一、网络的物理结构和光纤千兆网络
首先,我们需要知道网络的物理结构——数据是如何从一台机器传输到另外一台机器的
这个过程是非常重要的。现在很多人做软件开发,只会软件角度,这导致讲软件原理头头是道,但是连数据线都不会接,公司让组一个网络产品,网络设备要怎么买,买哪些东西,怎么组合成网络也不清楚,这严重影响软件的表现。
二、网络中的地址(IP)
并不是所有的地址都是可以用的
以0开头的地址都是不可用的
以0结尾的地址表示网段而不是具体的地址(可用但是不可访问)
224开头到239开头的地址,是组播地址,不可用于点对点的传输(组播可以理解为tcp/udp上面的广播)(组播可以极大的节约带宽,但是组播有个问题:容易形成网络风暴)
240开头到255开头的地址,是实验用的,保留,一般不做服务器地址
127.0.0.1保留的,回环网络的地址
0.0.0.0保留的,一般用于服务器监听的,表示全网段监听
32位网络地址由4个字节构成 可以表示255*255*255*255个网络地址

Network:网络地址
Host:主机地址
所以A类的网络地址(大型网络)只有7bit,所以网络内部最多容纳2^7个机器
B类地址(中型网络)只有14bit,所以最多65536个机器,然后每个最多65536个终端
C类地址(小型网络)
三、网络中的端口
公认端口(Well Known Ports):这类端口也常称之为"常用端口"。
这类端口的端口号从0 到1024,它们紧密绑定于一些特定的服务。通常这些端口的通
信明确表明了某种服务的协议,这种端口是不可再重新定义它的作用对象。
例如:80 端口实际上总是HTTP 通信所使用的,而23 号端口则是Telnet 服务专用的。443端口一般用于https服务(加密传输协议)
这些端口通常不会像木马这样的黑客程序利用。
注册端口(Registered Ports):端口号从1025 到49151。
它们松散地绑定于一些服务。也是说有许多服务绑定于这些端口,这些端口同样用于许
多其他目的。这些端口多数没有明确的定义服务对象,不同程序可根据实际需要自己定义,
如后面要介绍的远程控制软件和木马程序中都会有这些端口的定义的。
记住这些常见的程序端口在木马程序的防护和查杀上是非常有必要的。常见木马所使用
的端口在后面将有详细的列表。
动态和/或私有端口(Dynamic and/or Private Ports):端口号从49152 到65535。
理论上,不应把常用服务分配在这些端口上。实际上,有些较为特殊的程序,特别是一些木马程序就非常喜欢用这些端口,因为这些端口常常不被引起注意,容易隐蔽。
端口并非服务器才会使用,客户端也一样会使用端口
四、什么是协议
TCP 协议包头说明
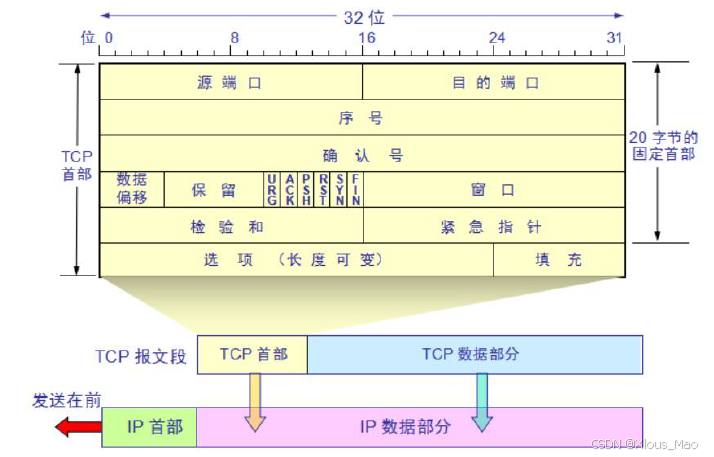
SSH 数据包头结构

协议就是一种网络交互中数据格式和交互流程的约定
通过协议,我们可以与远程的设备进行数据交互
请求或者完成对方的服务
协议就是计算机中的语言(语言就需要遵循一些规定,这些规定就是协议)
五、TCP协议的基础
传输控制协议(TCP,Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议
注意:TCP是可靠的协议(你发送了数据则一定服务器端收到了),区别于UDP协议,UDP协议是不可靠的。(可靠的代价就是牺牲了性能)
基于字节流:可以发送1个字节,或者上w个字节,数据是字节流,这个是纯字节流,没有回车什么的
交互流程:
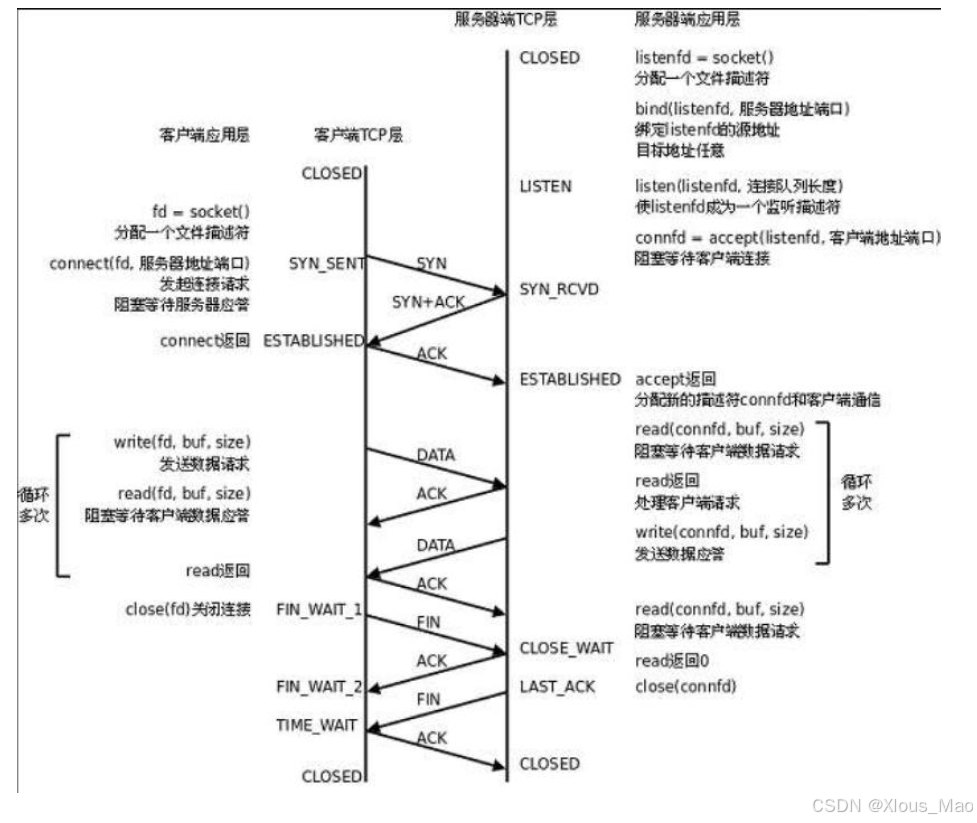
当物理连接中断过后,只有超时才能解决。默认的超时可能长达两个小时。
如何弥补呢?心跳包的机制 (除了正常的发送TCP数据之外,我们还会发送心跳包数据,每个心跳包服务器都要给予应答,这个收发的过程就表现了物理的连接,当三次没有收到应答,就表明物理连接断开了)(说人话就是:强制询问双方是否在线,如果种植,或者异常连续超过若干次(一般为三次)那么物理连接就断开了)
六、什么是套接字
网络编程就是编写程序使两台连网的计算机相互交换数据。两台计算机之间用什么传
输数据呢?首先需要物理连接。在此基础上,只需考虑如何编写数据传输软件。但实际上这
也不用愁,因为操作系统会提供名为"套接字"(socket)的部件。套接字是网络数据传输用
的软件设备(软件模块)。即使对网络数据传输原理不太熟悉,我们也能通过套接字完成数据传输。因此,
网络编程又称为套接字编程。
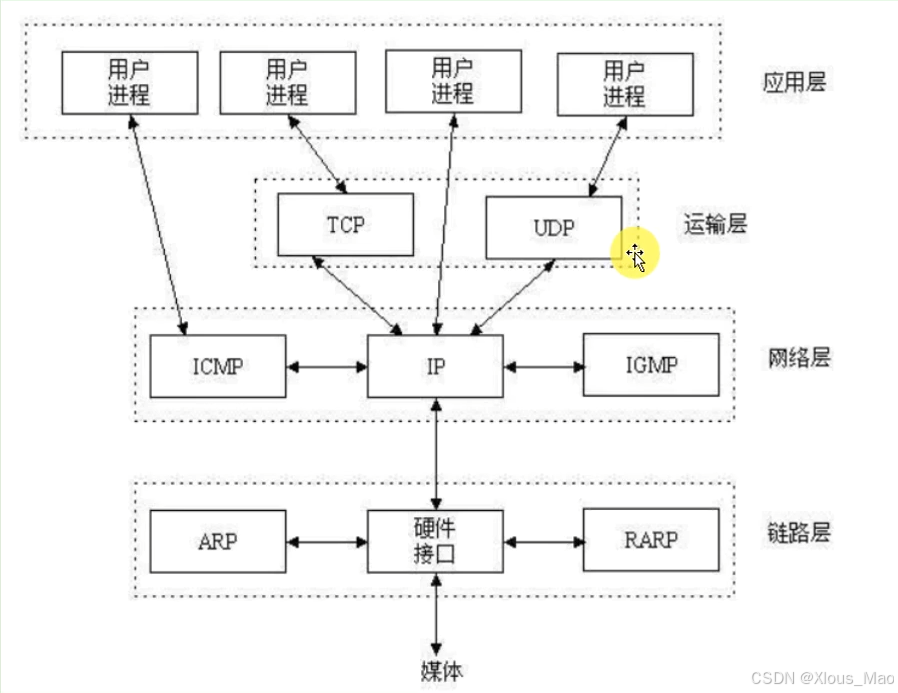
应用层: 就是程序,程序就是在应用层
网络层:解析IP(通过协议解析)
用户直接用IP协议就是原始的套接字,原始套接字在逆向和安全中可以用来伪装包头
七、套接字的创建
套接字有很多种,其中用的最多的是TCP和UDP
我们先讨论TCP 套接字。TCP套接字可以比喻成电话机。实际上,电话机也是通过固定电话网(telephone network)完成语音数据交换的。就如同于:创建一个套接字就相当于是安装了一部电话机。
#include<sys/socket.h>
int socket(int domain,int type,int protocol);
成功时返回文件描述符,失败时返回-1。
● domain 域,(包括地址协议族和协议协议族)套接字中使用的协议族(Protocol Family)信息。 (两孔或者三孔插座)
● type 套接字数据传输类型信息。 (圆孔或者方孔)
●protocol 计算机间通信中使用的协议信息(运输层和网络层的协议,不是应用层的协议(例如http、ssh))。(很复杂,由前面两个确定) (220v或者110v)
八、socket函数
参数一:domain (Protocol Family)(域)
头文件sys/socket.h 中声明的协议族

在一般的网络编程程序里面,PF_INET 对应的IPV4 互联网协议是最常用的,我们目前只需要掌握这类协议族。
参数二:套接字类型:type
套接字类型指的是套接字的数据传输方式,通过socket 函数的第二个参数传递,只有这样才能决定创建的套接字的数据传输方式。(告诉系统怎么传输这个数据)
那为什么已通过第一个参数传递了协议族信息,还要决定数据传输方式?问题就在于,决定了协议族并不能同时决定数据传输方式,换言之,socket 函数第一个参数PF_INET 协议族中也存在多种数据传输方式。
套接字类型1∶面向连接的套接字(SOCK_STREAM)---TCP
如果向socket 函数的第二个参数传递SOCK_STREAM,将创建面向连接的套接字。
什么是面向连接呢?
就如同上图一样: 数据(糖果)的传输方式有三个特点:
A 传输的过程数据不会丢失(收没收到数据是知道的)
B 按顺序传输
C 传输的过程中不存在数据边界
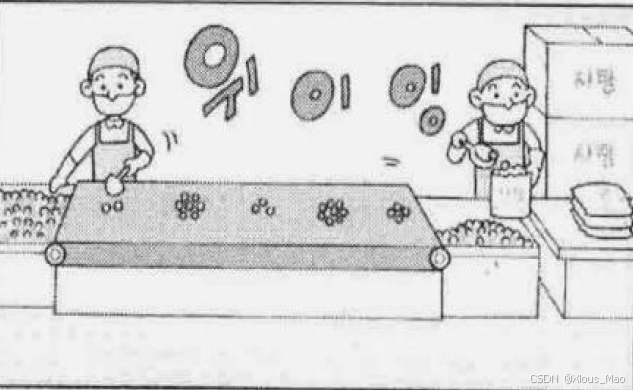
数据边界是啥?
举个例子:"100 个糖果是分批传递的,但接收者凑齐100 个后才装袋。再比如:传输数据的计算机通过3 次调用write 函数传递了100 字节的数据,但接收数据的计算机仅通过1 次read 函数调用就接收了全部100 个字节。" 收发数据的套接字内部有缓冲(buffer),简言之就是字节数组。通过套接字传输的数据将保存到该数组。因此,收到数据并不意味着马上调用read 函数。只要不超过数组容量,则有可能在数据填充满缓冲后通过1 次read 函数调用读取全部,也有可能分成多次read 函数调用进行读取。也就是说,在面向连接的套接字中,read 函数和writ 函数的调用次数并无太大意义。所以说面向连接的套接字不存在数据边界。
面向连接的套接字:
"可靠的、按序传递的、基于字节的面向连接的数据传输方式的套接字"
套接字类型2∶面向消息的套接字(SOCK DGRAM)---UDP
如果向socket 函数的第二个参数传递SOCK DGRAM,则将创建面向消息的套接字。面
向消息的套接字可以比喻成高速移动的摩托车快递。
数据(包裹)的传输方式有四个特点:
A 强调快速传输而非传输顺序
B 传输的数据可能丢失也可能损毁
C 传输的过程中不存在数据边界
D 限制每次传输的数据大小。(不能超过UDP单个包的大小,如果超过了就需要拆包)
面向消息的套接字:
"不可靠的、不按序传递的、以数据的高速传输为目的的套接字"
参数三:protocol 计算机间通信中使用的协议信息
大部分情况下可以向第三个参数传递0,
除非遇到以下这种情况∶
"同一协议族中存在多个数据传输方式相同的协议"
数据传输方式相同,但协议不同。此时需要通过第三个参数具体指定协议信息。
九、bind函数(将套接字和对应的地址端口关联)
#include<sys/socket.h>
int bind(int sockfd, struct sockaddr *myaddr, socklen_t addrlen);
成功时返回0,失败时返回-1。
调用bind 函数给套接字分配地址后,就基本完成了接电话的所有准备工作。
如果把套接字比喻为电话,那么目前只安装了电话机。
接着就要给电话机分配号码的方法,即给套接字分配IP 地址和端口号。就是用的bind 函数。
struct sockaddr *myaddr:对于这个结构体指针,实际中,我们并不会填这个指针,而是填一系列结构体的地址,因为这个地址并不是一个结构体可以说清楚点
socklen_t addrlen:这个填写上面那个参数的实际长度,用于解析第二个参数。
参数一:套接字描述符sockfd
要分配地址信息(IP 地址和端口号)的套接字文件描述符。
参数二:存有地址信息的结构体变量地址值myaddr
网络地址
4 字节地址族
IPv4(Internet Protocol version 4)
16 字节地址族
IPv6(Internet Protocol version 6)
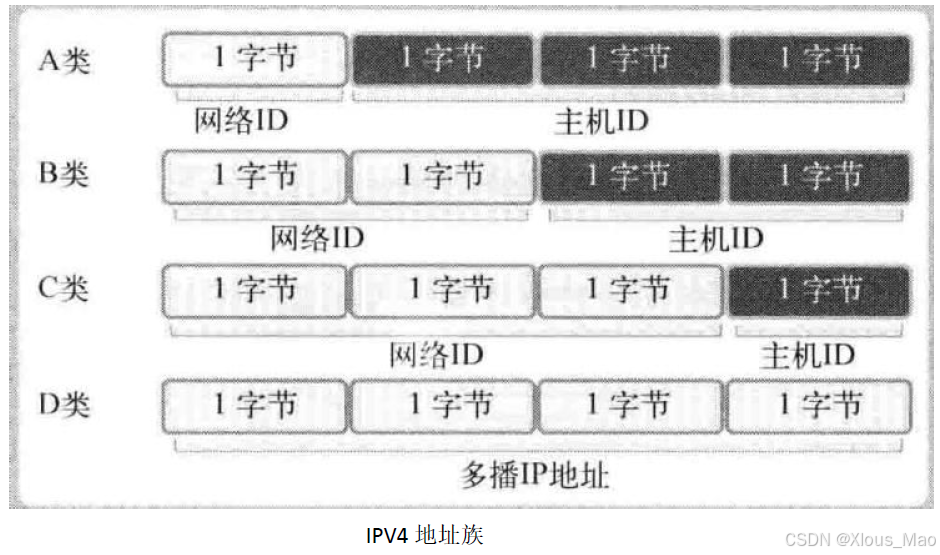
只需通过IP 地址的第一个字节即可判断网络地址占用的字节数,因为我们根据IP 地址的边界区分网络地址:
A 类地址的首字节范围∶0~127
B 类地址的首字节范围∶128~191
C 类地址的首字节范围∶192~223
A 类地址的首位以0 开始
B 类地址的前2 位以10 开始
C 类地址的前3 位以110 开始
端口
IP 用于区分计算机,端口用于在同一操作系统内为区分不同套接字而设置的,因此无法将1 个端口号分配给不同套接字。另外,端口号由16 位构成,可分配的端口号范围是0-65535。但0-1023 是知名端口,一般分配给特定应用程序。另外,虽然端口号不能重复,但TCP 套接字和UDP 套接字不会共用端口号,所以允许重复。例如∶如果某TCP 套接字使用9190号端口,则其他TCP 套接字就无法使用该端口号,但UDP 套接字可以使用。
总之,数据传输目标地址同时包含IP 地址和端口号,只有这样,数据才会被传输到最
终的目的应用程序(应用程序套接字)。
地址信息的表示
struct sockaddr_in
{
sa_family//地址族(Address Family)
sa_family_t sin_family;// //地址族(Address Family)
uint16_t sin_port; // 16 位TCP/UDP 端口号
struct in_addr sin_addr; //32 位IP 地址
char sin_zero[8]; //不使用 用于对齐
}
该结构体中提到的另一个结构体in_addr 定义如下,它用来存放32 位IP 地址。
struct in_addr
{
In_addr_t s_addr; //32 位IPv4 地址
};
成员sin_family --- 地址族(Address Family)
成员sin_port
该成员保存16 位端口号 0-65535,一般而言0-1024不要用,这一般留给系统用的
成员sin_addr

该成员保存32 位IP 地址信息,且也以网络字节序保存。为理解好该成员,应同时观察结构体in addr。但结构体in addr 声明为uint32t,因此只需当作32 位整数型即可。
成员sin_zero
无特殊含义。只是为使结构体sockaddr in 的大小与sockaddr 结构体保持一致而插入的成员。必需填充为0,否则无法得到想要的结果。
网络字节序(一般先传输低位)与地址变换
大端序(Big Endian)∶高位字节存放到低位地址。
小端序(Little Endian)∶高位字节存放到高位地址。
字节序转换:
. unsigned short htons(unsigned short);
. unsigned short ntohs(unsigned short);
. unsigned long htonl(unsigned long);
. unsined long ntohl(unsigned long);
通过函数名应该能掌握其功能,只需了解以下细节。
. htons 中的h 代表主机(host)字节序。
.htons 中的n 代表网络(network)字节序。
ntohs 可以解释为"把short 型数据从网络字节序转化为主机字节序"。
参数三:第二个结构体变量的长度
一般直接用sizeof 第二个参数就行
测试代码:
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
void lession57()
{
int sock=socket(PF_INET, SOCK_STREAM, 0);//创建一个套接字
if (sock != -1) {
struct sockaddr_in addr;
addr.sin_family = AF_INET;//地址协议族
addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //设置ip地址
addr.sin_port = htons(9527);//设置端口 主机字节序转换为网络字节序
int ret=bind(sock, (struct sockaddr*)&addr, sizeof(addr));
if (ret != 0) {
//TODO 报错
}
}
}十、listen和accept
listen 函数
#include <sys/socket.h>
int listen(int sock,int backlog);
→成功时返回0,失败时返回-1。
sock希望进入等待连接请求状态的套接字文件描述符,传递的描述符套接字参数成为服务器端
套接字(监听套接字)。
backlog 连接请求等待队列(Queue)的长度,若为5,则队列长度为5,表示最多使5 个连
接请求进入队列。
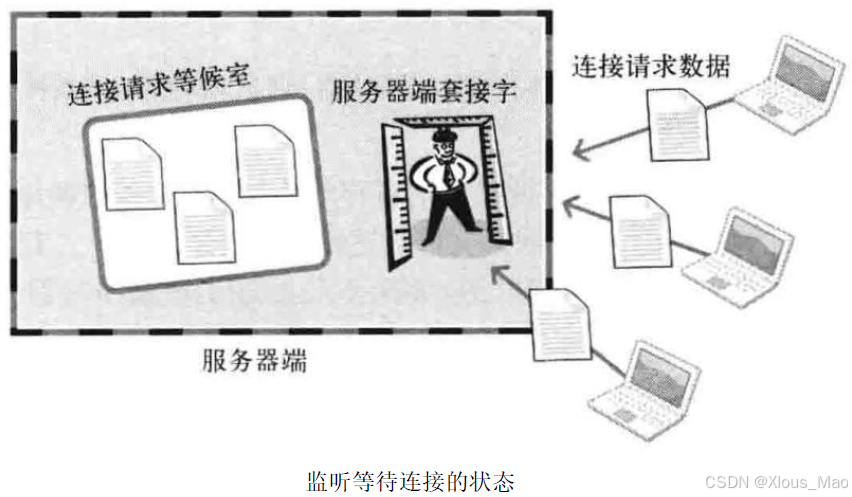
由上图可知作为listen 函数的第一个参数传递的文件描述符套接字的用途。
客户端连接请求本身也是从网络中接收到的一种数据,而要想接收就需要套接字。此任务就由服务器端套接字完成。服务器端套接字是接收连接请求的一名门卫或一扇门。
客户端如果向服务器端询问∶"请问我是否可以发起连接?"
服务器端套接字就会亲切应答∶"您好!当然可以,但系统正忙,请到等候室排号等待,准备好后会立即受理您的连接。"
调用listen 函数即可生成这种门卫(服务器端套接字)
listen函数的第二个参数决定了等候室的大小。等候室称为连接请求等待队列,准备好服务器端套接字和连接请求等待队列后,这种可接收连接请求的状态称为等待连接请求状态。
listen 函数的第二个参数值与服务器端的特性有关,像频繁接收请求的Web 服务器端至
少应为15。另外,连接请求队列的大小始终根据实验结果而定。
accept 函数
#include<sys/socket.h>
int accept(int sock,struct sockaddr * addr, socklen_t*addrlen);
accept默认是阻塞的,直到有连接进来才会返回
→成功时返回创建的套接字文件描述符,失败时返回-1。
参数sock:服务器套接字的文件描述符。
参数addr:保存发起连接请求的客户端地址信息的变量地址值,调用函数后向传递来的地址
变量参数填充客户端地址信息。(只能作为参考,因为可能通过伪装包头进行错误的信息,但正常情况下是没问题的)
参数addrlen:第二个参数结构体的长度,但是存有长度的变量地址。函数调用完成后,该
变量即被填客户端地址长度。
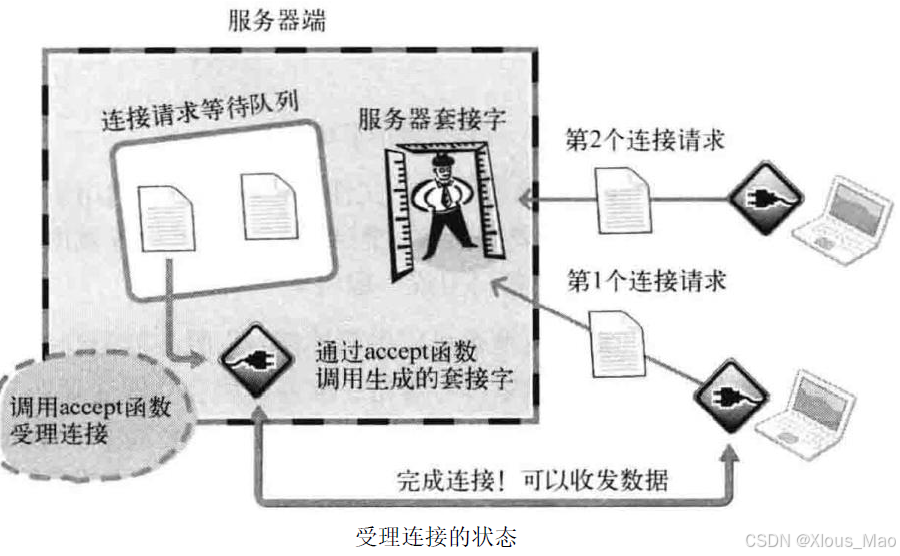
调用listen 函数后,若有新的连接请求,则应按序受理。如果在与客户端的数据交换中使用门卫,那谁来守门呢?因此需要另外一个套接字,但没必要亲自创建。此时accept 应运而生。
accept 函数受理连接请求等待队列中待处理的客户端连接请求。函数调用成功时,accept
函数内部将产生用于数据I/O 的套接字,并返回其文件描述符。套接字是自动创建的,并自动与发起连接请求的客户端建立连接。上图展示了accept 函数调用过程。