1.merge函数拼接
-
merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=(’_x’, ‘_y’), copy=True, indicator=False) -
how:指的是合并(连接)的方式有inner(内连接),采用内连接,连接两边都有的值left(左外连接)取左表所有数据,right(右外连接),outer(全外连接)outer外连接时,会取并集,并用NaN填充;默认为inner
-
on : 指的是用于连接的列索引名称。必须存在右右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键
-
left_on:左则DataFrame中用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。
-
right_on:右则DataFrame中用作 连接键的列名
-
left_index:使用左则DataFrame中的行索引做为连接键
-
right_index:使用右则DataFrame中的行索引做为连接键
-
sort:默认为True,将合并的数据进行排序。在大多数情况下设置为False可以提高性能
-
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’,’_y’)
-
copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能
-
indicator:在 0.17.0中还增加了一个显示合并数据中来源情况;如只来自己于左边(left_only)、两者(both)
-
a表和b表相同列的索引名称不同,可以通过指定left_on,right_on来进行合并
-
left_on 左表的索引值 即:b,right_on右表索引值 即:a
-
indicator 显示数据来源 both 公有的
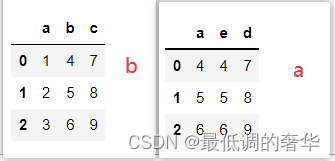
c = pd.merge(b,a,left_on='b',right_on='e',indicator=True)
c
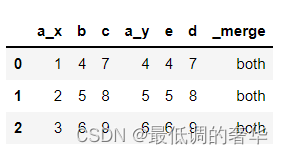

- 有共同列并且列索引相同 on = ’ b ’
c = pd.merge(b,a,on='b',sort=False,indicator=True)
c

- 索引名称进行连接
c = pd.merge(b,a,left_index=True,right_index=True,sort=False,indicator=True)
c
2.concat函数拼接
-
pd.concat(
objs: Union[Iterable[ForwardRef(‘NDFrame’)], Mapping[Union[Hashable, NoneType], ForwardRef(‘NDFrame’)]],
axis=0,
join=‘outer’,
ignore_index: bool = False,
keys=None,
levels=None,
names=None,
verify_integrity: bool = False,
sort: bool = False,
copy: bool = True,
) -
axis=0 行拼接 axis=1 列拼接
-
ignore_index = True 合并后重新索引
-
join = ‘inner’ 内连接取交集 (交集为含有列索引名称相同的合并) ‘outer’ 外连接取并集(如果不存在时自动填充为nan)
-
keys 说明数据的来源
-
sort 排序
-
1.以列进行左右连接
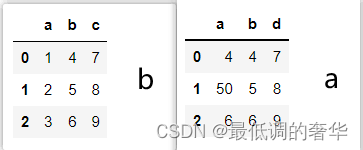
c = pd.concat([a,b],axis=1,keys=['a','b'],names=['ll','kk'])
c

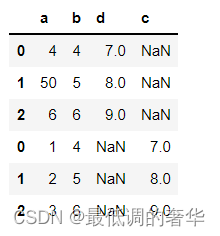
- 2.取并集,
c = pd.concat([a,b],join='outer')
c
3.numpy中concatenate()函数拼接
a = np.array([[11, 22], [33, 44]])
a
>> array([[11, 22],
[33, 44]])
b = np.array([[55, 66]])
b
>> array([[55, 66]])
- 俩个数组上下拼接
np.concatenate((a, b), axis=0)
array([[11, 22],
[33, 44],
[55, 66]])
- 俩个数组左右拼接(把b表先转置)
b.T
array([[55],
[66]])
np.concatenate((a, b.T), axis=1)
array([[11, 22, 55],
[33, 44, 66]])
- 每一个元素增加[]
a[:,np.newaxis]
array([[[11, 22]],
[[33, 44]]])
- 给最外层增加一个[]
a[np.newaxis,:]
array([[[11, 22],
[33, 44]]])
- 数组最后一列添加一列
c = np.array([[11,22,33],[44,55,66],[77,88,99]])
c
array([[11, 22, 33],
[44, 55, 66],
[77, 88, 99]])
c = np.column_stack((c,np.arange(1,4)))
c
array([[11, 22, 33, 1],
[44, 55, 66, 2],
[77, 88, 99, 3]])
- 数组最后一行添加一行
c = np.row_stack((c,np.arange(1,4)))
c
array([[11, 22, 33],
[44, 55, 66],
[77, 88, 99],
[ 1, 2, 3]])