华为在这2023年2月9日发布了一篇关于多元时间序列预测的文章,借鉴了NLP中前一阵比较热的Mixer模型,取代了Attention结构,不仅实现了效果上的提升,而且还实现了效率上的提高。
1. Transformer的探讨
Transformer在时间序列预测中的作用最近得到非常广泛地探讨。下图为经典Transformer时间序列预测模型图。
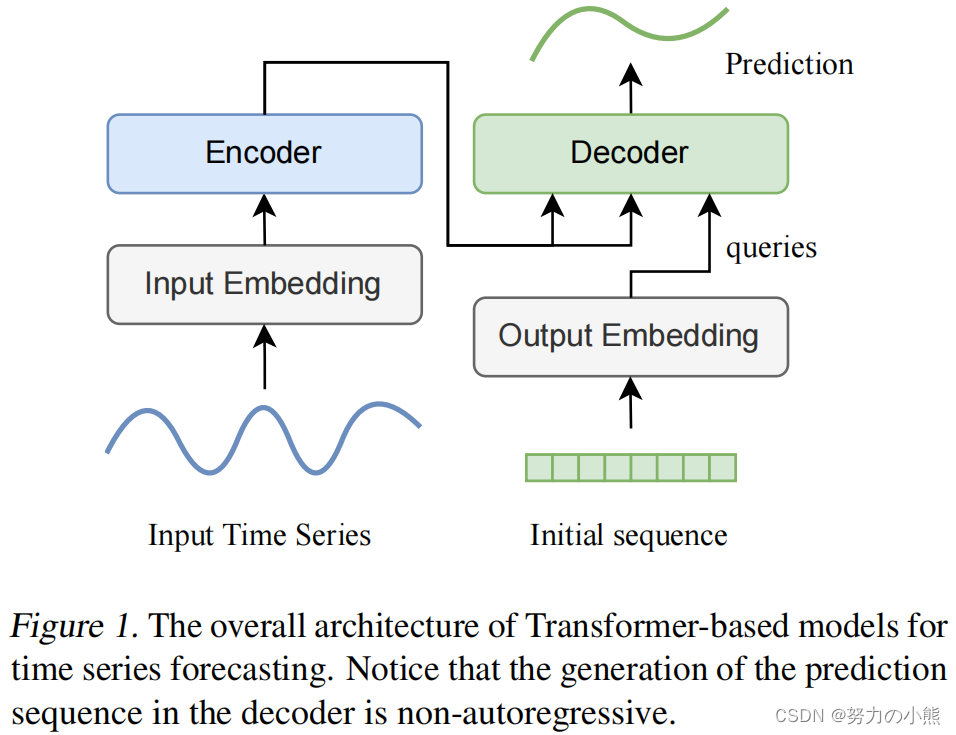
Transformer做时间序列预测时,存在以下几个问题。首先,Temporal dependency的提取是时间序列预测的关键,而Attention机制如何实现这种信息提取还没有被合理得到解释。其次,Transformer对时间特征、Position embedding有很强的依赖性,这些信息会和序列一起进入Attention模块,影响了Temporal dependency的学习。最后,Transformer模型本身的计算量很大,虽然一些工作提出了Attention的高效计算方法,但是除了Attention外,模型中还有很多其他模块计算量也很大。
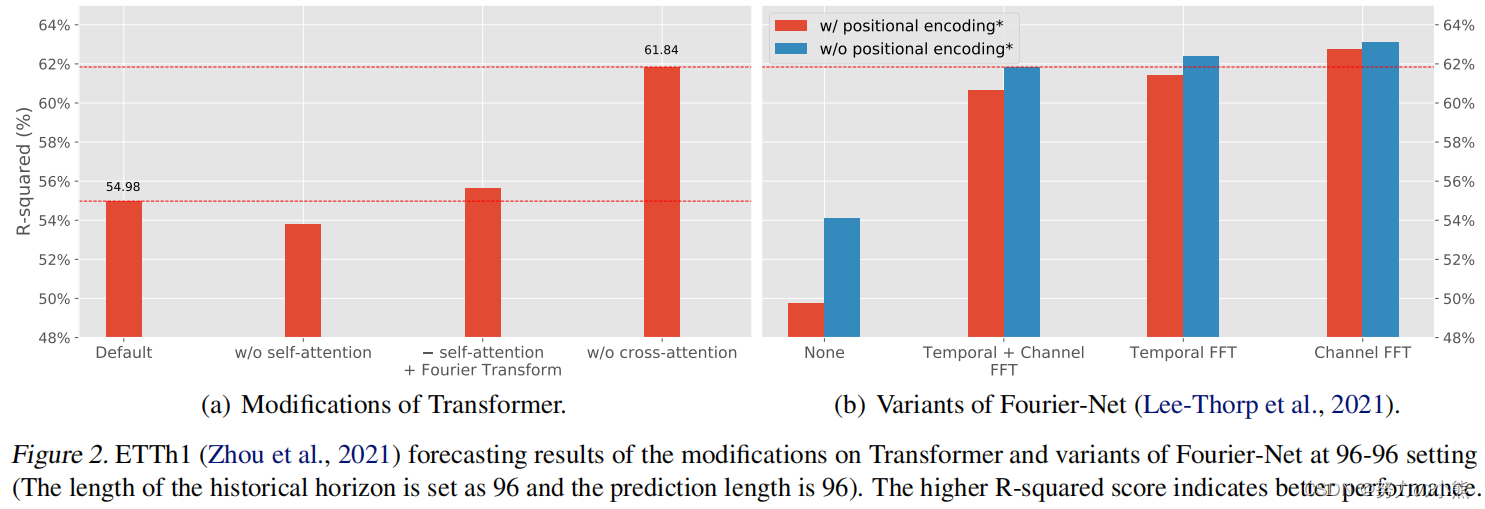
文中对比了Transformer模型和其他结构的效果差异。如果将Attention换成简单的傅里叶变换,效果是有提升的。而去掉Encoder和Decoder之间的Attention,效果反而提升非常大。这不禁让人们怀疑attention机制在多大程度上帮助了时间序列预测任务。
2. 多元时间序列的冗余性
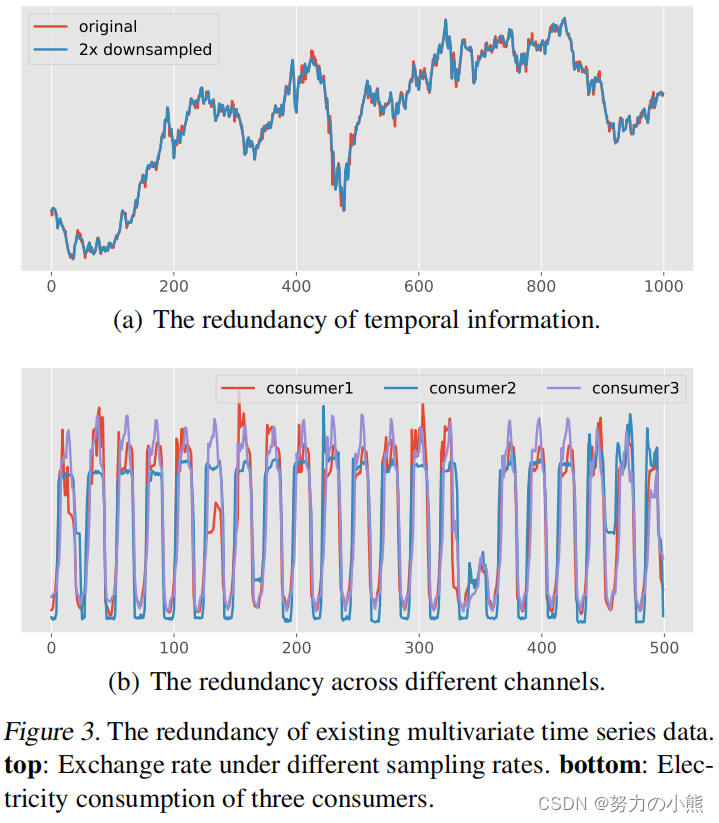
多元时间序列无论是在Temporal维度还是Channel维度,都存在比较强的冗余性。如下图所示,在Temporal维度上,对一个序列进行下采样,生成的新序列和原始序列保持着相似的趋势性、季节性。而在channel维度上,多元序列中不同的子序列也展示出相似的Pattern。这些冗余性都表明,大多数多元时间序列都存在低秩性,即只使用一小部分数据就可以表示出近似完整的原始矩阵。利用这个性质,可以简化多元时间序列的建模。
3. MTS-Mixer模型
MTS-Mixer的模型结构如下,第二列是一个抽象结构,后面3列是具体的实现方法。
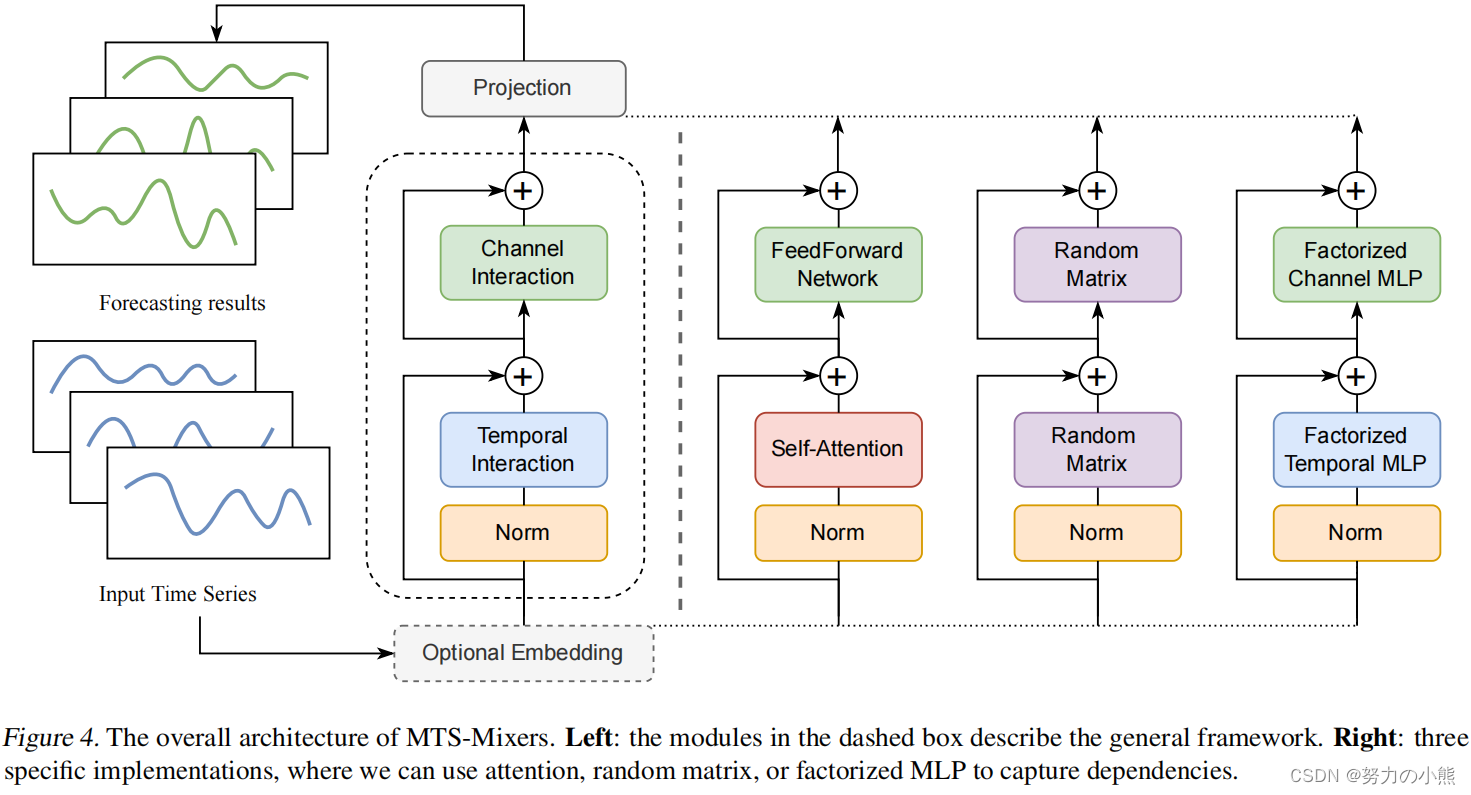
这三种实现方式的整体计算逻辑可以表示为如下形式,时间维度信息提取+空间维度信息提取+信息融合和输出映射。

第一种结构方法是基于Self-attention。这个版本基本类似Transformer,区别在于将Transformer的Decoder部分去掉了,直接改成全连接的映射。因为从之前的实验能够看到,去掉Encoder和Decoder之间的Attention效果反而是提升的。
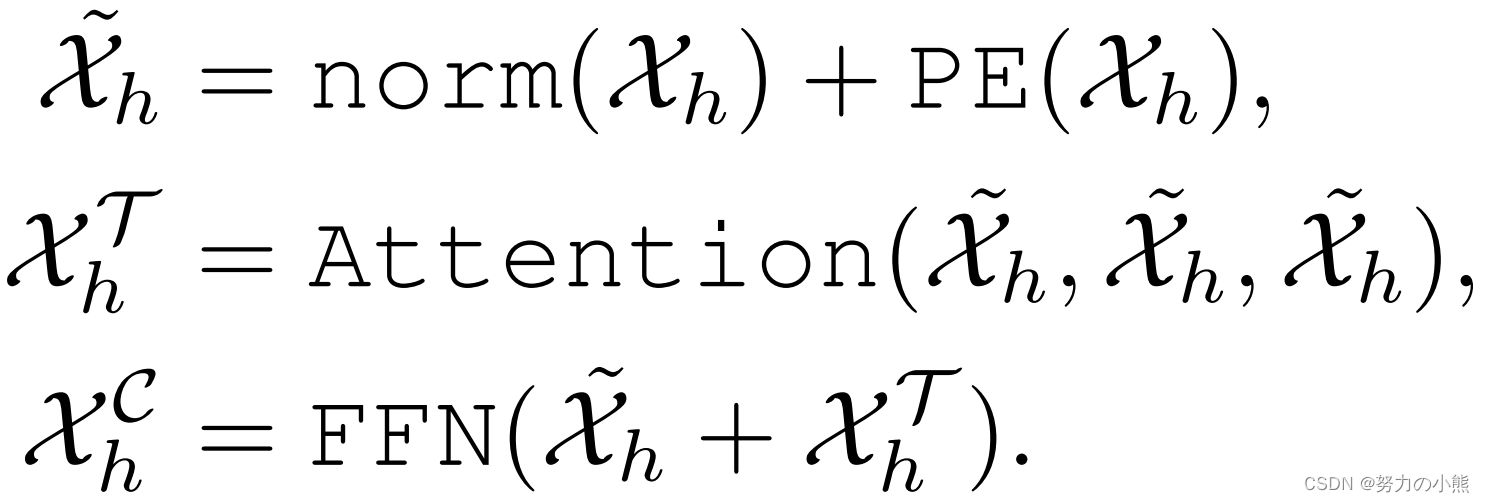
第二种结构使用的是随机初始化的矩阵。其计算公式如下,主要是将Temporal维度、channel维度使用两个矩阵进行Mixup,再加上一个输出映射矩阵。这三个矩阵都是随机初始化的。
第三种结构采用了因子分解的思路。由于上面分析的多元时间序列矩阵存在低秩性,因此文中设计了一种基于因子分解的时间维度和Channel维度的Mixup。对于时间维度的冗余性,将源时间序列拆分成多个子序列,每段子序列分别进行temporal信息的学习,然后再按原来的顺序拼接傲一起。对于Channel维度的冗余性,使用SVD分解。整个计算逻辑如下,主要就是利用全连接做Temporal维度和Channel维度的Mixup:

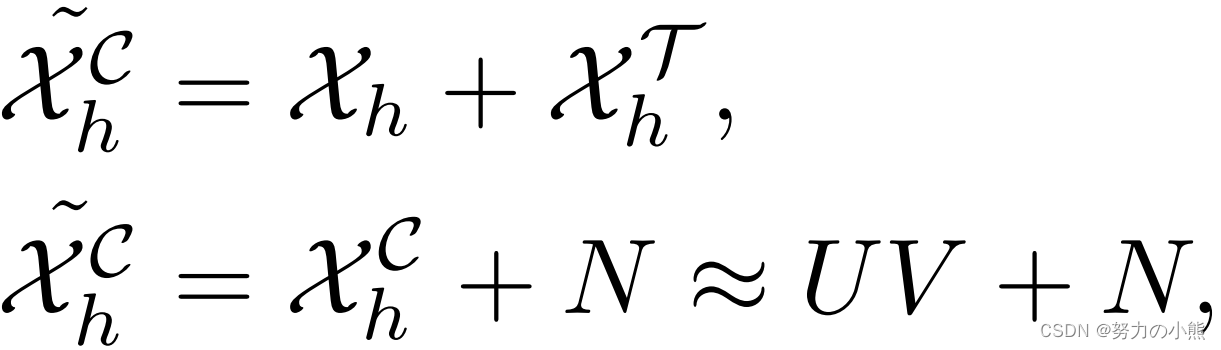
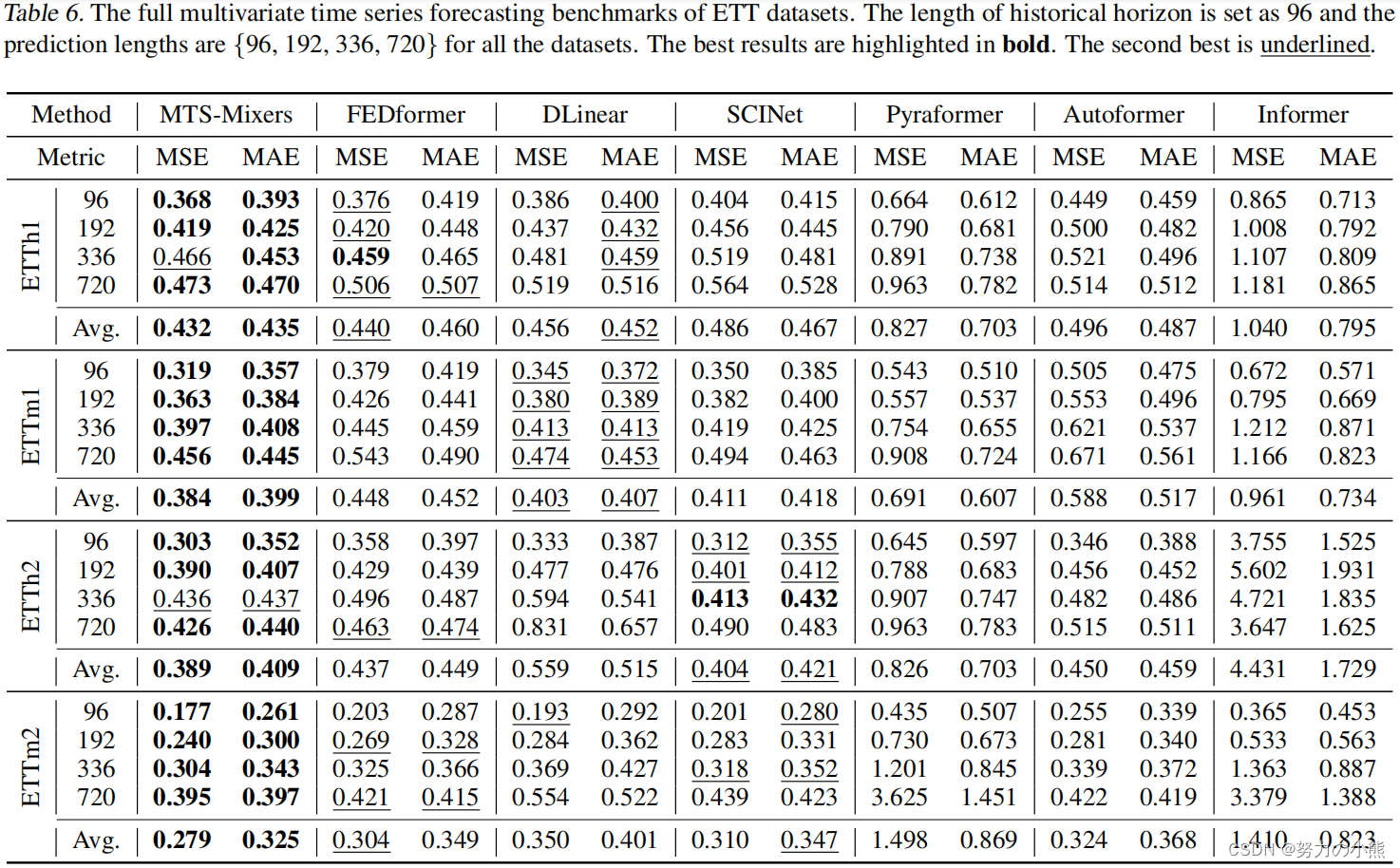
4. 实验结果
文中在多个数据集上对比了MTS-Mixer和众多Transformer模型的效果,发现即使不加Attention结构,采用文中提出的简单架构,就能取得超过Transformer的效果。
5. 结论
本文提出了MTS Mixers,这是一个多变量时间序列预测的通用框架。我们进行了一项广泛的研究,以调查注意力机制对时间序列预测性能的真正贡献和不足。实验结果表明,捕获时间相关性不需要注意,时间序列数据中的冗余会影响预测性能。此外,我们提出的时间和信道因子分解策略利用了时间序列数据的低秩特性,并在多个真实世界数据集上以更高的效率获得了最先进的结果。对模型学习到的模式的模型分析表明,输入和输出序列之间的映射可能是我们需要的关键。