📖标题:The Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation
🌐来源:arXiv, 2501.01329
🌟摘要
🔸测试用例对于验证软件应用程序的可靠性和质量至关重要。最近的研究表明,大型语言模型(LLM)能够为给定的源代码生成有用的测试用例。然而,现有的工作主要依赖于人工编写的简单提示,这通常会导致次优结果,因为LLM的性能会受到提示的高度影响。此外,这些方法对所有LLM使用相同的提示,忽略了不同LLM可能最适合不同提示的事实。鉴于可能的提示公式种类繁多,自动发现每个LLM的最佳提示是一个重大挑战。尽管在自然语言处理领域有自动提示优化的方法,但它们很难为测试用例生成任务生成有效的提示。首先,这些方法在没有适当指导的情况下,通过简单地组合和修改现有的提示来迭代优化提示,导致提示缺乏多样性,并倾向于在生成的测试用例中重复相同的错误。其次,提示通常缺乏领域上下文知识,限制了LLM在任务中的表现。
🔸本文介绍了MAPS,这是一种用于生成teSt案例的LLM辅助提示生成方法。MAPS包括三个主要模块:多样性引导的提示生成、故障驱动的规则归纳和领域上下文知识提取。具体来说,在多样性引导提示生成模块中,MAPS通过在优化过程中探索不同的修改路径来创建不同的提示。它防止优化过程收敛到局部最优。故障驱动规则归纳模块旨在通过反映生成的测试用例中的常见故障来识别有前景的优化方向,其中反射输出基于规则转换方法被软集成到提示中。领域上下文知识提取模块旨在通过整合文件内和跨文件上下文信息,用相关领域知识丰富提示。
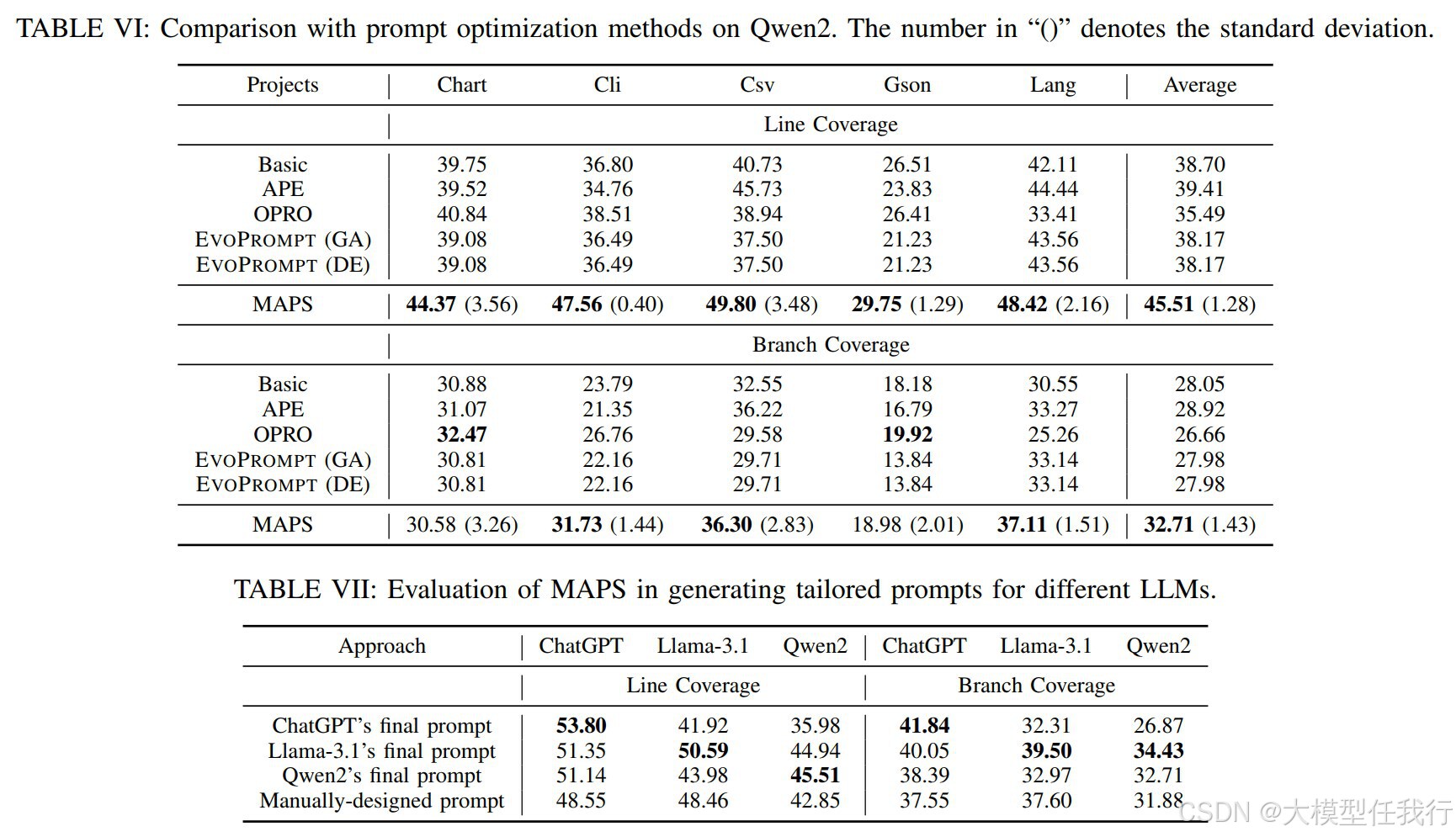
🔸为了评估MAPS的有效性,我们将其与三种流行LLM中的四种最先进的提示优化方法进行了比较。实验结果表明,我们的方法在很大程度上优于基线方法,平均实现了6.19%的线路覆盖率和5.03%的分支覆盖率。此外,在不同LLM上的实验表明,我们的方法可以有效地为每种LLM找到最合适的提示。
🛎️文章简介
🔸研究问题:现有基于大语言模型(LLM)的测试用例生成方法中,手动设计的提示(prompt)效果不佳且难以适应不同LLM
🔸主要贡献:论文提出了一种名为MAPS的自动化提示优化方法,通过结合多样性引导的提示生成、失败驱动的规则归纳和领域上下文知识提取,显著提升了测试用例生成的提示效果,并为不同LLM生成定制化的提示。
📝重点思路
🔸多样性引导的提示生成:通过评估当前提示的性能,选择表现最好的提示,并生成多样化的修改方法,以探索更广泛的提示空间。
🔸失败驱动的规则归纳:从失败的测试用例中提取常见错误信息,生成反思提示,并将反思结果转化为简洁的规则,以避免LLM重复相同的错误。
🔸领域上下文知识提取:通过提取与测试方法相关的领域上下文信息(如子类继承和类调用信息),帮助LLM生成更准确的测试用例。
🔸迭代优化过程:通过多次迭代,逐步优化提示,最终生成包含多样性引导的提示、归纳规则和上下文信息的最终提示。
🔎分析总结
🔸MAPS的有效性:MAPS在多个LLM上显著优于现有的提示优化方法,平均行覆盖率提高了6.19%,分支覆盖率提高了5.03%。
🔸LLM定制化提示生成:MAPS能够为不同LLM生成定制化的提示,且这些提示在各自LLM上的表现优于手动设计的提示。
🔸各模块的影响:失败驱动的规则归纳和多样性引导的提示生成对MAPS的性能提升贡献显著,移除任一模块都会导致性能大幅下降。
🔸实验设置的影响:MAPS在不同实验设置下表现稳定,且随着种子提示数量和迭代次数的增加,性能逐步提升。
💡个人观点
论文的核心是形成了一套生成、反思和优化的测试用例提示优化闭环。
🧩附录