Python序列结构
一、概述
分类:
- 有序序列
- 可变序列
- 列表
- 不可变序列
- 元组
- 字符串
- 可变序列
- 无序列表
- 可变序列
- 字典
- 集合
- 不可变序列
- 无
- 可变序列
可见,其实常用序列就是分三类,有序可变序列,有序不可变序列,无序可变序列
有序序列:可以通过索引去访问,支持使用切片
可变序列:可以修改其中的值,可以增加新元素或者减少已有的元素
生成器对象和range、map、enumerate、filter、zip等对象也部分支持类似于序列的操作
二、列表-有序可变序列
标准格式:
[元素1, 元素2,元素3,...... ]
特点:
- 同一个列表中元素的数据类型可以各不相同(同时包含多种数据类型的元素)
- 没有任何元素表示空列表
使用:
1)列表的创建与删除
赋值创建
使用 “ = ”将列表常量赋值给变量即可创建列表对象
a_list = ['a' , 'b', 'c']
a_list = [] #创建空列表
转换其他对象进行创建
使用list() 函数把元组、range对象、字符串、字典、集合或者 其他可迭代对象转换成列表
a = list((3,5,7,9,11)) #将元组转换为列表
print(a)
a = list(range(1,10,2)) #将range对象转换为列表
print(a)
a = list('hello world') #将字符串转换为列表
print(a)
a = list({3,7,5}) #将集合转换为列表,集合中的元素是无序的
print(a)
a = list({'a':3, 'b':9, 'c':11}) #将字典的键转换为列表
print(a)
a = list({'a':3, 'b':9, 'c':11}.items()) #将字典的元素转换为列表
print(a)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jRb0v6jL-1607835631220)(C:%5CUsers%5C%E7%99%BD%E6%98%BC%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20201124113512566.png)]
关于字典.items 方法解释:
把字典中每对 key 和 value 组成一个元组,并把这些元组放在列表中返回。
a = {'a':3, 'b':9, 'c':11}.items() print(type(a))[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4R0pBexB-1607835631228)(C:%5CUsers%5C%E7%99%BD%E6%98%BC%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20201124115452072.png)]
当一个列表不再使用时,可以使用del函数将其删除,删除之后列表无法再访问就会报错
x = [1,2,3]
del x #删除列表对象
print(x[1]) #通过索引进行访问
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-deDwYZ20-1607835631230)(C:%5CUsers%5C%E7%99%BD%E6%98%BC%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20201124141447633.png)]
2)列表元素的访问
使用整数作为下标来随机访问其中任意位置上的元素,0作为第一个元素,-1代表最后一个元素,依次类推
x = list("Hello world")
print(x[1])
print(x[-1])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cFaxcRqH-1607835631231)(C:%5CUsers%5C%E7%99%BD%E6%98%BC%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20201124142238985.png)]
3)列表的常用方法
-
操作列表元素的方法
-
append()方法
-
向列表尾部追加一个元素
-
x = [1,2,3] x.append(0) print(x) -
单参数方法
-
-
insert()方法
-
向列表中的指定位置添加一个元素,其他元素顺移
-
x = [1,2,3] x.insert(0,1) print(x) -
双参数方法,参数一为指定位置索引,参数二位增加的元素
-
-
extend()方法
-
将另一个列表中的所有元素追加到当前列表的尾部
-
x = [1,2,3] x.extend([5,6,7]) print(x) -
单参数方法,参数类型为列表
-
-
-
删除列表元素的方法
-
pop()
-
用于删除并返回指定位置上的元素,默认无参数则删除最好一个
-
x = [1,2,3] x.pop(0) print(x) -
单参数方法,参数类型为空或者索引值,也就是整形,满足索引值为负数的条件
-
-
remove()
-
用于删除列表中的第一个值与指定值相等的元素
-
x = [1,2,3] x.remove(2) print(x) -
单参数方法,参数为列表中的元素,特点是删除值相等的第一个
-
-
del “命令”
-
用于删除列表中指定位置的元素
-
x = [1,2,3] del x[2] print(x) -
命令而非方法着重注意
-
-
-
其他方法
-
count()
-
返回列表中指定元素出现的次数
-
x = [1,2,3,4,5,6,6,6,6] print(x.count(6)) -
单参数方法,对列表中元素进行计数,进行值的比较,列表中不存在这个元素则抛出异常
-
-
index()
-
返回指定元素在列表中首次出现位置的索引
-
x = [1,2,3,4,5,6,6,6,6] print(x.index(1)) -
单参数方法,参数值为元素值,获取第一次出现参数的索引
-
-
sort()
-
按照指定的规则对列表中的元素进行排序
-
import random x = list(range(11)) #取0~11的数作为列表的元素 random.shuffle(x) #打乱列表顺序 print(x) x.sort(key=lambda item:len(str(item)),reverse=True) #安装换成字符串以后的长度降序排序 print(x) -
用于列表排序,可只当排序规则
-
-
reverse()
-
将所有的元素进行翻转,第一个和倒数第一个交换位置,第二个和倒数第二个交换位置,依次类推
-
x = [10,2,3,4,5,6] x.reverse() print(x) -
reverse属于对象成员方法,没有返回值
-
-
4)列表对象支持的运算符
-
加法运算符+可以连接两个列表,返回一个新的列表
-
x = [1,2,3] x = x + [5,6] print(x)
-
-
乘法运算符*用于列表和整数相乘,表示序列重复,返回新列表
-
x = [1,2,3] x = x * 3 print(x)
-
-
成员运算符in用于测试列表中是否包含某个元素
-
x = [1,2,3] print(3 in x) -
返回布尔类型
-
-
关系运算符可以用于比较两个列表的大小
-
x = [1,2,4] y = [1,2,3,5] print(x > y) -
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yU7W31d5-1607835631233)(C:%5CUsers%5C%E7%99%BD%E6%98%BC%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20201124154239224.png)]
-
比较根据,逐个比较对应位置上的元素,直到某个元素能比较出大小,则作为整体比较的结果
-
5)内置函数对列表的操作
import random
x = list(range(11)) #生成【0,11)的列表,step默认是1
random.shuffle(x) #将列表打乱
print(all(x)) #测试是否所有的列表元素都等价于True
print(any(x)) #测试是否存在等价于True的元素
print(max(x)) #返回最大值
print(max(x,key=str)) #根据指定规则返回最大值(这里的规则是字符串)
print(min(x)) #返回最小值
print(sum(x)) #求所有元素之和
print(len(x)) #返回列表元素个数
print(list(zip(x,[1]*11))) #多个列表元素重新组合
print(zip(range(1,4))) #zip也可用于一个序列或者迭代对象
list(zip(['a','b','c'],[1,2])) #如果两个列表不等长,以短的为标准
list(enumerate(x)) #把enumerate对象转换成列表
#也可以转换成元组、集合等
关于zip()内置函数:
作用:将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,返回这些元组组成的列表。
如果各个迭代器的元素不一致,则返回列表长度与最短的对象相同,利用*号操作符,可以将元组解压为列表。
需要注意的是,zip返回的是一个对象
print(zip(x,[1]*11)) #多个列表元素重新组合 print(type(zip(x,[1]*11)))
返回的是一个zip类型的对象,如果需要展示列表则需要手动的调用list()内置函数进行转换
print(list(zip(x,[1]*11)))



三、元组-有序不可变
在Python中定义了另一种有序列表交作元组:tuple。tuple和list非常相似,但是tuple一旦初始化就不能被修改
tuple的不可变性
示例:
classmate = ('Susa','Max','lily')
classmate[1] = 'hahah'
print(classmate[1])
分析:这里的代码的含义是将元组inde为1的元素的值修改为‘hahah’,但是由于元组的不可变性(一旦初始化了就不能被修改)
结果:
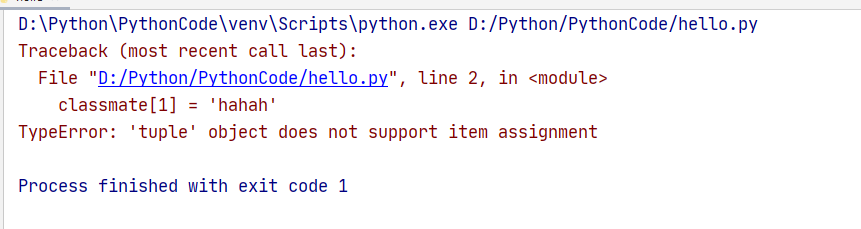
这里就会报’tuple’ obejct does not support item assignment
也就是tuple类型不支持被修改
tuple不可变就意味着代码更加的安全,如果可能,能用tuple代替list就尽量用tuple
当定义一个tuple的时候,tuple元素就必须被确定下来
因为它的不变性,相应的它也不存在那些增删改的方法
tuple的陷阱:
在定义只有一个元素的tuple,如果这样去定义:
t = (1)
那么这里定义的并不是tuple,而是1这个数,这是因为括号()既可以表示tuple,又可以表示数学公示中的小括号,这里这样就产生了起义。
所有在定义只有一个元素的元组的时候应该:
t = (1,)
添加一个逗号来消除歧义
tuple的可变性:
tuple中存储的是对象的地址,而对于基本数据类型的对象来说,数值是不可以更改的,但是如果是存储的列表或者其他对象,数值具有可变性
示例:
t = ('a','b',['A','B'])
t[2][0] = 'X'
t[2][1] = 'Y'
分析:在元组t中存储了字符串和列表,列表中存储了字符串,对于元组t来说是存储了对象的地址,但是对于列表中的元素地址并没有存储,所以可以修改列表中元素的值,这样的使用效果属于元组的可变性
换句话说,tuple的元素确实变了,但是变的不是tuple的元素,是list的元素,所以tuple所谓的不变是说,tuple的每个元素,指向永远不变,不难指向其他的对象,指向list 的地址也没变,变的是list本身
tuple的访问:
通过下标进行访问,可以二维访问
比如说
t = 'a','b',['a','b'];
print(t[2][1])
四、字典-无序可变性
dict全程dictionary,在其他语言中成为map,使用键值对进行存储,有很快的查找速度
构造方式和访问方式:
dictionary = {'lala':95,"jaja":85,"sese":66}
print(dictionary['lala'])
判断key 是否在 dict中的方法:
通过使用in关键字:
dictionary = {'lala':95,"jaja":85,"sese":66}
print('lala' in dictionary)

通过使用get方法:
如果key不存在,则会返回None,或者是自己指定的报错值,也就是get的第二个参数
dictionary = {'lala':95,"jaja":85,"sese":66}
a = dictionary.get('lalaa')
print(a)
a = dictionary.get('lalaa',-1)
print(a)
删除一个key:
通过调用pop(key) 方法,对应的value也会从dict中删除
dictionary = {'lala':95,"jaja":85,"sese":66}
dictionary.pop("lala")
优劣:
和list相比,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增多而变慢
- 需要占用大量的内存,内存浪费比较多
list的对应特点:
- 占用和插入的时间会随着元素的增加而增加
- 占用空间小,浪费内存很少
所以dict可以说是一种用空间来换取时间效率的一种方式。
注意:
dict可以用在需要告诉查找的地方,需要注意的是dict的key是不可变对象
这是因为dict根据key来计算value 的存储未知,如果每次计算相同的key得出不同的结果,那么dict的内部就完全的混乱了,这个通过key计算未知的算法称之为哈希算法
要保证hash 的正确性,作为key的对象就不能变,而在Python中不可变的数据类型比如:整数,字符串,但是list就是可变的,所以不能作为key
五、集合-无序可变性
存储一组不能重复的key,因为key不能重复。
set的创建
s = set([1,2,3])

分析:
创建一个set需要一个list作为输入集合,需要注意的是,传入的参数是一个list,而显示{1,2,3}也不表示set是有序的。
示例:
s = set([1,2,3])
print(s)
s = set([1,2,3,3,4])
print(s) #重复的元素在set的创建过程中会自动被过滤
s.add(5)
print(s) #通过add(key)的方式可以向set中添加元素
s.remove(5)
print(s) #通过remove(key)的方式可以从set中移除元素
set 可以看成数学意义上的无序和无重复元素的集合,因此set可以做数学意义上交集、并集等操作:
s1 = set([1,2,3])
s2 = set([2,3,4])
print(s1 & s2)
print(s1 | s2)
set和dict的唯一区别就在于没有存储相应的value,但是set的原理和dict一样,所以同样不可以方式可变对象,因为无法判断可变对象是否相等,也就是无法符合哈希算法,更无法保证set中不会有重复的元素。
把list放入set:
s1 = set([[1,2,3],2,3]

这个错误翻译过来就是无法匹配哈希的类型 list,也就是在set中不能放入list,因为list是可变的
理解不可变性:
为什么说字符串是不可变的对象,明明他有replace方法,会修改字符串的值
示例:
补充:
id() 内置函数将会返回对象在内存中的地址
a = 'abc'
print(id(a))
a = a.replace('a','A')
print(id(a))
效果:

对于同一变量a来说,它的值先是对象‘abc’ 然后是‘Abc’,这里a只是一个变量而并不是一个对象,它指向的对象的内容是‘abc’
当调用str.replace方法时,这个方式其实没有改变‘abc’这个对象的内容,而是创建了一个新的字符串‘Abc’并把地址返回,所以字符串对象是具有不可变性的
对于不可变对象来说,调用对象本身的任意方法,也不会改变对象自身的内容,相反这些方法会创建
理解:
写一个理解代码:
tuple = ('a','b','c') print(tuple) # tuple[1] = tuple[1].replace('b','A') tuple[1].replace('b','A') print(tuple)分析这段代码第一步我是想看看直接调用replce方法是否能修改tuple中的值,这时我以为是字符串直接调用replace函数就能修改本身对象的地址,结果也是没修改,我就先测试了replce函数
a = 'abcd' a.replace('a','A') print(a) a = a.replace('a','A') print(a)结果:
理解replace方法的机制就是读取对象值然后返回一个新的对象,直接调用不接收不会改变本身对象的值
所以replace方法就无法直接改变值
这时候我就用tuple去接收,就报错了,值不能被修改,进一步证明了不变性的本质就是存储的指向不能被修改,这个时候我就好奇Python的内存存储方式是什么。
