maximizing the cluster-wide job efficiency,[16] allows users to transparently trade heterogeneous GPU-time by a couple of techniques including profiling and automatic trade pricing. Gavel [106] is another heterogeneity-aware fairness scheduler. It profiles the performance heterogeneity between different types of GPUs and DL model architectures. A round-based scheduling technique is adopted to improve the scheduling flexibility and ensure timely GPU-time re-allocation. This scheduler can satisfy different types of fairness defnitions, e.g., max-min fairness, makespan minimization, finish-time fairness minimization. However, it is prohibitive to scale up Gavel to a large datacenter due to the time-consuming mathematical solving process. To this end, POP [104] proposes to partition a large datacenter into several smaller ones. Then the original complex optimization formulation is decomposed into multiple smaller problems and can be solved in parallel. It provides a theoretical proof and several empirical evidences to demonstrate the effectiveness of this optimization technique.
实现不同代GPU的公平性也是一项挑战。数据中心用户更喜欢为他们的训练工作请求最强大的GPU资源。然而,许多工作并不能使这些高端GPU的峰值性能饱和。此外,不同的DL训练作业对GPU的计算能力具有不同的运行时速度敏感性。 [16] 是专用于异构GPU资源环境的早期公平调度器。它针对GPU异构中的用户间公平性。为了在最大化集群范围内的作业效率的同时保持这种公平性,[16]允许用户通过包括分析和自动交易定价在内的多种技术透明地交易异构GPU时间。Gavel[106]是另一个异构感知公平调度器。它描述了不同类型的GPU和DL模型体系结构之间的性能异构性。采用基于轮的调度技术,提高了调度的灵活性,保证了GPU时间的及时重新分配。该调度器可以满足不同类型的公平性定义,例如最大-最小公平性、完工时间最小化公平性。然而,由于耗时的数学求解过程,将Gavel扩展到大型数据中心是令人望而却步的。为此,POP[104]提出将一个大型数据中心划分为几个较小的数据中心。然后将原来的复杂优化公式分解为多个较小的问题,并可以并行求解。它提供了一个理论证明和几个经验证据来证明该优化技术的有效性。
3.1.3 Deadline Guarantee. 最后期限保证
Different from the efficiency goal which aims to complete the job as soon as possible, this objective is to ensure the job can be done before the specified deadline. It is relatively less studied due to the lack of comprehensive analysis about the deadline requirement in DL workloads. An early deadline-aware scheduler for DL training workloads is GENIE [20]. It develops a performance model to predict the job throughput on different resource placement policies.The performance model only requires a small number of training iterations to profile without any significant degradation of job execution T3. With this performance model, GENIE can identify the best placement policy for each job to satisfy the corresponding deadline requirement. However, GENIE [20] does not investigate the deadline requirement from users and cannot support a mixed workload of deadline and best-effort jobs. In [42], a user survey is conducted to uncover users’ latent needs about the deadline guarantee, and comprehensively discuss the deadline requirement from GPU datacenter users. Motivated by this survey, it introduces Chronus, a scheduler to improve the deadline guarantee for Service-Level-Objective (SLO) jobs and latency of best-effort jobs at the same time. It formulates the deadline-guarantee scheduling task as an MILP problem with the resource and time constraints. The MILP solver can make effective scheduling decisions for a collection of jobs. Moreover, in consideration of the placement sensitivity of different training jobs, it proposes round-up and local-search techniques to make placement decisions. These designs successfully enable Chronus to outperform existing deadline schedulers in reducing deadline miss rates and improving the latency of best effort jobs.
与旨在尽快完成工作的效率目标不同,该目标是确保工作能够在规定的截止日期前完成。由于缺乏对DL工作负载中的截止日期要求的全面分析,因此对它的研究相对较少。用于DL训练工作负载的早期截止日期感知调度器是GENIE[20]。它开发了一个性能模型来预测不同资源放置策略下的作业吞吐量。性能模型只需要少量的训练迭代来评测,而不会显著降低作业执行T3。有了这个性能模型,GENIE可以为每个工作确定最佳的安置策略,以满足相应的截止日期要求。然而,GENIE[20]没有调查用户的截止日期要求,也不能支持截止日期和尽力而为工作的混合负载。在[42]中,进行了一项用户调查,以揭示用户对截止日期保证的潜在需求,并全面讨论GPU数据中心用户的截止日期要求。受此调查的启发,它引入了Chronous,这是一款调度器,用于同时改进服务级别目标(SLO)作业的截止日期保证和尽力而为作业的延迟。它将保证工期的调度任务定义为具有资源和时间约束的MILP问题。MILP求解器可以为一组作业做出有效的调度决策。此外,考虑到不同培训工作的安置敏感性,提出了四舍五入和局部搜索技术来进行安置决策。这些设计成功地使Chronous在降低截止日期未命中率和提高尽力而为作业的延迟方面优于现有的截止日期调度器。
3.2 Resource Consumption Feature
In addition to the scheduling objective, another orthogonal view to categorize training workloads is their resource consumption features. We discuss prior works based on whether they adopt heterogeneous resources, GPU sharing and elastic training.
除了调度目标之外,对训练工作负载进行分类的另一个角度是它们的资源消耗特征。我们讨论了先前的工作,基于它们是否采用异构资源、GPU共享和弹性训练。
3.2.1 Heterogeneous Resources.
Most schedulers focus on the allocation of GPU resources, as they dominate the DL training. However, the consumption of CPUs and memory can also affect the training performance C3. Synergy [102] observes that different DL training jobs exhibit different levels of sensitivity to the CPU and memory allocation. An optimal allocation can improve the overall cluster utilization and efficiency. Therefore, it introduces optimistic profiling to empirically profile the job throughput for various CPU allocations and analytically estimate all the combinations of CPUs and memory along with the respective storage bandwidth requirement. Based on the profiling results, it performs round-based scheduling and greedily packs runnable jobs along multiple resource dimensions with the objective of minimizing the fragmentation in each round T1. CODA [180] observes that CPU jobs colocating within the same compute node can interfere with the training jobs due to the CPU resource contention. It then designs three components to optimize system-wide performance: an adaptive CPU allocator identifies the optimal CPU cores for each DL training job; a real-time contention eliminator monitors and throttles the memory bandwidth of each CPU job to reduce its interference with the GPU training jobs; a multi-array job scheduler allows CPU jobs to preempt the CPU cores reserved by the GPU jobs accordingly, and vice versa. Experimental results demonstrate CODA can efficiently improve the GPU utilization without sacrificing the performance of CPU jobs.
大多数调度器关注GPU资源的分配,因为它们主导DL训练。然而,CPU和内存的消耗也会影响训练性能C3。Synergy[102]观察到,不同的DL训练作业对CPU和内存分配表现出不同程度的敏感性。优化分配可以提高集群的整体利用率和效率。因此,它引入了乐观分析来凭经验分析各种CPU分配的作业吞吐量,并分析估计CPU和内存的所有组合以及相应的存储带宽需求。基于分析结果,它执行基于轮的调度,并沿着多个资源维度贪婪地打包可运行的作业,目的是最小化每轮T1中的碎片。CODA[180]观察到,由于CPU资源争用,位于同一计算节点内的CPU作业可能会干扰训练作业。然后,它设计了三个组件来优化系统范围的性能:自适应CPU分配器为每个DL训练作业识别最佳CPU内核;实时争用消除器监视并调节每个CPU作业的存储器带宽,以减少其对GPU训练作业的干扰;多阵列作业调度器允许CPU作业相应地抢占由GPU作业保留的CPU核,反之亦然。实验结果表明,CODA可以在不牺牲CPU作业性能的情况下有效地提高GPU的利用率。
Beyond the CPU and memory resources, network bandwidth is another bottleneck for efficient DL training. Ada-SRSF [146] is a two-stage framework for mitigating the communication contention among DLT jobs. In the job scheduling stage, it is combined with the classical SRSF algorithm to relax the contention of two jobs if it can reduce the job completion time. In the job placement stage, it strives to balance the resource utilization and communication overhead. Liquid [47] proposes a cluster network-efficient scheduling solution to achieve better placement for PS-based distributed workloads. Specifically, it adopts a random forest model to predict job resource requirements and then uses the best-fit algorithm and grouping genetic algorithm to optimize the execution performance of DL jobs. Parrot [88] is a framework to manage network bandwidth contention among training jobs using the PS architecture. The communication scheme in a PS workload exhibits a coflow chain dependency where the event of parameter-pull happens after the event of parameter-push. Parrot tries to assign the bandwidth of each physical link to coflows while satisfying the dependency constraints in order to minimize the JCT. It adopts a least per-coflow attained service policy to prioritize jobs. Then it uses a linear program (LP) solution to derive a weighted bandwidth scaling strategy to minimize the time cost in the communication stage.
除了CPU和内存资源之外,网络带宽是高效DL训练的另一个瓶颈。Ada SRSF[146]是一个两阶段框架,用于缓解DLT作业之间的通信争用。在作业调度阶段,如果可以减少作业完成时间,则将其与经典的SRSF算法相结合,以缓解两个作业的争用。在任务放置阶段,它努力平衡资源利用率和通信开销。Liquid[47]提出了一种集群网络高效调度解决方案,以实现基于PS的分布式工作负载的更好布局。具体来说,它采用随机森林模型来预测作业资源需求,然后使用最佳拟合算法和分组遗传算法来优化DL作业的执行性能。Parrot[88]是一个使用PS架构管理训练作业之间网络带宽争用的框架。PS工作负载中的通信方案表现出共流链依赖性,其中参数拉取事件发生在参数推送事件之后。Parrot试图将每个物理链路的带宽分配给余流,同时满足依赖性约束,以最小化JCT。它采用了最低成本的服务政策来优先考虑工作。然后,它使用线性规划(LP)解决方案来推导加权带宽缩放策略,以最小化通信阶段的时间成本。
3.2.2 GPU Sharing.
With the increased compute capability and memory capacity of GPUs, the conventional placement approach which makes each DL job exclusively use the GPU can lead to severe resource underutilization. It is now more promising to perform GPU sharing to fully exploit GPU resources and improve the system throughput T5. In this context, utilization is more inclined to the usage of every single GPU instead of the occupied GPU quantity at the datacenter scale.
随着GPU的计算能力和内存容量的增加,使每个DL作业专门使用GPU的传统放置方法可能导致严重的资源利用不足。现在更有希望执行GPU共享以充分利用GPU资源并提高系统吞吐量T5。在这种情况下,利用率更倾向于每个GPU的使用,而不是数据中心规模的占用GPU数量。
Some works profile and revoke unsuitable jobs to achieve efficient GPU sharing. Salus [168] focuses on fine-grained GPU sharing with two primitives: fast job switching enables efficient time sharing and rapid preemption for active DL jobs on a GPU; memory sharing addresses the memory management issues to ensure high utilization by packing more small DL jobs on the same device.Gandiva [152] designs a packing mechanism to pack multiple jobs on one GPU under the constraints of GPU memory and job performance. It utilizes a profiling mechanism to monitor and unpack jobs that could affect jobs’ performance. Jigsaw [79] is designed upon a novel distributed training scheme named Structured Partial Backpropagation (SPB). SPB allows each worker not to perform the entire backward pass in the distributed training. This can save lots of compute resources, and enable efficient time- and space-multiplexing across jobs in a single GPU. Although SPB can reduce the cluster-wide JCT, it might lead to accuracy loss to some extent. Recently, Antman [153] is introduced, which co-designs the infrastructure between the cluster scheduler and DL framework engine to efficiently manage GPU resources in a fine-grained manner. It supports the co-execution of multiple jobs on a GPU device, and thus largely improves the overall compute resource utilization. Ali-MLaaS [149] provides a comprehensive analysis of large-scale workload traces in Alibaba, and discloses the benefit of GPU sharing in production GPU datacenters.
一些工作配置和撤销不合适的作业,以实现高效的GPU共享。Salus[168]专注于具有两个基元的细粒度GPU共享:快速作业切换实现GPU上活跃的DL作业的高效时间共享和快速抢占;内存共享解决了内存管理问题,通过在同一设备上打包更多的小DL作业来确保高利用率。Gandiva[152]设计了一种打包机制,在GPU内存和作业性能的约束下,将多个作业打包在一个GPU上。它利用一种分析机制来监视和解包可能影响作业性能的作业。Jigsaw[79]是基于一种新的分布式训练方案设计的,该方案名为结构化部分反向传播(SPB)。SPB允许每个作业在分布式训练中不执行整个后向传播。这可以节省大量计算资源,并在单个GPU中实现跨作业的高效时间和空间复用。尽管SPB可以减少集群范围内的JCT,它可能会在一定程度上导致准确性损失。最近,Antman[153]被引入,它设计了集群调度器和DL框架引擎之间的基础设施,以细粒度的方式有效地管理GPU资源。它支持在GPU设备上协同执行多个作业,从而大大提高了整体计算资源利用率。Ali MLaaS[149]对阿里巴巴的大规模工作负载痕迹进行了全面分析,并揭示了GPU共享在生产GPU数据中心的好处。
Alternatively, some works use data-driven approaches to make the GPU sharing decision. Horus [159, 160] designs a prediction-based interference-aware mechanism that can be integrated with existing DL training scheduling frameworks. The prediction engine in Horus is in charge of estimating the GPU usage of each DL job by accessing its graph and dry running the model upon the job submission. Based on the prediction results, Horus allocates GPU resources to DL jobs via de-prioritizing co-location placement decisions that would result in JCT slowdown from the severe interference and communication delays. Co-scheML [76] also measures some metrics for each DL job and uses a random forest model to predict the interference. Then the scheduler makes the decision with the aim of fully utilizing the cluster resources. Analogously, Liquid [47] also supports fine-grained GPU sharing for further resource utilization improvement using a random forest model. Harmony [9] applies an RL model to make placement decisions for minimizing the interference and maximizing the throughput for bin packing DL workloads in a GPU datacenter. It contains a reward function for the prediction module and RL placement decision-making module.This reward function aims to maximize the normalized training speed across all the concurrent jobs in a fixed scheduling interval. The training speed estimation of bin-packing jobs can not be directly obtained, and it depends upon a neural network model via supervised learning from historical logs.To stabilize and accelerate RL model training, Harmony adopts several techniques including actorcritic, job-aware action space, and experience replay. Putting them together, Harmony outperforms significantly over heuristic baselines.
或者,一些作品使用数据驱动的方法来做出GPU共享决策。Horus[159160]设计了一种基于预测的干扰感知机制,该机制可以与现有的DL训练调度框架集成。Horus中的预测引擎负责通过访问每个DL作业的网络和在提交时试运行模型来估计其GPU使用情况。基于预测结果,Horus通过取消同位置放置决策的优先级来将GPU资源分配给DL作业,这将导致严重干扰和通信延迟,从而导致JCT减慢。Co-scheML[76]还测量了每个DL作业的一些度量,并使用随机森林模型来预测干扰。然后调度器以充分利用集群资源为目标进行决策。类似地,Liquid[47]还支持细粒度GPU共享,以使用随机森林模型进一步提高资源利用率。Harmony[9]应用RL模型来做出布局决策,以最大限度地减少GPU数据中心中DL工作负载的干扰并最大限度地提高吞吐量。它包含预测模块和RL布局决策模块的奖励函数。该奖励函数旨在在固定的调度间隔内最大化所有并发作业的归一化训练速度。装箱作业的训练速度估计不能直接获得,它依赖于通过从历史日志中监督学习的神经网络模型。为了稳定和加速RL模型训练,Harmony采用了几种技术,包括演员评论家、工作感知动作空间和经验回放。将它们放在一起,Harmony显著优于基线。
3.2.3 Elastic Training.
In order to maximize the GPU utilization and improve the training efficiency, many novel schedulers support elastic training, which dynamically adjusts the parallelism and resource allocation of workloads to achieve the objectives C1 T6.
为了最大限度地提高GPU利用率和训练效率,许多新颖的调度器支持弹性训练,该训练动态调整工作负载的并行性和资源分配,以实现目标C1 T6。
Gandiva [152] designs a Grow-Shrink mechanism which uses the profiling information to estimate each job’s progress rate and then allocates GPUs accordingly. Optimus [115] estimates the loss reduction rate on any placement policies based on a performance model. then it designs a greedy resource allocation scheme to prioritize the maximum marginal loss reduction. This greedy policy successfully maximizes the cluster-wide training throughput. Elan [154] designs several mechanisms to achieve efficient elastic training: hybrid scaling can better trade-off the training efficiency and model performance; concurrent IO-free replication leverages RDMA to reduce the numbers of IO and CPU-GPU memory copy operations; asynchronous coordination avoids the high overhead of start and initialization during re-adjustments. With the integration of the FIFO and backfill scheduling algorithms, Elan successfully improves the cluster resource utilization and reduces the job pending time. AFS [64] is proposed based on the insight that the scheduler should proactively prepare for the resource contention in the future by utilizing the current resources. It considers both resource efficiency and job length for resource allocation while amortizing the cost of future jobs into the calculation of the current share. Besides, a DL training system framework, CoDDL, is also implemented to deliver automatic job parallelization and efficient re-adjustments. EDL [151] also supports elasticity in DL job scheduling. It implements stop-free scaling and graceful exit to minimize the scale-out and scale-in overheads respectively. Furthermore, EDL optimizes the data allocation pipeline by on-demand and pre-fetching data.
Gandiva[152]设计了一种增长-收缩机制,该机制使用分析信息来估计每个作业的进度,然后相应地分配GPU。Optimus[115]基于性能模型估计任何放置策略的损失减少率。然后设计了一个贪心资源分配方案来优先考虑最大边际损失的减少。这种贪心策略成功地最大化了集群范围内的训练吞吐量。Elan[154]设计了几种机制来实现高效的弹性训练:混合缩放可以更好地权衡训练效率和模型性能;并发无IO复制利用RDMA来减少IO和CPU-GPU内存复制操作的数量;异步协调避免了重新调整期间启动和初始化的高开销。通过集成FIFO和回填调度算法,Elan成功地提高了集群资源利用率,减少了作业挂起时间。AFS[64]是基于调度器应该通过利用当前资源来主动为未来的资源争用做准备这一观点而提出的。它考虑了资源分配的资源效率和作业长度,同时将未来作业的成本分摊到当前份额的计算中。此外,还实现了DL训练系统框架CoDDL,以提供自动作业并行化和高效的重新调整。EDL[151]也支持DL作业调度的弹性。它实现了无停止扩展和优雅退出,最大限度地减少了缩小和扩展开销。此外,EDL通过按需和预取数据来优化数据分配管道。
MARBLE [56] enables elastic DL training in HPC systems. It determines the optimal number of GPUs through offline profiling and employs a FIFO-based policy for scheduling. Vaibhav et al [122] designs a job scalability analyzer and a dynamic programming based optimizer to determine the batch sizes and GPU counts for DL jobs.OASiS [10] introduces a primal-dual framework for optimizing the distributed PS-based jobs, which is coupled with efficient dual subroutines to achieve good long-term performance guarantees with polynomial time complexity. During the training, OASiS dynamically scales in or scales out the number of workers and parameter servers for the best resource utilization and training expedition.
MARBLE[56]在HPC系统中实现弹性DL训练。它通过离线评测确定GPU的最佳数量,并采用基于FIFO的策略进行调度。Vaibhav等人[122]设计了一个作业可扩展性分析器和一个基于动态编程的优化器,以确定DL作业的batch size和GPU个数。OASiS[10]引入了一种用于优化分布式基于PS的作业的原始-对偶框架,该框架与高效的对偶子程序相结合,以实现具有多项式时间复杂性的良好长期性能保证。在培训过程中,OASiS会动态地增加或减少作业数目和参数服务器的数量,以实现最佳的资源利用率和训练规模。
Some online scheduling algorithms adopt the elastic training mechanism for datacenter optimization. For instance, GADGET [166] formulates a resource scheduling analytical model for ring-all-reduce DL and uses a greedy approach to maximize the utility of unfinished jobs. It obtains provable guarantee for high performance. AOnline [178, 184] uses the integer linear program to formulate the maximum weighted schedule problem. It schedules a job if its weight is higher than its estimated serving cost to maximize the total weight of scheduled jobs.
一些在线调度算法采用弹性训练机制进行数据中心优化。例如,GADGET[166]为环形减少DL制定了一个资源调度分析模型,并使用贪心方法最大化未完成作业的效率。它获得了可证明的高性能保证。AOnline[178184]使用整数线性规划来制定最大加权调度问题。如果作业的权重高于其估计的服务成本,则它会调度作业,以最大化调度作业的总权重。
A number of works apply RL to optimize the elastic training policy. Specifically, RIFLING [18] adopts K-means to divide concurrent jobs into several groups based on the computationcommunication ratio similarity. The group operation reduces the state space and accelerates the convergence speed of the RL model. The RL model only determines the number of GPUs and nodes for each job. This can effectively reduce the action space. A reward function is designed to minimize the resource fragmentation and improve the job throughput. RIFLING chooses the Q-Learning algorithm and allows the RL model to perform online update from historical logs to adapt to the workload variation. [116] is another RL scheduler focusing on the PS architecture and dynamically adjusts the resources allocated to the parameter server and workers. It mitigates the optimization instability by a combination of offline supervised learning and online actor-critic reinforcement learning. The RL model also takes the job state and resource state as input and then makes the resource allocation decision for each job. The reward function targets the clusterwide normalized epoch progress. These techniques enable [116] to present satisfactory job latency reduction even for unseen job types.
许多工作应用RL来优化弹性训练策略。具体而言,RIFLING[18]采用K-means方法,根据计算通信比相似性将并发作业划分为多组。群运算减少了RL模型的状态空间,加快了RL模型收敛速度。RL模型仅确定每个作业的GPU和节点的数量。这样可以有效地减少动作空间。设计了一个奖励函数,以最大限度地减少资源碎片并提高作业吞吐量。RIFLING选择Q-Learning算法,并允许RL模型根据历史日志进行在线更新,以适应工作负载的变化。[116]是另一个专注于PS架构的RL调度器,并动态调整分配给参数服务器和作业的资源。它通过离线监督学习和在线演员-评论家强化学习的结合来缓解优化的不稳定性。RL模型还将作业状态和资源状态作为输入,然后为每个作业做出资源分配决策。奖励函数的目标是集群范围内的归一化epoch进度。这些技术使[116]即使对于看不见的作业类型也能提供令人满意的作业延迟减少。
Some works focus on the optimization of elasticity implementation in practical schedulers, e.g., Kubernetes. Wang et al [147] developed an elastic scheduling framework as plugins in Kubernetes.It uses the training job progress information to allocate and reallocate GPUs to minimize JCT. It efficiently reallocates GPUs based on a SideCar process, which introduces an early initialization mechanism for fast reshaping down and achieves non-intrusion to DL training frameworks. DynamoML [21] is a Kubernetes platform which combines KubeShare [158] and Dragon [92] for DL workload scheduling. Dragon [92] fills the gap that existing Kubernetes schedulers fail to manage the distributed training workloads. It resolves this issue by introducing three enhancements including gang-scheduling, locality-aware placement and autoscaling of training workloads. DynamoML also supports scheduling optimization for inference jobs, which will be discussed in Sec. 4.
一些工作集中于实际调度器中弹性实现的优化,例如Kubernetes。王等人[147]开发了一个弹性调度框架作为Kubernetes中的插件。它使用训练工作进度信息来分配和重新分配GPU,以最大限度地减少JCT。它基于SideCar过程有效地重新分配GPU,引入了一种早期初始化机制来快速重构,并实现了对DL训练框架的非入侵。DynamoML[21]是一个Kubernetes平台,它结合了KubeShare[158]和Dragon[92]用于DL工作负载调度。Dragon[92]填补了现有Kubernetes调度器无法管理分布式训练工作负载的空白。它通过引入三种增强功能来解决这个问题,包括集群调度、位置感知和训练工作量的自动缩放。DynamoML还支持推理作业的调度优化,这将在第4节中讨论。
In addition to the elasticity of GPU resources, DL job configurations can also be dynamically adjusted C3. Pollux [117] aims to achieve higher utilization by automatically configuring the DL training jobs and co-adaptively allocating resources to them. Specifically, it defines goodput, a metric for comprehensively measuring training performance including system throughput and statistical efficiency. It designs a joint scheduling architecture to maximize the goodput. At the job-level granularity, Pollux dynamically tunes the batch size and learning rate for the best utilization of the allocated resources. At the cluster-level granularity, Pollux dynamically (re-)allocates resources based on the goodput of all the jobs sharing the cluster as well as other cluster-level objectives (e.g., fairness, JCT). Aryl [85] further extends Pollux by dynamically loaning idle inference GPU nodes to training jobs. It brings higher cluster utilization and lower queuing time.
除了GPU资源的弹性之外,DL作业配置也可以动态调整C3。Pollux[117]旨在通过自动配置DL训练作业并自适应地为其分配资源来实现更高的利用率。具体地说,它定义了goodput,这是一种全面衡量训练性能的指标,包括系统吞吐量和统计效率。它设计了一个联合调度架构,以最大限度地提高吞吐量。在作业级别的粒度上,Pollux动态调整batch size和学习速率,以获得所分配资源的最佳利用率。在集群级别的粒度上,Pollux根据共享集群的所有作业的吞吐量以及其他集群级别的目标(例如,公平性、JCT)动态(重新)分配资源。Aryl[85]通过动态借用空闲推理GPU节点来训练作业,进一步扩展了Pollux。它带来了更高的集群利用率和更低的排队时间。
Similar to Pollux, ONES [12] automatically manages the elasticity of each job based on the training batch size.It designs an online evolutionary search algorithm to continuously optimize the scheduling decisions, which achieves superior performance compared with greedy strategies. More recently, Microsoft presents Singularity [129], an epochal distributed scheduling system for Azure DL training and inference workloads. It achieves transparent preemption, migration and elasticity across a global fleet of AI accelerators (e.g., GPUs, FPGAs). It implements device proxy for the decoupled execution and elastic scheduling across the workers. Although it is developed for public cloud services, the promising techniques are also effective in managing private GPU datacenters.
与Pollux类似,ONES[12]根据训练batch size自动管理每个作业的弹性。它设计了一种在线进化搜索算法来持续优化调度决策,与贪婪策略相比,该算法具有更好的性能。最近,微软推出了Singularity[129],这是一个划时代的用于Azure DL训练和推理工作负载的分布式调度系统。它实现了全球人工智能加速器(如GPU、FPGA)的透明抢占、迁移和弹性。它实现了设备代理,用于解耦执行和跨作业的弹性调度。尽管它是为公共云服务开发的,但有前景的技术在管理私有GPU数据中心方面也很有效。
3.3 Implications 影响
The scheduling objective plays an important role in designing schedulers for GPU datacenters.A majority of schedulers consider timing-efficiency and fairness. In contrast, other objectives including deadline guarantee, cost efficiency and accuracy efficiency are not fully explored yet, although they have been thoroughly considered in the conventional cloud and HPC systems.Modern cloud providers are accelerating the pace of building GPU platforms to support a sizable number of training workloads. We anticipate these objectives are also important for training workload management. This inspires researchers and developers to jointly optimize their objectives with the constraints of deadline guarantee and cost.
调度目标在GPU数据中心的调度器设计中起着重要作用。大多数调度器考虑时间效率和公平性。相比之下,包括最后期限保证、成本效率和准确性效率在内的其他目标尚未得到充分探索,尽管它们在传统的云和HPC系统中已经得到了充分考虑。现代云提供商正在加快构建GPU平台的步伐,以支持大量的训练工作负载。我们预计这些目标对培训工作量管理也很重要。这激励了研究人员和开发人员在截止日期保证和成本的约束下共同优化他们的目标。
According to the unique resource consumption features of DL training jobs, datacenter managers can enhance the overall resource utilization and improve users’ experience through designing more efficient resource allocation mechanisms, e.g., fine-grained job placement on GPUs, dynamic job parallelism adjustment, adaptive CPU allocation, etc. However, these approaches have their limitations that can hinder their deployment in practice. For instance, adaptive training could change jobs’ batch size, learning rate and GPU amount, which can cause model convergence issues.Its generalization for more application scenarios also requires more validations. Job colocation can cause potential performance degradation and fault tolerance issue, which can make users unwilling to adopt this feature. How to address these practical issues is a promising and challenging future direction. We look forward to seeing more progress in this topic.
根据DL培训作业独特的资源消耗特征,数据中心管理者可以通过设计更高效的资源分配机制来提高整体资源利用率,改善用户体验,例如GPU上的细粒度作业布局、动态作业并行度调整、自适应CPU分配等,这些方法有其局限性,可能会阻碍它们在实践中的部署。例如,自适应训练可能会改变作业的批量大小、学习率和GPU数量,这可能会导致模型收敛问题。它对更多应用场景的泛化也需要更多的验证。作业主机代管可能会导致潜在的性能下降和容错问题,这可能会让用户不愿意采用此功能。如何解决这些实际问题是一个充满希望和挑战的未来方向。我们期待着在这一议题上取得更多进展。
Although different scheduling algorithms for conventional workloads and systems have been extensively studied for decades, it still requires more efforts to design effective scheduling algorithms for large-scale GPU datacenters to reduce the operational cost and improve the job throughput. The rapid development of AI technology motivates researchers to investigate the possibility of using machine learning to optimize scheduler designs. From our summary, ML-based schedulers have shown their effectiveness in some scenarios. However, the datacenter managers are still concerned about the reliability and scalability of these ML-based schedulers. We expect more research works will be performed to address these concerns and make these schedulers more practical.
尽管针对传统工作负载和系统的不同调度算法已经被广泛研究了几十年,但为大规模GPU数据中心设计有效的调度算法以降低操作成本并提高作业吞吐量仍然需要付出更多的努力。人工智能技术的快速发展促使研究人员研究使用机器学习优化调度器设计的可能性。根据我们的总结,基于ML的调度器在某些场景中显示了其有效性。然而,**数据中心管理者仍然关心这些基于ML的调度器的可靠性和可扩展性。**我们预计将进行更多的研究工作来解决这些问题,并使这些调度器更加实用。
4.SCHEDULING DL INFERENCE WORKLOADS 调度DL推理工作负载
As more DL-based applications are released as online services in our daily life, it becomes more critical to manage and schedule large-scale inference workloads in the GPU datacenter. Different from the resource-intensive and long-term training workloads, inference jobs have unique characteristics and requirements (Sec. 2.1.2), which demand new scheduling solutions. Similar as Sec.3, we categorize these inference scheduling techniques based on their objectives, and resource consumption features. Then we give some implications from these works at the end of this section.Table 2 summaries the relevant papers and their features.
随着越来越多基于DL的应用程序在我们的日常生活中作为在线服务发布,在GPU数据中心管理和调度大规模推理工作负载变得更加重要。与资源密集型和长期训练工作负载不同,推理工作具有独特的特点和要求(第2.1.2节),需要新的调度解决方案。类似于Sec。3,我们根据这些推理调度技术的目标和资源消耗特征对其进行了分类。然后,我们在本节末尾给出了这些工作的一些启示。表2总结了相关论文及其特点。
4.1.1 Efficiency.
As discussed in Sec. 2.2.3, the main objective for scheduling an inference workload is to improve its efficiency. This includes the reduction of inference latency and cost, and improvement of the prediction accuracy I2. The challenge here is that there exist trade-offs among different efficiency goals. Here we discuss the techniques to improve each goal as well as to jointly balance and improve them.
如第2.2.3节所述,调度推理工作负载的主要目标是提高其效率。这包括减少推断延迟和成本,以及提高预测精度I2。这里的挑战是,在不同的效率目标之间存在权衡。在这里,我们讨论了改进每个目标以及共同平衡和改进这些目标的技术。
1)Accuracy efficiency. Improving the prediction accuracy is a perpetual objective in an inference system. To achieve this, one approach is to collect a set of models, and select the best one to predict the result for each input query. The scheduling decision made includes model selection and resource allocation among different candidates. Ease.ml [87] leverages the input and output shape information of the query sample to automatically select the model. It estimates the potential accuracy improvement of each candidate model and then picks the highest one for actual inference.It also formulates the cost-aware model selection process under both single-tenant and multi-tenant settings with multi-armed bandit and Bayesian Optimization. Another effective approach is model ensemble, which combines the prediction results from multiple models to improve the prediction accuracy and generalization. Clipper [25] examines the benefits brought from the model ensemble in computer vision tasks and applies a linear ensemble method to compute a weighted average of the base model predictions. The linear weights are decided by bandit- and learning-based approaches.Rafiki [148] leverages an RL model to determine the model set for the ensemble. This model is also used to identify the final optimal model combinations, and tune critical parameters, e.g., batch size.
1) 精度效率。 提高预测精度是推理系统的永恒目标。为了实现这一点,一种方法是收集一组模型,并选择最好的模型来预测每个输入查询的结果。所做出的调度决策包括模型选择和不同候选者之间的资源分配。Ease.ml[87]利用查询样本的输入和输出形状信息来自动选择模型。它估计每个候选模型的潜在精度提高,然后选择最高的模型进行实际推理。它还利用multi-armed bandit(多臂老虎机算法)和贝叶斯优化制定了单租户和多租户环境下的成本感知模型选择过程。另一种有效的方法是模型集成,它将多个模型的预测结果相结合,以提高预测精度和泛化能力。Clipper[25]研究了计算机视觉任务中模型集成带来的好处,并应用线性集成方法计算基本模型预测的加权平均值。线性权重由基于bandit和学习的方法决定。Rafiki[148]利用RL模型来确定集合的模型集。该模型还用于识别最终的最优模型组合,并调整关键参数,例如批量大小。
2)Latency efficiency. An inference system should have a satisfactory response time, even for burst and fluctuating query requests C7. The latency requirement poses challenges for the scheduler to decide which jobs to be prioritized in the job assignment and rearrangement process.This objective can be achieved via carefully optimizing the resource allocation.
2) 延迟效率。 推理系统应该具有令人满意的响应时间,即使对于突发和波动的查询请求C7也是如此。延迟要求给调度器决定在作业分配和重排过程中优先考虑哪些作业带来了挑战。这一目标可以通过仔细优化资源分配来实现。
It is common to launch multiple inference execution instances concurrently to meet the corresponding latency requirement as much as possible due to the low GPU utilization for each request(C5). Therefore, the inference scheduler can make scheduling decisions aiming at scaling up resources according to the request density to maintain a satisfactory latency. Clipper [25] conducts linear scaling of inference instances and uses separate docker containers to isolate different models. It replicates the model containers according to the number of queries and applies adaptive batching independently for each model due to the varied execution time. MArk [172, 173] scales the inference instances with the cloud services. It selects and combines different cloud services like AWS EC2 and Lambda in order based on their prices and scaling abilities. Also, it monitors the system loads and request queuing situations proactively and leverages Lambda to scale up instances when there exist requests violating the latency demands. InferLine [24] targets the pipelined inference workloads with multiple stages. It monitors the frequency of queries to each model and makes the scaling decisions of each component separately, to maintain the latency SLOs even during sharp bursts.
由于每个请求的GPU利用率较低,通常并发启动多个推理执行实例以尽可能满足相应的延迟需求(C5)。因此,推理调度器可以根据请求密度做出旨在扩展资源的调度决策,以保持令人满意的延迟。Clipper[25]对推理实例进行线性缩放,并使用单独的docker容器来隔离不同的模型。它根据查询的数量复制模型容器,并根据不同的执行时间独立地为每个模型应用自适应批处理。MArk[172,173]用云服务扩展推理实例。它根据价格和扩展能力选择并组合不同的云服务,如AWS EC2和Lambda。此外,它还主动监视系统负载和请求排队情况,并在存在违反延迟需求的请求时利用Lambda扩展实例。interline[24]针对多阶段的流水线推理工作负载。它监视对每个模型的查询频率,并单独做出每个组件的缩放决策,以便即使在急剧爆发期间也能保持延迟slo。
A number of works aim to provide bounded latency for inference execution at the system level considering its deterministic execution I1. Clockwork [51] discovers that many DL inference models have deterministic performance because of the underlying deterministic computations. Thus, it guarantees deterministic latency by alleviating the uncertainty introduced by other components of the system. To overcome the uncertainty from memory and cache usages, hardware interactions, and other uncontrollable external performance variations, Clockwork consolidates the configurations among all the system layers during the inference execution, by proactively controlling the memory allocation and deallocation, and disabling concurrent execution of multiple inference workloads to eliminate the interaction. Reducing the parallelism of execution eliminates the interference from other tasks, but inevitably brings lower throughput and resource utilization. To address this issue, Abacus [29] tries to guarantee SLO for query requests under the GPU co-location scenarios. It controls the execution sequence and the co-location situation proactively, rather than the default random-ordered execution overlap. Given the explicit order and specific co-location operators on GPUs, Abacus could predict the estimated running time under co-location from the early offline profiling stage. Based on the estimation, the query controller schedules all the simultaneous inference workloads to guarantee the QoS by searching the optimal execution sequence of DNN operators. ParM [78] migrates the concept of erasure codes from distributed computing to model inference systems, and uses learning-based coded computation to introduce redundancy and thus supports the recovery of inference executions with tail latency or failures.
考虑到推理执行的确定性,许多工作旨在为系统级的推理执行提供有界延迟(I1)。Clockwork[51]发现,由于底层的确定性计算,许多深度学习推理模型具有确定性性能。因此,它通过减轻系统其他组件引入的不确定性来保证确定性延迟。为了克服内存和缓存使用、硬件交互和其他不可控的外部性能变化带来的不确定性,Clockwork在推理执行期间整合了所有系统层之间的配置,通过主动控制内存分配和释放,并禁用多个推理工作负载的并发执行来消除交互。降低执行的并行性可以消除来自其他任务的干扰,但不可避免地会降低吞吐量和资源利用率。为了解决这个问题,Abacus[29]尝试在GPU共置场景下保证查询请求的SLO。它主动控制执行顺序和共定位情况,而不是默认的随机顺序执行重叠。给定gpu上明确的顺序和特定的共址运算符,Abacus可以从早期的离线分析阶段预测共址下的估计运行时间。在此基础上,查询控制器通过搜索DNN算子的最优执行顺序,调度所有同时进行的推理工作负载,以保证QoS。ParM[78]将擦除码的概念从分布式计算迁移到模型推理系统,并使用基于学习的编码计算引入冗余,从而支持具有尾部延迟或失败的推理执行的恢复。
Some solutions proactively schedules the inference workloads and rearranges the execution sequence at the job level. Irina [150] is the first online inference scheduling system, modeling the satisfaction of latency demands as a scheduling problem. By leveraging preemption for DL inference workloads, Irina dynamically decides whether to preempt the ongoing query and launch the later arrived one, which brings significant reduction of average completion time for inference workloads. The main challenge is that existing ML frameworks are not designed and suitable for preemption during execution. Irina carefully manages the preemption process by adding an exit node to the existing dataflow graph of the inference workload, thus enabling safe preemption at arbitrary moments. It is necessary to have more runtime information about the inference workloads for effective scheduling. Kube-Knots [137] makes predictions about the resource utilization of each inference workload from two aspects. From the spatial aspect, Kube-Knots discovers the correlations across different resource utilization metrics, and then forecasts the future resource utilization. From the temporal aspect, Kube-Knots predicts the peak inference usage and tries to avoid co-locating jobs which could attain peak consumption of the same resources simultaneously.
一些解决方案主动调度推理工作负载,并在作业级别重新安排执行顺序。Irina[150]是第一个在线推理调度系统,将延迟需求的满足建模为调度问题。通过利用DL推理工作负载的抢占,Irina动态决定是否抢占正在进行的查询并启动后到达的查询,这大大减少了推理工作负载的平均完成时间。主要的挑战是现有的ML框架的设计不适合在执行期间进行抢占。Irina通过在推理工作负载的现有数据流图中添加退出节点来仔细管理抢占过程,从而在任意时刻实现安全抢占。为了有效地调度,有必要拥有更多关于推理工作负载的运行时信息。Kube-Knots[137]从两个方面对每个推理工作负载的资源利用率进行了预测。从空间方面来看,Kube-Knots发现不同资源利用指标之间的相关性,然后预测未来的资源利用情况。从时间方面来看,Kube-Knots预测峰值推理使用情况,并试图避免可能同时达到相同资源消耗峰值的任务共存。
3) Cost-efficiency. The monetary cost becomes one of the main concerns when using public cloud resources to deploy DL inference workloads. Considering the varied compute capabilities and prices for different types of resources and services, a couple of schedulers implement many mechanisms to achieve cost-efficient inference. MArk [172, 173] analyzes the cost of utilizing different levels of resource abstractions in Amazon Web Services (AWS) and Google Cloud Platform (GCP) for inference. It finds that the Infrastructure-as-a-Service (IaaS) provides better cost efficiency than Content-as-a-Service (CaaS), while Function-as-a-Service (FaaS) could compensate for the relatively long cold start latency of IaaS at the cost of increased costs. Small instances with advanced CPUs and burstable instances are also recommended. For GPU instances, the cost can be greatly reduced by batch processing as well. Given different levels of capability, scalability, and pricing,
MArk greedily selects the most cost-effective type of instances and leverages the spot instances for cost-saving. AutoDeep [89] considers not only the resource type in the cloud but also the device placement for DL inference. It leverages Bayesian Optimization for the nearly optimal cloud configuration and Deep Reinforcement Learning for the nearly optimal device placement. Constrained by the SLO requirements, AutoDeep performs joint optimization to minimize the total cost of the inference execution. Cocktail [52] develops a distributed weighted auto-scaling policyand leverages the spot instances to minimize the cost.
**3)成本效率。**在使用公共云资源部署深度学习推理工作负载时,货币成本成为主要问题之一。考虑到不同类型的资源和服务的不同计算能力和价格,几个调度器实现了许多机制来实现经济高效的推理。MArk[172,173]分析了在Amazon Web Services (AWS)和Google Cloud Platform (GCP)中利用不同级别的资源抽象进行推理的成本。研究发现,基础设施即服务(IaaS)比内容即服务(CaaS)提供了更好的成本效率,而功能即服务(FaaS)可以弥补IaaS相对较长的冷启动延迟,但代价是增加成本。还建议使用具有高级cpu和突发实例的小型实例。对于GPU实例,批处理也可以大大降低成本。考虑到不同水平的能力、可扩展性和定价,MArk[]172,17.]地选择最具成本效益的实例类型,并利用现货实例来节省成本。AutoDeep[89]不仅考虑了云中的资源类型,还考虑了深度学习推理的设备位置。它利用贝叶斯优化几乎最优的云配置和深度强化学习几乎最优的设备放置。受SLO要求的限制,AutoDeep执行联合优化以最小化推理执行的总成本。Cocktail[52]开发了一种分布式加权自动缩放策略,并利用spot实例来最小化成本。
4) Trade-offs between accuracy, latency and cost. The objectives of accuracy, latency and cost are not independent C6. Improving one goal may possibly compromise another goal if the solution is not designed properly. Besides, users may also have their specific expectations about different objectives. This motivates researchers to explore the trade-offs between these objectives, and devise more flexible and comprehensive scheduling systems.
4)在准确性、延迟和成本之间进行权衡。 准确性、延迟和成本的目标不是相互独立的(C6)。如果解决方案设计不当,改进一个目标可能会损害另一个目标。此外,用户也可能对不同的目标有自己特定的期望。这促使研究人员探索这些目标之间的权衡,并设计出更灵活、更全面的调度系统。
The adoption of multiple models can improve the model inference accuracy, but might also increase the response latency and cost. Several works track the latency and prediction accuracy of different models and implement mechanisms to select the most appropriate ones determined by the schedulers. Clipper [25] introduces a model selection abstraction, which supports both single model selection and model ensemble selection. It executes the inference for all the models and combines their results. It observes the corresponding accuracy and latency feedback continuously to make the selection with a best-effort search method. Model-Switching [176] pursues the trade-offs between computational cost and service accuracy by switching different model variants proactively, to improve the accuracy of responses under the latency constraint. By maximizing the ratio of correct predictions returned within the deadline, it makes selections among model variations with different computation demands and accuracy. Cocktail [52] balances the cost with accuracy and latency on the public cloud via the optimization of the model ensemble. With a dynamic model selection policy that searches models tightly with the accuracy and latency bounds, Cocktail reduces the candidates in the ensemble and accomplishes fast and efficient model selection.
采用多模型可以提高模型的推理精度,但也可能增加响应延迟和成本。一些工作跟踪了不同模型的延迟和预测精度,并实现了由调度器确定的选择最合适模型的机制。Clipper[25]引入了一个模型选择抽象,它既支持单个模型选择,也支持模型集成选择。它对所有模型执行推理并组合它们的结果。连续观察相应的精度和延迟反馈,用最优搜索法进行选择。模型切换[176]通过主动切换不同的模型变量,在计算成本和服务精度之间进行权衡,以提高延迟约束下响应的准确性。通过最大限度地提高在期限内返回正确预测的比例,在不同计算需求和精度的模型变量中进行选择。Cocktail[52]通过优化模型集合,在公共云上平衡了成本与准确性和延迟。Cocktail采用一种动态模型选择策略,严格按照准确率和延迟界限搜索模型,减少了集合中的候选模型,实现了快速高效的模型选择。
Some schedulers allow users to specify their demands about accuracy, latency and cost, and make scheduling decisions directly according to the demands. Tolerance Tiers [55] discloses the efforts the system can offer to achieve each objective, and makes users programmatically select their demands. Observing that improving the accuracy of some extreme requests can increase the latency greatly, Tolerance Tiers relaxes and sacrifices the accuracy demand to improve the latency and service cost. Each tier defines an error tolerance to indicate the tolerable accuracy loss, and an optimization objective. Then, Tolerance Tiers optimizes the objective under the constraint of the maximum error tolerance. INFaaS [121, 155] also asks for the performance and accuracy demands from the users. It generates some variants from the existing models with different specific parameters (e.g., batch size, hardware configurations, hardware-specific parameters). After one-time profiling for each variant, INFaaS selects the model variant based on the resource consumption and performance information from the profiling to serve users’ requests. Since each model variant may have different performance and monetary costs during execution, INFaaS makes the selection via a heuristic-based approach, which selects the variant with the minimum cost while meeting the SLO constraint, or upgrades existing variants with higher performance to fulfill the burst queries.
一些调度器允许用户指定他们对准确性、延迟和成本的要求,并直接根据需求做出调度决策。容差等级[55]揭示了系统为实现每个目标所能付出的努力,并让用户以编程方式选择他们的需求。考虑到提高某些极端请求的准确性会大大增加延迟,容忍层放宽和牺牲准确性需求,以提高延迟和服务成本。每一层都定义了一个误差容忍度,以表示可容忍的精度损失,以及一个优化目标。然后,在最大误差容忍度约束下,对目标进行优化。INFaaS[121,155]也要求用户对性能和精度提出要求。它从具有不同特定参数(例如,批处理大小、硬件配置、硬件特定参数)的现有模型中生成一些变体。在对每个变体进行一次性分析之后,INFaaS根据分析中的资源消耗和性能信息选择模型变体,以满足用户的请求。由于每个模型变体在执行过程中可能具有不同的性能和货币成本,因此INFaaS通过基于启发式的方法进行选择,该方法在满足SLO约束的情况下选择成本最低的变体,或者升级具有更高性能的现有变体以满足突发查询。
4.1.2 System Throughput. Another important objective for scheduling inference workloads is to improve its throughput capability. The techniques to achieve this goal is summarized as follows.
4.1.2系统吞吐量。调度推理工作负载的另一个重要目标是提高其吞吐量能力。实现这一目标的技术总结如下。
**1) Batching execution. ** One common approach is to batch multiple inference queries, and execute them concurrently. Handling individual inference queries usually leads to GPU underutilization C5. Hence, batching inference can efficiently improve the utilization and reduce the system overhead. Like job queuing in parallel job scheduling, batching multiple queries can delay the execution of the requests that come earlier, and possibly jeopardize the SLO requirement. Setting a proper batch size is critical to balance such delays and system throughput. Most schedulers dynamically adjust this hyperparameter based on the actual SLO requirement and queuing situation.
1)批量执行。 一种常见的方法是批量处理多个推理查询,并并发地执行它们。处理单个推理查询通常会导致GPU利用率不足(C5)。因此,批处理推理可以有效地提高利用率,降低系统开销。与并行作业调度中的作业排队一样,批处理多个查询可能会延迟较早到来的请求的执行,并可能危及SLO需求。设置适当的批处理大小对于平衡此类延迟和系统吞吐量至关重要。大多数调度器都会根据实际的SLO需求和排队情况动态调整这个超参数。
First, some schedulers adopt heuristic methods to tune the batch size. Clipper [25] and Rafiki [148] apply the practical Additive-Increase-Multiplicative-Decrease (AIMD) algorithm to adjust the inference batch size. Specifically, the batch size is additively increased by a fixed amount until the latency of processing a batch exceeds the latency requirement and then multiplicatively decreased by a fixed percent. Clipper evaluates that AIMD is simple yet effective and adaptive to the changing throughput of a model in special cases. It also aggressively delays the execution of queries under moderate loads to the subsequent batch, which can bring a significant throughput increase for some models. GSLICE [31] also applies a similar adaptive and self-learning approach to determine the optimal batch size. It carefully tracks the execution time and increases the batch size until the execution of the last batch exceeds the SLO requirement. Ebird [26, 27] proposes a novel elastic batching mechanism, which runs different CUDA streams concurrently for different batches. Motivated by the observation that processing multiple queries in a large batch has similar performance as multiple CUDA streams with smaller batch sizes, Ebird dynamically adjusts the batch size per stream to utilize the spare GPU resources and fulfill the whole GPU. In each scheduling round, it selects and launches a job based on its batch size and remaining GPU resources in a best-effort manner, squeezing the full GPU utilization and minimizing inference queuing delay.
首先,一些调度器采用启发式方法来调优批处理大小。Clipper[25]和Rafiki[148]采用实用的AIMD (additive - increase - multiply - reduction)算法来调整推理批大小。具体地说,批大小以固定的数量增加,直到处理批的延迟超过延迟要求,然后以固定的百分比乘法减少。Clipper评价AIMD简单有效,在特殊情况下能够适应模型吞吐量的变化。它还积极地将中等负载下的查询执行延迟到后续批处理,这可以为某些模型带来显着的吞吐量增加。GSLICE[31]也采用类似的自适应和自学习方法来确定最优批大小。它仔细跟踪执行时间并增加批处理大小,直到最后一批处理的执行超过SLO要求。Ebird[26,27]提出了一种新的弹性批处理机制,该机制为不同的批处理并发运行不同的CUDA流。Ebird观察到大批量处理多个查询与批量大小较小的多个CUDA流具有相似的性能,因此Ebird动态调整每个流的批处理大小,以利用备用GPU资源并满足整个GPU的需求。在每个调度轮中,它根据其批处理大小和剩余GPU资源以最佳方式选择并启动作业,从而压缩GPU的全部利用率并最大限度地减少推理排队延迟。
Second, some schedulers propose optimization-based methods to balance the inference delay and throughput. MArk [172, 173] considers the maximum time of delaying a query, profiles the processing rate without batching, and searches for the optimal batch size under the SLO constraint. Nanily [136] presents the upper bound of the batch size by retrieving the maximum remaining time for the requests, calculated as the remaining time towards the deadline subtracted by the least queuing time for the available resources. It then derives the corresponding batch size, which makes the inference execution time equal or close to the maximum remaining time. DyBatch [179] considers the fairness of the delay for each independent workload when batching. It implements fine-grained batching schemes along with fairness-driven scheduling, which can compensate for the deviation of slowdown for small inference workloads. DyBatch organizes the workload batches in a time-sharing manner and selects the batch with the lowest resource utilization for running, thus maintaining fairness and minimizing the slowdown of each workload.
其次,一些调度器提出了基于优化的方法来平衡推理延迟和吞吐量。MArk[172,173]考虑了查询延迟的最大时间,在没有批处理的情况下分析了处理速率,并在SLO约束下搜索了最优批处理大小。Nanily[136]通过检索请求的最大剩余时间来给出批大小的上界,计算为截止日期前的剩余时间减去可用资源的最小排队时间。然后,它派生出相应的批处理大小,这使得推理执行时间等于或接近最大剩余时间。DyBatch[179]在批处理时考虑了每个独立工作负载延迟的公平性。它实现了细粒度的批处理方案以及公平驱动的调度,这可以补偿小型推理工作负载的减速偏差。DyBatch以分时的方式组织工作负载批次,并选择资源利用率最低的批次运行,从而保持公平性并最大限度地减少每个工作负载的减速。
2) Caching and reusing. Another widely-used strategy for throughput improvement is caching and reusing the prediction results across different requests C7. The scheduler selects the request that benefits most from caching and allocates proper resources. This can be done at two levels.
2)缓存和重用。 另一个广泛使用的吞吐量改进策略是缓存和跨不同请求重用预测结果C7。调度器选择从缓存中获益最多的请求,并分配适当的资源。这可以在两个层面上完成。
The first direction is to perform optimization at the query level. To provide fast responses to different queries, the inference system can cache the inference execution and prediction results for burst queries. Clipper [25] maintains a prediction cache for requests with the same target model and the query input. Then it can produce the results for some queries without evaluating the model, thus increasing the inference throughput. Clipper also applies an LRU cache eviction policy to optimize the caching efficiency. However, this approach may be less efficient when the queries do not have high similarities in practical scenarios, which leads to high cache miss rates and evictions.
第一个方向是在查询级别执行优化。为了提供对不同查询的快速响应,推理系统可以缓存突发查询的推理执行和预测结果。Clipper[25]为具有相同目标模型和查询输入的请求维护一个预测缓存。然后,它可以在不评估模型的情况下产生某些查询的结果,从而提高推理吞吐量。Clipper还应用了LRU缓存退出策略来优化缓存效率。然而,当查询在实际场景中没有很高的相似性时,这种方法可能效率较低,这会导致高缓存丢失率和清除。
The second direction is to perform optimization at the device level. Gillman et al [45] proposed to cache the DL models instead of the inference results. It schedules models to be loaded into the limited GPU memory to maximize the probability of servicing an incoming request without swapping the models in and out of the memory, thus accelerating the inference by eliminating the cold start latency with cache hits. The caching and eviction policy considers many runtime aspects of DL inference workloads, including model size, frequency, model accuracy, and speed. This work also discusses some future directions for more dynamic caching mechanisms and policies, like framework-level GPU memory-friendly optimization, proactively loading and evicting, and cluster-level GPU memory allocation. To address the limitation of GPU memory, GSLICE [31] and HiveMind [108] explore the common GPU memory component in different inference models, and propose to save GPU resources via memory sharing. Particularly, GSLICE enables efficient GPU memory sharing by allowing the reuse of model parameters via modifications to the DL framework, exposing the CUDA address to different instances. Therefore, it supports loading the inference model-related parameters only once to the GPUs, resulting in faster module loading. HiveMind extends the shared content and brings more possibilities of shared model weights and layers across different inference workloads, saving the overhead from both model loading and inference evaluation. TrIMS [30] organizes the memory sharing of different models in a more systematic design. The model resource manager in TrIMS offers a multi-tiered cache for DL models to be shared across users’ FaaS functions and enables DL model sharing across all levels of the memory hierarchy in the GPU, CPU, local storage, and remote storage in the cloud. TrIMS reconciles the lifecycle of model memory consumption and carefully handles the cache misses and evictions. It also considers multi-node, isolation, and fairness problems during sharing. Extensive evaluations on different models show its general abilities to improve the inference performance by mitigating the model loading overhead.
第二个方向是在设备级执行优化。Gillman等[45]提出缓存深度学习模型,而不是缓存推理结果。它计划将模型加载到有限的GPU内存中,以最大限度地为传入请求提供服务,而不需要在内存中交换模型,从而通过消除缓存命中的冷启动延迟来加速推理。缓存和回收策略考虑DL推理工作负载的许多运行时方面,包括模型大小、频率、模型准确性和速度。这项工作还讨论了一些动态缓存机制和策略的未来方向,如框架级GPU内存友好优化,主动加载和驱逐,以及集群级GPU内存分配。为了解决GPU内存的局限性,GSLICE[31]和HiveMind[108]探索了不同推理模型中常见的GPU内存组件,并提出通过内存共享来节省GPU资源。特别是,GSLICE允许通过修改DL框架来重用模型参数,从而将CUDA地址暴露给不同的实例,从而实现高效的GPU内存共享。因此,它支持只将与推理模型相关的参数加载到gpu一次,从而加快模块加载速度。HiveMind扩展了共享内容,并在不同的推理工作负载之间提供了更多共享模型权重和层的可能性,从而节省了模型加载和推理评估的开销。TrIMS[30]对不同车型的内存共享进行了更系统的组织设计。TrIMS中的模型资源管理器为DL模型提供了一个多层缓存,以便在用户的FaaS功能之间共享,并使DL模型能够在GPU、CPU、本地存储和云中的远程存储中的所有内存层次中共享。TrIMS协调模型内存消耗的生命周期,并仔细处理缓存丢失和清除。它还考虑了共享过程中的多节点、隔离和公平性问题。对不同模型的广泛评估表明,它能够通过减轻模型负载开销来提高推理性能。
3) System configuration tuning. Besides the optimization techniques detailed above, there exist some schedulers leveraging end-to-end configuration tuning to improve the system throughput. Morphling [143] formulates the optimal configuration search as a few-shot learning problem. Then it adopts model-agnostic meta-learning (MAML) [40] to combine offline meta-model training for inference serving performance modeling under varied hardware and runtime configurations, and performs online few-shot learning to predict the service performance. Based on the prediction, Morphling auto-tunes the resource provisioning configurations and makes better scheduling decisions. RRL [118] concentrates on optimizing the parallelism configurations from different levels, including request level parallelism and intra-request level (inter-op and intra-op) parallelism, which have strong impacts on the latency of the entire system. RRL utilizes a region-based RL method to tune the parallelism configurations and reduce the inference processing latency, based on the system performance similarity between different configurations within a similar parallelism setting.
3)系统配置调优。 除了上面详细介绍的优化技术之外,还有一些调度器利用端到端配置调优来提高系统吞吐量。Morphling[143]将最优构型搜索表述为一个少次学习问题。然后采用模型无关元学习(model-agnostic meta-learning, MAML)[40],结合离线元模型训练进行不同硬件和运行时配置下的推理服务性能建模,并进行在线少次学习进行服务性能预测。基于预测,Morphling自动调整资源供应配置并做出更好的调度决策。RRL[118]侧重于从不同层次优化并行配置,包括请求级并行和请求内级(inter-op和intra-op)并行,这对整个系统的延迟有很大的影响。RRL利用基于区域的RL方法来调优并行配置并减少推理处理延迟,这是基于相似并行设置中不同配置之间的系统性能相似性。
4.2 Resource Consumption Feature
4.2资源消耗特性
Similar to training workloads, the inference schedulers can also be categorized based on the resource consumption feature. Below we detail the scheduling solutions designed to target these features.
与训练工作负载类似,推理调度器也可以基于资源消耗特性进行分类。下面我们将详细介绍针对这些特性设计的调度解决方案。
4.2.1 Colocation and resource sharing.
From Challenge C5 in Sec. 2.2.3, executing one inference request can lead to GPU resource underutilization. The recent development of GPU architecture designs motivates the GPU sharing from both the hardware perspective [2, 4] and software perspective [127, 168]. GPU sharing across different inference requests can significantly improve the resource utilization by better leveraging GPUs’ parallel compute capability. However, it can also incur the risks of violating the latency requirements due to the uncertain running time.
4.2.1主机托管和资源共享。
从第2.2.3节的挑战C5来看,执行一个推理请求可能导致GPU资源利用率不足。GPU架构设计的最新发展从硬件角度[2,4]和软件角度[127,168]激发了GPU共享。跨不同推理请求的GPU共享可以更好地利用GPU的并行计算能力,从而显著提高资源利用率。然而,由于不确定的运行时间,它也可能导致违反延迟需求的风险。
One line of research works adopt the static colocation strategy to guarantee the inference latency. Space-Time [68] calls for both space-sharing and time-sharing for DL inference with GPUs. It preserves the predictability and isolation during virtualization by monitoring the inference latency per kernel. Then it improves the utilization by merging concurrent small kernels into larger superkernels that can fill up the GPU utilization under the time-sharing mechanism. Irina [150] only considers a safe GPU colocation situation based on the peak GPU requirement of the workloads, when their total GPU requirement does not exceed the capacity. It assumes there is no interference and slowdown on the job completion time and heuristically places the newly arrived job on the GPU with the smallest JCT. Nexus [126] also applies a heuristic approach to select the requests to be co-located on the same GPU. First, it identifies the most appropriate batch size for throughput and SLO needs of the existing inference workload. Afterward, it establishes all possible combinations within a GPU’s duty cycle on a single GPU in a best-fit manner, and maximizes the utilization without violating the latency requirement.
其中一项研究工作采用静态主机托管策略来保证推理延迟。时空[68]要求gpu的深度学习推理同时需要空间共享和时间共享。它通过监视每个内核的推理延迟来保持虚拟化期间的可预测性和隔离性。然后在分时机制下,通过将并发的小内核合并成更大的超级内核来填补GPU的利用率,从而提高利用率。Irina[150]仅在GPU总需求不超过容量的情况下,根据工作负载的GPU峰值需求来考虑安全的GPU托管情况。它假设作业完成时间没有干扰和延迟,并启发式地将新到达的作业放在具有最小JCT的GPU上。Nexus[126]还采用启发式方法来选择在同一GPU上共同定位的请求。首先,它为现有推理工作负载的吞吐量和SLO需求确定最合适的批处理大小。之后,它以最合适的方式在单个GPU上建立GPU占空比内的所有可能组合,并在不违反延迟要求的情况下最大化利用率。
Some other works introduce dynamic colocation mechanisms for managing the inference workloads. GSLICE [31] is an inference system to systematically achieve safe and efficient GPU sharing. It leverages spatial GPU multiplexing for different inference requests on top of the state-of-the-art GPU spatial multiplexing framework MPS. It intensively evaluates the colocation performance with and without MPS, and with the resource provisioning limits. It discovers that the colocation interference could be amortized under the careful configuration of the resource limits. The performance improvement reaches a point of diminishing returns (i.e., kneepoint) after certain configurations, which has a non-linear relationship with the throughput and latency of the inference. Based on these observations, GSLICE tracks the kneepoint of different inference workloads and partition the whole GPU according to their kneepoints. It also designs a hot-standby mechanism to dynamically adjust the resource limit configuration of the specific inference job, along with other implementation optimizations including minimizing the data transfer overhead. MIG-SERVING [135] leverages the hardware support for GPU virtualization (i.e., MIG [3] on NVIDIA A100[2]) for efficient GPU colocation. With MIG, an A100 card could be dynamically partitioned into several instances with smaller hardware capacities under some hard constraints. MIG-SERVING discovers that the throughput of most models does not grow linearly with the increase of resources on different instances. It establishes a reconfigurable scheduling problem and applies a generic algorithm to find a sub-optimal and feasible solution, and improve it via a search-based method.
其他一些工作介绍了管理推理工作负载的动态托管机制。GSLICE[31]是一个系统实现安全高效GPU共享的推理系统。它利用空间GPU多路复用在最先进的GPU空间多路复用框架MPS之上的不同推理请求。它集中评估了使用和不使用MPS以及使用资源供应限制时的主机托管性能。研究发现,在合理配置资源限制的情况下,可以平摊托管干扰。经过某些配置后,性能改进达到收益递减点(即膝点),这与推理的吞吐量和延迟具有非线性关系。基于这些观察,GSLICE跟踪不同推理工作负载的膝点,并根据其膝点对整个GPU进行分区。它还设计了一个热备用机制来动态调整特定推理作业的资源限制配置,以及其他实现优化,包括最小化数据传输开销。MIG- serving[135]利用GPU虚拟化的硬件支持(即,在NVIDIA A100[2]上的MIG[3])来实现高效的GPU托管。使用MIG,在一些硬约束下,可以将A100卡动态地划分为几个具有较小硬件容量的实例。MIG-SERVING发现大多数模型的吞吐量并不随着不同实例上资源的增加而线性增长。建立了一个可重构调度问题,应用通用算法寻找次优可行解,并通过基于搜索的方法对其进行改进。