📖标题:QWEN2 TECHNICAL REPORT
🌐来源:arXiv, 2407.10671
🛎️文章简介
论文首先介绍了Qwen2模型的设计和评估方法,然后介绍了在多个基准数据集上的性能表现,最后提供了模型的开放资源和应用。
📝重点思路
🔺模型设计
🔸分词器:继Qwen之后,采用基于字节级字节对编码的相同分词器,具有较高的编码效率,相对于其他方案具有更好的压缩率,整个词表包含151643个常规token和3个控制token。
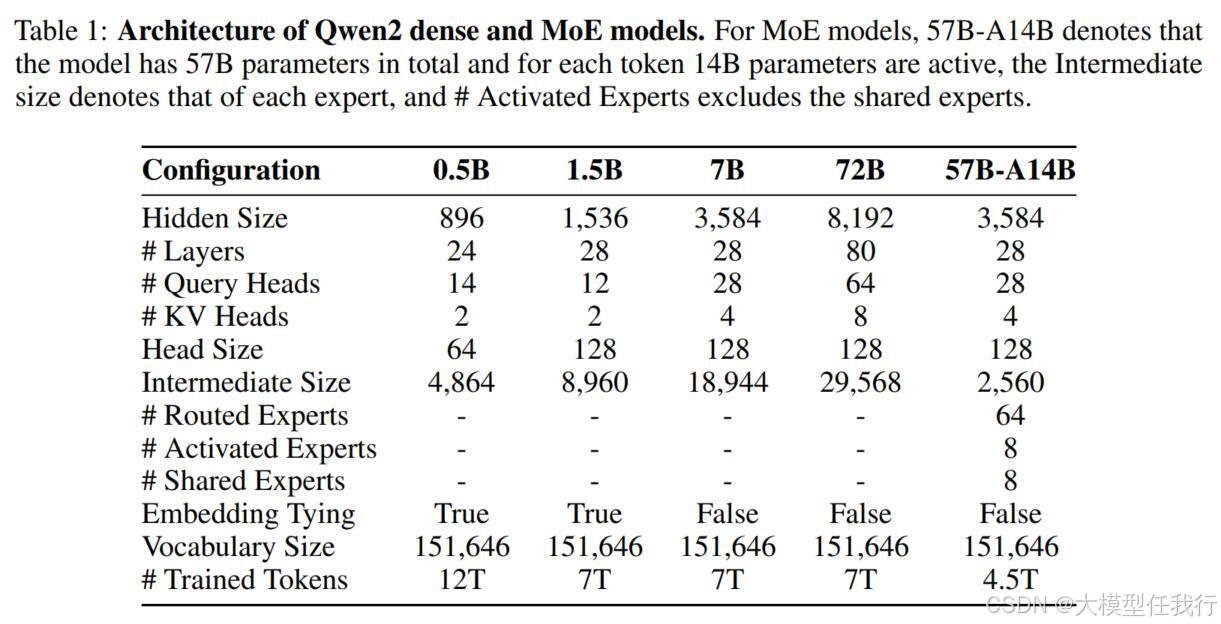
🔸模型架构:基于Transformer的GQA自注意力,该系列包含4个尺寸的密集语言模型和专家混合 (MoE) 模型。
🔺预训练
🔸语料:比之前的Qwen和Qwen1.5中使用的语料库有所改进,通过质量增强、数据扩展和分布改进,优化了预训练数据的规模、质量和多样性。
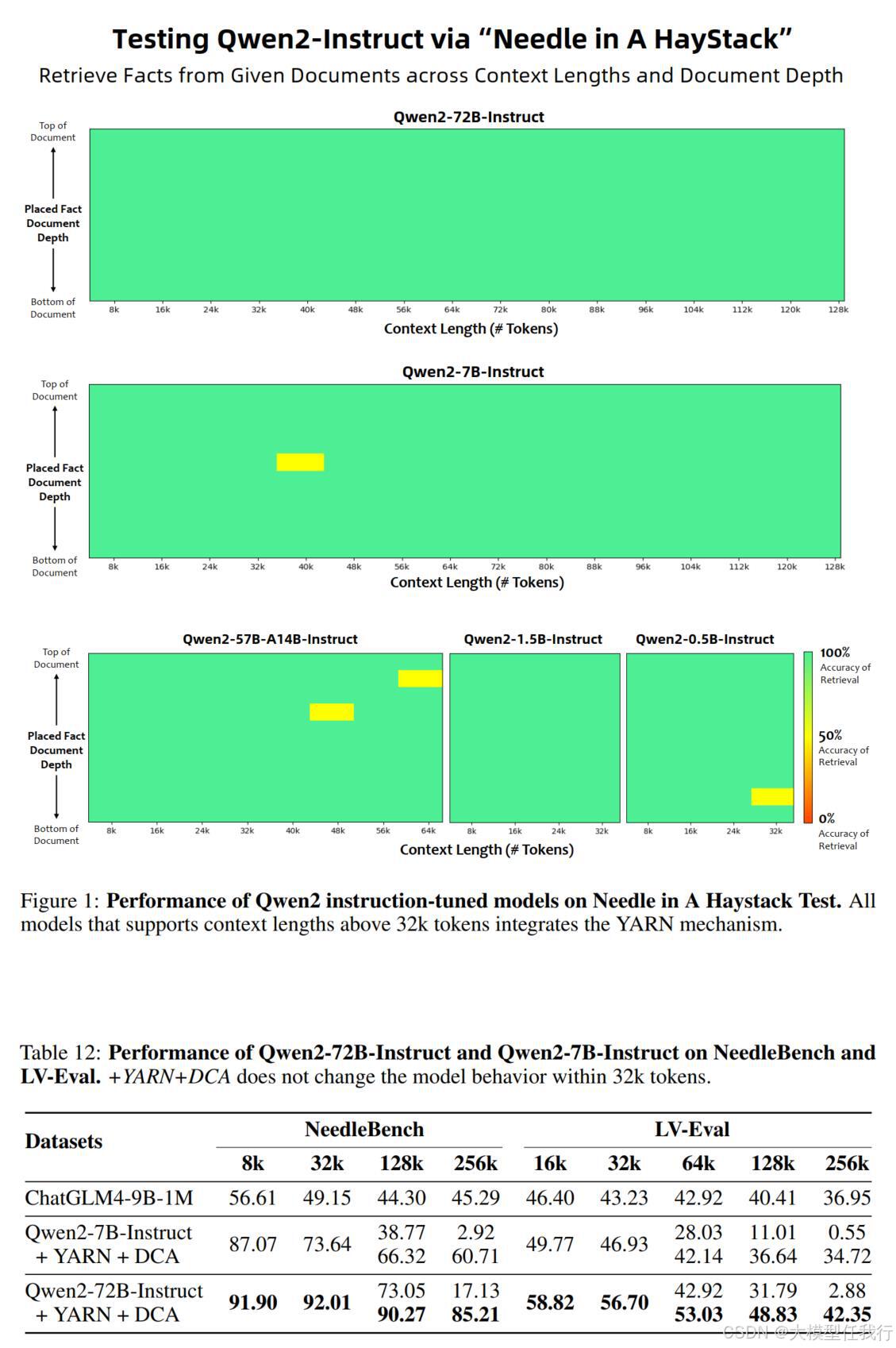
🔸长文本:在预训练的最后阶段将上下文长度从4096个标记增加到32768个标记,RoPE的基本频率从10000修改为1000000,采用了YARN机制增强长度外推潜力。这些策略使模型能够处理多达131072个标记的序列,同时保持高性能。
🔺后训练
🔸数据:通过协作数据注释(自动本体提取、指令选择、指令进化和人工注释)和自动数据合成(拒绝采样、执行反馈、数据再利用和宪法反馈)两阶段,构建示例数据和偏好数据,覆盖成代码、数学、指令遵循、创作、角色扮演和安全领域。
🔸SFT:在超过500000个示例上通过两阶段微调,应用学习率衰减优化学习过程。
🔸RLHF:通过离线和在线两阶段训练,并采用在线合并优化器来减轻对齐性能下降。
🔺评估
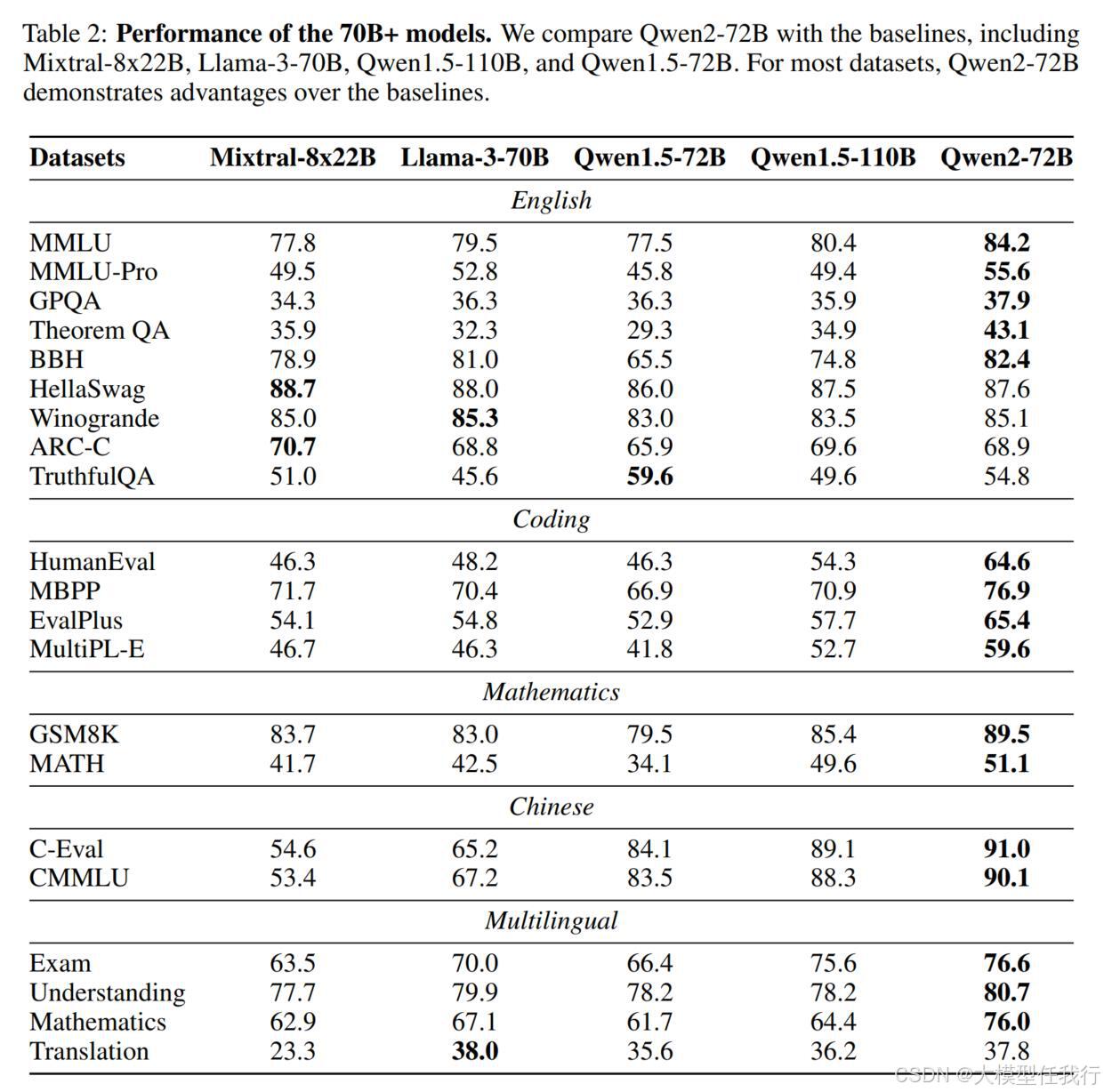
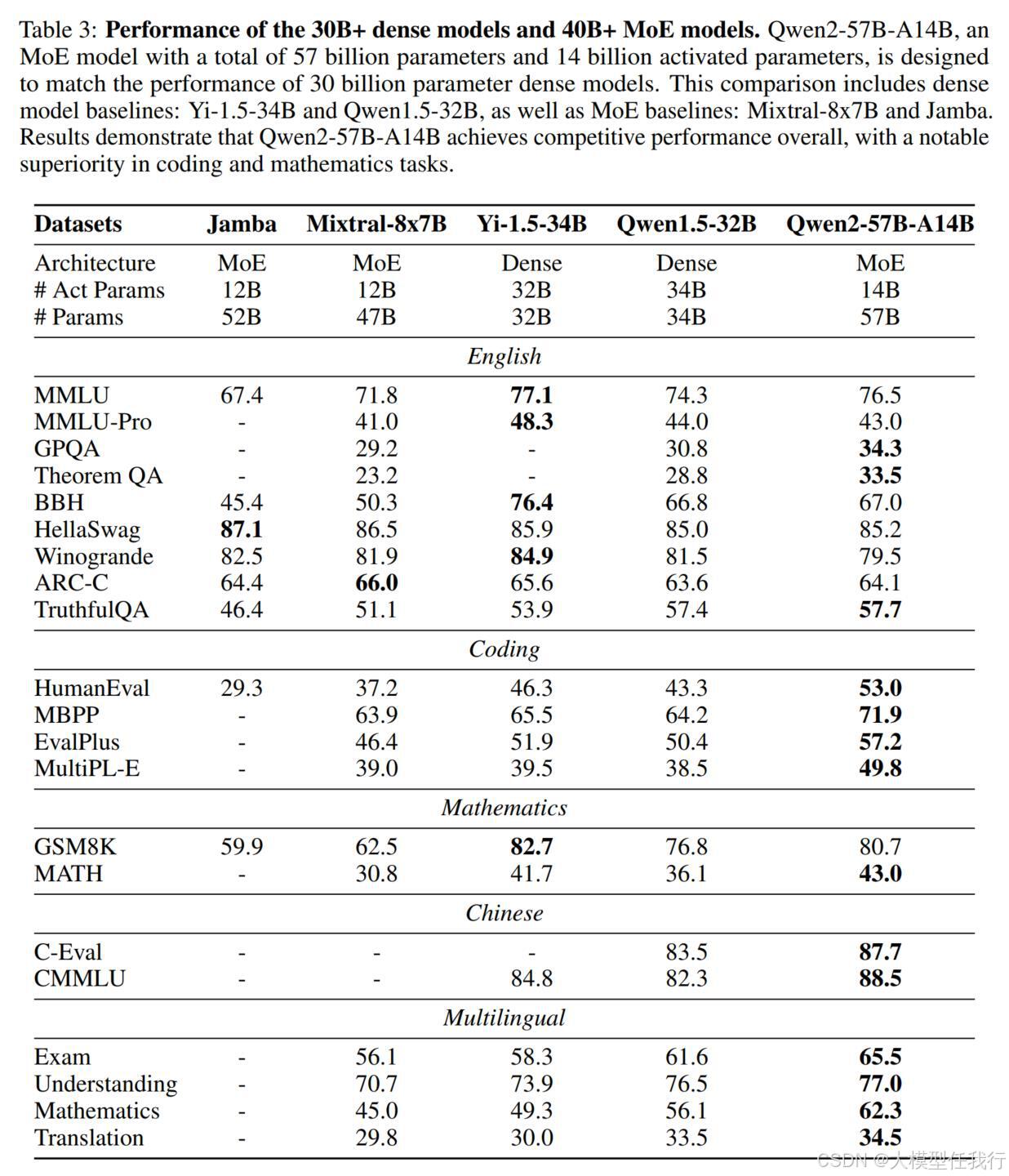
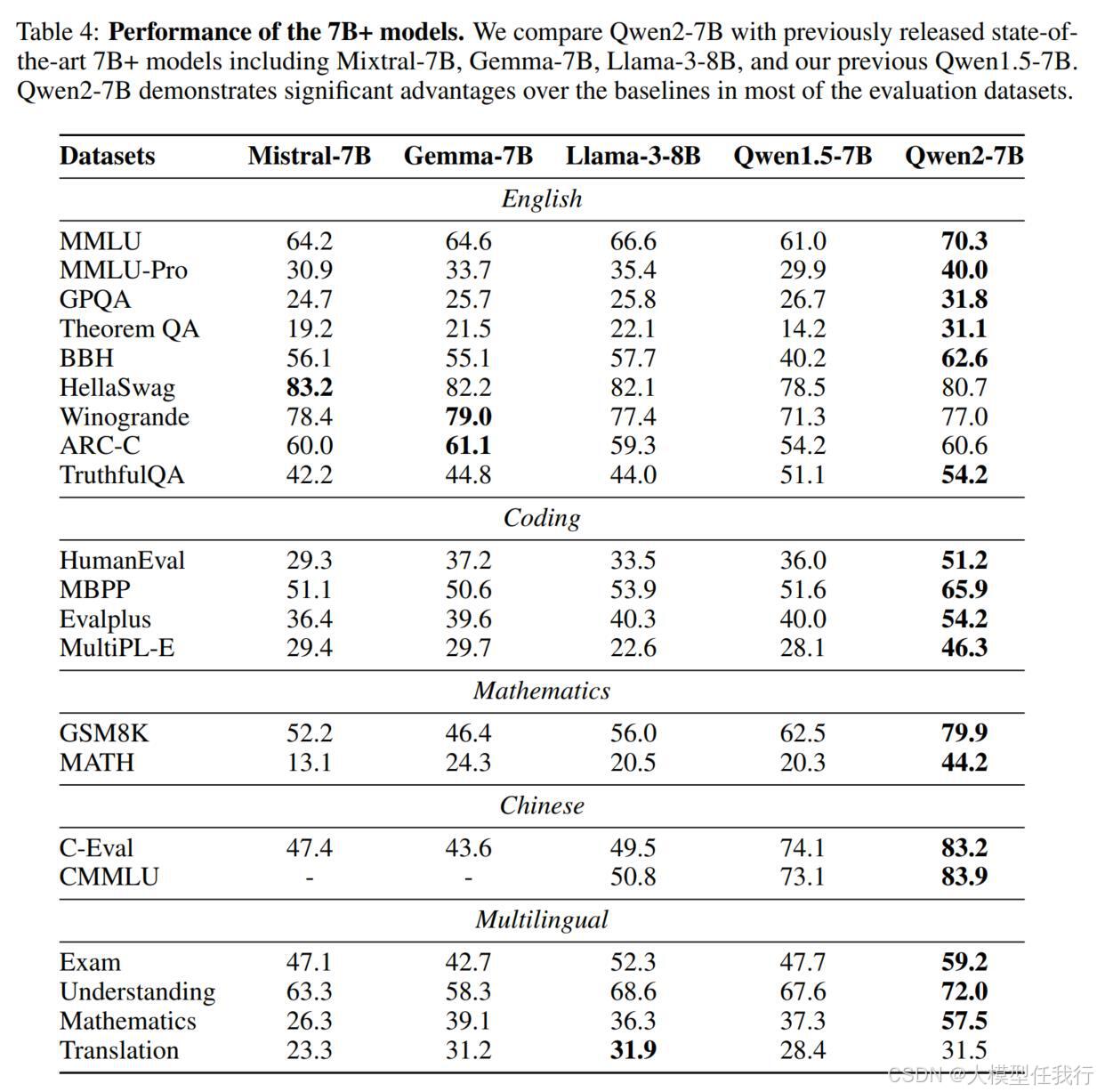
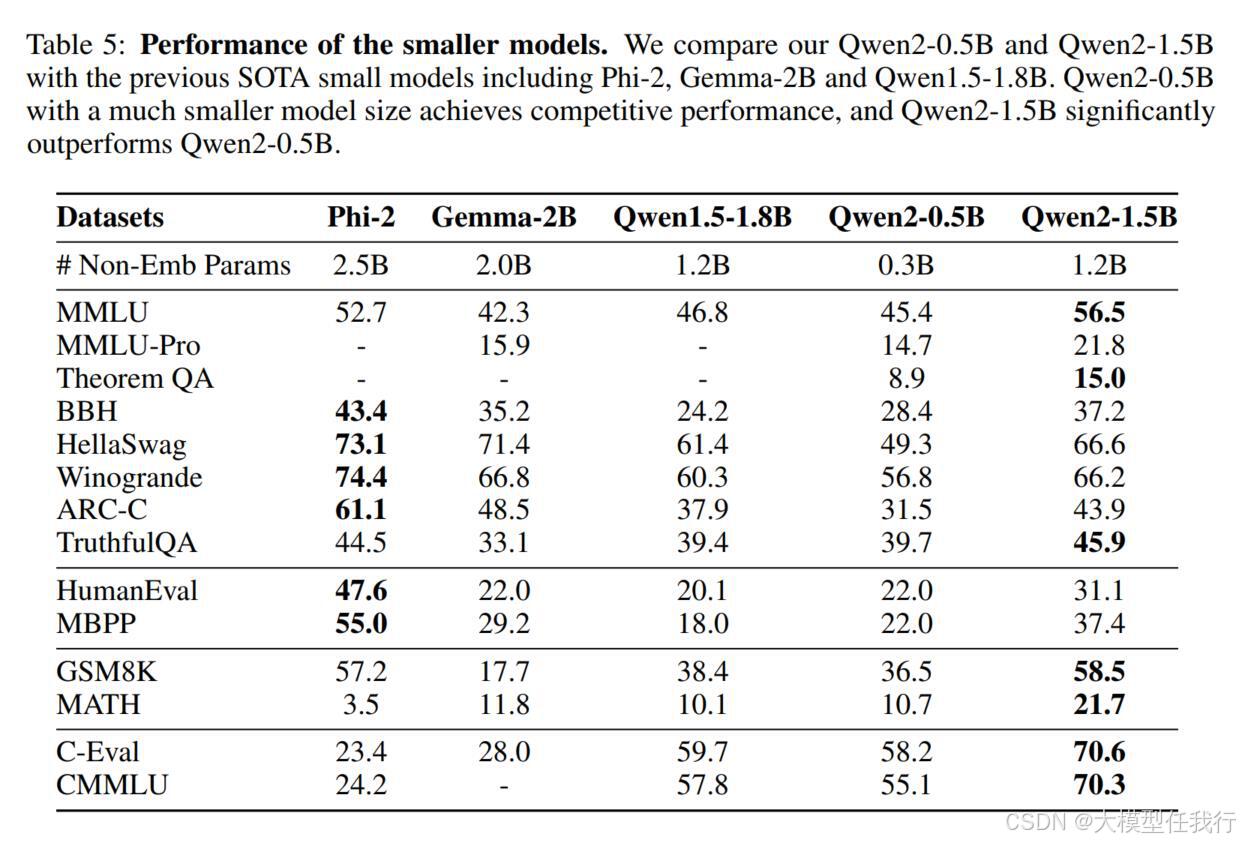
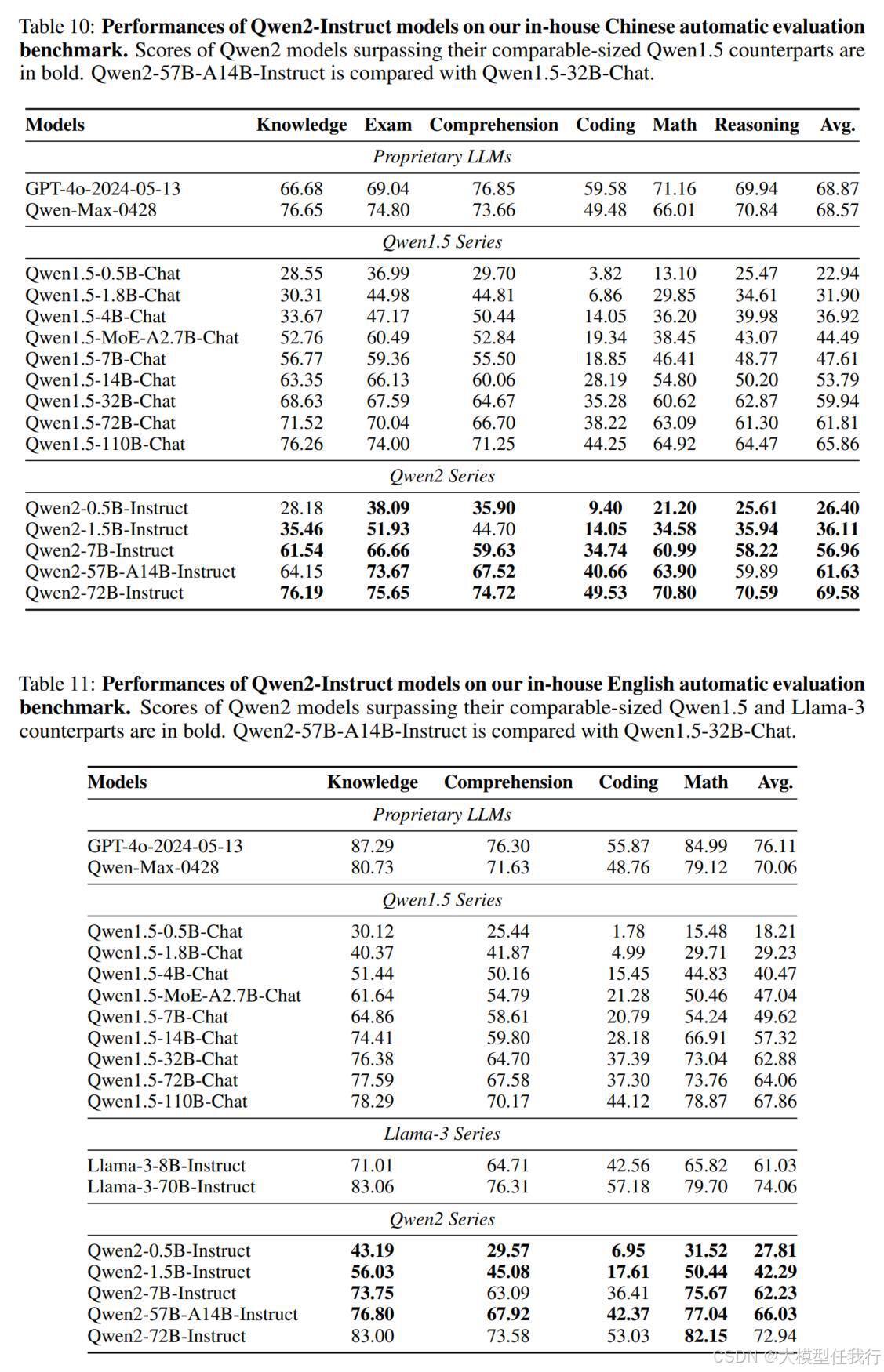
🔸基础模型:在基准数据集上评估模型的知识和基本能力,并评估其对多语言的支持。
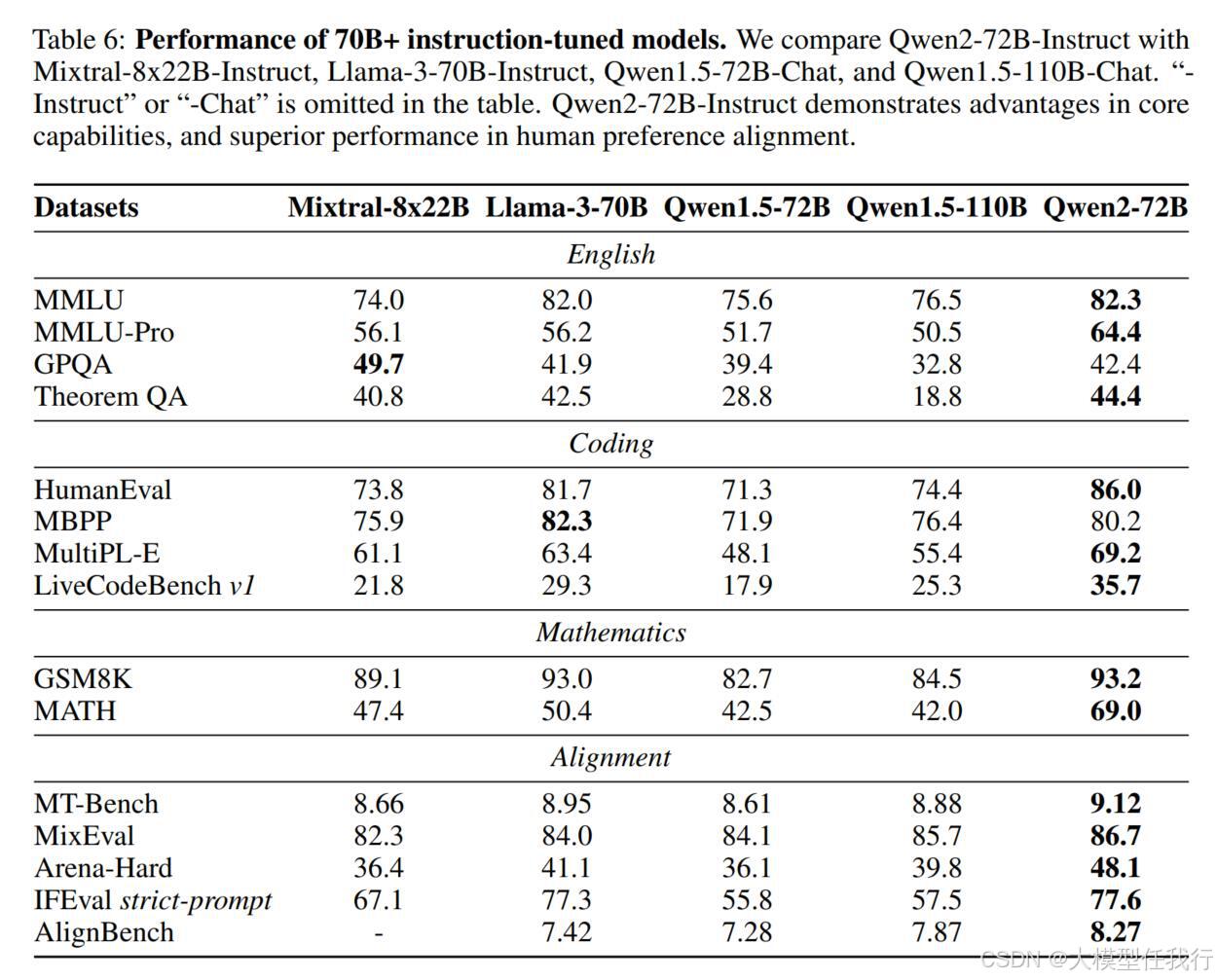
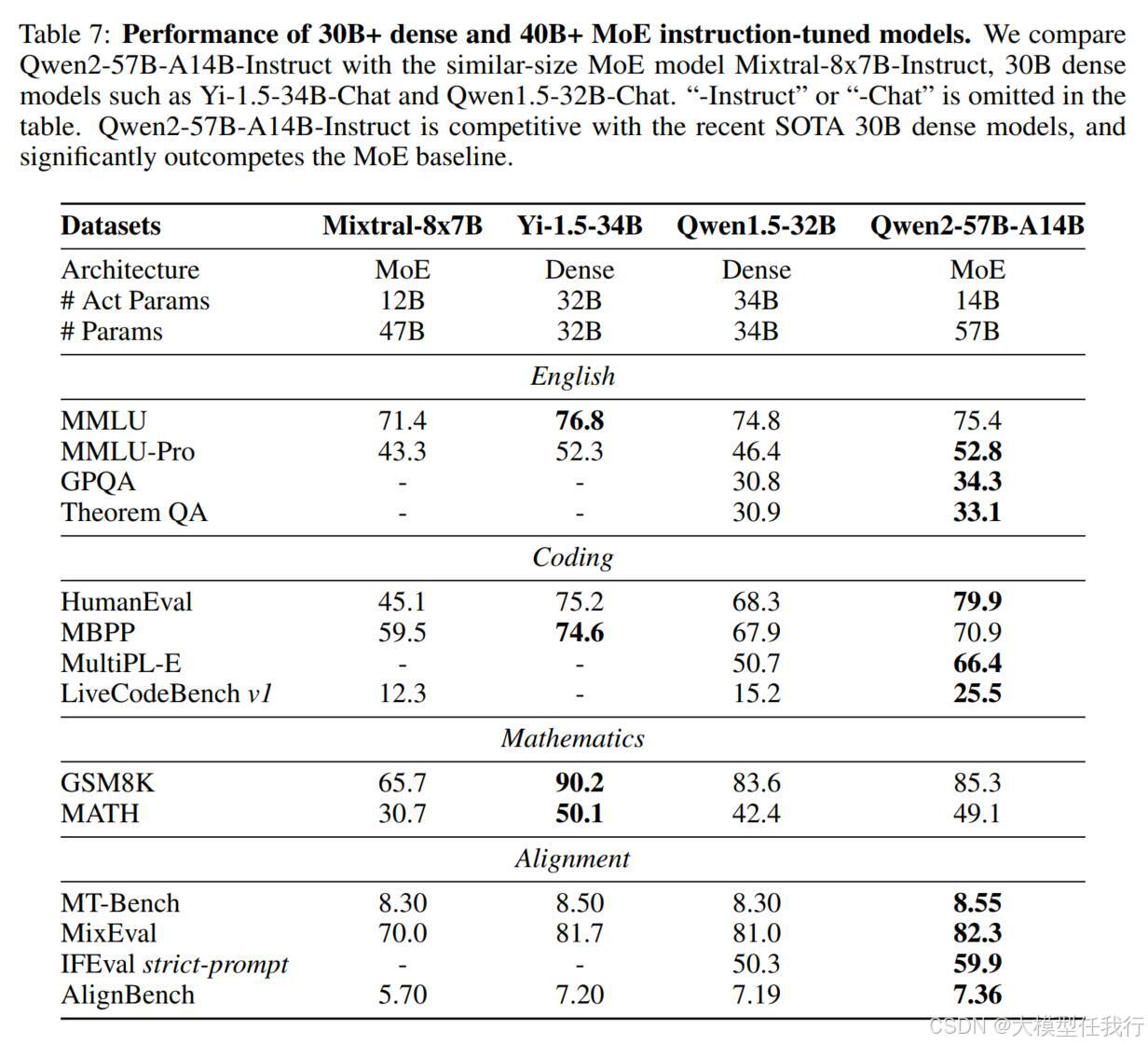
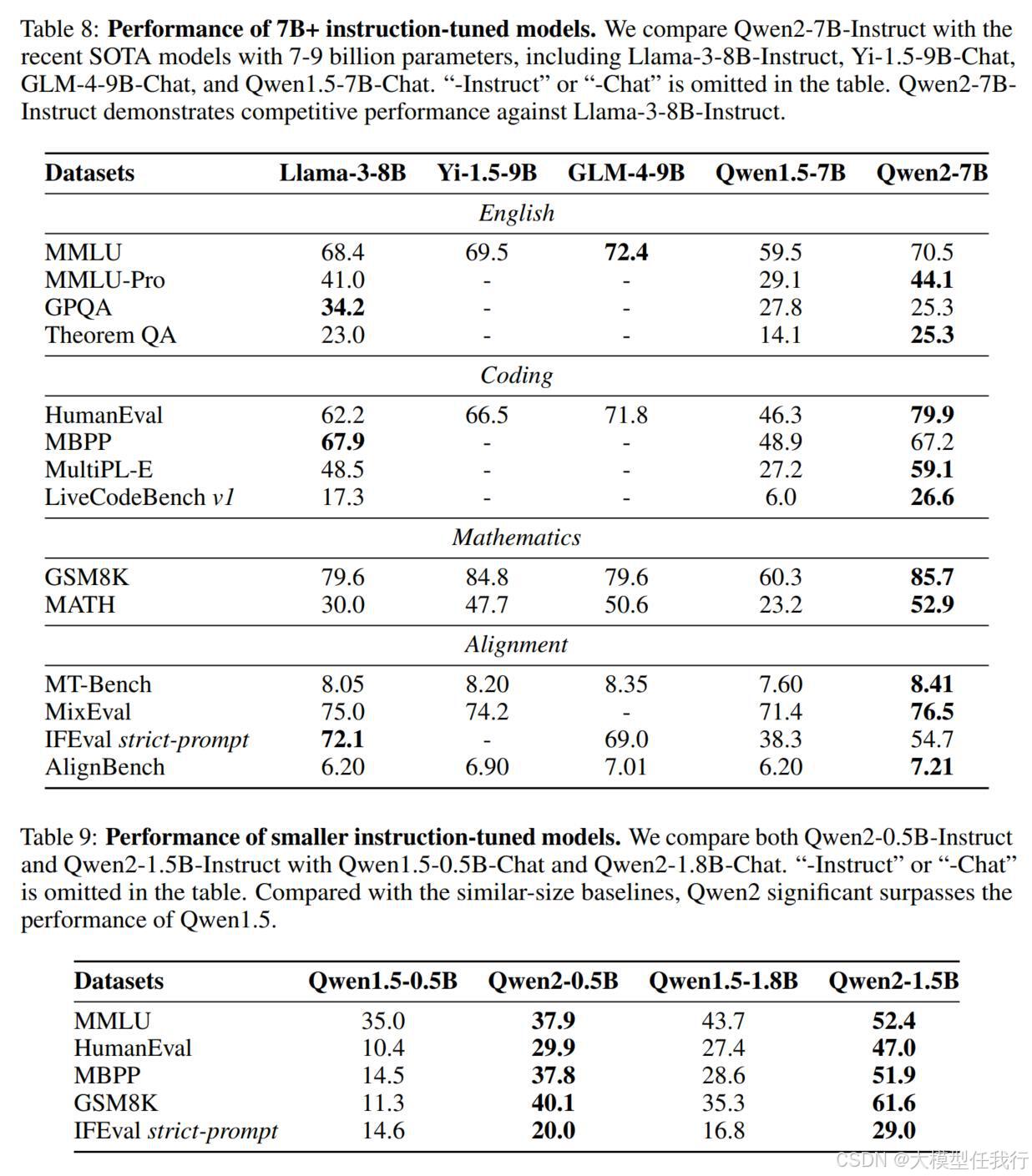
🔸对齐模型:使用开放数据集和基准,对基础技能和人类偏好进行评估,特别关注长上下文能力和安全能力。
💡个人观点
千问2通过高质量多语言数据集和改进的训练技术,显著提升了模型的推理能力和指令遵循能力。
附录