文章目录
Boosting算法
首先这三种算法都属于Boosting方法,且GBDT是机器学习算法,XGBoost和LightGBM是GBDT的算法实现。
Boosting方法训练基分类器时采用串行的方式,各个基分类器之间 有依赖。其基本思想是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。这个过程是在不断地减小损失函数,使得模型偏差不断降低。但Boosting的过程并不会显著降低方差。这是因为Boosting的训练过程使得各弱分类器之间是强相关的,缺乏独立性,所以并不会对降低方差有作用。
GBDT算法
Gradient Boosting是Boosting中的一大类算法,算法1描述了Gradient Boosting算法的基本流程,在每一轮迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练一个新的弱分类器进行拟合并计算出该弱分类器的权重,最终实现对模型的更新。
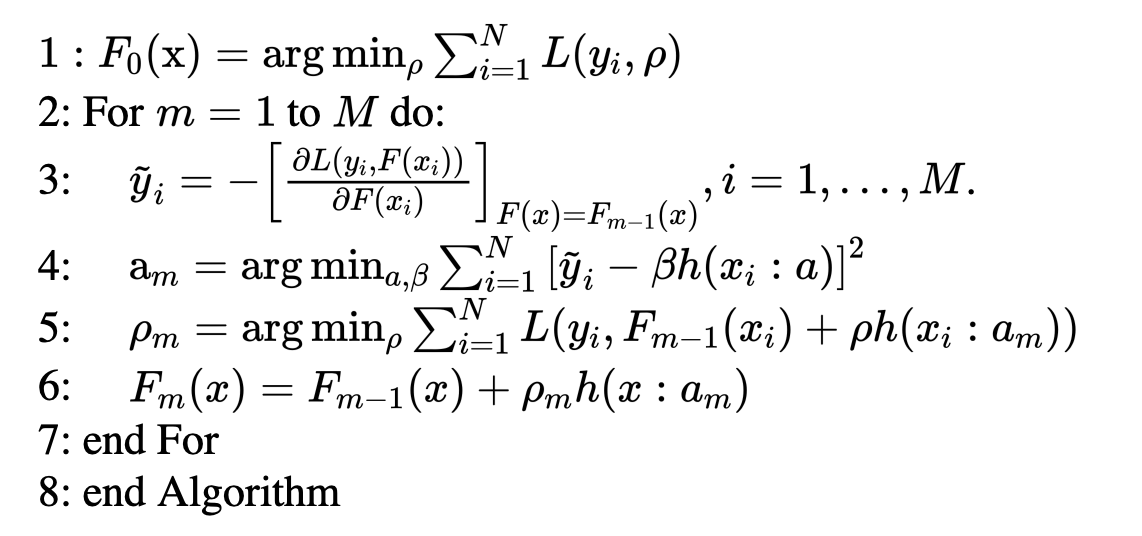
GBDT的优点
- 预测阶段的计算速度快,树与树之间可并行化计算。
- 在分布稠密的数据集上,泛化能力和表达能力都很好。
- 采用决策树作为弱分类器使得GBDT模型具有较好的解释性和鲁棒性,能够自动发现特征间的高阶关系,并且也不需要对数据进行特殊的预处理如归一化等。
GBDT的局限性
- GBDT在高维稀疏的数据集上,表现不如支持向量机或者神经网络。
- GBDT在处理文本分类特征问题上,相对其他模型的优势不如它在处理数值特征时明显。
- 训练过程需要串行训练,只能在决策树内部采用一些局部并行的手段提高训练速度。
XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进。原始的GBDT算法基于经验损失函数的负梯度来构造新的决策树,只是在决策树构建完成后再进行剪枝。而XGBoost在决策树构建阶段就加入了正则项,即
L t = ∑ i l ( y i , F t − 1 ( x i ) + f t ( x i ) ) + Ω ( f t ) L_{t}=\sum_{i} l\left(y_{i}, F_{t-1}\left(x_{i}\right)+f_{t}\left(x_{i}\right)\right)+\Omega\left(f_{t}\right) Lt=i∑l(yi,Ft−1(xi