📖标题:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
🌐来源:arXiv, 2502.11089
🌟摘要
🔸长上下文建模对于下一代语言模型至关重要,但标准注意力机制的高计算成本带来了重大的计算挑战。稀疏注意力为在保持模型功能的同时提高效率提供了一个有前景的方向。
🔸我们提出了NSA,这是一种可主动训练的S解析注意力机制,它将算法创新与硬件对齐优化相结合,以实现高效的长上下文建模。NSA采用动态分层稀疏策略,将粗粒度令牌压缩与细粒度令牌选择相结合,以保持全局上下文感知和局部精度。我们的方法通过两个关键创新推进了稀疏注意力设计:(1)我们通过算术强度平衡算法设计实现了显著的加速,并对现代硬件进行了实现优化。(2) 我们支持端到端训练,在不牺牲模型性能的情况下减少预训练计算。
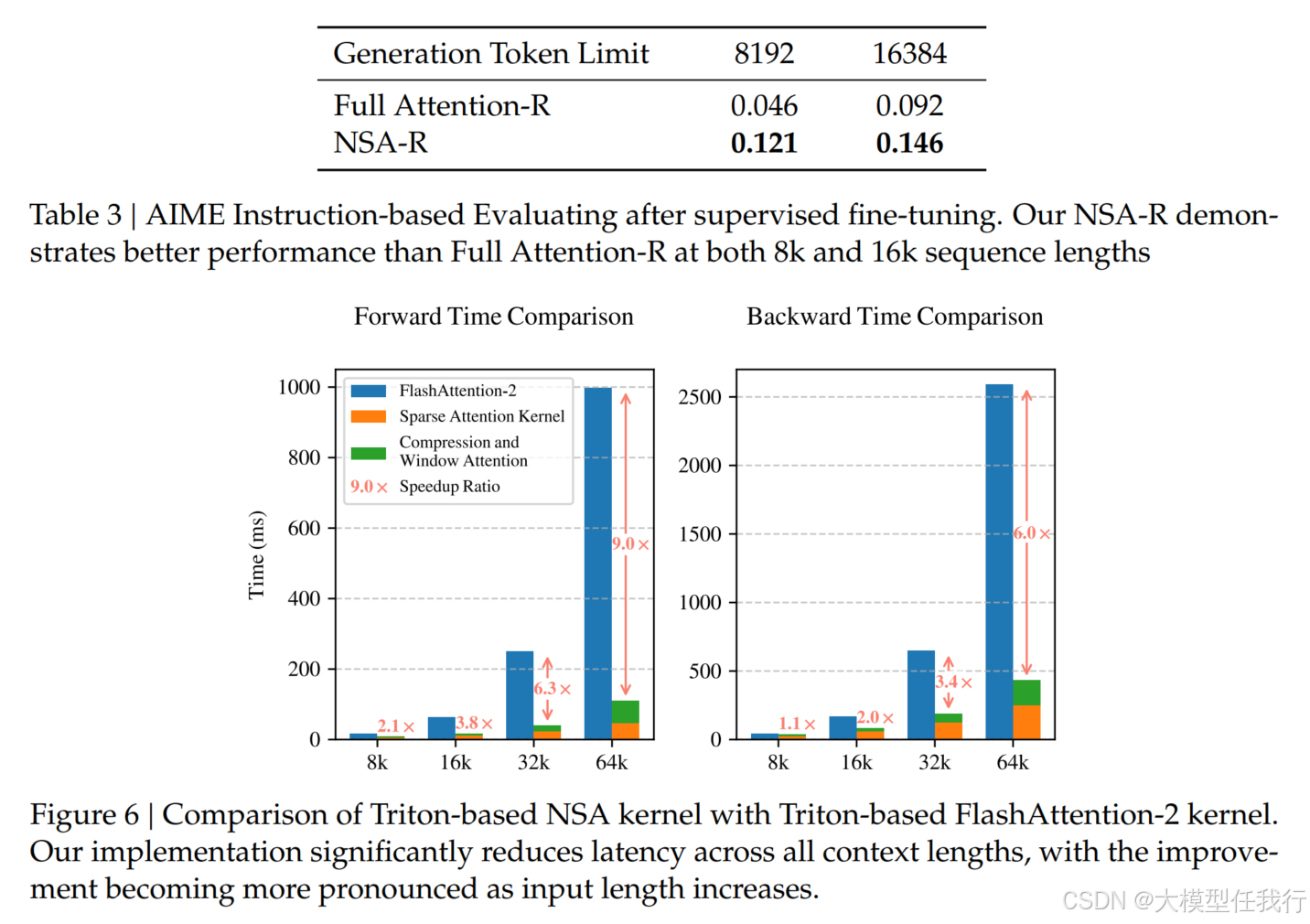
🔸实验表明,使用NSA预训练的模型在一般基准测试、长上下文任务和基于指令的推理中保持或超过了全注意力模型。同时,NSA在解码、前向传播和后向传播的64k长度序列上比Full Attention实现了显著的加速,验证了其在整个模型生命周期中的效率。
🛎️文章简介
🔸研究问题:现有稀疏注意力机制在推理和训练阶段的效率低下,特别是在长文本上下文建模中的性能限制。
🔸主要贡献:论文提出了一种名为NSA的稀疏注意力架构,通过结合分层令牌建模和硬件优化的实现,显著提高了长上下文建模的效率和性能。
📝重点思路
🔸提出了一种新的稀疏注意力架构NSA,将注意力计算分为三个路径,分别为压缩的粗粒度令牌、选择性保留的细粒度令牌和用于局部上下文的滑动窗口,NSA能够在不同的上下文中有效处理重要信息,以此提高模型的效率与性能。
🔸实现了硬件对齐的稀疏注意力内核,以最大化计算效率,特别是在现代加速器上。
🔸通过对比实验,在多种基准测试中评估了NSA的性能,验证其在一般语言任务、长上下文任务和推理任务中的有效性。
🔎分析总结
🔸NSA在大多数评估指标上超越了全注意力基线,显示出优越的性能,尤其在推理相关的基准测试中表现突出。
🔸在长上下文任务中,NSA实现了完美的检索准确率,表明其能够有效结合全局和局部信息。
🔸在链式推理评估中,NSA在较长的上下文设置下显著提高了准确性,验证了其在复杂推理任务中的有效性。
🔸NSA在训练和推理阶段均展现了显著的速度提升,随着上下文长度的增加,速度优势愈加明显。
💡个人观点
论文的核心在于对输入的令牌压缩和选择,有效地捕捉长程依赖关系,并在硬件优化实现计算效率提升。
🧩附录