1. 概述
前提条件:linux服务器下已经安装好了docker服务。
本文档将搭建一个三台RabbitMQ的集群,包括三个RabbitMQ容器安装在同一服务器和三台不同的服务器。
2. 集群搭建
在一台服务器上创建三个RabbitMQ容器。
2.1.1. 创建容器
执行以下命令创建三个RabbitMQ容器:
# 容器1
docker run -d --hostname rabbit01 --name mq01 \
-p 5671:5672 -p 15671:15672 \
-e RABBITMQ_DEFAULT_USER=guest \
-e RABBITMQ_DEFAULT_PASS=guest \
-e RABBITMQ_ERLANG_COOKIE="javaboy_rabbitmq_cookie" rabbitmq:3-management
# 容器2
docker run -d --hostname rabbit02 --name mq02 \
--link mq01:mylink01 \
-p 5672:5672 -p 15672:15672 \
-e RABBITMQ_DEFAULT_USER=guest \
-e RABBITMQ_DEFAULT_PASS=guest \
-e RABBITMQ_ERLANG_COOKIE="javaboy_rabbitmq_cookie" rabbitmq:3-management
# 容器3
docker run -d --hostname rabbit03 --name mq03 \
--link mq01:mylink02 --link mq02:mylink03 \
-p 5673:5672 -p 15673:15672 \
-e RABBITMQ_DEFAULT_USER=guest \
-e RABBITMQ_DEFAULT_PASS=guest \
-e RABBITMQ_ERLANG_COOKIE="javaboy_rabbitmq_cookie" rabbitmq:3-management
--link:用来链接2个容器,使得源容器(被链接的容器)和接收容器(主动去链接的容器)之间可以互相通信(容器间通过容器名或容器id进行网络访问)。-e RABBITMQ_ERLANG_COOKIE:搭建集群时,节点中的Erlang Cookie值要一致,默认情况下,文件在 /var/lib/rabbitmq/.erlang.cookie,我们在用docker创建RabbitMQ容器时,可以为之设置相应的Cookie值。--hostname:设置容器的主机名,用于在搭建集群的时候指定主机。
2.1.2. 开始搭建
进入到容器mq02中,执行以下命令:
rabbitmqctl stop_app
# rabbit@rabbit01中前面的rabbit是固定值,后面的rabbit01对应mq01的hostname值
rabbitmqctl join_cluster rabbit@rabbit01
rabbitmqctl start_app然后查看集群状态:
# 查看集群状态
rabbitmqctl cluster_status执行效果

以相同的方式进入到容器 mq03 中,执行以下命令:
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbit01
rabbitmqctl start_app
此时集群已经有三个节点了,可以登录RabbitMQ实例的Web端首页查看到以下内容:
# 首页地址,以下三个节点任一节点都可以,登录账号和密码为:guest
http://192.168.1.39:15671/#/
http://192.168.1.39:15672/#/
http://192.168.1.39:15673/#/
2.2. 跨服务器
假设我们有三台服务器(确保这三台服务器可以相互ping通),三台服务器的ip地址分别是:
- 192.168.1.149(服务1,主服务器)
- 192.168.1.167(服务2)
- 192.168.1.152(服务3)
我们将在每台服务器上安装RabbitMQ服务,然后将这三个RabbitMQ服务组成RabbitMQ集群。
2.2.1. 设置主机名称
设置主机名称和ip的映射,计算机可以通过自定义的主机名称自动定位到相应的ip地址,需要在三台服务器中都设置,执行以下命令:
vim /etc/hosts可以看到和以下差不多的内容:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6在末尾再添加以下内容(例如第一行表示 主机名为node1 和 ip为192.168.1.149 的映射关系):
# node1、node2、node3分别为三台服务器主机名称,使用“hostname”即可查看服务器的主机名称
192.168.1.149 node1
192.168.1.167 node2
192.168.1.152 node3最后效果如下:

然后可以测试一下,直接ping这个主机名,效果如下:

2.2.2. 创建容器
在每一台服务上运行如下脚本:
docker run \
-d \
--net host \
--name mq01 \
-e RABBITMQ_DEFAULT_USER=guest \
-e RABBITMQ_DEFAULT_PASS=guest \
--restart=always \
rabbitmq:3-management参数释义:
--net host:以host模式启动容器,容器将共享宿主机的ip和端口-e RABBITMQ_DEFAULT_USER:设置RabbitMQ的web管理页面的登录账号,默认guest-e RABBITMQ_DEFAULT_PASS:设置RabbitMQ的web管理页面的登录密码,默认guest,集群的每个节点的账号密码需要一致--restart=always:在容器退出时总是重启容器
效果如下图:

确保每一个服务都可以打开对应的web端管理页面
# 首页地址,确保以下三个节点任一节点都可以
http://192.168.1.149:15672/#/
http://192.168.1.167:15672/#/
http://192.168.1.152:15672/#/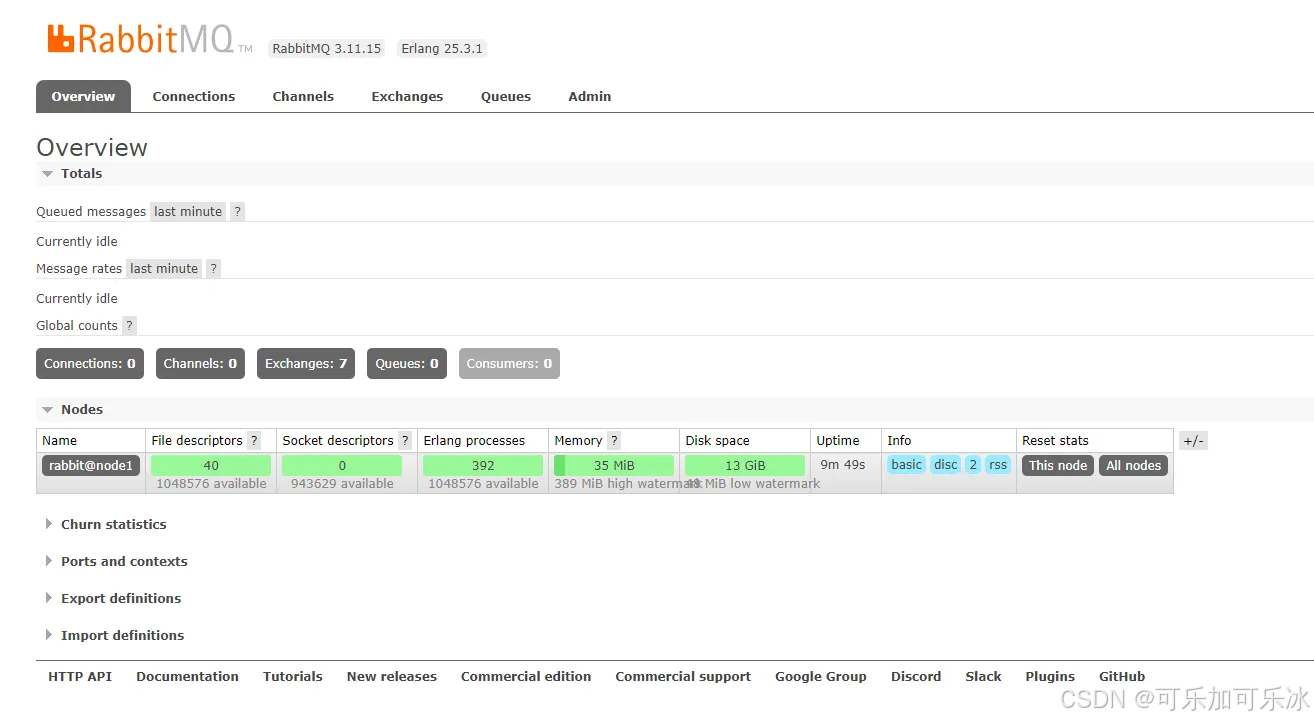
2.2.3. 查看容器端口
查看容器的端口用于排查容器启动的问题,例如端口的占用,或者后续登录或者连接服务,也需要知道端口信息,如果忘记了服务的端口,就可以使用查看端口命令来查看,如果暂时没有这方面的需求,可以暂时跳过本段。
容器启动之后会以默认端口启动,容器启动之后的效果如下:

如果想要查询容器的端口,先查询出容器的PID:

再根据PID查询端口:
netstat -anp | grep 1655
如上图,可以看出RabbitMQ服务默认启动的端口有很多,例如25672、15672、5672等。
2.2.4. 设置cookie
要使两个节点能够通信,它们必须具有相同的共享密钥,称为Erlang cookie。cookie是一串最多 255 个字符的任意字母数字字符,每个集群节点必须具有相同的cookie,我们可以将主服务的cookie文件复制到每台从服务中。
cookie文件所在目录为容器内部的/var/lib/rabbitmq/.erlang.cookie和/root/.erlang.cookie两处,如果进入目录使用ls命令查看,不要忘记加-a参数,.erlang.cookie是一个隐藏文件。
先将主服务器容器内部的cookie文件拷贝到宿主机中:
docker cp mq01:/var/lib/rabbitmq/.erlang.cookie /mydata/rabbitmq/效果如下图:

docker宿主机和容器文件相互拷贝的语法:
# 本地到服务器
docker cp 本地路径 容器id或者容器名字:容器内路径
# 服务器到本地
docker cp 容器id或者容器名字:容器内路径 本地路径再将cookie文件从主服务宿主机中拷贝到每台的从服务宿主机中:
# 利用scp工具将cookie文件从主服务宿主机中拷贝到每台的从服务宿主机中
scp /mydata/rabbitmq/.erlang.cookie root@node2:/mydata/rabbitmq/
scp /mydata/rabbitmq/.erlang.cookie root@node3:/mydata/rabbitmq/
在从服务器2和从服务器3中就可以看到这个cookie文件了:

在从服务器2和从服务器3中,将cookie文件copy到容器中,覆盖原cookie文件:
docker cp /mydata/rabbitmq/.erlang.cookie mq01:/var/lib/rabbitmq/.erlang.cookie
docker cp /mydata/rabbitmq/.erlang.cookie mq01:/root/.erlang.cookie效果如下图:
然后重启容器。
2.2.5. 加入集群
分别进入从服务器2和从服务器3,然后分别进入其容器内部,再将该节点加入集群:
# 进入指定容器命令,例如下面进入容器mq01
docker exec -it mq01 bash
# 关闭当前启动的节点
rabbitmqctl stop_app
# 将当前节点加入到集群节点node1上
rabbitmqctl join_cluster rabbit@node1
# 再开启当前节点
rabbitmqctl start_app效果如下图:
node2加入到node1中
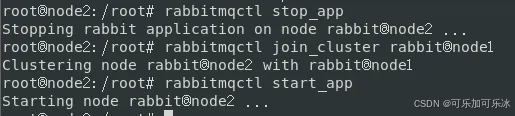
node3加入到node1中

最后登录任一节点的后台管理系统(例如node2的:http://192.168.1.167:15672/#/)查看:
注意:如果在node2或者node3节点中,执行加入集群命令的时候报错,请检查以下几点:

- 每台服务器之间是否是否可以ping通,并且通过主机名也可以ping通。
- 每个服务单独都可以启动成功,并且后台管理页面可以访问到。
- 每台从服务的两个cookie文件是否都和主服务的cookie文件一致,不要随意修改cookie文件的权限。
3. 集群容灾性测试
- 普通集群:我们创建的队列Queue,它的元数据(主要就是Queue的一些配置信息)会在所有的RabbitMQ 实例中进行同步,但是队列中的消息只会存在于一个RabbitMQ实例上,而不会同步到其他队列。
这种集群可以提高RabbitMQ的消息吞吐能力,但是无法保证高可用,因为一旦一个 RabbitMQ 实例挂了,消息就没法访问了,如果消息队列做了持久化,那么等 RabbitMQ 实例恢复后,就可以继续访问了;如果消息队列没做持久化,那么消息就丢了 - 镜像集群:它和普通集群最大的区别在于Queue数据和原数据不再是单独存储在一台机器上,而是同时存储在多台机器上。也就是说每个RabbitMQ实例都有一份镜像数据(副本数据)。每次写入消息的时候都会自动把数据同步到多台实例上去,这样一旦其中一台机器发生故障,其他机器还有一份副本数据可以继续提供服务,也就实现了高可用。
3.1. 普通集群
上面我们搭建的就是普通集群,普通集群数据只在一个RabbitMQ实例上,所以如果这个实例宕机了,
正常情况:

停止服务2
再次启动服务2,这次换停止服务3,发现消息的发送和消费还是不受影响
将服务3也还原回来,这次直接停止主节点服务1,再次调用接口
消息没有收到,发现所有的队列也直接崩了
这时候恢复服务1,发现队列就回来了
普通集群模式下,从节点并没有数据,主节点接收消息,从节点只是去主节点拉取消息,这样做来提高吞吐量,可用性并没有提高,主节点一宕机,这个集群就用不了了。





3.2. 镜像集群
3.2.1. 配置
镜像集群并不用重新搭建,只需在原来普通集群的基础上修改策略即可。
进入RabbitMQ web管理页面

新增策略
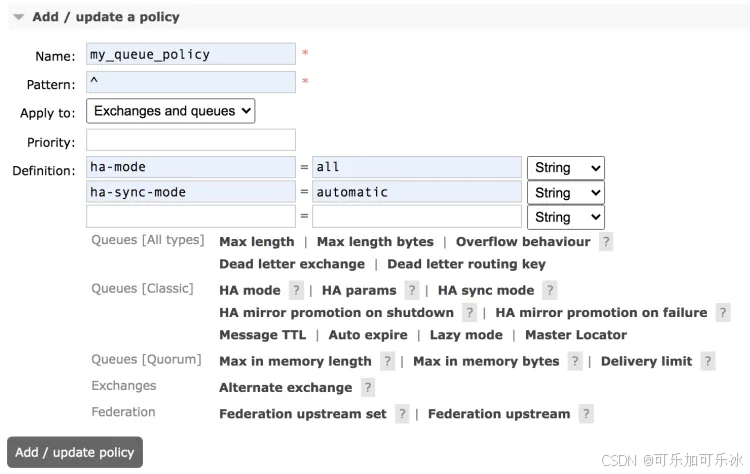
各参数含义如下:
- Name: policy 的名称。
- Pattern: queue 的匹配模式(正则表达式)。
- Definition:镜像定义,主要有三个参数:ha-mode, ha-params, ha-sync-mode。
-
- ha-mode:指明镜像队列的模式,有效值为 all、exactly、nodes。其中 all 表示在集群中所有的节点上进行镜像(默认即此);exactly 表示在指定个数的节点上进行镜像,节点的个数由 ha-params 指定;nodes 表示在指定的节点上进行镜像,节点名称通过 ha-params 指定。
- ha-params:ha-mode 模式需要用到的参数。
- ha-sync-mode:进行队列中消息的同步方式,有效值为 automatic 和 manual。
- priority 为可选参数,表示 policy 的优先级。
配置完成后,点击下面的 add/update policy 按钮
或者直接使用命令:
语法:
rabbitmqctl set_policy [-p vhost] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition}设置好之后再去看队列就可以看到末尾有+2的标志:
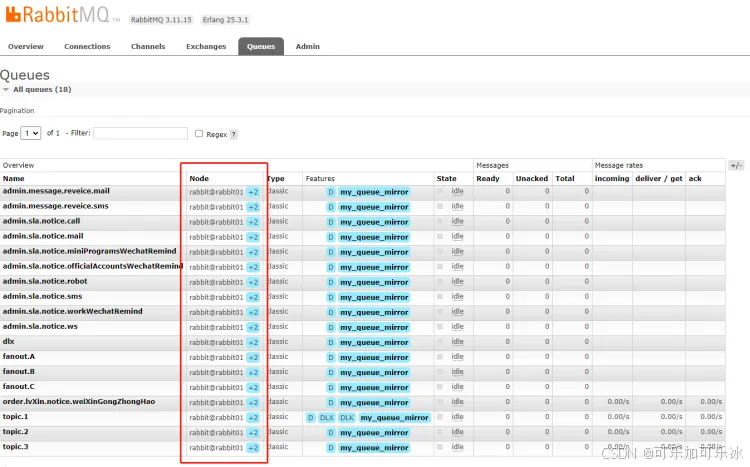
3.2.2. 测试
关闭服务2测试:服务和普通集群一样,可以正常运行;
关闭服务1测试:

这时候队列也还存在,测试消息也能正常发送和消费。
4. 连接和使用集群
1、添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>2、配置文件
spring:
rabbitmq:
addresses: 192.168.1.39:5671,192.168.1.39:5672,192.168.1.39:5673
username: guest
password: guest
# 消息重试配置
listener:
simple:
retry:
# 开启重试机制
enabled: true
# 最大重试次数
max-attempts: 60
# 最大重试间隔时间
max-interval: 60000
# 初始重试间隔时间
initial-interval: 3000
# 间隔时间乘子,当前间隔时间*间隔时间乘子=下一次的间隔时间,最大不能超过设置的最大重试间隔时间
multiplier: 2