Elasticsearch是一个分布式、高扩展、高实时的搜索与数据分析引擎。以下是对Elasticsearch的详细介绍:
一、基本概述
Elasticsearch是Elastic Stack(以前称为ELK Stack)的核心组件,Logstash和Beats有助于收集、聚合和丰富数据并将其存储在Elasticsearch中,而Kibana则提供数据可视化、探索和分享的功能。Elasticsearch能够处理各种类型的数据,包括结构化、半结构化和非结构化数据,并为其提供近乎实时的搜索和分析能力。
二、技术特点
1、分布式架构:Elasticsearch采用分布式架构,数据可以在多个节点上进行分散存储,这提高了数据的可靠性和可伸缩性。随着数据和查询量的增长,Elasticsearch可以无缝地扩展其部署规模。
2、实时性:Elasticsearch具有近实时的搜索和分析能力,数据的添加、更新和删除操作几乎可以立即生效。这使得Elasticsearch成为实时数据分析和监控的理想选择。
3、高可用性:通过复制机制和分片技术,Elasticsearch保证了数据的高可用性。即使某个节点发生故障,也能够保证系统的正常运行和数据的不丢失。
4、强大的全文检索能力:Elasticsearch使用倒排索引来实现全文检索,能够快速地搜索和过滤大量的文本数据。同时,它还提供了多种查询方式,包括全文查询、精确查询、范围查询、模糊查询等,以满足不同类型的查询需求。
5、支持多种数据格式:Elasticsearch支持多种数据格式的索引和搜索,包括结构化数据(如数据库中的表)、半结构化数据(如JSON和XML)和非结构化数据(如文本和图像)。
6、可扩展性:Elasticsearch可以通过添加新的节点来扩展系统的容量和性能,实现水平扩展。这使得Elasticsearch能够轻松应对大规模数据集和高并发查询的挑战。
三、应用场景
1、日志分析:Elasticsearch可以用于实时地收集、存储和分析大量的日志数据。它可以帮助开发人员和运维人员快速搜索和分析日志数据,以便定位和解决问题。
2、搜索引擎:Elasticsearch的全文搜索功能非常强大,可以用于构建搜索引擎。它支持复杂的查询和过滤,可以在大规模文档集合中快速地进行全文搜索。
3、实时分析:Elasticsearch可以用于实时分析大规模数据。它可以对结构化和非结构化数据进行索引和分析,支持聚合操作和复杂的数据可视化。
4、电子商务:Elasticsearch可以用于构建电子商务网站的产品搜索功能。它可以根据用户的查询实时地返回相关的产品结果,并支持过滤、排序和推荐等功能。
5、监控和告警:Elasticsearch可以用于实时监控和告警系统。它可以收集和分析各种指标和日志数据,并根据设定的规则和阈值触发告警。
6、地理空间分析:Elasticsearch支持地理空间数据的索引和查询,可以用于构建地理信息系统(GIS)和地理空间分析应用。
四、工作原理
Elasticsearch的工作原理主要基于倒排索引和分布式架构。当用户将数据提交到Elasticsearch数据库中时,Elasticsearch会对数据进行分词处理,并创建一个倒排索引。倒排索引将术语链接到文档中的位置,从而实现快速文本搜索。同时,Elasticsearch通过分片技术将数据分散存储在多个节点上,并通过复制机制增强容错能力和可用性。当用户进行查询时,Elasticsearch会根据倒排索引快速找到相关文档,并根据权重对结果进行排名和打分,最终将返回结果呈现给用户。
五、详解ES环境搭建
ES下载安装
首先我们需要下载ES压缩包
curl -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0-linux-x86_64.tar.gz
通过curl指令完成下载后,通过tar 指令进行解压:
tar -zxvf elasticsearch-7.12.0-linux-x86_64.tar.gz
完成配置后我们就可以进入bin目录,执行./elasticsearch将es启动。
查看控制台没有报错后,我们可以通过curl指令查看es是否正常运行:
curl 127.0.0.1:9200
kibana下载安装
kibana是操作es的图形界面工具,用起来非常方便,接下来我们就开始介绍一下kibana的安装步骤,我们首先到达kibana官网,找到和我们ES一致的Linux版本进行下载:
Kibana 7.12.0:https://www.elastic.co/cn/downloads/past-releases/kibana-7-12-0
完成后我们进入kibana根目录的bin目录执行./kibana将其启动。完成后我们通过浏览器访问5601端口如果出现如果进入kibana初始化界面。
在界面我们可以按需点击add data选择simple data等面板数据导入。
详解ElasticSearch和Kibana基础搜索
基础插入和查询
接下来就是正式的介绍Kibana对于ES的操作步骤了,在此之前我们先找到dev tools界面:
若我们希望通过kibana插入一条数据,我们就可以通过put指令完成,如下所示,我们指定索引名为customer,type为_doc并指定id为1的文档设置数据text为hello kibana
PUT /customer/_doc/1
{
"text":"hello kibana"
}
完成后我们可以直接通过GET指令获取对应的指令为GET /customer/_doc/1,最终查询结果如下:
查询所有
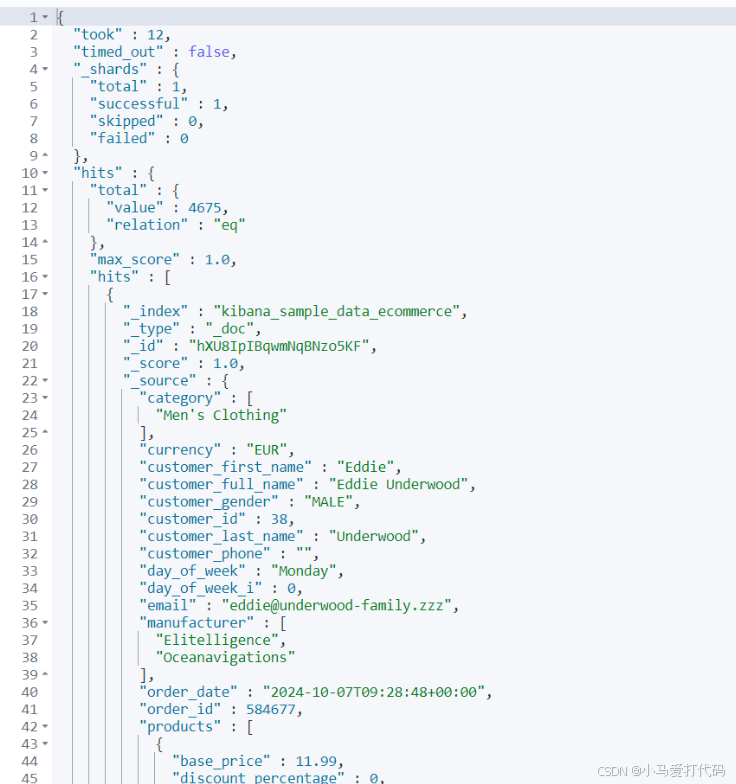
通过上一个例子我们了解了基于kibana的基础读写ES操作,接下来我们就来演示一下几种比较常见的查询,对应指令如下,可以看到我们指定导入数据的index为kibana_sample_data_ecommerce,并键入_search指令:
GET /kibana_sample_data_ecommerce/_search
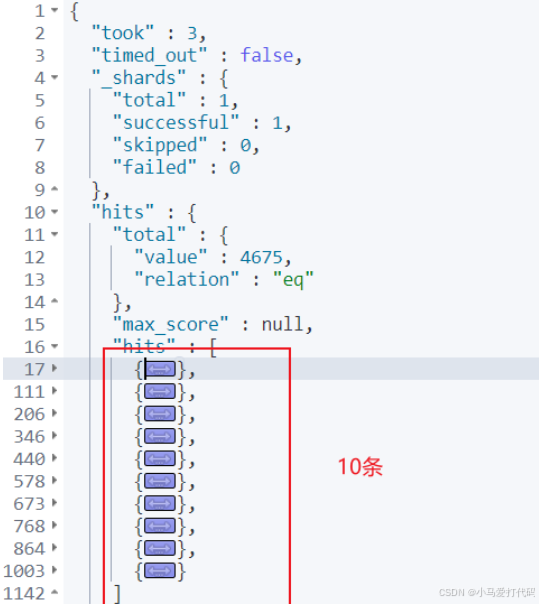
最终我们就可以看到下面这样的输出,简单介绍一下几个比较重要的字段:
- took:查询耗费时间,单位为毫秒。
- timed_out:搜索请求是否超时,这里显示false即没有超时。
- _shards:查询的分片数,并列出成功、失败、跳过的条目数。
- max_score:最匹配的一份文档的分数值。
- hits.sort:具体文档列表信息
- hits._score:具体文档的相关性得分,例如下图第一条目的文档就是1分。
分页查询
如果我们希望分页查询,则可以通过from指定起始页,通过size指定每页的大小,对应的查询示例如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_all": {} },
"sort": [
{ "email": "asc" }
],
"from": 1,
"size": 10
}
输出结果:
指定条件字段
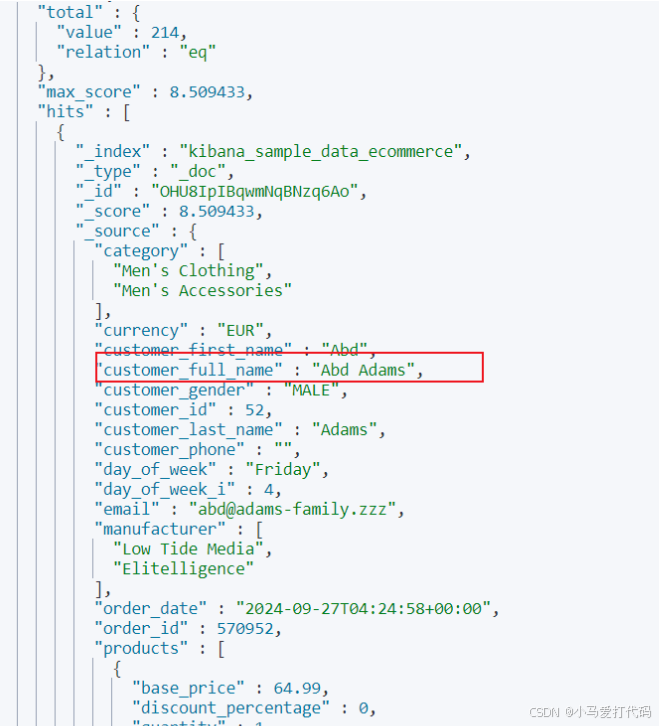
我们希望查询customer_full_name中包含Abd或者Adams中的数据,对此我们就可以通过match指明查询的字段和字段值即可:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match": { "customer_full_name": "Abd Adams" } }
}
输出结果:
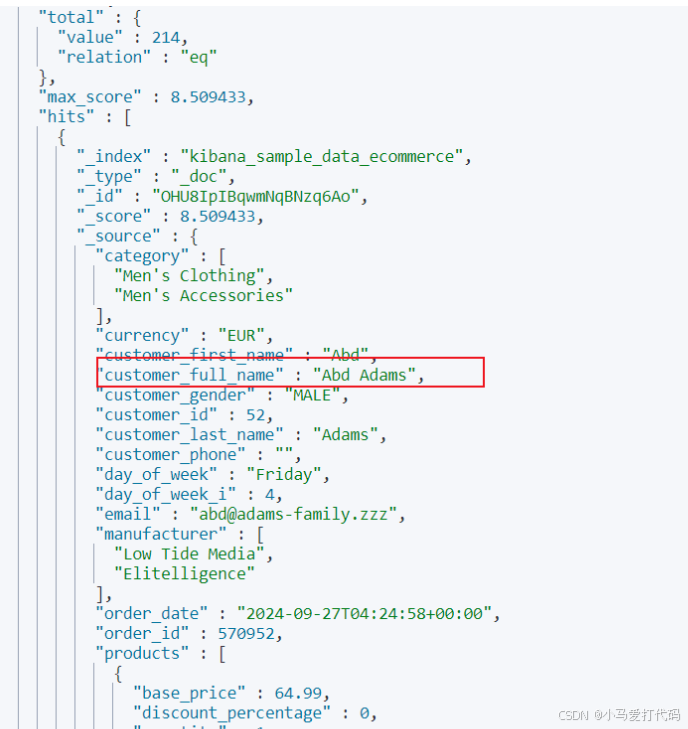
段落匹配
上一个例子是针对每一个词项进行匹配,如果我们希望查到customer_full_name中带有Abd Adams的数据,我们就可以通过段落匹配即可实现,对应的指令如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_phrase": { "customer_full_name": "Abd Adams" } }
}
输出结果:
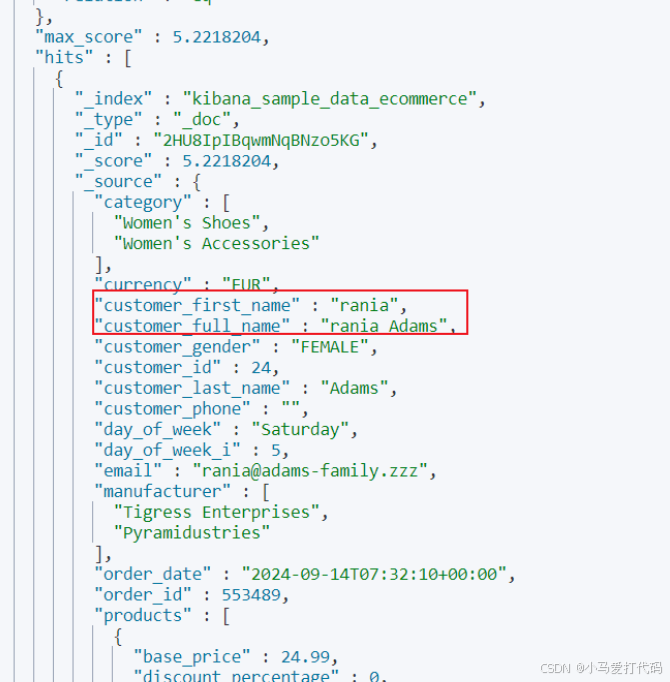
多条件查询
es支持多条件查询,例如我们希望查询customer_full_name带有Abd、Adams但是customer_first_name不包含Abd的数据,那么我们就可以指定:
- must中指明customer_full_name为Abd、Adams。
- must_not中指明customer_first_name为Abd。
对应的指令示例如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"bool": {
"must": [
{ "match": { "customer_full_name": "Abd Adams" } }
],
"must_not": [
{ "match": { "customer_first_name": "Abd" } }
]
}
}
}
输出结果:
复合条件查询
我们希望查询符合如下3个条件的数据:
- customer_full_name为Abd、Adams。
- currency为EUR。
- customer_id范围在50~55。
对此我们的编写的检索语句为:
- 指定查询为bool多条件查询。
- must通过match_phrase关键字限定customer_full_name为Abd Adams。
- filter过滤出值为EUR的currency。
- 通过customer_id限定customer_id范围为50~55。
对应的我们给出查询语句,读者可结合表述进行理解,这里笔者需要补充一点,如果查询时单单使用filter进行过滤的话,查询结果是是不会计算max_score等匹配相关的结果,得到每份文档的匹配分数还是建议使用must:
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customer_full_name": "Abd Adams"
}
}
],
"filter": [
{
"term": {
"currency": "EUR"
}
},
{
"range": {
"customer_id": {
"gte": 50,
"lte": 55
}
}
}
]
}
}
}
简单聚合查询
es同样是支持聚合操作,例如我们希望看到每个customer_full_name对应的文档数,我们就可以通过group_by_state查询指定term(词项)为customer_full_name,被聚合的字段无需对分词统计,所以使用customer_full_name.keyword对整个字段统计:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword"
}
}
}
}
输出结果:
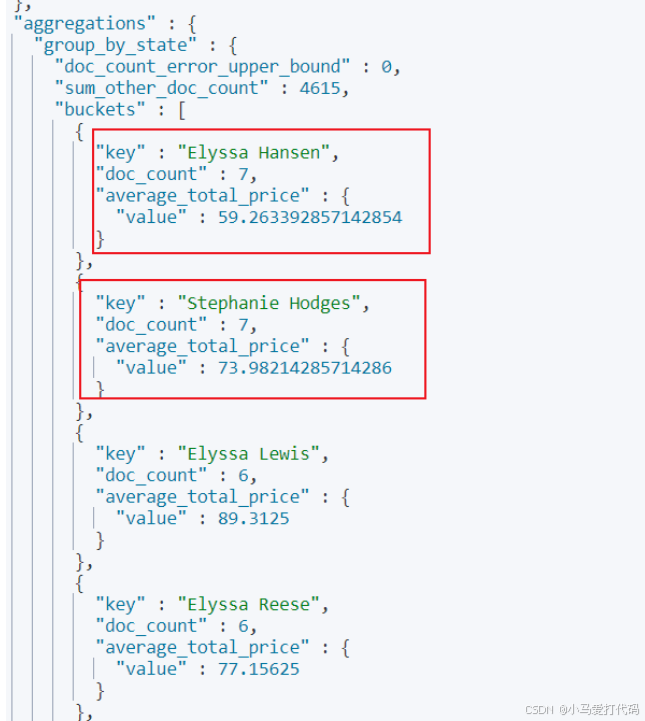
嵌套聚合
基于上述基础,我们希望查询出这每个人taxful_total_price的平均值,我们可以通过es的嵌套聚合实现,语句如下,基于上述语法基础再声明一个aggs指明avg的字段为taxful_total_price即可:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword"
},
"aggs": {
"average_total_price": {
"avg": {
"field": "taxful_total_price"
}
}
}
}
}
}
聚合结果排序查询
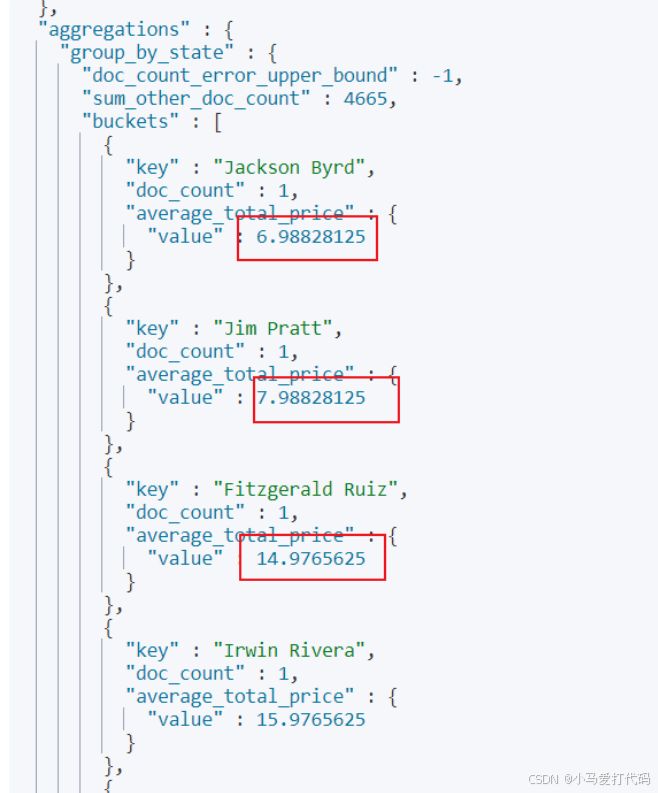
还是以上面的排序为例,如果我们希望通过taxful_total_price的结果进行升序排序的话,我们可以通过order指明使用的排序结果,以笔者本次示例来说,也就是通过average_total_price的结果进行排序,所以对应的语法如下:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword",
"order": {
"average_total_price": "asc"
}
},
"aggs": {
"average_total_price": {
"avg": {
"field": "taxful_total_price"
}
}
}
}
}
}
从结果来看,输出的数据确实是按照聚合排序数据显示: